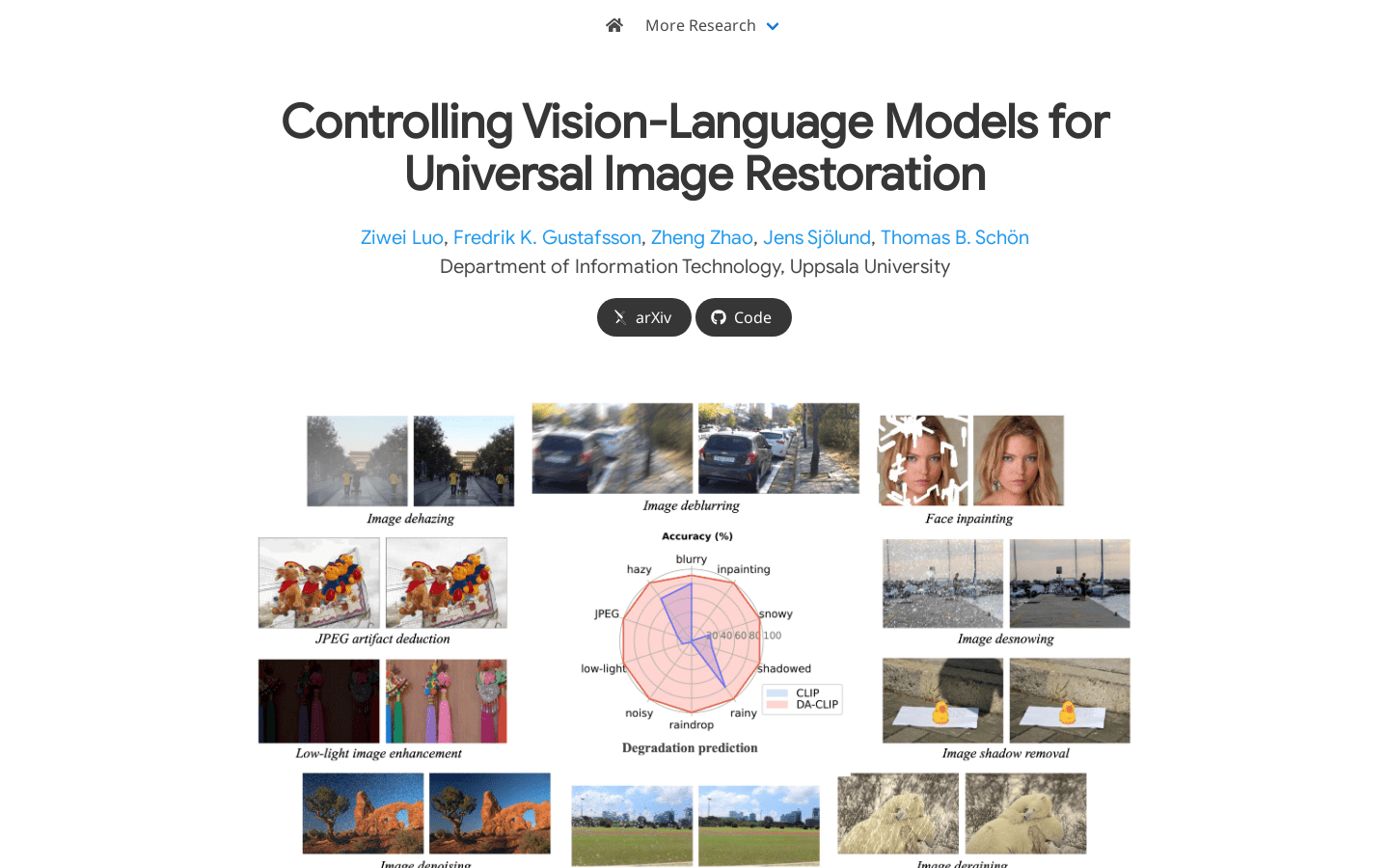
DA-CLIP是一种降级感知的视觉语言模型,可用作图像恢复的通用框架。它通过训练一个额外的控制器,使固定的CLIP图像编码器能够预测高质量的特征嵌入,并将其整合到图像恢复网络中,从而学习高保真度的图像重建。控制器本身还会输出与输入的真实损坏匹配的降级特征,为不同的降级类型提供自然的分类器。DA-CLIP还使用混合降级数据集进行训练,提高了特定降级和统一图像恢复任务的性能。
需求人群:
"DA-CLIP可用于图像恢复任务,特别是在处理损坏输入时,可以提高预测精度。"
使用场景示例:
使用DA-CLIP恢复受损的数字图像
使用DA-CLIP恢复受损的自然图像
使用DA-CLIP恢复受损的医学图像
产品特色:
通过训练一个额外的控制器,使固定的CLIP图像编码器能够预测高质量的特征嵌入
将特征嵌入整合到图像恢复网络中,学习高保真度的图像重建
输出与输入的真实损坏匹配的降级特征,为不同的降级类型提供自然的分类器
使用混合降级数据集进行训练,提高了特定降级和统一图像恢复任务的性能
浏览量:169
最新流量情况
月访问量
753
平均访问时长
00:00:00
每次访问页数
1.03
跳出率
42.30%
流量来源
直接访问
37.80%
自然搜索
33.49%
邮件
0.15%
外链引荐
18.54%
社交媒体
8.21%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
巴西
6.12%
哥伦比亚
4.32%
土耳其
5.43%
美国
84.13%
DA-CLIP的通用图像恢复
DA-CLIP是一种降级感知的视觉语言模型,可用作图像恢复的通用框架。它通过训练一个额外的控制器,使固定的CLIP图像编码器能够预测高质量的特征嵌入,并将其整合到图像恢复网络中,从而学习高保真度的图像重建。控制器本身还会输出与输入的真实损坏匹配的降级特征,为不同的降级类型提供自然的分类器。DA-CLIP还使用混合降级数据集进行训练,提高了特定降级和统一图像恢复任务的性能。
盲图像恢复技术,利用即时生成参考图像恢复破损图像
InstantIR是一种基于扩散模型的盲图像恢复方法,能够在测试时处理未知退化问题,提高模型的泛化能力。该技术通过动态调整生成条件,在推理过程中生成参考图像,从而提供稳健的生成条件。InstantIR的主要优点包括:能够恢复极端退化的图像细节,提供逼真的纹理,并且通过文本描述调节生成参考,实现创造性的图像恢复。该技术由北京大学、InstantX团队和香港中文大学的研究人员共同开发,得到了HuggingFace和fal.ai的赞助支持。
强大的开源视觉语言模型
CogVLM是一个强大的开源视觉语言模型。CogVLM-17B拥有100亿个视觉参数和70亿个语言参数。CogVLM-17B在10个经典的跨模态基准测试中取得了最先进的性能,包括NoCaps、Flicker30k字幕、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA和TDIUC,并在VQAv2、OKVQA、TextVQA、COCO字幕等方面排名第二,超过或与PaLI-X 55B相匹配。CogVLM还可以与您就图像进行对话。
视觉状态空间模型,线性复杂度,全局感知
VMamba是一种视觉状态空间模型,结合了卷积神经网络(CNNs)和视觉Transformer(ViTs)的优势,实现了线性复杂度而不牺牲全局感知。引入了Cross-Scan模块(CSM)来解决方向敏感问题,能够在各种视觉感知任务中展现出优异的性能,并且随着图像分辨率的增加,相对已有基准模型表现出更为显著的优势。
8亿参数的多语言视觉语言模型,支持OCR、图像描述、视觉推理等功能
CohereForAI的Aya Vision 8B是一个8亿参数的多语言视觉语言模型,专为多种视觉语言任务优化,支持OCR、图像描述、视觉推理、总结、问答等功能。该模型基于C4AI Command R7B语言模型,结合SigLIP2视觉编码器,支持23种语言,具有16K上下文长度。其主要优点包括多语言支持、强大的视觉理解能力以及广泛的适用场景。该模型以开源权重形式发布,旨在推动全球研究社区的发展。根据CC-BY-NC许可协议,用户需遵守C4AI的可接受使用政策。
使用生成扩散先验进行盲图像恢复
DiffBIR 是一种基于生成扩散先验的盲图像恢复模型。它通过两个阶段的处理来去除图像的退化,并细化图像的细节。DiffBIR 的优势在于提供高质量的图像恢复结果,并且具有灵活的参数设置,可以在保真度和质量之间进行权衡。该模型的使用是免费的。
多模态视觉语言模型
MouSi是一种多模态视觉语言模型,旨在解决当前大型视觉语言模型(VLMs)面临的挑战。它采用集成专家技术,将个体视觉编码器的能力进行协同,包括图像文本匹配、OCR、图像分割等。该模型引入融合网络来统一处理来自不同视觉专家的输出,并在图像编码器和预训练LLMs之间弥合差距。此外,MouSi还探索了不同的位置编码方案,以有效解决位置编码浪费和长度限制的问题。实验结果表明,具有多个专家的VLMs表现出比孤立的视觉编码器更出色的性能,并随着整合更多专家而获得显著的性能提升。
连接不同语言模型和生成视觉模型进行文本到图像生成
LaVi-Bridge是一种针对文本到图像扩散模型设计的桥接模型,能够连接各种预训练的语言模型和生成视觉模型。它通过利用LoRA和适配器,提供了一种灵活的插拔式方法,无需修改原始语言和视觉模型的权重。该模型与各种语言模型和生成视觉模型兼容,可容纳不同的结构。在这一框架内,我们证明了通过整合更高级的模块(如更先进的语言模型或生成视觉模型)可以明显提高文本对齐或图像质量等能力。该模型经过大量评估,证实了其有效性。
一款强大的小型视觉语言模型,无处不在
moondream是一个使用SigLIP、Phi-1.5和LLaVA训练数据集构建的16亿参数模型。由于使用了LLaVA数据集,权重受CC-BY-SA许可证保护。您可以在Huggingface Spaces上尝试使用它。该模型在VQAv2、GQA、VizWiz和TextVQA基准测试中表现如下:LLaVA-1.5(13.3B参数):80.0、63.3、53.6、61.3;LLaVA-1.5(7.3B参数):78.5、62.0、50.0、58.2;MC-LLaVA-3B(3B参数):64.2、49.6、24.9、38.6;LLaVA-Phi(3B参数):71.4、-、35.9、48.6;moondream1(1.6B参数):74.3、56.3、30.3、39.8。
PaliGemma 2是一个强大的视觉-语言模型,支持多种视觉语言任务。
PaliGemma 2是一个由Google开发的视觉-语言模型,继承了Gemma 2模型的能力,能够处理图像和文本输入并生成文本输出。该模型在多种视觉语言任务上表现出色,如图像描述、视觉问答等。其主要优点包括强大的多语言支持、高效的训练架构和广泛的适用性。该模型适用于需要处理视觉和文本数据的各种应用场景,如社交媒体内容生成、智能客服等。
一款AI视觉语言模型,提供图像分析和描述服务。
InternVL是一个AI视觉语言模型,专注于图像分析和描述。它通过深度学习技术,能够理解和解释图像内容,为用户提供准确的图像描述和分析结果。InternVL的主要优点包括高准确性、快速响应和易于集成。该技术背景基于最新的人工智能研究,致力于提高图像识别的效率和准确性。目前,InternVL提供免费试用,具体价格和定位需要根据用户需求定制。
自由形式文本图像合成与理解的视觉语言大模型
InternLM-XComposer2是一款领先的视觉语言模型,擅长自由形式文本图像合成与理解。该模型不仅能够理解传统的视觉语言,还能熟练地从各种输入中构建交织的文本图像内容,如轮廓、详细的文本规范和参考图像,实现高度可定制的内容创作。InternLM-XComposer2提出了一种部分LoRA(PLoRA)方法,专门将额外的LoRA参数应用于图像标记,以保留预训练语言知识的完整性,实现精确的视觉理解和具有文学才能的文本构成之间的平衡。实验结果表明,基于InternLM2-7B的InternLM-XComposer2在生成高质量长文本多模态内容方面优越,以及在各种基准测试中其出色的视觉语言理解性能,不仅明显优于现有的多模态模型,还在某些评估中与甚至超过GPT-4V和Gemini Pro。这凸显了它在多模态理解领域的卓越能力。InternLM-XComposer2系列模型具有7B参数,可在https://github.com/InternLM/InternLM-XComposer 上公开获取。
通用型视觉语言模型
Qwen-VL 是阿里云推出的通用型视觉语言模型,具有强大的视觉理解和多模态推理能力。它支持零样本图像描述、视觉问答、文本理解、图像地标定位等任务,在多个视觉基准测试中达到或超过当前最优水平。该模型采用 Transformer 结构,以 7B 参数规模进行预训练,支持 448x448 分辨率,可以端到端处理图像与文本的多模态输入与输出。Qwen-VL 的优势包括通用性强、支持多语种、细粒度理解等。它可以广泛应用于图像理解、视觉问答、图像标注、图文生成等任务。
Google的尖端开放视觉语言模型
PaliGemma是Google发布的一款先进的视觉语言模型,它结合了图像编码器SigLIP和文本解码器Gemma-2B,能够理解图像和文本,并通过联合训练实现图像和文本的交互理解。该模型专为特定的下游任务设计,如图像描述、视觉问答、分割等,是研究和开发领域的重要工具。
先进多模态大型语言模型系列
InternVL 2.5是一系列先进的多模态大型语言模型(MLLM),在InternVL 2.0的基础上,通过引入显著的训练和测试策略增强以及数据质量提升,进一步发展而来。该模型系列在视觉感知和多模态能力方面进行了优化,支持包括图像、文本到文本的转换在内的多种功能,适用于需要处理视觉和语言信息的复杂任务。
先进的视觉基础模型,支持多种视觉和视觉-语言任务
Florence-2是由微软开发的高级视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示,执行诸如图像描述、目标检测和分割等任务。它利用FLD-5B数据集,包含54亿个注释,覆盖1.26亿张图像,精通多任务学习。其序列到序列的架构使其在零样本和微调设置中均表现出色,证明是一个有竞争力的视觉基础模型。
视觉语言模型,结合图像和文本信息进行智能处理。
Aquila-VL-2B模型是一个基于LLava-one-vision框架训练的视觉语言模型(VLM),选用Qwen2.5-1.5B-instruct模型作为语言模型(LLM),并使用siglip-so400m-patch14-384作为视觉塔。该模型在自建的Infinity-MM数据集上进行训练,包含约4000万图像-文本对。该数据集结合了从互联网收集的开源数据和使用开源VLM模型生成的合成指令数据。Aquila-VL-2B模型的开源,旨在推动多模态性能的发展,特别是在图像和文本的结合处理方面。
AI图像增强与恢复工具
Enhance Images AI是一款先进的AI图像增强与恢复工具。通过先进的生成式AI技术,Enhance Images AI可以提供卓越的图像放大、图像增强和修复老照片的能力。让您的图像更清晰!
基于强化学习技术的视觉思考模型,理科测试行业领先
Kimi视觉思考模型k1是基于强化学习技术打造的AI模型,原生支持端到端图像理解和思维链技术,并将能力扩展到数学之外的更多基础科学领域。在数学、物理、化学等基础科学学科的基准能力测试中,k1模型的表现超过了全球标杆模型。k1模型的发布标志着AI在视觉理解和思考能力上的新突破,尤其在处理图像信息和基础科学问题上展现出色的表现。
PaliGemma 2是一款强大的视觉-语言模型,支持多种语言的图像和文本处理任务。
PaliGemma 2是由Google开发的视觉-语言模型,它结合了SigLIP视觉模型和Gemma 2语言模型的能力,能够处理图像和文本输入,并生成相应的文本输出。该模型在多种视觉-语言任务上表现出色,如图像描述、视觉问答等。其主要优点包括强大的多语言支持、高效的训练架构以及在多种任务上的优异性能。PaliGemma 2的开发背景是为了解决视觉和语言之间的复杂交互问题,帮助研究人员和开发者在相关领域取得突破。
PaLI-3 视觉语言模型:更小、更快、更强
Pali3是一种视觉语言模型,通过对图像进行编码并与查询一起传递给编码器-解码器Transformer来生成所需的答案。该模型经过多个阶段的训练,包括单模态预训练、多模态训练、分辨率增加和任务专业化。Pali3的主要功能包括图像编码、文本编码、文本生成等。该模型适用于图像分类、图像字幕、视觉问答等任务。Pali3的优势在于模型结构简单、训练效果好、速度快。该产品定价为免费开源。
面部恢复的多功能模型
PGDiff是一个多功能的面部恢复框架,适用于广泛的面部恢复任务,包括盲恢复、上色、修补、基于参考的恢复、旧照片恢复等。它使用指导扩散模型,通过部分指导来实现面部恢复。PGDiff的优势在于它的多功能性和适用性,可以应用于多种面部恢复任务。
高效的视觉编码技术,提升视觉语言模型性能。
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
基于感知损失的扩散模型
该论文介绍了一种基于感知损失的扩散模型,通过将感知损失直接纳入扩散训练中来提高样本质量。对于有条件生成,该方法仅改善样本质量而不会影响条件输入,因此不会牺牲样本多样性。对于无条件生成,这种方法也能提高样本质量。论文详细介绍了方法的原理和实验结果。
视觉语言模型的最新进展
POINTS-Qwen-2-5-7B-Chat是一个集成了视觉语言模型最新进展和新技巧的模型,由微信AI的研究人员提出。它通过预训练数据集筛选、模型汤等技术,显著提升了模型性能。这个模型在多个基准测试中表现优异,是视觉语言模型领域的一个重要进步。
一种新的图像恢复算法
PMRF(Posterior-Mean Rectified Flow,后验均值修正流)是一种新提出的图像恢复算法,旨在解决图像恢复任务中的失真-感知质量权衡问题。它通过结合后验均值和修正流的方式,提出了一种新颖的图像恢复框架,能够在降低图像失真同时保证图像的感知质量。
先进的大型混合专家视觉语言模型
DeepSeek-VL2是一系列先进的大型混合专家(MoE)视觉语言模型,相较于前代DeepSeek-VL有显著提升。该模型系列在视觉问答、光学字符识别、文档/表格/图表理解、视觉定位等多项任务中展现出卓越的能力。DeepSeek-VL2由三种变体组成:DeepSeek-VL2-Tiny、DeepSeek-VL2-Small和DeepSeek-VL2,分别拥有1.0B、2.8B和4.5B激活参数。DeepSeek-VL2在激活参数相似或更少的情况下,与现有的开源密集型和基于MoE的模型相比,达到了竞争性或最先进的性能。

© 2026 AIbase 备案号:闽ICP备08105208号-14