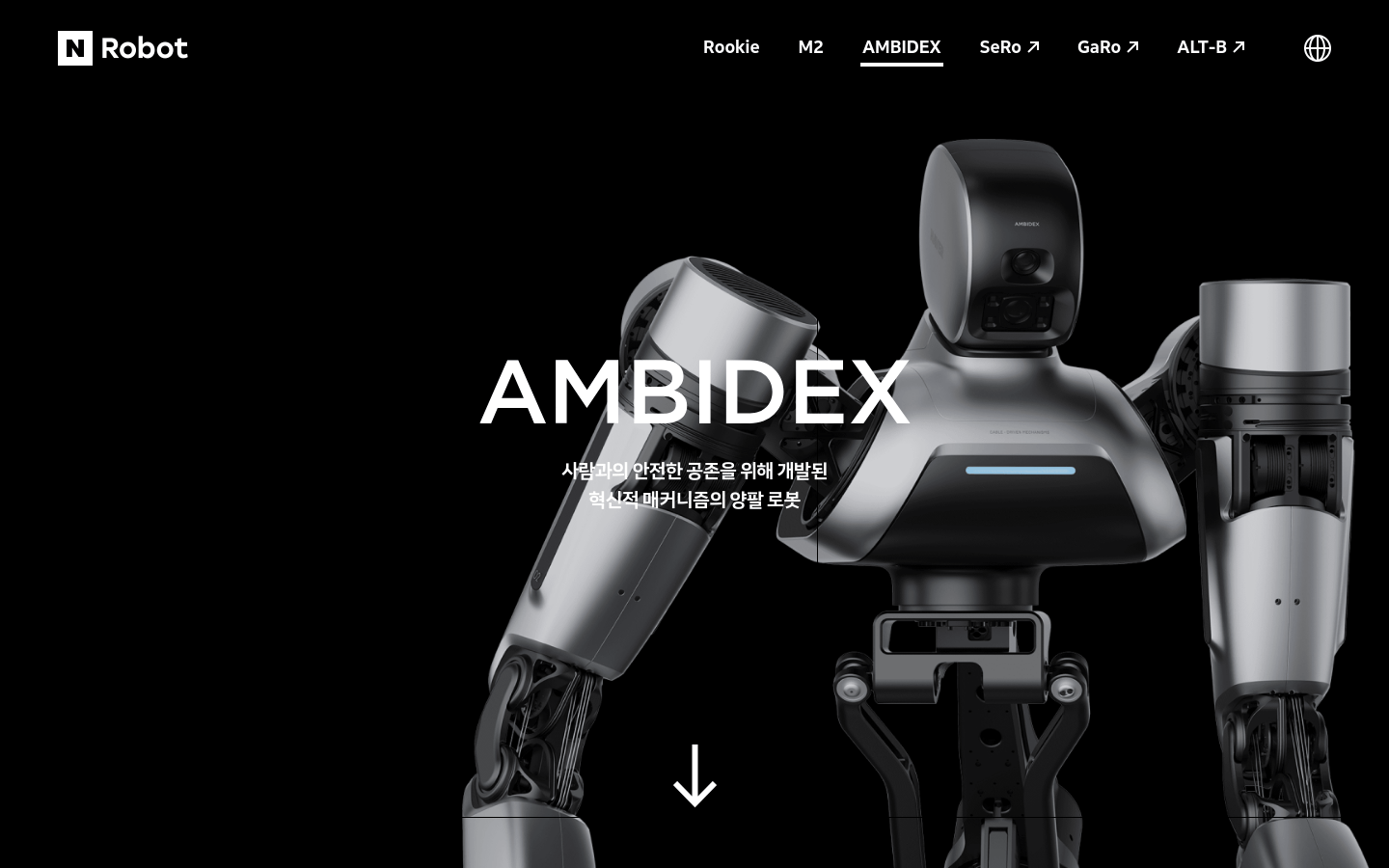
AMBIDEX是NAVER LABS开发的双臂机器人,旨在实现与人类的安全共存。该机器人具有强大的动力传递机制,同时保持轻便和灵活,满足坚韧和安全性的要求。AMBIDEX项目正在研究新的学习方式,使机器人能够学习人类的动作能力,以执行日常遇到的复杂任务。
需求人群:
"适用于需要机器人在日常生活中执行复杂任务的场景,如家庭服务、医疗辅助、工业自动化等。"
使用场景示例:
家庭中使用AMBIDEX机器人进行日常清洁和整理工作
医疗机构利用AMBIDEX机器人为病患提供护理和康复辅助
工厂中部署AMBIDEX机器人进行精密装配和质量检测
产品特色:
实现人与机器人的安全共存
具有创新的动力传递机制,既强大又轻便
研究新的学习方式,使机器人能学习人类的动作能力
浏览量:73
最新流量情况
月访问量
100.47k
平均访问时长
00:07:12
每次访问页数
6.87
跳出率
33.73%
流量来源
直接访问
47.79%
自然搜索
38.69%
邮件
0.03%
外链引荐
11.62%
社交媒体
1.56%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
法国
2.12%
印度
3.56%
韩国
68.86%
美国
5.32%
为与人类安全共存而开发的创新双臂机器人机制
AMBIDEX是NAVER LABS开发的双臂机器人,旨在实现与人类的安全共存。该机器人具有强大的动力传递机制,同时保持轻便和灵活,满足坚韧和安全性的要求。AMBIDEX项目正在研究新的学习方式,使机器人能够学习人类的动作能力,以执行日常遇到的复杂任务。
大规模机器人学习数据集,推动多用途机器人策略发展。
AGIBOT WORLD是一个专为推进多用途机器人策略而设计的大规模机器人学习数据集。它包括基础模型、基准测试和一个生态系统,旨在为学术界和工业界提供高质量的机器人数据,为具身AI铺平道路。该数据集包含100多台机器人的100万条以上轨迹,覆盖100多个真实世界场景,涉及精细操控、工具使用和多机器人协作等任务。它采用尖端的多模态硬件,包括视觉触觉传感器、耐用的6自由度灵巧手和具有全身控制的移动双臂机器人,支持模仿学习、多智能体协作等研究。AGIBOT WORLD的目标是改变大规模机器人学习,推进可扩展的机器人系统生产,是一个开源平台,邀请研究人员和实践者共同塑造具身AI的未来。
机器人教学框架,无需在野机器人
通用操作接口(UMI)是一个数据收集和策略学习框架,允许直接将现场人类演示中的技能转移到可部署的机器人策略。UMI采用手持夹具与仔细的界面设计相结合,实现便携、低成本和信息丰富的数据收集,用于挑战性的双手和动态操作演示。为促进可部署的策略学习,UMI结合了精心设计的策略界面,具有推理时延迟匹配和相对轨迹动作表示。从而产生的学习策略与硬件无关,并且可以在多个机器人平台上部署。配备这些功能,UMI框架解锁了新的机器人操作功能,仅通过为每个任务更改训练数据,允许泛化的动态、双手、精确和长时间的行为,从而实现零次调整。我们通过全面的真实环境实验演示了UMI的通用性和有效性,其中仅通过使用各种人类演示进行训练的UMI策略,在面对新环境和对象时实现了零次调整的泛化。
通用型物理引擎,用于机器人学和物理AI应用
Genesis是一个全面物理仿真平台,专为机器人学、具身AI和物理AI应用设计。它是一个从头构建的通用物理引擎,能够模拟广泛的材料和物理现象。作为一个轻量级、超快速、Pythonic且用户友好的机器人仿真平台,它还具备强大的真实感渲染系统和将自然语言描述转换为各种数据模态的生成数据引擎。Genesis通过其核心物理引擎的集成,进一步增强了上层的生成代理框架,旨在为机器人学及其它领域实现全自动数据生成。
基于生成式模拟的自动机器人学习
RoboGen 是一款基于生成式模拟的自动机器人学习产品。它通过自动生成多样化的任务、场景和训练监督,实现大规模机器人技能学习。RoboGen 具备自主提出、生成、学习的能力,可以不断生成与各种任务和环境相关的技能演示。
用于人形机器人学习的通用基础模型
NVIDIA Project GR00T是一种通用基础模型,可在仿真和真实世界中改变人形机器人的学习方式。通过在NVIDIA GPU加速模拟中进行训练,GR00T使得人形机器人能够从少量的人类演示中通过模仿学习和NVIDIA Isaac Lab进行强化学习,并可从视频数据生成机器人动作。GR00T模型接受多模态指令和过去的交互作为输入,并输出机器人需要执行的动作。
学习野外音频视觉数据的机器人操控
ManiWAV是一个研究项目,旨在通过野外的音频和视觉数据学习机器人操控技能。它通过收集人类演示的同步音频和视觉反馈,并通过相应的策略接口直接从演示中学习机器人操控策略。该模型展示了通过四个接触丰富的操控任务来证明其系统的能力,这些任务需要机器人被动地感知接触事件和模式,或主动地感知物体表面的材料和状态。此外,该系统还能够通过学习多样化的野外人类演示来泛化到未见过的野外环境中。
大规模城市环境中的机器人模拟交互平台。
GRUtopia是一个为各种机器人设计的交互式3D社会模拟平台,它通过模拟到现实(Sim2Real)的范式,为机器人学习提供了一个可行的路径。平台包含100k精细标注的交互场景,可以自由组合成城市规模的环境,覆盖89种不同的场景类别,为服务导向环境中通用机器人的部署提供了基础。此外,GRUtopia还包括一个由大型语言模型(LLM)驱动的NPC系统,负责社交互动、任务生成和分配,模拟了具身AI应用的社交场景。
开源机器人模拟平台,用于生成无限机器人数据和泛化AI。
ManiSkill是一个领先的开源平台,专注于机器人模拟、无限机器人数据生成和泛化机器人AI。由HillBot.ai领导,该平台支持通过状态和/或视觉输入快速训练机器人,与其它平台相比,ManiSkill/SAPIEN实现了10-100倍的视觉数据收集速度。它支持在GPU上并行模拟和渲染RGB-D,速度高达30,000+FPS。ManiSkill提供了40多种技能/任务和2000多个对象的预构建任务,拥有数百万帧的演示和密集的奖励函数,用户无需自己收集资产或设计任务,可以专注于算法开发。此外,它还支持在每个并行环境中同时模拟不同的对象和关节,训练泛化机器人策略/AI的时间从天缩短到分钟。ManiSkill易于使用,可以通过pip安装,并提供简单灵活的GUI以及所有功能的广泛文档。
AI国际象棋机器人,智能对弈与教学
元萝卜AI下棋机器人是商汤科技旗下家用机器人品牌,通过AI科技为孩子的健康、学习、快乐成长保驾护航。产品具备陪练涨棋、棋力闯关、巅峰对决、在线对弈、残局挑战、AI打谱、AI习题精练、棋局分享等功能,旨在通过真实棋盘棋子的交互,保护孩子视力,同时提高棋艺水平。
模块化仿人机器人,用于强化学习训练
Agibot X1是由Agibot开发的模块化仿人机器人,具有高自由度,基于Agibot开源框架AimRT作为中间件,并使用强化学习进行运动控制。该项目是Agibot X1使用的强化学习训练代码,可以与Agibot X1提供的推理软件结合用于真实机器人和模拟步行调试,或导入其他机器人模型进行训练。
智能AI聊天助手,提供多语言对话和个性化服务。
Ai Chat机器人Plus是一款基于人工智能技术的聊天机器人,它能够理解并流畅地与用户进行交流,提供信息查询、日常咨询、技术支持等服务。这款产品通过模仿人类的对话方式,为用户提供了一个直观、便捷的交互体验。它主要的优点包括快速响应、高准确率的语义理解以及个性化的服务体验。Ai Chat机器人Plus适用于需要快速、智能对话解决方案的个人和企业用户。
Figure是第一家专注于研发通用型人形机器人的AI机器人公司。
Figure是一个创新的AI机器人公司,致力于研发第一台通用型人形机器人Figure 01。Figure 01集成了人形的灵巧性和前沿的AI技术,可广泛应用于制造业、物流、仓储和零售等领域,支持人类完成更多工作。该机器人高5.6英尺,载重20公斤,重60公斤,工作时间5小时,移动速度每秒1.2米。Figure还拥有世界顶级的机器人团队,团队成员在AI和人形机器人领域拥有超过100年的丰富经验。
AI娱乐聊天机器人
ChatShitGPT是一款非同寻常的聊天机器人,能够为用户提供娱乐和消遣。其特色在于具有个性化的角色,用户可以选择与海盗、主角或者愤怒的角色进行互动。用户可以免费开始使用,但也提供订阅服务。产品定位为提供娱乐、消遣和放松的聊天体验。
全栈开源机器人
智元灵犀X1是一款开源人形机器人,具有29个关节和2个夹爪,支持扩展头部3自由度。它提供了详细的开发指南和开源代码,使开发者能够快速搭建并进行二次开发。该产品代表了智能机器人领域的先进技术,具有高度的灵活性和可扩展性,适用于教育、研究和商业开发等多种场景。
基于GPT-4的拟人机器人
Alter3是一个基于GPT-4的拟人机器人,能够通过自然语言指令生成各种人类动作,实现零次学习。它具有43个关节自由度,可以自由运动,同时结合面部表情识别和生成,实现复杂的交互。用户只需要提供语言指令,Alter3就可以自主调整代码,生成相应运动,无需人工迭代调整。还可以通过语言反馈来优化动作,形成运动记忆。这种结合语言理解和身体运动的系统,大大提升了人机交互的潜力。
为真实世界机器人提供最先进的机器学习模型、数据集和工具。
LeRobot 是一个旨在降低进入机器人领域的门槛,让每个人都能贡献并从共享数据集和预训练模型中受益的开源项目。它包含了在真实世界中经过验证的最先进的方法,特别关注模仿学习和强化学习。LeRobot 提供了一组预训练模型、带有人类收集演示的数据集和模拟环境,以便用户无需组装机器人即可开始。未来几周内,计划增加对最实惠和最有能力的真实世界机器人的支持。
让机器人写作
write.bot是一个让机器人写作的平台。您可以提交主题想法,邀请 GPT 机器人在您的主题或其他人的主题上撰写文章。您还可以添加自己的 GPT 机器人来撰写文章。通过写.bot,您可以与 AI 互动,并免费邀请机器人为您撰写文章。
通过模仿学习实现手术任务的机器人
Surgical Robot Transformer 是一种通过模仿学习在达芬奇机器人上执行手术操作任务的模型。该模型通过相对动作公式克服了达芬奇系统的前向运动学不准确的问题,使得机器人能够成功地训练和部署政策。这种方法的一个显著优势是可以直接利用包含近似运动学的大量临床数据进行机器人学习,而无需进一步校正。该模型展示了在执行三个基本手术任务(包括组织操作、针头处理和结扎)方面的成功。
基于GPT算法的智能聊天机器人
Open-GPT 开放版·直连GPT聊天机器人,是一款基于的GPT算法开发的聊天机器人,具备较高的智能度和语言理解能力,可以进行智能问答、闲聊、教育咨询等多种交互,为用户提供更加便利和快捷的服务。系统聊天记录不会被上传到第三方服务器,用户的隐私得到了更好的保护。
Twitter蓝色机器人扩展插件
BlueBot是一款基于CHAT-GPT技术的Twitter蓝色机器人扩展插件,可以改变您与这个流行的社交媒体平台交互的方式。BlueBot提供了强大的功能,包括智能回复、自动转发、定时发布、数据分析等。BlueBot的优势是简化了Twitter的使用过程,帮助用户更高效地管理和扩展自己的Twitter账号。BlueBot的定价根据不同的功能套餐而定,详情请查看官方网站。
SERL是一个高效的机器人强化学习软件套件
SERL是一个经过精心实现的代码库,包含了一个高效的离策略深度强化学习方法,以及计算奖励和重置环境的方法,一个高质量的广泛采用的机器人控制器,以及一些具有挑战性的示例任务。它为社区提供了一个资源,描述了它的设计选择,并呈现了实验结果。令人惊讶的是,我们发现我们的实现可以实现非常高效的学习,仅需25到50分钟的训练即可获得PCB装配、电缆布线和物体重定位等策略,改进了文献中报告的类似任务的最新结果。这些策略实现了完美或接近完美的成功率,即使在扰动下也具有极强的鲁棒性,并呈现出新兴的恢复和修正行为。我们希望这些有前途的结果和我们的高质量开源实现能为机器人社区提供一个工具,以促进机器人强化学习的进一步发展。
聊天机器人,让你不再孤单
豆包是一款智能聊天机器人,能够与用户进行自然语言交互,提供各种聊天话题,包括天气、新闻、笑话、音乐等。豆包还能够根据用户的喜好和习惯,推荐相关的内容和服务。豆包是你的私人聊天助手,让你不再孤单。
AI聊天机器人,帮助您处理客户支持
Ping Parrot是一个AI聊天机器人平台,可以帮助您快速构建自定义的聊天机器人,并将其嵌入到您的网站上,帮助您处理客户支持。无需编码即可使用。聊天机器人可以根据您的数据进行训练,学习并提供最佳答案。您可以定制聊天机器人的外观以匹配您的品牌,并在80种语言中提供帮助。

© 2026 AIbase 备案号:闽ICP备08105208号-14