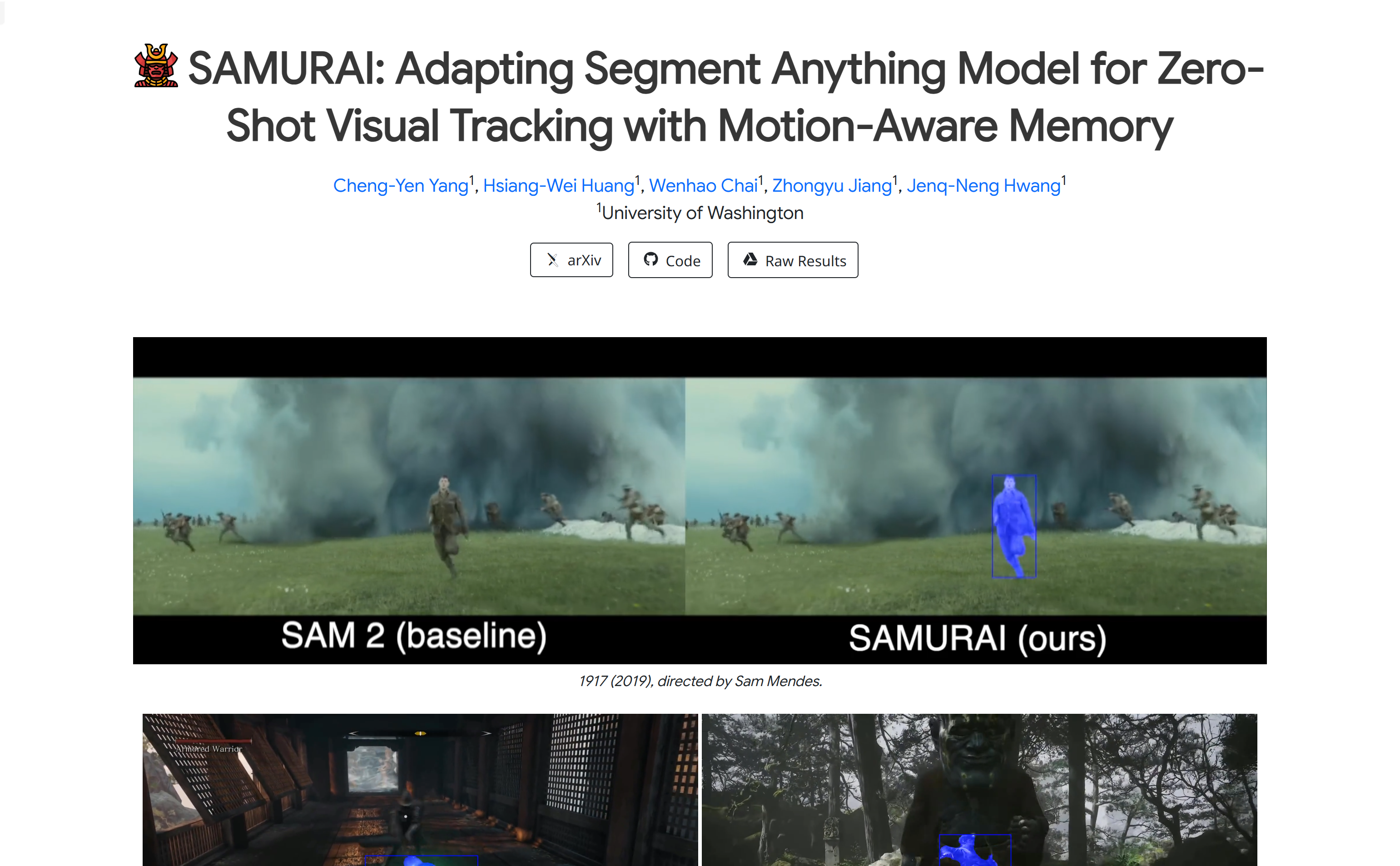
SAMURAI是一种基于Segment Anything Model 2 (SAM 2)的视觉对象跟踪模型,专门设计用于处理快速移动或自遮挡对象的视觉跟踪任务。它通过引入时间运动线索和运动感知记忆选择机制,有效预测对象运动并优化掩膜选择,无需重新训练或微调即可实现鲁棒、准确的跟踪。SAMURAI能够在实时环境中运行,并在多个基准数据集上展现出强大的零样本性能,证明了其无需微调即可泛化的能力。在评估中,SAMURAI在成功率和精确度上相较于现有跟踪器取得了显著提升,例如在LaSOT-ext上AUC提升了7.1%,在GOT-10k上AO提升了3.5%。此外,与LaSOT上的全监督方法相比,SAMURAI也展现出了竞争力,强调了其在复杂跟踪场景中的鲁棒性以及在动态环境中的潜在实际应用价值。
需求人群:
"SAMURAI的目标受众包括计算机视觉研究人员、视频监控系统开发者、自动驾驶技术工程师以及任何需要高精度视觉跟踪技术的行业。这些用户可以利用SAMURAI在无需大量训练数据的情况下实现高效的对象跟踪,特别是在动态和复杂的视觉环境中。"
使用场景示例:
在体育赛事中实时跟踪运动员的运动轨迹。
在视频监控系统中跟踪可疑人员或车辆。
在自动驾驶汽车中跟踪周围移动的物体以避免碰撞。
产品特色:
- 零样本视觉跟踪:无需训练即可在多种数据集上进行视觉跟踪。
- 运动感知记忆选择:通过运动线索优化掩膜选择,提高跟踪精度。
- 实时性能:能够在实时环境中处理视觉跟踪任务。
- 泛化能力:无需微调即可在不同数据集上实现跟踪。
- 高成功率和精确度:在多个基准测试中表现优于现有跟踪器。
- 鲁棒性:在复杂和动态环境中保持稳定的跟踪性能。
- 无需重新训练或微调:简化了模型部署和应用流程。
使用教程:
1. 访问SAMURAI的官方网站以获取模型和相关代码。
2. 阅读文档了解模型的输入输出要求和配置参数。
3. 准备需要跟踪的视频或图像序列。
4. 根据文档指导,将视频或图像序列输入到SAMURAI模型中。
5. 观察并分析SAMURAI输出的跟踪结果。
6. 根据需要调整模型参数以优化跟踪性能。
7. 将SAMURAI集成到实际应用中,如监控系统或自动驾驶技术。
浏览量:109
最新流量情况
月访问量
1197
平均访问时长
00:00:22
每次访问页数
1.55
跳出率
54.67%
流量来源
直接访问
47.35%
自然搜索
27.39%
邮件
0.10%
外链引荐
11.54%
社交媒体
11.53%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
德国
30.53%
韩国
16.94%
美国
52.53%
零样本视觉跟踪模型,具有运动感知记忆。
SAMURAI是一种基于Segment Anything Model 2 (SAM 2)的视觉对象跟踪模型,专门设计用于处理快速移动或自遮挡对象的视觉跟踪任务。它通过引入时间运动线索和运动感知记忆选择机制,有效预测对象运动并优化掩膜选择,无需重新训练或微调即可实现鲁棒、准确的跟踪。SAMURAI能够在实时环境中运行,并在多个基准数据集上展现出强大的零样本性能,证明了其无需微调即可泛化的能力。在评估中,SAMURAI在成功率和精确度上相较于现有跟踪器取得了显著提升,例如在LaSOT-ext上AUC提升了7.1%,在GOT-10k上AO提升了3.5%。此外,与LaSOT上的全监督方法相比,SAMURAI也展现出了竞争力,强调了其在复杂跟踪场景中的鲁棒性以及在动态环境中的潜在实际应用价值。
零样本风格化情侣肖像创作
Omni-Zero-Couples是一个使用diffusers管道的零样本风格化情侣肖像创作模型。它利用深度学习技术,无需预先定义的风格样本,即可生成具有特定艺术风格的情侣肖像。这种技术在艺术创作、个性化礼物制作和数字娱乐领域具有广泛的应用前景。
零样本声音转换技术,实现音质与音色的高保真转换。
seed-vc 是一个基于 SEED-TTS 架构的声音转换模型,能够实现零样本的声音转换,即无需特定人的声音样本即可转换声音。该技术在音频质量和音色相似性方面表现出色,具有很高的研究和应用价值。
一种用于零样本定制图像生成的扩散自蒸馏技术
Diffusion Self-Distillation是一种基于扩散模型的自蒸馏技术,用于零样本定制图像生成。该技术允许艺术家和用户在没有大量配对数据的情况下,通过预训练的文本到图像的模型生成自己的数据集,进而微调模型以实现文本和图像条件的图像到图像任务。这种方法在保持身份生成任务的性能上超越了现有的零样本方法,并能与每个实例的调优技术相媲美,无需测试时优化。
视频重渲染:零样本文本引导的视频到视频翻译
RERENDER A VIDEO是一种新颖的零样本文本引导的视频到视频翻译框架,用于将图像模型应用于视频领域。该框架包括两个部分:关键帧翻译和完整视频翻译。第一部分使用适应性扩散模型生成关键帧,并应用分层跨帧约束来确保形状、纹理和颜色的一致性。第二部分通过时间感知的补丁匹配和帧混合将关键帧传播到其他帧。我们的框架以低成本实现了全局风格和局部纹理的时间一致性(无需重新训练或优化)。该适应性与现有的图像扩散技术兼容,使我们的框架能够利用它们,例如使用LoRA自定义特定主题,并使用ControlNet引入额外的空间引导。大量实验证明了我们提出的框架在呈现高质量和时间一致性视频方面的有效性。
无需对齐信息的零样本文本到语音转换模型
MaskGCT是一个创新的零样本文本到语音转换(TTS)模型,它通过消除显式对齐信息和音素级持续时间预测的需求,解决了自回归和非自回归系统中存在的问题。MaskGCT采用两阶段模型:第一阶段使用文本预测从语音自监督学习(SSL)模型中提取的语义标记;第二阶段,模型根据这些语义标记预测声学标记。MaskGCT遵循掩码和预测的学习范式,在训练期间学习预测基于给定条件和提示的掩码语义或声学标记。在推理期间,模型以并行方式生成指定长度的标记。实验表明,MaskGCT在质量、相似性和可理解性方面超越了当前最先进的零样本TTS系统。
零样本图像编辑,一键模仿参考图像风格
MimicBrush是一种创新的图像编辑模型,它允许用户通过指定源图像中的编辑区域和提供一张野外参考图像来实现零样本图像编辑。该模型能够自动捕捉两者之间的语义对应关系,并一次性完成编辑。MimicBrush的开发基于扩散先验,通过自监督学习捕捉不同图像间的语义关系,实验证明其在多种测试案例下的有效性及优越性。
零样本图像动画生成器
AnimateZero是一款零样本图像动画生成器,通过分离外观和运动生成视频,解决了黑盒、低效、不可控等问题。它可以通过零样本修改将预训练的T2V模型转换为I2V模型,从而实现零样本图像动画生成。AnimateZero还可以用于视频编辑、帧插值、循环视频生成和真实图像动画等场景,具有较高的主观质量和匹配度。
VideoGrain 是一种零样本方法,用于实现类别级、实例级和部件级的视频编辑。
VideoGrain 是一种基于扩散模型的视频编辑技术,通过调节时空注意力机制实现多粒度视频编辑。该技术解决了传统方法中语义对齐和特征耦合的问题,能够对视频内容进行精细控制。其主要优点包括零样本编辑能力、高效的文本到区域控制以及特征分离能力。该技术适用于需要对视频进行复杂编辑的场景,如影视后期、广告制作等,能够显著提升编辑效率和质量。
X-Dyna是一种基于扩散模型的零样本人类图像动画生成技术。
X-Dyna是一种创新的零样本人类图像动画生成技术,通过将驱动视频中的面部表情和身体动作迁移到单张人类图像上,生成逼真且富有表现力的动态效果。该技术基于扩散模型,通过Dynamics-Adapter模块,将参考外观上下文有效整合到扩散模型的空间注意力中,同时保留运动模块合成流畅复杂动态细节的能力。它不仅能够实现身体姿态控制,还能通过本地控制模块捕捉与身份无关的面部表情,实现精确的表情传递。X-Dyna在多种人类和场景视频的混合数据上进行训练,能够学习物理人体运动和自然场景动态,生成高度逼真和富有表现力的动画。
大型语言模型是视觉推理协调器
Cola是一种使用语言模型(LM)来聚合2个或更多视觉-语言模型(VLM)输出的方法。我们的模型组装方法被称为Cola(COordinative LAnguage model or visual reasoning)。Cola在LM微调(称为Cola-FT)时效果最好。Cola在零样本或少样本上下文学习(称为Cola-Zero)时也很有效。除了性能提升外,Cola还对VLM的错误更具鲁棒性。我们展示了Cola可以应用于各种VLM(包括大型多模态模型如InstructBLIP)和7个数据集(VQA v2、OK-VQA、A-OKVQA、e-SNLI-VE、VSR、CLEVR、GQA),并且它始终提高了性能。
SigLIP2 是谷歌推出的一种多语言视觉语言编码器,用于零样本图像分类。
SigLIP2 是谷歌开发的多语言视觉语言编码器,具有改进的语义理解、定位和密集特征。它支持零样本图像分类,能够通过文本描述直接对图像进行分类,无需额外训练。该模型在多语言场景下表现出色,适用于多种视觉语言任务。其主要优点包括高效的语言图像对齐能力、支持多种分辨率和动态分辨率调整,以及强大的跨语言泛化能力。SigLIP2 的推出为多语言视觉任务提供了新的解决方案,尤其适合需要快速部署和多语言支持的场景。
掌握开放世界交互的视觉-时间上下文提示模型
ROCKET-1是一个视觉-语言模型(VLMs),专门针对开放世界环境中的具身决策制定而设计。该模型通过视觉-时间上下文提示协议,将VLMs与策略模型之间的通信连接起来,利用来自过去和当前观察的对象分割来指导策略-环境交互。ROCKET-1通过这种方式,能够解锁VLMs的视觉-语言推理能力,使其能够解决复杂的创造性任务,尤其是在空间理解方面。ROCKET-1在Minecraft中的实验表明,该方法使代理能够完成以前无法实现的任务,突出了视觉-时间上下文提示在具身决策制定中的有效性。
无需代码或训练数据即可建立强大的计算机视觉模型
DirectAI是一个基于大型语言模型和零样本学习的平台,可以根据您的描述即时构建适合您需求的模型,无需训练数据。您可以在几秒钟内部署和迭代模型,省去了组装训练数据、标记数据、训练模型和微调模型的时间和费用。DirectAI在纽约市总部,并获得了风投支持,正在改变人们在现实世界中使用人工智能的方式。
零代码检测AI生成文本的工具
Binoculars是一个先进的AI生成文本检测工具,无需训练数据即可零配置使用。它的检测思路非常简单明了:大多数只用decoder的因果语言模型在预训练时使用了大量相同的数据集,例如Common Crawl、Pile等。更多关于该方法及其效果的信息请参阅我们的论文《用双目镜发现LLM: 机器生成文本的零样本检测》。
图片和视频的通用对象基础模型
GLEE 是一个针对图片和视频的通用对象基础模型,通过统一的框架实现了定位和识别图像和视频中的对象,并能应用于各种对象感知任务。GLEE 通过联合训练来自不同监督水平的各种数据源,形成通用的对象表示,在保持最先进性能的同时,能够有效地进行零样本迁移和泛化。它还具备良好的可扩展性和鲁棒性。
开源的实时语音克隆技术
OpenVoice是一个开源的语音克隆技术,可以准确地克隆参考音色,生成多种语言和口音的语音。它可以灵活地控制语音风格,如情感、口音等参数,以及节奏、停顿和语调等。它实现了零样本跨语言语音克隆,即生成语音和参考语音的语言都不需要出现在训练数据中。
通用视觉-语义物体检测,无需任务特定调优
T-Rex2是一种范式突破的物体检测技术,能够识别从日常到深奥的各种物体,无需任务特定调优或大量训练数据集。它将视觉和文本提示相结合,赋予其强大的零射能力,可广泛应用于各种场景的物体检测任务。T-Rex2综合了四个组件:图像编码器、视觉提示编码器、文本提示编码器和框解码器。它遵循DETR的端到端设计原理,涵盖多种应用场景。T-Rex2在COCO、LVIS、ODinW和Roboflow100等四个学术基准测试中取得了最优秀的表现。
根据人类指令修复和编辑照片的框架
PromptFix是一个综合框架,能够使扩散模型遵循人类指令执行各种图像处理任务。该框架通过构建大规模的指令遵循数据集,提出了高频引导采样方法来控制去噪过程,并设计了辅助提示适配器,利用视觉语言模型增强文本提示,提高模型的任务泛化能力。PromptFix在多种图像处理任务中表现优于先前的方法,并在盲恢复和组合任务中展现出优越的零样本能力。
GoDiary是一款自动跟踪运动的健身应用
GoDiary是一款能够自动跟踪运动的健身应用。它结合了GPS和专有的机器学习算法,以省电的方式监测用户的健身活动。通过GoDiary,用户可以轻松追踪自己的跑步、步行和骑行等运动,并提供个性化的目标跟踪和历史数据分析。
Level-Navi Agent是一个无需训练即可使用的框架,利用大语言模型进行深度查询理解和精准搜索。
Level-Navi Agent是一个开源的通用网络搜索代理框架,能够将复杂问题分解并逐步搜索互联网上的信息,直至回答用户问题。它通过提供Web24数据集,覆盖金融、游戏、体育、电影和事件等五大领域,为评估模型在搜索任务上的表现提供了基准。该框架支持零样本和少样本学习,为大语言模型在中文网络搜索代理领域的应用提供了重要参考。
虚拟试穿、物体移动
AnyDoor 是一种基于扩散的图像生成器,可以在用户指定的位置将目标对象以和谐的方式传送到新场景中。我们的模型只需要训练一次,就可以轻松推广到不同的对象和场景组合中,无需为每个对象调整参数。为了充分描述某个特定对象,我们除了使用常用的身份特征外,还补充了细节特征,这些特征经过精心设计,既能保持纹理细节,又能允许多样的局部变化(如光照、方向、姿势等),从而使对象与不同的环境更好地融合。我们还提出从视频数据集中借用知识的方法,在视频数据集中可以观察到同一对象的各种形态(沿时间轴),从而增强模型的泛化能力和鲁棒性。大量实验证明了我们方法的优越性,以及它在虚拟试穿和物体移动等实际应用中的巨大潜力。
音乐生成系统,支持多语言声乐生成和音乐编辑。
Seed-Music 是一个音乐生成系统,它通过统一的框架支持生成具有表现力的多语言声乐音乐,允许精确到音符级别的调整,并提供将用户自己的声音融入音乐创作的能力。该系统采用先进的语言模型和扩散模型,为音乐家提供多样化的创作工具,满足不同音乐制作需求。
克隆你的声音,就像 Ctrl+C, Ctrl+V
Voicv是一个尖端的语音克隆平台,可在几分钟内将您的语音转换为数字资产,支持多种语言和零样本学习。该平台结合了先进的AI技术和用户友好的设计,提供专业级别的语音克隆能力。Voicv的主要优点包括零样本语音克隆、多语言支持、实时处理、高准确性、跨平台支持和企业级准备。产品背景信息显示,Voicv致力于通过其技术帮助内容创作者、配音演员等用户以多语言制作内容,同时保持个人品牌和声音特征。
强大的零样本语音转换和文本到语音WebUI
GPT-SoVITS-WebUI是一个强大的零样本语音转换和文本到语音WebUI。它具有零样本TTS、少样本TTS、跨语言支持和WebUI工具等功能。该产品支持英语、日语和中文,提供了集成工具,包括语音伴奏分离、自动训练集分割、中文ASR和文本标注,帮助初学者创建训练数据集和GPT/SoVITS模型。用户可以通过输入5秒的声音样本,即可体验即时的文本到语音转换,还可以通过仅使用1分钟的训练数据对模型进行微调,以提高语音相似度和逼真度。产品支持环境准备、Python和PyTorch版本、快速安装、手动安装、预训练模型、数据集格式、待办事项和致谢。

© 2026 AIbase 备案号:闽ICP备08105208号-14