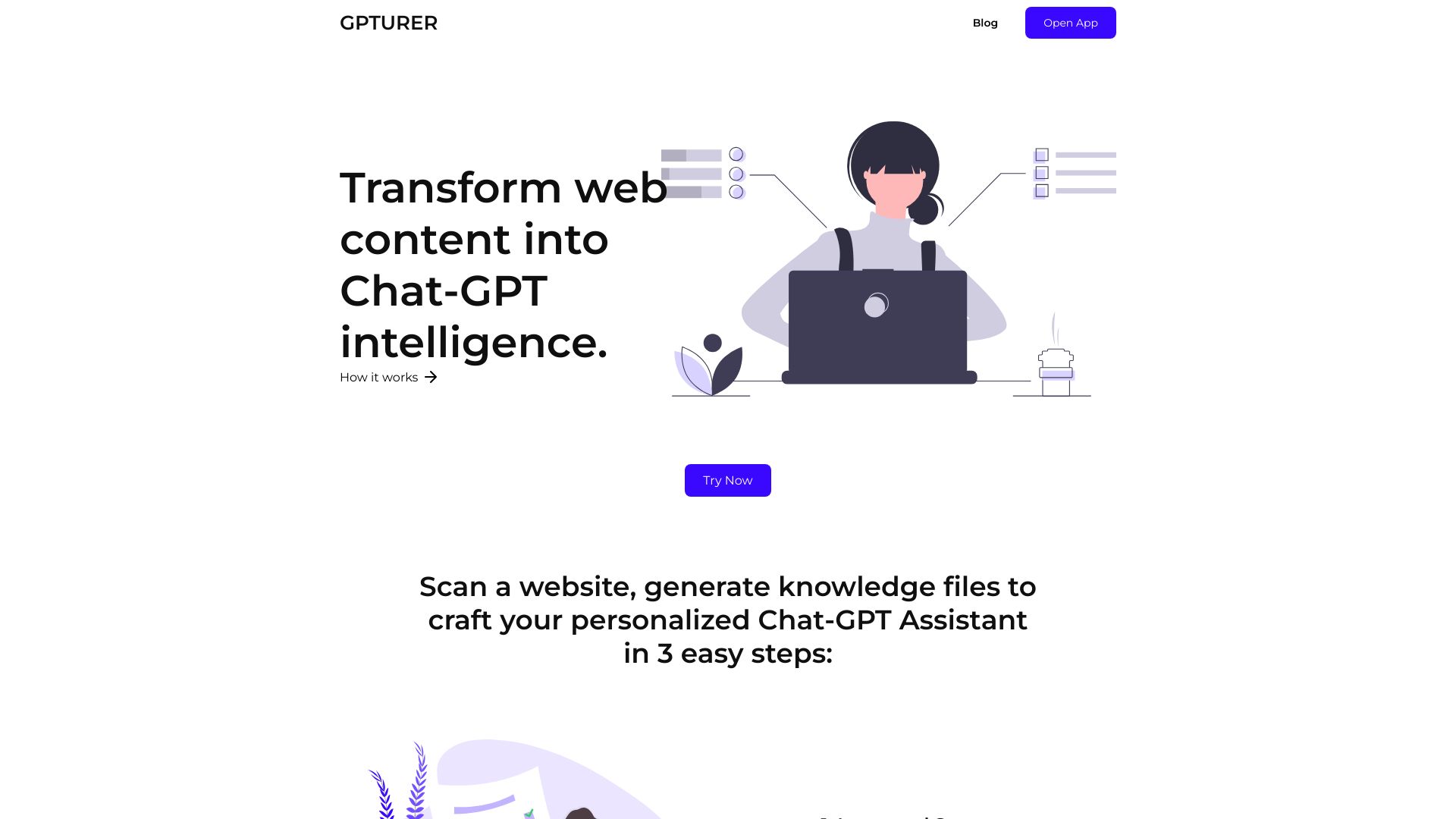
GPTURER是一个简单易用的解决方案,通过扫描网站来生成全面的知识数据集。只需两个步骤即可简化ChatGPT助手的创建:创建一个网站扫描任务,并下载集成的知识数据。使用GPTURER,您可以输入网站URL,让我们的系统仔细浏览和提取必要的数据,包括文本、图片、URL和结构元素。当我们的系统仔细扫描网站时,它会将提取的数据编译成结构化的输出文件,一旦扫描完成,您就可以立即下载这些文件。利用这些生成的输出文件作为基础,轻松创建个性化的ChatGPT助手,无缝嵌入提取的内容,以增强其功能。我们提供三种定价方案,Starter(€5)、Basic(€20)和Premium(€50),根据您的需求选择合适的套餐。GPTURER能够将网页内容转换为Chat GPT智能,为您提供更强大的助手功能。
需求人群:
用于创建个性化Chat GPT助手
使用场景示例:
将新闻网站转换为聊天机器人助手
将产品文档网站转换为智能问答助手
将维基百科页面转换为语义搜索助手
产品特色:
将网页内容转换为Chat GPT智能
提取文本、图片、URL和结构元素
生成结构化的输出文件
浏览量:45
最新流量情况
月访问量
3494
平均访问时长
00:00:00
每次访问页数
1.25
跳出率
87.29%
流量来源
直接访问
0
自然搜索
0
邮件
0
外链引荐
0
社交媒体
0
展示广告
0
截止目前所有流量趋势图
将网页内容转换为Chat GPT智能
GPTURER是一个简单易用的解决方案,通过扫描网站来生成全面的知识数据集。只需两个步骤即可简化ChatGPT助手的创建:创建一个网站扫描任务,并下载集成的知识数据。使用GPTURER,您可以输入网站URL,让我们的系统仔细浏览和提取必要的数据,包括文本、图片、URL和结构元素。当我们的系统仔细扫描网站时,它会将提取的数据编译成结构化的输出文件,一旦扫描完成,您就可以立即下载这些文件。利用这些生成的输出文件作为基础,轻松创建个性化的ChatGPT助手,无缝嵌入提取的内容,以增强其功能。我们提供三种定价方案,Starter(€5)、Basic(€20)和Premium(€50),根据您的需求选择合适的套餐。GPTURER能够将网页内容转换为Chat GPT智能,为您提供更强大的助手功能。
快速文档扫描,AI 辅助命名
扫描小子是一款独特的 iOS 和 iPadOS 文档扫描应用。它具有快速的扫描速度,可创建高质量的可选文本 PDF,并利用人工智能快速生成文件名,让您节省时间。如果您想自己命名文档并避免使用人工智能,也可以自行命名。定价:免费使用基本功能,付费订阅解锁高级功能。
AI 驱动的智能网页变化订阅工具。
猫头鹰智能网页订阅是一款基于AI技术的网站变化监控工具,帮助用户实时追踪网页内容更新,适用于个人与企业用户。与传统爬虫工具不同,本产品无需编写代码或配置复杂脚本,仅需一句话即可完成全自动监控设置,即使目标网站页面改版也能自动适配;同时,借助AI对需求的理解,系统能够精准捕捉用户真正关心的内容,无需设置大量关键词,即可实现实时智能通知,帮助用户提升工作效率与市场响应能力。产品整体定位为零门槛、高效率、易操作的信息监测工具,广泛适合不同需求的用户群体。
数学文本智能标记数据集
AutoMathText是一个广泛且精心策划的数据集,包含约200GB的数学文本。数据集中的每条内容都被最先进的开源语言模型Qwen进行自主选择和评分,确保高标准的相关性和质量。该数据集特别适合促进数学和人工智能交叉领域的高级研究,作为学习和教授复杂数学概念的教育工具,以及为开发和训练专门处理和理解数学内容的AI模型提供基础。
智能语音生成与数据集
ClearCypherAI是一家总部位于美国的AI初创公司,致力于构建前沿的解决方案。我们的产品包括文本转语音(T2A)、语音转文本(A2T)和语音转语音(A2A),支持多语言、多模态、实时语音智能。我们还提供自然语言数据集、威胁评估、AI定制平台等服务。我们的产品具有高度定制性、先进的技术和优质的客户支持。
高质量英文网页数据集
FineWeb数据集包含超过15万亿个经过清洗和去重的英文网页数据,来源于CommonCrawl。该数据集专为大型语言模型预训练设计,旨在推动开源模型的发展。数据集经过精心处理和筛选,以确保高质量,适用于各种自然语言处理任务。
腾讯文档智能助手,支持内容生成、数据处理、版式美化等创作需求
腾讯文档智能助手正式开启公测,可与Word、Excel、PPT等多品类文档进行智能互动,支持内容秒级生成,实现数据处理、版式美化等创作辅助功能。主要优势有:可基于标题或描述生成多类型文档内容,支持函数公式应用、数据处理、表格自动化等能力,实现 PPT 一键美化,可快速提取 PDF 文档摘要等,让文档内容实现跨品类畅通流转。
网页应用的智能助手
flowstate是网页应用的智能助手,能够为用户提供即时访问和支持。它能够无缝整合知识和支持,轻松提升用户在您的网页应用中的熟练程度。通过记录流程、对流程进行训练,以及将训练后的AI作为用户的专家,flowstate能够指导用户在他们与您的网页应用的整个交互过程中,帮助他们解决问题,甚至在途中教授他们新的知识。UIUX设计师和开发人员一直在努力为用户创造出色的体验,然而,任何网页应用都存在一定的学习曲线。flowstate旨在通过自然语言交流的方式解决这一问题,提升用户体验。
AI数据引擎,涵盖标注、工作流、数据集和人工智能
V7是一个AI数据引擎,提供企业级训练数据的完整基础设施,涵盖标注、工作流、数据集和人工在循环中。它能够帮助用户快速高效地标注、处理和管理训练数据,提高AI模型的准确性和性能。V7支持自动化标注、视频标注、文档处理等功能,适用于各种行业和应用场景。
多功能AI助手,提供问答、写作、绘图等智能服务。
三顿智能助手是一个集成了多种AI功能的在线平台,它通过提供问答、写作、绘图等多种服务,帮助用户提高工作效率和创造力。该产品以其强大的AI技术背景和用户友好的界面,为用户提供了一个便捷的智能服务入口。价格方面,三顿智能助手提供免费试用,同时也提供付费服务以解锁更多功能。
AI模型数据集平台
始智AI是一家提供AI模型和数据集的平台,致力于为科研单位、企事业单位和个人提供高质量的AI模型和数据集。始智AI的优势在于提供多种类型的AI模型和数据集,包括图像、视频、自然语言处理等,用户可以根据自己的需求选择合适的模型和数据集。始智AI的定价合理,用户可以根据自己的需求选择不同的套餐,满足不同的需求。始智AI的定位是成为AI模型和数据集领域的领先平台。
AI 智能网页抓取工具
FetchFox 是一款基于人工智能的网页抓取工具。它通过使用 AI 从原始网页文本中提取用户所需的数据。作为 Chrome 插件运行,用户可以用简单的英语描述所需的数据。您可以使用 FetchFox 快速收集数据,例如构建潜在客户列表、收集研究数据或调查市场细分。通过使用 AI 从原始文本中进行抓取,FetchFox 可以绕过 LinkedIn 和 Facebook 等网站的反抓取措施。即使是最复杂的 HTML 结构,FetchFox 也能轻松解析。
大规模图像编辑数据集
UltraEdit是一个大规模的图像编辑数据集,包含约400万份编辑样本,自动生成,基于指令的图像编辑。它通过利用大型语言模型(LLMs)的创造力和人类评估员的上下文编辑示例,提供了一个系统化的方法来生产大规模和高质量的图像编辑样本。UltraEdit的主要优点包括:1) 它通过利用大型语言模型的创造力和人类评估员的上下文编辑示例,提供了更广泛的编辑指令;2) 其数据源基于真实图像,包括照片和艺术作品,提供了更大的多样性和减少了偏见;3) 它还支持基于区域的编辑,通过高质量、自动生成的区域注释得到增强。
1点击数据捕获和网页抓取工具,结合人工智能
Hexofy Scraper是一款免费的网页抓取工具,通过结合人工智能,实现1点击数据捕获和网页抓取。它提供直观的点选界面,无需编写代码即可轻松从网页中提取数据。无论是从市场上的热门网站如亚马逊和eBay,还是从特定领域的网站上提取信息,Hexofy都能高效地完成任务。它是基于浏览器的工具,无需下载和安装。无论是一次性任务还是大规模数据提取项目,Hexofy都能为您提供无缝的抓取体验。
数据标注专家 - 为您的训练数据集进行标注
数据标注专家是一个为您提供优质训练数据集的数据标注服务平台。我们拥有专业的团队、先进的标注工具和有效的方法论,致力于帮助您获得更好的训练数据集。我们的服务包括数据标注、算法调优、数据清洗等。无论您是需要图像标注、文本标注还是其他类型的标注,我们都可以满足您的需求。
全能型智能助手,满足多样化应用需求。
IMYAI智能助手是一款集成了多种智能功能的在线服务平台,旨在为用户提供聊天对话、文本处理、专业绘画、音乐创作、视频创作等多元化服务。它结合了先进的人工智能技术,通过对话词库、绘画词库等资源,能够满足不同用户在不同场景下的应用需求。
您的 MCP 服务器安全扫描器,扫描常见漏洞,确保数据和代理安全。
mccan.ai 是一款专注于 Model Context Protocol (MCP) 服务器的安全扫描工具。它能够检测 MCP 服务器中的各种安全漏洞,确保大型语言模型(LLM)与外部工具的交互。该产品致力于帮助开发者识别和修复潜在的安全风险,从而保护敏感数据和系统免受攻击。mcpscan.ai 的核心价值在于其专门针对 MCP 实施的安全扫描,提供实时监控和详细的漏洞分析,为用户的安全部署提供支持。
智能编码助手,提升开发效率
通义灵码是一款专为开发者设计的智能编码助手,支持多种开发环境,包括JetBrains IDEs、Visual Studio Code、Visual Studio等。它通过集成先进的AI技术,帮助开发者快速完成编码任务,提高编码效率和质量,适用于各种编程语言和开发场景。
生成合成数据,管理数据,提高数据质量,构建最佳AI项目数据集。
YData是一个数据中心AI平台,提供生成合成数据、管理数据、提高数据质量和构建最佳AI项目数据集的功能。通过YData,您可以生成高质量的合成数据集,对数据进行管理和改进,构建出适用于您的AI项目的最佳数据集。YData还提供数据目录、数据配置和数据测量等功能。YData的定价信息,请联系官方获取。YData定位为数据科学领域的数据质量工具。
模型和数据集的集合
Distil-Whisper是一个提供模型和数据集的平台,用户可以在该平台上访问各种预训练模型和数据集,并进行相关的应用和研究。该平台提供了丰富的模型和数据集资源,帮助用户快速开展自然语言处理和机器学习相关工作。
将网页变成有组织的数据
From Chaos是一个Chrome插件,可以将网页内容转化为有组织的数据。通过ChatGPT的能力,您可以输入您的OpenAI API密钥,在所需页面上点击插件,描述您想要的数据类型,并选择数据类型(如JSON、YAML、CSV等)来下载数据。
整合所有资料,让 AI 搜索回答,提升知识获取效率。
飞书知识问答是一款基于 AI 的知识管理工具,能够整合用户上传的各类资料,如 PDF、Word、PowerPoint 等,通过 AI 搜索技术快速提供精准答案。该产品主要面向企业用户和知识工作者,帮助他们高效管理和检索知识,提升工作效率。其技术优势在于强大的 AI 搜索算法和对多种文件格式的支持,能够快速解析和理解用户上传的内容,提供准确的问答服务。
表情包视觉标注数据集
emo-visual-data 是一个公开的表情包视觉标注数据集,它通过使用 glm-4v 和 step-free-api 项目完成的视觉标注,收集了5329个表情包。这个数据集可以用于训练和测试多模态大模型,对于理解图像内容和文本描述之间的关系具有重要意义。
收集和梳理垂直领域的开源模型、数据集及评测基准
Awesome-Domain-LLM是一个收集和梳理垂直领域的开源模型、数据集及评测基准的项目。该项目收录了包括医疗、法律、金融、教育等多个领域的开源模型、数据集和评测基准,旨在推动大模型赋能各行各业。用户可以在该项目中找到适合自己领域的模型和数据集,以提高工作效率和质量。
高质量开放数据集平台,为大型模型提供数据支持
OpenDataLab是一个开源数据平台,提供高质量的开放数据集,支持大型AI模型的训练和应用。平台容量巨大,包含5500多个数据集,涵盖1500多种任务类型,总数据量达到80TB以上,下载量超过1064500次。平台提供30多种应用场景、20多种标注类型和5种数据类型,支持数据结构、标注格式和在线可视化的统一标准,实现数据的开放共享和智能搜索,提供结构化的数据信息和可视化的注释和数据分布,方便用户阅读和筛选。平台提供快速下载服务,无需VPN即可从国内云端快速下载数据。
首个说唱音乐生成数据集
RapBank是一个专注于说唱音乐的数据集,它从YouTube收集了大量说唱歌曲,并提供了一个精心设计的数据预处理流程。这个数据集对于音乐生成领域具有重要意义,因为它提供了大量的说唱音乐内容,可以用于训练和测试音乐生成模型。RapBank数据集包含94,164首歌曲链接,成功下载了92,371首歌曲,总时长达到5,586小时,覆盖84种不同的语言,其中英语歌曲的总时长最高,占总时长的大约三分之二。

© 2026 AIbase 备案号:闽ICP备08105208号-14