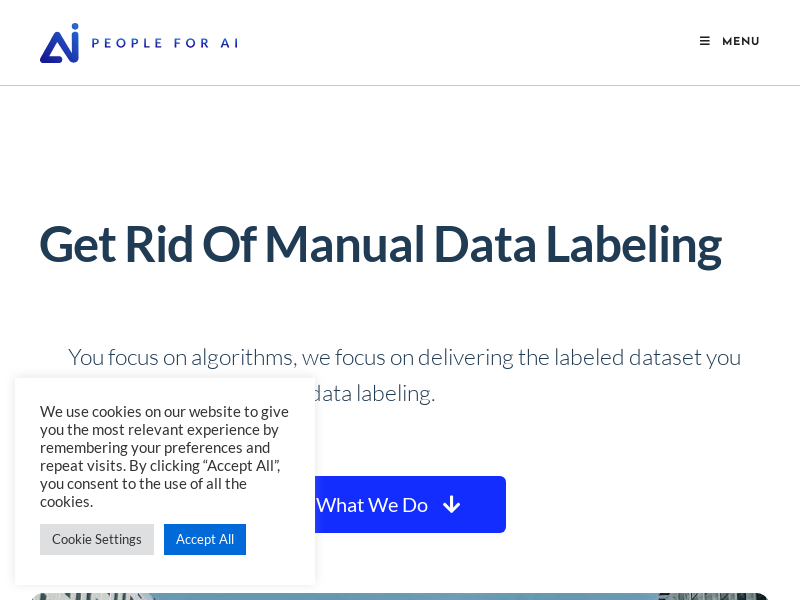
浏览量:110
最新流量情况
月访问量
2561
平均访问时长
00:00:29
每次访问页数
1.77
跳出率
38.65%
流量来源
直接访问
35.85%
自然搜索
36.27%
邮件
0.18%
外链引荐
19.68%
社交媒体
6.60%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
法国
34.42%
印度
15.21%
美国
50.37%
数据标注专家 - 为您的训练数据集进行标注
数据标注专家是一个为您提供优质训练数据集的数据标注服务平台。我们拥有专业的团队、先进的标注工具和有效的方法论,致力于帮助您获得更好的训练数据集。我们的服务包括数据标注、算法调优、数据清洗等。无论您是需要图像标注、文本标注还是其他类型的标注,我们都可以满足您的需求。
表情包视觉标注数据集
emo-visual-data 是一个公开的表情包视觉标注数据集,它通过使用 glm-4v 和 step-free-api 项目完成的视觉标注,收集了5329个表情包。这个数据集可以用于训练和测试多模态大模型,对于理解图像内容和文本描述之间的关系具有重要意义。
开源数据标注工具,提升机器学习模型性能。
LabelU是一个开源的数据标注工具,适用于需要对图像、视频、音频等数据进行高效标注的场景,以提升机器学习模型的性能和质量。它支持多种标注类型,包括标签分类、文本描述、拉框等,满足不同场景的标注需求。
AI数据引擎,涵盖标注、工作流、数据集和人工智能
V7是一个AI数据引擎,提供企业级训练数据的完整基础设施,涵盖标注、工作流、数据集和人工在循环中。它能够帮助用户快速高效地标注、处理和管理训练数据,提高AI模型的准确性和性能。V7支持自动化标注、视频标注、文档处理等功能,适用于各种行业和应用场景。
一个用于训练高性能奖励模型的开源数据集。
HelpSteer2是由NVIDIA发布的一个开源数据集,旨在支持训练能够对齐模型以使其更加有帮助、事实正确和连贯,同时在响应的复杂性和冗余度方面具有可调节性。该数据集与Scale AI合作创建,当与Llama 3 70B基础模型一起使用时,在RewardBench上达到了88.8%的表现,是截至2024年6月12日最佳的奖励模型之一。
AI 图像标注工具,致力于轻量、快速构建复杂场景数据集。
T Rex Label 是一个开箱即用的 AI 标注工具,具有快速构建复杂场景数据集的能力。其主要优点包括高效性、易用性和准确性。背景信息包括为图像标注提供便捷的解决方案,定位于为用户提供高效的标注工具。
SuperAnnotate提供端到端数据标注、版本控制和管理平台以生成AI模型的训练数据。
SuperAnnotate是一个全面的端到端数据标注、版本控制和管理平台,可高效生成AI模型的高质量训练数据。它提供了标注软件、标注服务、项目和质量管理、AI数据管理和策展以及MLOps和自动化等功能模块。企业可以通过SuperAnnotate更快地构建、微调、迭代和管理自己的AI模型,大幅度缩短准确AI模型的开发时间。SuperAnnotate支持图像、视频、文本等多种数据类型的标注,安全合规,拥有强大的NLP支持。已经获得Hinge Health、Motorola Solutions、Percepto等客户的广泛应用,可以提高模型准确率、缩短标注周期等。
标签平台,高质量训练数据
Kili Technology是一个标签平台,帮助企业将非结构化数据转化为高质量数据集,用于训练AI模型,实现成功的项目。该平台具有快速标注、发现和修复错误、简化数据操作等功能,并提供专家标注服务。Kili Technology支持文本、图像、视频、OCR和地理空间等多种类型的数据标注。
多语言预训练数据集
FineWeb2是由Hugging Face提供的一个大规模多语言预训练数据集,覆盖超过1000种语言。该数据集经过精心设计,用于支持自然语言处理(NLP)模型的预训练和微调,特别是在多种语言上。它以其高质量、大规模和多样性而闻名,能够帮助模型学习跨语言的通用特征,提升在特定语言任务上的表现。FineWeb2在多个语言的预训练数据集中表现出色,甚至在某些情况下,比一些专门为单一语言设计的数据库表现更好。
前端标注组件库,支持多种数据标注方式。
labelU-Kit 是一个开源的前端标注组件库,提供图片、视频和音频的标注功能,支持2D框、点、线、多边形、立体框等多种标注方式。它以NPM包的形式提供,方便开发者集成到自己的标注平台中,提高数据标注的效率和灵活性。
开源数据标注工具
Label Studio是一款灵活的开源数据标注平台,适用于各种数据类型。它可以帮助用户准备计算机视觉、自然语言处理、语音、声音和视频模型的训练数据。Label Studio提供了多种标注类型,包括图像分类、对象检测、语义分割、音频分类、说话人分割、情感识别、文本分类和命名实体识别等。它支持快速启动和使用,适用于个人和团队使用。
数据标注平台,助力AI项目高效管理数据标注项目。
Data Annotation Platform是一个端到端的数据标注平台,允许用户上传计算机视觉数据,选择标注类型,并下载结果,无需任何最低承诺。该平台支持多种数据标注类型,包括矩形、多边形、3D立方体、关键点、语义分割、实例分割和泛视觉分割等,服务于AI项目经理、机器学习工程师、AI初创公司和研究团队,解决他们在数据标注过程中遇到的挑战。平台以其无缝执行、成本计算器、指令生成器、免费任务、API接入和团队访问等特点,为用户提供了一个简单、高效、成本效益高的数据标注解决方案。
数据标注必须易于使用
Unitlab是一个由AI驱动的数据标注平台,它可以自动收集原始数据,并允许您与人工标注者合作为机器学习模型生成高度准确的标签。通过我们的服务,您可以优化工作效率、提高数据质量并节省成本。
模型和数据集的集合
Distil-Whisper是一个提供模型和数据集的平台,用户可以在该平台上访问各种预训练模型和数据集,并进行相关的应用和研究。该平台提供了丰富的模型和数据集资源,帮助用户快速开展自然语言处理和机器学习相关工作。
开源数据管理和标注平台
Dioptra 数据管理平台是一个开源的数据管理和标注平台,为计算机视觉、自然语言处理和语言模型提供数据筛选、标注和重训练的功能。通过注册你的元数据到 Dioptra 平台,你可以诊断模型失败原因,使用活跃学习算法筛选最有价值的未标注数据,并通过 Dioptra 的 API 与你的标注和重训练流程集成。我们的客户通过使用 Dioptra 平台,提高了模型在难例上的准确性,缩短了训练周期,并减少了标注成本。
大规模多模态预训练数据集
allenai/olmo-mix-1124数据集是由Hugging Face提供的一个大规模多模态预训练数据集,主要用于训练和优化自然语言处理模型。该数据集包含了大量的文本信息,覆盖了多种语言,并且可以用于各种文本生成任务。它的重要性在于提供了一个丰富的资源,使得研究人员和开发者能够训练出更加精准和高效的语言模型,进而推动自然语言处理技术的发展。
ChatGPT 数据与分析是一个全面的资源、材料和指南目录,旨在帮助您掌握人工智能的艺术。
ChatGPT 数据与分析是一个包含资源、材料和指南的综合目录,涵盖了与 ChatGPT 相关的内容。该目录旨在帮助您提高 AI 技能。本书提供了 ChatGPT 的提示,可帮助您释放创造力,提高工作效率。提示清晰简明。本目录中的所有材料都经过精心策划,确保来源可靠和权威,为您提供高质量的信息和指导。
将Common Crawl转化为精细的长期预训练数据集
Nemotron-CC是一个基于Common Crawl的6.3万亿token的数据集。它通过分类器集成、合成数据改写和减少启发式过滤器的依赖,将英文Common Crawl转化为一个6.3万亿token的长期预训练数据集,包含4.4万亿全球去重的原始token和1.9万亿合成生成的token。该数据集在准确性和数据量之间取得了更好的平衡,对于训练大型语言模型具有重要意义。
大规模图像编辑数据集
UltraEdit是一个大规模的图像编辑数据集,包含约400万份编辑样本,自动生成,基于指令的图像编辑。它通过利用大型语言模型(LLMs)的创造力和人类评估员的上下文编辑示例,提供了一个系统化的方法来生产大规模和高质量的图像编辑样本。UltraEdit的主要优点包括:1) 它通过利用大型语言模型的创造力和人类评估员的上下文编辑示例,提供了更广泛的编辑指令;2) 其数据源基于真实图像,包括照片和艺术作品,提供了更大的多样性和减少了偏见;3) 它还支持基于区域的编辑,通过高质量、自动生成的区域注释得到增强。
用于强化学习验证的数学问题数据集
RLVR-GSM-MATH-IF-Mixed-Constraints数据集是一个专注于数学问题的数据集,它包含了多种类型的数学问题和相应的解答,用于训练和验证强化学习模型。这个数据集的重要性在于它能够帮助开发更智能的教育辅助工具,提高学生解决数学问题的能力。产品背景信息显示,该数据集由allenai在Hugging Face平台上发布,包含了GSM8k和MATH两个子集,以及带有可验证约束的IF Prompts,适用于MIT License和ODC-BY license。
大规模机器人学习数据集,推动多用途机器人策略发展。
AGIBOT WORLD是一个专为推进多用途机器人策略而设计的大规模机器人学习数据集。它包括基础模型、基准测试和一个生态系统,旨在为学术界和工业界提供高质量的机器人数据,为具身AI铺平道路。该数据集包含100多台机器人的100万条以上轨迹,覆盖100多个真实世界场景,涉及精细操控、工具使用和多机器人协作等任务。它采用尖端的多模态硬件,包括视觉触觉传感器、耐用的6自由度灵巧手和具有全身控制的移动双臂机器人,支持模仿学习、多智能体协作等研究。AGIBOT WORLD的目标是改变大规模机器人学习,推进可扩展的机器人系统生产,是一个开源平台,邀请研究人员和实践者共同塑造具身AI的未来。
高质量英文网页数据集
FineWeb数据集包含超过15万亿个经过清洗和去重的英文网页数据,来源于CommonCrawl。该数据集专为大型语言模型预训练设计,旨在推动开源模型的发展。数据集经过精心处理和筛选,以确保高质量,适用于各种自然语言处理任务。
生成合成数据,管理数据,提高数据质量,构建最佳AI项目数据集。
YData是一个数据中心AI平台,提供生成合成数据、管理数据、提高数据质量和构建最佳AI项目数据集的功能。通过YData,您可以生成高质量的合成数据集,对数据进行管理和改进,构建出适用于您的AI项目的最佳数据集。YData还提供数据目录、数据配置和数据测量等功能。YData的定价信息,请联系官方获取。YData定位为数据科学领域的数据质量工具。
大规模多模态医学数据集
MedTrinity-25M是一个大规模多模态数据集,包含多粒度的医学注释。它由多位作者共同开发,旨在推动医学图像和文本处理领域的研究。数据集的构建包括数据提取、多粒度文本描述生成等步骤,支持多种医学图像分析任务,如视觉问答(VQA)、病理学图像分析等。
高质量开放数据集平台,为大型模型提供数据支持
OpenDataLab是一个开源数据平台,提供高质量的开放数据集,支持大型AI模型的训练和应用。平台容量巨大,包含5500多个数据集,涵盖1500多种任务类型,总数据量达到80TB以上,下载量超过1064500次。平台提供30多种应用场景、20多种标注类型和5种数据类型,支持数据结构、标注格式和在线可视化的统一标准,实现数据的开放共享和智能搜索,提供结构化的数据信息和可视化的注释和数据分布,方便用户阅读和筛选。平台提供快速下载服务,无需VPN即可从国内云端快速下载数据。
上传数据,获取机器学习模型
Automated Machine Learning as a Service是一个提供自动化机器学习服务的网站。用户可以通过上传数据来获取他们的机器学习模型,该平台为用户提供了便捷的机器学习模型开发和部署流程。该平台还提供了丰富的功能和优势,包括简单易用的界面、自动化的模型训练和优化、灵活的定价策略等。用户可以根据自己的需求选择适合的定价方案,并在不同的场景中应用该机器学习模型。该产品的定位是为广大用户提供高效、便捷、灵活的机器学习解决方案。
Pixta AI | 大规模数据标注和数据采集服务
Pixta AI是一家提供大规模数据标注和数据采集解决方案的公司。我们拥有1000多名经验丰富的标注员,超过9000万张图片和1000万个视频。通过我们的服务,可以加速您的AI开发。我们提供的标注和数据采集服务能够满足各种需求,并且可以根据您的项目进行定制化。

© 2026 AIbase 备案号:闽ICP备08105208号-14