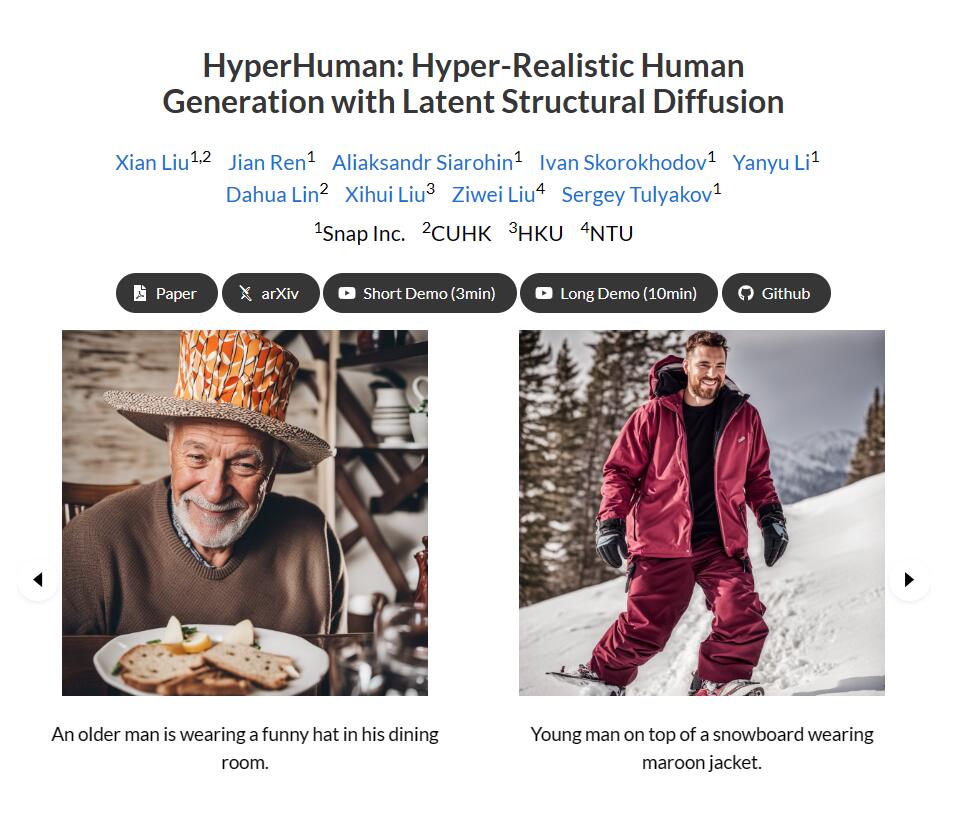
HyperHuman是一个生成逼真的人类图像的模型。该模型通过捕捉人类图像的结构性特征,从粗略的身体骨架到细粒度的空间几何形状,生成具有连贯性和自然性的人类图像。HyperHuman包括三个部分:1)构建一个大规模的人类数据集HumanVerse,其中包含340M张图像和全面的注释,如人体姿势、深度和表面法线;2)提出一个潜在结构扩散模型,该模型同时去噪深度、表面法线和合成的RGB图像。我们的模型在一个统一的网络中强制学习图像外观、空间关系和几何形状,模型中的每个分支都具有结构感知性和纹理丰富性;3)最后,为了进一步提高视觉质量,我们提出了一个结构引导的细化器,用于更详细的高分辨率生成。大量实验证明,我们的模型在各种场景下生成了具有高真实感和多样性的人类图像,达到了最先进的性能。
需求人群:
"HyperHuman可用于生成逼真的人类图像,例如在游戏、电影、虚拟现实等领域中。"
使用场景示例:
HyperHuman可用于游戏中的人物角色生成。
HyperHuman可用于电影中的特效制作。
HyperHuman可用于虚拟现实中的人类形象生成。
产品特色:
生成逼真的人类图像
捕捉人类图像的结构性特征
生成具有连贯性和自然性的人类图像
构建一个大规模的人类数据集
去噪深度、表面法线和合成的RGB图像
强制学习图像外观、空间关系和几何形状
提高视觉质量
生成高分辨率的图像
浏览量:253
最新流量情况
月访问量
19.08k
平均访问时长
00:00:27
每次访问页数
1.58
跳出率
46.23%
流量来源
直接访问
34.90%
自然搜索
45.46%
邮件
0.06%
外链引荐
10.22%
社交媒体
8.61%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
德国
8.17%
印度
7.66%
新加坡
22.38%
美国
33.34%
越南
7.26%
生成逼真的人类图像
HyperHuman是一个生成逼真的人类图像的模型。该模型通过捕捉人类图像的结构性特征,从粗略的身体骨架到细粒度的空间几何形状,生成具有连贯性和自然性的人类图像。HyperHuman包括三个部分:1)构建一个大规模的人类数据集HumanVerse,其中包含340M张图像和全面的注释,如人体姿势、深度和表面法线;2)提出一个潜在结构扩散模型,该模型同时去噪深度、表面法线和合成的RGB图像。我们的模型在一个统一的网络中强制学习图像外观、空间关系和几何形状,模型中的每个分支都具有结构感知性和纹理丰富性;3)最后,为了进一步提高视觉质量,我们提出了一个结构引导的细化器,用于更详细的高分辨率生成。大量实验证明,我们的模型在各种场景下生成了具有高真实感和多样性的人类图像,达到了最先进的性能。
生成高质量逼真图像的文本到图像技术
Imagen 2 是我们最先进的文本到图像扩散技术,可生成与用户提示密切对齐且一致的高质量逼真图像。它通过使用训练数据的自然分布生成更加逼真的图像,而不是采用预先编程的风格。Imagen 2 强大的文本到图像技术通过 Google Cloud Vertex AI 的 Imagen API 为开发者和云客户提供支持。Google Arts and Culture 团队还在其文化标志实验中部署了我们的 Imagen 2 技术,使用户可以通过 Google AI 探索、学习和测试其文化知识。
高质量逼真AI头像
RAVATAR是一款利用先进的生成AI技术生产高质量逼真头像的产品。通过使用合成数据,我们可以根据现有的音频和视频样本参考重现任何人的虚拟形象。RAVATAR的头像具有多样性和适用性,可以广泛应用于各种场景。定价请咨询官方网站,定位于数字人类市场。
高质量图像修复,根据人类指示进行优化
InstructIR 接受图像和人类书写的指令作为输入,通过单一神经模型执行一体化图像修复。在多个修复任务中取得了最先进的结果,包括图像去噪、去雨、去模糊、去雾以及低光图像增强等。🚀 您可以从演示教程开始。查看我们的 GitHub 获取更多信息。 免责声明:请注意,这不是一个产品,因此您会注意到一些限制。此演示需要输入具有某些降级的图像(模糊、噪音、雨、低光、雾)和一个提示,请求应该执行什么操作。由于 GPU 内存限制,如果输入高分辨率图像(2K、4K),应用可能会崩溃。 该模型主要使用合成数据进行训练,因此在真实世界复杂图像上可能效果不佳。然而,在真实世界的雾天和低光图像上效果出奇地好。您还可以尝试一般的图像增强提示(例如,“润色此图像”,“增强颜色”)并查看它如何改善颜色。
AI角色引擎,为AI NPC提供复杂逼真的人类行为
Inworld是AI和游戏领域最资深的初创公司,通过协调多个模型模拟人类行为,为AI NPC提供复杂逼真的人类行为,增加玩家的参与度。Inworld是AI NPC的最先进引擎,通过组合多模态的角色表达,模仿人类行为。
朱雀大模型检测,精准识别AI生成图像,助力内容真实性鉴别。
朱雀大模型检测是腾讯推出的一款AI检测工具,主要功能是检测图片是否由AI模型生成。它经过大量自然图片和生成图片的训练,涵盖摄影、艺术、绘画等内容,可检测多类主流文生图模型生成图片。该产品具有高精度检测、快速响应等优点,对于维护内容真实性、打击虚假信息传播具有重要意义。目前暂未明确其具体价格,但从功能来看,主要面向需要进行内容审核、鉴别真伪的机构和个人,如媒体、艺术机构等。
最新的图像上色算法
DDColor 是最新的图像上色算法,输入一张黑白图像,返回上色处理后的彩色图像,并能够实现自然生动的上色效果。 该模型为黑白图像上色模型,输入一张黑白图像,实现端到端的全图上色,返回上色处理后的彩色图像。 模型期望使用方式和适用范围: 该模型适用于多种格式的图像输入,给定黑白图像,生成上色后的彩色图像;给定彩色图像,将自动提取灰度通道作为输入,生成重上色的图像。
基于 DiT 的人类图像动画框架,实现精细控制与长效一致性。
DreamActor-M1 是一个基于扩散变换器 (DiT) 的人类动画框架,旨在实现细粒度的整体可控性、多尺度适应性和长期时间一致性。该模型通过混合引导,能够生成高表现力和真实感的人类视频,适用于从肖像到全身动画的多种场景。其主要优势在于高保真度和身份保留,为人类行为动画带来了新的可能性。
语音到语音翻译系统,保留声音和等时性特征
TransVIP是由微软研究院开发的一个创新的语音到语音翻译系统,它能够在翻译过程中保留说话者的声音特征和等时性(即说话的节奏和停顿),这对于视频配音等场景非常有用。TransVIP通过联合概率实现端到端的推理,同时利用不同的数据集进行级联处理。该技术的主要优点包括高适应性、声音特征保留以及等时性保持,这使得它在多语言交流和内容本地化领域具有重要价值。
3D形状的文本驱动逼真材质绘制
MaPa是一种创新的方法,能够根据文本描述为3D网格生成材质。该技术通过创建分段的程序化材质图来表示外观,支持高质量渲染,并在编辑上提供了显著的灵活性。利用预训练的2D扩散模型,MaPa在不需要大量配对数据的情况下,架起了文本描述和材质图之间的桥梁。该技术通过分解形状为多个部分,并设计了控制段的扩散模型来合成与网格部分对齐的2D图像,进而初始化材质图的参数,并通过可微分渲染模块进行微调,以产生符合文本描述的材质。广泛的实验表明,MaPa在逼真度、分辨率和可编辑性方面优于现有技术。
评估图像生成模型在不同地理区域的质量、多样性和一致性。
DIG-In是一个用于评估文本到图像生成模型在不同地理区域中质量、多样性和一致性差异的库。它使用GeoDE和DollarStreet作为参考数据集,通过计算生成图像的相关特征和精度、覆盖度指标,以及使用CLIPScore指标来衡量模型的表现。该库支持研究人员和开发者对图像生成模型进行地理多样性的审计,以确保其在全球范围内的公平性和包容性。
探索Flux模型在亚洲女性形象上的适应性。
Flux1.dev-AsianFemale是一个基于Flux.1 D模型的LoRA(Low-Rank Adaptation)实验性模型,旨在探索通过训练使Flux模型的默认女性形象更趋向亚洲人的外貌特征。该模型未经面部美化或网络名人脸训练,具有实验性质,可能存在一些训练上的问题和挑战。
AI声音合成,高质量,逼真
SteosVoice(以前称为CyberVoice)是人工智能的声带,具有超高质量的逼真语音合成。它适用于创作者、视频制作、游戏开发、模组制作、播客、有声读物等领域。它提供超过150种不同的声音,每天生成超过25小时的音频。用户可以使用SteosVoice创造独特的内容,为视频配音、向赞助者发送语音消息、制作播客、为模组和游戏添加声音等。SteosVoice还提供付费计划,于2023年1月9日重新开放。
为需要的人生成图像的描述性替代文本
GenAlt生成在线图像的描述性替代文本,为那些需要的人提供帮助。只需右键单击图像,然后单击“从GenAlt获取替代文本”,即可获得图像的描述作为其替代文本。要查看生成的标题并将其复制到剪贴板上,只需选择“从GenAlt复制AI图像描述”。用户的一些GenAlt见证如下: 1. “GenAlt对我理解照片很有帮助......比现有工具好。”——无障碍倡导者和Twitch主播 2. “GenAlt真的比互联网上的其他应用程序更有帮助,帮助我更好地描述图片。”——高中二年级学生Remi 3. “GenAlt易于使用,有助于让社交媒体对我更具可访问性。”——大学新生Aaron
真实人类舞蹈视频生成
MagicDance是一种新颖有效的方法,可以生成逼真的人类视频,实现生动的动作和面部表情转移,以及一致的2D卡通风格动画零调优生成。通过MagicDance,我们可以精确生成外观一致的结果,而原始的T2I模型(如稳定扩散和ControlNet)很难准确地保持主题身份信息。此外,我们提出的模块可以被视为原始T2I模型的扩展/插件,而不需要修改其预训练权重。
检测设备是否能运行不同规模的 DeepSeek 模型,提供兼容性预测。
DeepSeek 模型兼容性检测是一个用于评估设备是否能够运行不同规模 DeepSeek 模型的工具。它通过检测设备的系统内存、显存等配置,结合模型的参数量、精度位数等信息,为用户提供模型运行的预测结果。该工具对于开发者和研究人员在选择合适的硬件资源以部署 DeepSeek 模型时具有重要意义,能够帮助他们提前了解设备的兼容性,避免因硬件不足而导致的运行问题。DeepSeek 模型本身是一种先进的深度学习模型,广泛应用于自然语言处理等领域,具有高效、准确的特点。通过该检测工具,用户可以更好地利用 DeepSeek 模型进行项目开发和研究。
个性化图像复原,保留面部特征
本文提出了一种简单有效的个性化图像复原方法,名为双枢纽调谐。该方法包含两个步骤:1) 通过微调条件性生成模型来利用编码器中的条件信息进行个性化;2) 固定生成模型,调节编码器的参数以适应强化的个性化先验。这可以生成保留个性化面部特征以及图像退化属性的自然图像。实验证明,与非个性化方法相比,该方法可以生成更高保真度的面部图像。
基于InternViT-300M-448px的增强版本,提升视觉特征提取能力。
InternViT-300M-448px-V2_5是一个基于InternViT-300M-448px的增强版本,通过采用ViT增量学习与NTP损失(Stage 1.5),提升了视觉编码器提取视觉特征的能力,尤其是在大规模网络数据集中代表性不足的领域,如多语言OCR数据和数学图表等。该模型是InternViT 2.5系列的一部分,保留了与前代相同的“ViT-MLP-LLM”模型架构,并集成了新的增量预训练的InternViT与各种预训练的LLMs,如InternLM 2.5和Qwen 2.5,使用随机初始化的MLP投影器。
Lumalabs AI从文本和图像快速生成高质量、逼真视频的AI模型
Lumalabs AI的Dream Machine是一个AI模型,能够直接从文本和图像快速生成高质量的逼真视频。它是一个高度可扩展且高效的transformer模型,专门针对视频进行训练,能够生成物理上准确、一致且充满事件的镜头。Dream Machine是构建通用想象力引擎的第一步,现已对所有人开放。
AI创造性视觉的突破性AI
Stable Diffusion 3是Stability AI推出的最新创新,为创造性图像生成带来突破性的AI。它提供了改进的文本到图像生成算法、多模态能力和用户友好的许可证,免费使用SDXLTurbo.ai。革新设计、动画、游戏等领域,提升文本到图像生成、多模态能力和用户友好的许可证。探索、创造、转化。
训练无监督一致性文本到图像生成
ConsiStory是一个无需训练就能实现在预训练的文本到图像模型中生成一致性主体的方法。它不需要微调或个性化,因此比先前最优方法快20倍。我们通过引入以主体为驱动的共享注意力模块和基于对应关系的特征注入来增强模型,以促进图像之间的主体一致性。另外,我们开发了在保持主体一致性的同时鼓励布局多样性的策略。ConsiStory可以自然地扩展到多主体场景,甚至可以实现对常见对象的无需训练的个性化。
从单张 RGB 图像生成多个逼真的 3D 人体重建
DiffHuman 是一种概率性的光度逼真的 3D 人体重建方法。它可以从单张 RGB 图像预测一个 3D 人体重建的概率分布,并通过迭代降噪采样多个细节丰富、色彩鲜明的 3D 人体模型。与现有的确定性方法相比,DiffHuman 在未知或不确定区域能生成更加细节丰富的重建结果。同时,我们还引入了一个加速渲染的生成网络,大幅提高了推理速度。
AI内容检测工具,确保原创性和真实性。
AI Detector是一个提供AI内容检测和AI图像检测的网站工具,它使用先进的AI算法来识别文本和图像是否由人工智能生成。该工具强调内容原创性验证、安全性和准确性,适用于作家、教育工作者和专业人士,帮助他们确保其内容和视觉内容的原创性和真实性。
提供干净的视觉特征
去噪视觉变换器(Denoising Vision Transformers,DVT)是一种针对视觉变换器(ViTs)的新型噪声模型。通过解剖ViT输出并引入可学习的去噪器,DVT能够提取无噪声的特征,从而在离线应用和在线功能中显著改善基于Transformer的模型的性能。DVT不需要重新训练现有的预训练ViTs,可立即应用于任何基于Transformer的架构。通过在多个数据集上进行广泛评估,我们发现DVT在语义和几何任务中持续显著改善现有的最先进通用模型(例如,+3.84 mIoU)。我们希望我们的研究能够鼓励重新评估ViT设计,特别是关于位置嵌入的天真使用。
前沿文本到图像模型,生成逼真图像。
Ideogram 2.0 是一款前沿的文本到图像模型,具备生成逼真图像、平面设计、排版等能力。它从零开始训练,显著优于其他文本到图像模型,在图像文本对齐、整体主观偏好和文本渲染准确性等多个质量指标上表现突出。Ideogram 2.0 还推出了iOS应用,将高端平台带到移动用户手中,并通过API以极具竞争力的价格为开发者提供技术,以增强他们的应用和工作流程。
利用Flux进行图像细节增强的实验性工具
Flux Latent Detailer是一个实验性的工具,通过Flux的潜在空间插值技术,能够在图像中产生更精细的细节。该工具通过多遍处理,尝试在不破坏整体构图的情况下增强图像细节,同时避免过度处理的外观。开发者强调这是一个实验性项目,不提供支持,仅供分享。

© 2026 AIbase 备案号:闽ICP备08105208号-14