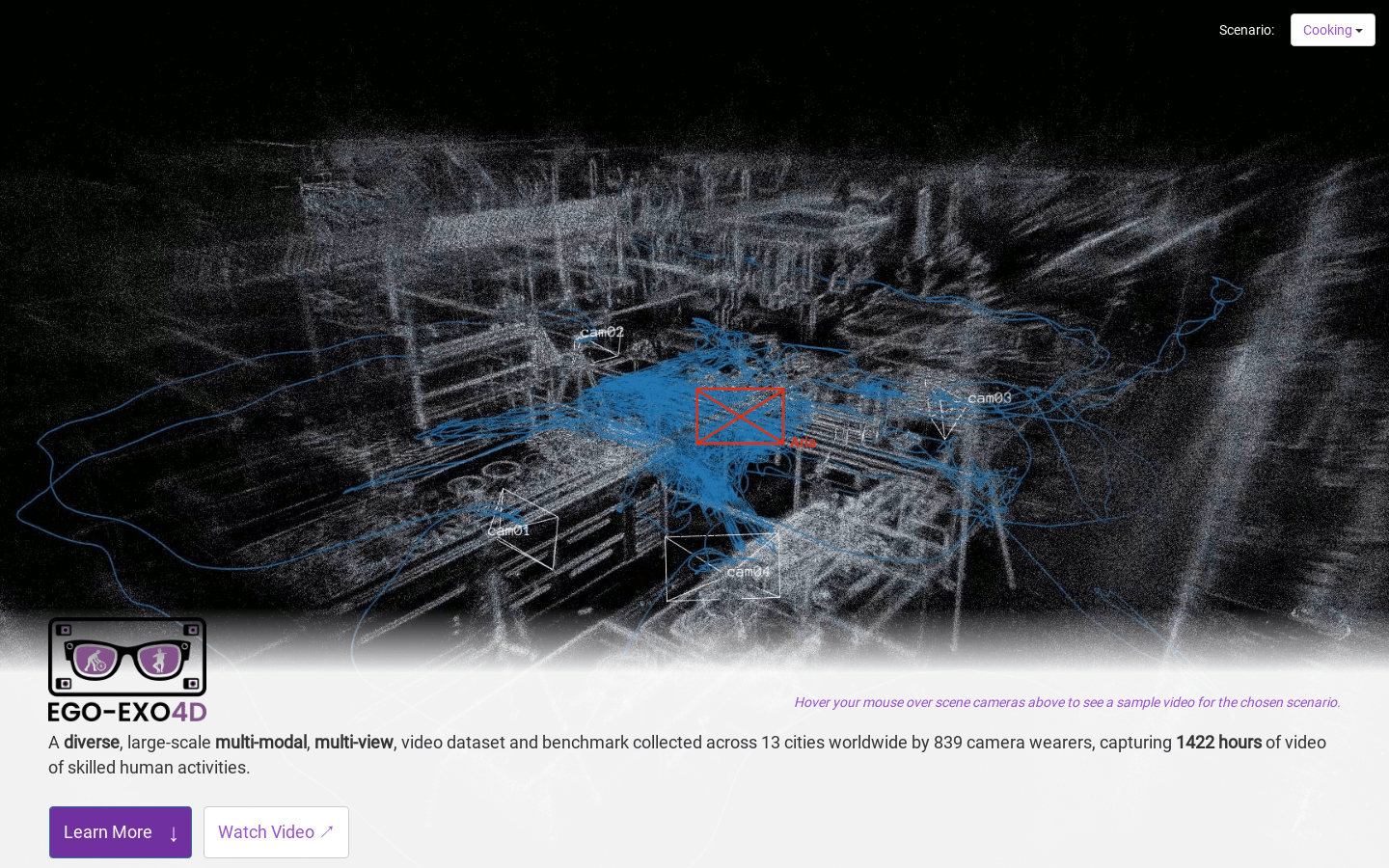
Ego-Exo4D 是一个多模态多视角视频数据集和基准挑战,以捕捉技能人类活动的自我中心和外部中心视频为中心。它支持日常生活活动的多模态机器感知研究。该数据集由 839 位佩戴摄像头的志愿者在全球 13 个城市收集,捕捉了 1422 小时的技能人类活动视频。该数据集提供了专家评论、参与者提供的教程样式的叙述和一句话的原子动作描述等三种自然语言数据集,配对视频使用。Ego-Exo4D 还捕获了多视角和多种感知模态,包括多个视角、七个麦克风阵列、两个 IMUs、一个气压计和一个磁强计。数据集记录时严格遵守隐私和伦理政策,参与者的正式同意。欲了解更多信息,请访问官方网站。
需求人群:
"支持多模态机器感知研究,用于日常生活活动的视频分析和理解"
产品特色:
多模态多视角视频数据集
同步的自我中心和外部中心视图
多种感知模态,包括麦克风、IMUs、气压计等
三种自然语言数据集
支持研究日常生活活动的多模态机器感知
浏览量:119
最新流量情况
月访问量
3219
平均访问时长
00:00:29
每次访问页数
1.68
跳出率
45.51%
流量来源
直接访问
51.36%
自然搜索
24.75%
邮件
0.06%
外链引荐
7.95%
社交媒体
14.56%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
日本
0.74%
韩国
21.61%
美国
77.65%
多模态多视角视频数据集和基准挑战
Ego-Exo4D 是一个多模态多视角视频数据集和基准挑战,以捕捉技能人类活动的自我中心和外部中心视频为中心。它支持日常生活活动的多模态机器感知研究。该数据集由 839 位佩戴摄像头的志愿者在全球 13 个城市收集,捕捉了 1422 小时的技能人类活动视频。该数据集提供了专家评论、参与者提供的教程样式的叙述和一句话的原子动作描述等三种自然语言数据集,配对视频使用。Ego-Exo4D 还捕获了多视角和多种感知模态,包括多个视角、七个麦克风阵列、两个 IMUs、一个气压计和一个磁强计。数据集记录时严格遵守隐私和伦理政策,参与者的正式同意。欲了解更多信息,请访问官方网站。
大规模多模态医学数据集
MedTrinity-25M是一个大规模多模态数据集,包含多粒度的医学注释。它由多位作者共同开发,旨在推动医学图像和文本处理领域的研究。数据集的构建包括数据提取、多粒度文本描述生成等步骤,支持多种医学图像分析任务,如视觉问答(VQA)、病理学图像分析等。
大规模多模态预训练数据集
allenai/olmo-mix-1124数据集是由Hugging Face提供的一个大规模多模态预训练数据集,主要用于训练和优化自然语言处理模型。该数据集包含了大量的文本信息,覆盖了多种语言,并且可以用于各种文本生成任务。它的重要性在于提供了一个丰富的资源,使得研究人员和开发者能够训练出更加精准和高效的语言模型,进而推动自然语言处理技术的发展。
一万亿Token和34亿张图像的多模态数据集
MINT-1T是由Salesforce AI开源的多模态数据集,包含一万亿个文本标记和34亿张图像,规模是现有开源数据集的10倍。它不仅包含HTML文档,还包括PDF文档和ArXiv论文,丰富了数据集的多样性。MINT-1T的数据集构建涉及多种来源的数据收集、处理和过滤步骤,确保了数据的高质量和多样性。
多模态大型模型,处理文本、图像和视频数据
Valley是由字节跳动开发的尖端多模态大型模型,能够处理涉及文本、图像和视频数据的多种任务。该模型在内部电子商务和短视频基准测试中取得了最佳结果,比其他开源模型表现更优。在OpenCompass测试中,与同规模模型相比,平均得分大于等于67.40,在小于10B模型中排名第二。Valley-Eagle版本参考了Eagle,引入了一个可以灵活调整令牌数量并与原始视觉令牌并行的视觉编码器,增强了模型在极端场景下的性能。
多模态大型模型,处理文本、图像和视频数据
Valley-Eagle-7B是由字节跳动开发的多模态大型模型,旨在处理涉及文本、图像和视频数据的多种任务。该模型在内部电子商务和短视频基准测试中取得了最佳结果,并在OpenCompass测试中展现出与同规模模型相比的卓越性能。Valley-Eagle-7B结合了LargeMLP和ConvAdapter构建投影器,并引入了VisionEncoder,以增强模型在极端场景下的性能。
生成多视角视频的模型
Stable Video 4D (SV4D) 是基于 Stable Video Diffusion (SVD) 和 Stable Video 3D (SV3D) 的生成模型,它接受单一视角的视频并生成该对象的多个新视角视频(4D 图像矩阵)。该模型训练生成 40 帧(5 个视频帧 x 8 个摄像机视角)在 576x576 分辨率下,给定 5 个相同大小的参考帧。通过运行 SV3D 生成轨道视频,然后使用轨道视频作为 SV4D 的参考视图,并输入视频作为参考帧,进行 4D 采样。该模型还通过使用生成的第一帧作为锚点,然后密集采样(插值)剩余帧来生成更长的新视角视频。
大规模长视频数据集,结构化字幕
MiraData是一个大规模的视频数据集,专注于长视频片段,平均时长72秒,提供结构化字幕,平均字幕长度318字,丰富了视频内容的描述。通过使用GPT-4V等技术,MiraData在视频理解和字幕生成方面展现出高准确性和语义连贯性。
EgoLife是一个长期、多模态、多视角的日常生活AI助手项目,旨在推进长期上下文理解研究。
EgoLife是一个面向长期、多模态、多视角日常生活的AI助手项目。该项目通过记录六名志愿者一周的共享生活体验,生成了约50小时的视频数据,涵盖日常活动、社交互动等场景。其多模态数据(包括视频、视线、IMU数据)和多视角摄像头系统为AI研究提供了丰富的上下文信息。此外,该项目提出了EgoRAG框架,用于解决长期上下文理解任务,推动了AI在复杂环境中的应用能力。
AI多模态数据绑定
ImageBind是一种新的AI模型,能够同时绑定六种感官模态的数据,无需显式监督。通过识别这些模态之间的关系(图像和视频、音频、文本、深度、热成像和惯性测量单元(IMUs)),这一突破有助于推动AI发展,使机器能够更好地分析多种不同形式的信息。探索演示以了解ImageBind在图像、音频和文本模态上的能力。
多模态大型语言模型,提升文本、图像和视频数据处理能力。
Valley是由字节跳动开发的多模态大型模型(MLLM),旨在处理涉及文本、图像和视频数据的多种任务。该模型在内部电子商务和短视频基准测试中取得了最佳结果,远超过其他开源模型,并在OpenCompass多模态模型评估排行榜上展现了出色的性能,平均得分67.40,位列已知开源MLLMs(<10B)中的前两名。
多视角视频生成同步技术
SynCamMaster是一种先进的视频生成技术,它能够从多样化的视角同步生成多摄像机视频。这项技术通过预训练的文本到视频模型,增强了视频内容在不同视角下的动态一致性,对于虚拟拍摄等应用场景具有重要意义。该技术的主要优点包括能够处理开放世界视频的任意视角生成,整合6自由度摄像机姿态,并设计了一种渐进式训练方案,利用多摄像机图像和单目视频作为补充,显著提升了模型性能。
大规模多模态推理与指令调优平台
MAmmoTH-VL是一个大规模多模态推理平台,它通过指令调优技术,显著提升了多模态大型语言模型(MLLMs)在多模态任务中的表现。该平台使用开放模型创建了一个包含1200万指令-响应对的数据集,覆盖了多样化的、推理密集型的任务,并提供了详细且忠实的理由。MAmmoTH-VL在MathVerse、MMMU-Pro和MuirBench等基准测试中取得了最先进的性能,展现了其在教育和研究领域的重要性。
统一多模态视频生成系统
UniVG是一款统一多模态视频生成系统,能够处理多种视频生成任务,包括文本和图像模态。通过引入多条件交叉注意力和偏置高斯噪声,实现了高自由度和低自由度视频生成。在公共学术基准MSR-VTT上实现了最低的Fr'echet视频距离(FVD),超越了当前开源方法在人类评估上的表现,并与当前闭源方法Gen2不相上下。
大型多模态模型,集成表格数据
TableGPT2是一个大型多模态模型,专门针对表格数据进行预训练和微调,以解决实际应用中表格数据整合不足的问题。该模型在超过593.8K的表格和2.36M的高质量查询-表格-输出元组上进行了预训练和微调,规模前所未有。TableGPT2的关键创新之一是其新颖的表格编码器,专门设计用于捕获模式级别和单元格级别的信息,增强了模型处理模糊查询、缺失列名和不规则表格的能力。在23个基准测试指标上,TableGPT2在7B模型上平均性能提升了35.20%,在72B模型上提升了49.32%,同时保持了强大的通用语言和编码能力。
一张图生成多视角扩散基础模型
Zero123++是一个单图生成多视角一致性扩散基础模型。它可以从单个输入图像生成多视角图像,具有稳定的扩散VAE。您可以使用它来生成具有灰色背景的不透明图像。您还可以使用它来运行深度ControlNet。模型和源代码均可在官方网站上获得。
大型多模态模型,处理多图像、视频和3D数据。
LLaVA-NeXT是一个大型多模态模型,它通过统一的交错数据格式处理多图像、视频、3D和单图像数据,展示了在不同视觉数据模态上的联合训练能力。该模型在多图像基准测试中取得了领先的结果,并在不同场景中通过适当的数据混合提高了之前单独任务的性能或保持了性能。
大规模人脸文本-视频数据集
CelebV-Text是一个大规模、高质量、多样化的人脸文本-视频数据集,旨在促进人脸文本-视频生成任务的研究。数据集包含70,000个野外人脸视频剪辑,每个视频剪辑都配有20个文本,涵盖40种一般外观、5种详细外观、6种光照条件、37种动作、8种情绪和6种光线方向。CelebV-Text通过全面的统计分析验证了其在视频、文本和文本-视频相关性方面的优越性,并构建了一个基准来标准化人脸文本-视频生成任务的评估。
为开源世界构建高质量视频数据集的计划
Open-Sora-Plan是一个开源项目,旨在为开源社区提供高质量的视频数据集。该项目已经爬取并处理了40258个来自开源网站的高质量视频,涵盖了60%的横屏视频。同时还提供了自动生成的密集字幕,供机器学习等应用使用。该项目免费开源,欢迎大家共同参与和支持。
多模态驱动的定制视频生成架构。
HunyuanCustom 是一个多模态定制视频生成框架,旨在根据用户定义的条件生成特定主题的视频。该技术在身份一致性和多种输入模式的支持上表现出色,能够处理文本、图像、音频和视频输入,适合虚拟人广告、视频编辑等多种应用场景。
大型多模态模型中视频理解的探索
Apollo是一个专注于视频理解的先进大型多模态模型家族。它通过系统性地探索视频-LMMs的设计空间,揭示了驱动性能的关键因素,提供了优化模型性能的实用见解。Apollo通过发现'Scaling Consistency',使得在较小模型和数据集上的设计决策能够可靠地转移到更大的模型上,大幅降低计算成本。Apollo的主要优点包括高效的设计决策、优化的训练计划和数据混合,以及一个新型的基准测试ApolloBench,用于高效评估。
表情包视觉标注数据集
emo-visual-data 是一个公开的表情包视觉标注数据集,它通过使用 glm-4v 和 step-free-api 项目完成的视觉标注,收集了5329个表情包。这个数据集可以用于训练和测试多模态大模型,对于理解图像内容和文本描述之间的关系具有重要意义。
多模态语言模型
SpeechGPT是一种多模态语言模型,具有内在的跨模态对话能力。它能够感知并生成多模态内容,遵循多模态人类指令。SpeechGPT-Gen是一种扩展了信息链的语音生成模型。SpeechAgents是一种具有多模态多代理系统的人类沟通模拟。SpeechTokenizer是一种统一的语音标记器,适用于语音语言模型。这些模型和数据集的发布日期和相关信息均可在官方网站上找到。
基于Omni AI Model的多模态AI视频生成器,支持多形式创作编辑。
Omni AI Video是基于强大的Omni AI Model构建的先进多模态视频生成系统。其重要性在于为创作者提供了一站式的AI视频创作解决方案。主要优点包括支持文本、图像、音频和视频输入,实现统一的多模态处理;无需切换工具,提高创作效率;输出高质量视频,适用于多种商业场景。产品背景是满足创作者对高效、多功能AI视频创作工具的需求。价格方面,有每日免费信用额度1 Credit,同时有不同的付费计划可供选择,价格即将上调,现在订阅可锁定低价。定位为面向创作者的一站式AI创意平台,提供7种顶级AI模型用于视频、图像、音乐和语音生成。
多模态语言模型预测网络
Honeybee是一个适用于多模态语言模型的局部性增强预测器。它能够提高多模态语言模型在不同下游任务上的性能,如自然语言推理、视觉问答等。Honeybee的优势在于引入了局部性感知机制,可以更好地建模输入样本之间的依赖关系,从而增强多模态语言模型的推理和问答能力。
面向长期视频理解的大规模多模态模型
MA-LMM是一种基于大语言模型的大规模多模态模型,主要针对长期视频理解进行设计。它采用在线处理视频的方式,并使用记忆库存储过去的视频信息,从而可以在不超过语言模型上下文长度限制或GPU内存限制的情况下,参考历史视频内容进行长期分析。MA-LMM可以无缝集成到当前的多模态语言模型中,并在长视频理解、视频问答和视频字幕等任务上取得了领先的性能。
多模态原生混合专家模型
Aria是一个多模态原生混合专家模型,具有强大的多模态、语言和编码任务性能。它在视频和文档理解方面表现出色,支持长达64K的多模态输入,能够在10秒内描述一个256帧的视频。Aria模型的参数量为25.3B,能够在单个A100(80GB)GPU上使用bfloat16精度进行加载。Aria的开发背景是满足对多模态数据理解的需求,特别是在视频和文档处理方面。它是一个开源模型,旨在推动多模态人工智能的发展。

© 2026 AIbase 备案号:闽ICP备08105208号-14