swinir
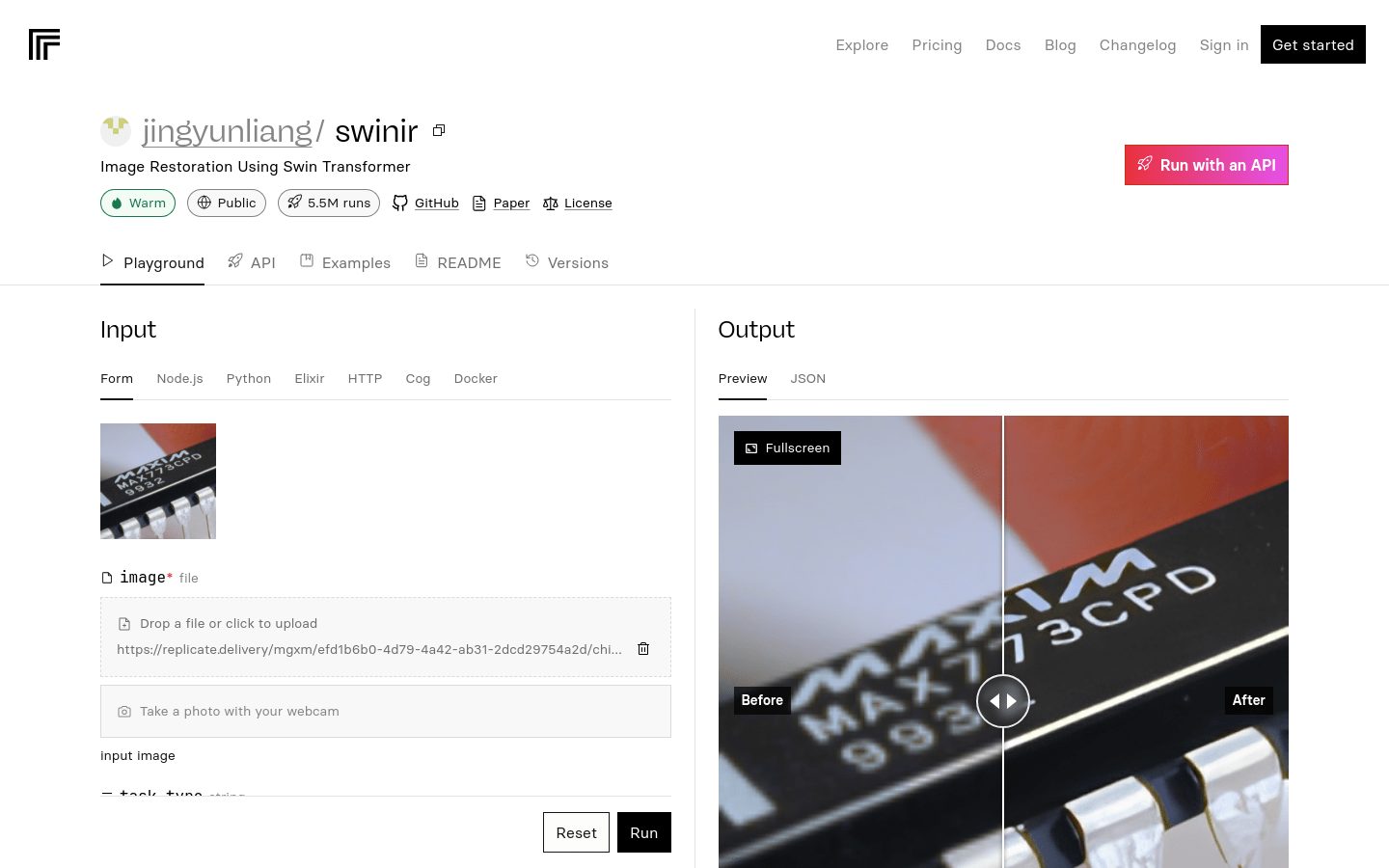
SwinIR 是一款基于 Swin Transformer 进行图像恢复的官方 PyTorch 实现,在经典、轻量级和真实世界图像超分辨率、灰度 / 彩色图像去噪以及 JPEG 压缩伪影去除等任务中取得了最先进的性能。它由浅层特征提取、深层特征提取和高质量图像重建组成,具有卓越的性能和参数优化。
需求人群:
"用于图像恢复任务,包括提高图像分辨率、去除噪音和压缩伪影。"
使用场景示例:
对低质量图像进行超分辨率处理。
去除图像中的噪音,提升图像质量。
减少 JPEG 压缩引起的伪影,改善图像细节。
产品特色:
经典、轻量级和真实世界图像超分辨率
灰度 / 彩色图像去噪
JPEG 压缩伪影去除
浏览量:155
最新流量情况
月访问量
2341.84k
平均访问时长
00:06:31
每次访问页数
6.54
跳出率
38.04%
流量来源
直接访问
57.28%
自然搜索
30.83%
邮件
0.05%
外链引荐
7.96%
社交媒体
3.59%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
巴西
5.06%
中国
3.86%
法国
3.99%
印度
8.45%
美国
16.79%
老照片修复 图片无损放大工具
SwinIR 是一款基于 Swin Transformer 进行图像恢复的官方 PyTorch 实现,在经典、轻量级和真实世界图像超分辨率、灰度 / 彩色图像去噪以及 JPEG 压缩伪影去除等任务中取得了最先进的性能。它由浅层特征提取、深层特征提取和高质量图像重建组成,具有卓越的性能和参数优化。
盲图像恢复技术,利用即时生成参考图像恢复破损图像
InstantIR是一种基于扩散模型的盲图像恢复方法,能够在测试时处理未知退化问题,提高模型的泛化能力。该技术通过动态调整生成条件,在推理过程中生成参考图像,从而提供稳健的生成条件。InstantIR的主要优点包括:能够恢复极端退化的图像细节,提供逼真的纹理,并且通过文本描述调节生成参考,实现创造性的图像恢复。该技术由北京大学、InstantX团队和香港中文大学的研究人员共同开发,得到了HuggingFace和fal.ai的赞助支持。
最新的图像上色算法
DDColor 是最新的图像上色算法,输入一张黑白图像,返回上色处理后的彩色图像,并能够实现自然生动的上色效果。 该模型为黑白图像上色模型,输入一张黑白图像,实现端到端的全图上色,返回上色处理后的彩色图像。 模型期望使用方式和适用范围: 该模型适用于多种格式的图像输入,给定黑白图像,生成上色后的彩色图像;给定彩色图像,将自动提取灰度通道作为输入,生成重上色的图像。
基于 Transformer 的图像识别模型
Google Vision Transformer 是一款基于 Transformer 编码器的图像识别模型,使用大规模图像数据进行预训练,可用于图像分类等任务。该模型在 ImageNet-21k 数据集上进行了预训练,并在 ImageNet 数据集上进行了微调,具备良好的图像特征提取能力。该模型通过将图像切分为固定大小的图像块,并线性嵌入这些图像块来处理图像数据。同时,模型在输入序列前添加了位置编码,以便在 Transformer 编码器中处理序列数据。用户可以通过在预训练的编码器之上添加线性层进行图像分类等任务。Google Vision Transformer 的优势在于其强大的图像特征学习能力和广泛的适用性。该模型免费提供使用。
使用生成扩散先验进行盲图像恢复
DiffBIR 是一种基于生成扩散先验的盲图像恢复模型。它通过两个阶段的处理来去除图像的退化,并细化图像的细节。DiffBIR 的优势在于提供高质量的图像恢复结果,并且具有灵活的参数设置,可以在保真度和质量之间进行权衡。该模型的使用是免费的。
AI图像增强与恢复工具
Enhance Images AI是一款先进的AI图像增强与恢复工具。通过先进的生成式AI技术,Enhance Images AI可以提供卓越的图像放大、图像增强和修复老照片的能力。让您的图像更清晰!
一种新的图像恢复算法
PMRF(Posterior-Mean Rectified Flow,后验均值修正流)是一种新提出的图像恢复算法,旨在解决图像恢复任务中的失真-感知质量权衡问题。它通过结合后验均值和修正流的方式,提出了一种新颖的图像恢复框架,能够在降低图像失真同时保证图像的感知质量。
更智能、更高效、更好用
悟空图像是国内一款可以替代AdobePhotoShop的专业图像处理软件,采用全新的设计理念和人工智能算法,让每个用户都能快速上手、快速出图。悟空图像不仅是国内首款支持50亿像素级超大图片处理,双向兼容PS文件格式,更支持全平台运行。悟空图像提供海量素材与模板,让你的创作不再从“0”开始;多达一百多种各类画笔,让创意设计更加得心应手;超多种组合特色功能,能够准确高效地实现用户办公需求。悟空图像圆你一个“创意设计大师”的梦,即使“0”基础,也能创作出专业级的效果!
基于Transformer的通用领域文本到图像生成
CogView是一个用于通用领域文本到图像生成的预训练Transformer模型。该模型包含410亿参数,能够生成高质量、多样化的图像。模型的训练思路采用抽象到具体的方式,先 pretrain 获得通用知识,然后 finetune 在特定域生成图像,能显著提升生成质量。值得一提的是,论文还提出了两种帮助大模型稳定训练的技巧:PB-relax 和 Sandwich-LN。
DA-CLIP的通用图像恢复
DA-CLIP是一种降级感知的视觉语言模型,可用作图像恢复的通用框架。它通过训练一个额外的控制器,使固定的CLIP图像编码器能够预测高质量的特征嵌入,并将其整合到图像恢复网络中,从而学习高保真度的图像重建。控制器本身还会输出与输入的真实损坏匹配的降级特征,为不同的降级类型提供自然的分类器。DA-CLIP还使用混合降级数据集进行训练,提高了特定降级和统一图像恢复任务的性能。
一种最小化均方误差的图像恢复算法
Posterior-Mean Rectified Flow(PMRF)是一种新颖的图像恢复算法,它通过优化后验均值和矫正流模型来最小化均方误差(MSE),同时保证图像的逼真度。PMRF算法简单而高效,其理论基础是将后验均值预测(最小均方误差估计)优化到与真实图像分布相匹配。该算法在图像恢复任务中表现出色,能够处理噪声、模糊等多种退化问题,并且具有较好的感知质量。
AI 图像生成进入 “毫秒级” 时代,速度快、质量高。
腾讯混元图像 2.0 是腾讯最新发布的 AI 图像生成模型,显著提升了生成速度和画质。通过超高压缩倍率的编解码器和全新扩散架构,使得图像生成速度可达到毫秒级,避免了传统生成的等待时间。同时,模型通过强化学习算法与人类美学知识的结合,提升了图像的真实感和细节表现,适合设计师、创作者等专业用户使用。
Masked Diffusion Transformer是图像合成的最新技术,为ICCV 2023的SOTA(State of the Art)
MDT通过引入掩码潜在模型方案来显式增强扩散概率模型(DPMs)在图像中对象部分之间关系学习的能力。MDT在训练期间在潜在空间中操作,掩蔽某些标记,然后设计一个不对称的扩散变换器来从未掩蔽的标记中预测掩蔽的标记,同时保持扩散生成过程。MDTv2进一步通过更有效的宏网络结构和训练策略提高了MDT的性能。
AI 图像擦除器,轻松删除照片中不需要的人、物体、文字和水印。
AI 图像擦除器是一款基于人工智能技术的工具,能够快速、简单地从照片中删除不需要的内容,提高照片的整体质量。该工具操作简便,免费使用,适用于个人和专业用户。
利用尖端AI技术,将创意转化为高质量图像。
Flux AI 图像生成器是由Black Forest Labs开发的,基于革命性的Flux系列模型,提供尖端的文本到图像技术。该产品通过其120亿参数的模型,能够精确解读复杂的文本提示,创造出多样化、高保真的图像。Flux AI 图像生成器不仅适用于个人艺术创作,也可用于商业应用,如品牌视觉、社交媒体内容等。它提供三种不同的版本以满足不同用户的需求:Flux Pro、Flux Dev和Flux Schnell。
AI生成图像鉴别挑战网站
AI判官是一个AI生成图像鉴别挑战的网站。它提供了普通模式、无尽模式和竞速模式三种游戏玩法。用户可以通过不同难度的游戏来提高自己分辨真实图片和AI生成图片的能力。该网站提供大量高质量的真实图片和AI生成图片作为判别素材。它的出现是对近期AI生成图片技术的一个回应,旨在提高公众的媒体识读能力。
深入理解Transformer模型的可视化工具
Transformer Explainer是一个致力于帮助用户深入理解Transformer模型的在线可视化工具。它通过图形化的方式展示了Transformer模型的各个组件,包括自注意力机制、前馈网络等,让用户能够直观地看到数据在模型中的流动和处理过程。该工具对于教育和研究领域具有重要意义,可以帮助学生和研究人员更好地理解自然语言处理领域的先进技术。
Recoverit是Windows和Mac的终极数据恢复软件,支持多种设备数据恢复。
Recoverit是由万兴科技(Wondershare)开发的一款功能强大的AI驱动的数据恢复软件,它能够帮助用户从硬盘、SD卡、USB驱动器、崩溃的PC和Mac设备中恢复删除的文件、照片、视频和文档等。其重要性在于为用户提供了在数据丢失情况下恢复数据的可靠手段,避免因数据丢失带来的损失。该软件具有操作简单、恢复成功率高、支持多种文件类型和存储设备等优点。价格方面提供免费下载版本,也有付费的高级版本可供选择,适用于个人用户、企业用户等有数据恢复需求的人群。
朱雀大模型检测,精准识别AI生成图像,助力内容真实性鉴别。
朱雀大模型检测是腾讯推出的一款AI检测工具,主要功能是检测图片是否由AI模型生成。它经过大量自然图片和生成图片的训练,涵盖摄影、艺术、绘画等内容,可检测多类主流文生图模型生成图片。该产品具有高精度检测、快速响应等优点,对于维护内容真实性、打击虚假信息传播具有重要意义。目前暂未明确其具体价格,但从功能来看,主要面向需要进行内容审核、鉴别真伪的机构和个人,如媒体、艺术机构等。
利用 AI 技术,一键从图片中提取设计元素。
AI 智能图像分割是一款基于 Figma 的插件,利用先进的 Segment Anything 模型 (SAM) 和 🤗 Transformers.js 技术,为设计师和艺术家提供了一个交互式和精确的图像分割工具。它通过点击交互的方式,简化了从图像中提取对象或区域的过程,极大提升了设计效率,释放了创造力。该插件免费使用且开源,允许用户自定义并为其开发做出贡献。
一种用于逆渲染的先进学习扩散先验方法,能够从任意图像中恢复物体材质并实现单视图图像重照明。
IntrinsicAnything 是一种先进的图像逆渲染技术,它通过学习扩散模型来优化材质恢复过程,解决了在未知静态光照条件下捕获的图像中物体材质恢复的问题。该技术通过生成模型学习材质先验,将渲染方程分解为漫反射和镜面反射项,利用现有丰富的3D物体数据进行训练,有效地解决了逆渲染过程中的歧义问题。此外,该技术还开发了一种从粗到细的训练策略,利用估计的材质引导扩散模型产生多视图一致性约束,从而获得更稳定和准确的结果。
在线AI图像增强器,无需注册下载,可将图像提升至4K并恢复细节。
该产品是一款在线AI图像增强器,其核心技术是利用人工智能算法对图像进行处理。重要性在于能够快速、高效地提升图像质量,节省用户时间和精力。主要优点包括无需注册和下载,操作简单便捷;可以将图像提升至4K分辨率,恢复图像细节。产品背景信息未提及,价格方面支持免费试用第一张照片,后续情况未提及。产品定位为满足用户对图像质量提升的需求,适用于各类需要处理图像的场景。
使用人工智能扩展图像边界
AI Image Extender 是一款利用人工智能技术扩展图像边界的工具,通过生成新内容与现有图像无缝融合,增强图像的视觉延展性。该产品通过先进的AI算法,能够智能识别图像内容并生成自然过渡的扩展区域,适用于需要图像扩展或背景生成的各种场景。
升级和恢复旧照片,生成高分辨率图形
Mimiko是一款应用,可以升级和恢复旧照片,根据您的输入操作图像,生成高分辨率图形。它还可以删除图片背景,从详细描述中生成图形,并从图像的特定方面获得答案。Mimiko提供了未来会有更多功能的承诺。
一种用于图像生成的模型。
IPAdapter-Instruct是Unity Technologies开发的一种图像生成模型,它通过在transformer模型上增加额外的文本嵌入条件,使得单一模型能够高效地执行多种图像生成任务。该模型主要优点在于能够通过'Instruct'提示,在同一工作流中灵活地切换不同的条件解释,例如风格转换、对象提取等,同时保持与特定任务模型相比的最小质量损失。
为 Diffusion Transformer 提供高效灵活的控制框架。
EasyControl 是一个为 Diffusion Transformer(扩散变换器)提供高效灵活控制的框架,旨在解决当前 DiT 生态系统中存在的效率瓶颈和模型适应性不足等问题。其主要优点包括:支持多种条件组合、提高生成灵活性和推理效率。该产品是基于最新研究成果开发的,适合在图像生成、风格转换等领域使用。
AI 图像修复工具
Lama Cleaner 是一个免费、开源的 AI 图像修复工具,基于最先进的 AI 模型。它可以删除图片中的任何不需要的物体、瑕疵或人物,也可以擦除和替换图片中的任何物体。该工具支持 CPU、GPU 和 M1/2,并提供多种 SOTA AI 模型可供选择。
面部恢复的多功能模型
PGDiff是一个多功能的面部恢复框架,适用于广泛的面部恢复任务,包括盲恢复、上色、修补、基于参考的恢复、旧照片恢复等。它使用指导扩散模型,通过部分指导来实现面部恢复。PGDiff的优势在于它的多功能性和适用性,可以应用于多种面部恢复任务。

© 2026 AIbase 备案号:闽ICP备08105208号-14