浏览量:131
多模态大型语言模型,支持图像和文本处理。
Llama-3.2-11B-Vision 是 Meta 发布的一款多模态大型语言模型(LLMs),它结合了图像和文本处理的能力,旨在提高视觉识别、图像推理、图像描述和回答有关图像的一般问题的性能。该模型在常见的行业基准测试中的表现超过了众多开源和封闭的多模态模型。
高效能长文本处理AI模型
Jamba 1.5 Open Model Family是AI21公司推出的最新AI模型系列,基于SSM-Transformer架构,具有超长文本处理能力、高速度和高质量,是市场上同类产品中表现最优的。这些模型专为企业级应用设计,考虑了资源效率、质量、速度和解决关键任务的能力。
高效能的长文本处理AI模型
AI21-Jamba-1.5-Mini是AI21实验室开发的最新一代混合SSM-Transformer指令跟随基础模型。这款模型以其卓越的长文本处理能力、速度和质量在市场上脱颖而出,相较于同类大小的领先模型,推理速度提升高达2.5倍。Jamba 1.5 Mini和Jamba 1.5 Large专为商业用例和功能进行了优化,如函数调用、结构化输出(JSON)和基础生成。
256M参数的医学领域语言模型,用于医学文本处理等任务
SmolDocling-256M-preview是由ds4sd推出的一个具有256M参数的语言模型,专注于医学领域。其重要性在于为医学文本处理、医学知识提取等任务提供了有效的工具。在医学研究和临床实践中,大量的文本数据需要进行分析和处理,该模型能够理解和处理医学专业语言。主要优点包括在医学领域有较好的性能表现,能够处理多种医学相关的文本任务,如疾病诊断辅助、医学文献摘要等。该模型的背景是随着医学数据的增长,对处理医学文本的技术需求日益增加。其定位是为医学领域的研究人员、医生、开发者等提供语言处理能力支持,目前未提及价格相关信息。
Gemini 2.0 Flash-Lite 是高效的语言模型,专为长文本处理和多种应用场景优化。
Gemini 2.0 Flash-Lite 是 Google 推出的高效语言模型,专为长文本处理和复杂任务优化。它在推理、多模态、数学和事实性基准测试中表现出色,具备简化的价格策略,使得百万级上下文窗口更加经济实惠。Gemini 2.0 Flash-Lite 已在 Google AI Studio 和 Vertex AI 中全面开放,适合企业级生产使用。
前沿级别的AI模型,提供顶级的指令遵循和长文本处理能力。
EXAONE 3.5是LG AI Research发布的一系列人工智能模型,这些模型以其卓越的性能和成本效益而著称。它们在模型训练效率、去污染处理、长文本理解和指令遵循能力方面表现出色。EXAONE 3.5模型的开发遵循了LG的AI伦理原则,进行了AI伦理影响评估,以确保模型的负责任使用。这些模型的发布旨在推动AI研究和生态系统的发展,并为AI创新奠定基础。
AI21推出的Jamba 1.6模型,专为企业私有部署设计,具备卓越的长文本处理能力。
Jamba 1.6 是 AI21 推出的最新语言模型,专为企业私有部署而设计。它在长文本处理方面表现出色,能够处理长达 256K 的上下文窗口,采用混合 SSM-Transformer 架构,可高效准确地处理长文本问答任务。该模型在质量上超越了 Mistral、Meta 和 Cohere 等同类模型,同时支持灵活的部署方式,包括在本地或 VPC 中私有部署,确保数据安全。它为企业提供了一种无需在数据安全和模型质量之间妥协的解决方案,适用于需要处理大量数据和长文本的场景,如研发、法律和金融分析等。目前,Jamba 1.6 已在多个企业中得到应用,如 Fnac 使用其进行数据分类,Educa Edtech 利用其构建个性化聊天机器人等。
用AI处理文本
Plus on Setapp是一款AI助手应用,可以帮助您撰写、翻译、总结和解释文本。它可以在任何应用程序中选择文本,并通过简单的快捷键将其发送给AI助手,让它帮您改进、校对、总结、解释或翻译文本。此外,您还可以自定义提示来完成特定任务。Plus on Setapp是Setapp订阅服务中的一部分,订阅费用为9.99美元/月。
国际领先的语言理解与长文本处理大模型。
GLM-4-Plus是智谱推出的一款基座大模型,它在语言理解、指令遵循和长文本处理等方面性能得到全面提升,保持了国际领先水平。该模型的推出,不仅代表了中国在大模型领域的创新和突破,还为开发者和企业提供了强大的语言处理能力,进一步推动了人工智能技术的发展和应用。
开源免费的 Wispr Flow 替代方案,为中文用户打造的桌面端语音输入与文本处理工具。
蛐蛐 (QuQu) 是一款开源免费的桌面端语音输入与文本处理工具,专为中文用户设计。它提供了隐私保护和本地处理功能,与 Wispr Flow 相比,无需支付订阅费用。通过集成 FunASR 本地模型,蛐蛐 能够精准识别中文,优化语音输入体验,适合开发者和普通用户使用。
专注长文本、多语言、垂直化
达观 “曹植” 大模型是专注于长文本、多语言、垂直化发展的国产大语言模型。具有自动化写作、翻译、专业性报告写作能力,支持多语言应用和垂直行业定制。可提供高质量文案撰写服务,广泛适用于各行业,是解决企业实际问题的智能工具。
AI21 Jamba Large 1.6 是一款强大的混合 SSM-Transformer 架构基础模型,擅长长文本处理和高效推理。
AI21-Jamba-Large-1.6 是由 AI21 Labs 开发的混合 SSM-Transformer 架构基础模型,专为长文本处理和高效推理而设计。该模型在长文本处理、推理速度和质量方面表现出色,支持多种语言,并具备强大的指令跟随能力。它适用于需要处理大量文本数据的企业级应用,如金融分析、内容生成等。该模型采用 Jamba Open Model License 授权,允许在许可条款下进行研究和商业使用。
先进AI语言模型
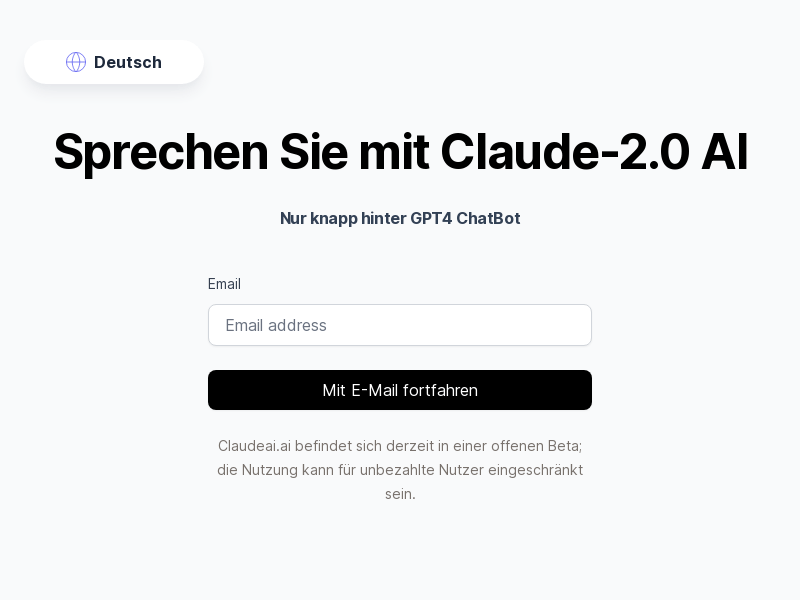
Claude 2是由Anthropic AI开发的先进语言模型,提供广泛的数据处理能力,创意写作,编程任务和数据分析。它支持100K token limit,推理能力仅次于ChatGPT4。免费使用Claude 2 AI,享受与先进AI技术的无缝交互。
高效处理长文本的先进语言模型
Qwen2.5-Turbo是阿里巴巴开发团队推出的一款能够处理超长文本的语言模型,它在Qwen2.5的基础上进行了优化,支持长达1M个token的上下文,相当于约100万英文单词或150万中文字符。该模型在1M-token Passkey Retrieval任务中实现了100%的准确率,并在RULER长文本评估基准测试中得分93.1,超越了GPT-4和GLM4-9B-1M。Qwen2.5-Turbo不仅在长文本处理上表现出色,还保持了短文本处理的高性能,且成本效益高,每1M个token的处理成本仅为0.3元。
多模态语言模型,融合文本和语音
Spirit LM是一个基础多模态语言模型,能够自由混合文本和语音。该模型基于一个7B预训练的文本语言模型,通过持续在文本和语音单元上训练来扩展到语音模式。语音和文本序列被串联为单个令牌流,并使用一个小的自动策划的语音-文本平行语料库,采用词级交错方法进行训练。Spirit LM有两个版本:基础版使用语音音素单元(HuBERT),而表达版除了音素单元外,还使用音高和风格单元来模拟表达性。对于两个版本,文本都使用子词BPE令牌进行编码。该模型不仅展现了文本模型的语义能力,还展现了语音模型的表达能力。此外,我们展示了Spirit LM能够在少量样本的情况下跨模态学习新任务(例如ASR、TTS、语音分类)。
首个多模态 Mistral 模型,支持图像和文本的混合任务处理。
Pixtral 12B 是 Mistral AI 团队开发的一款多模态 AI 模型,它能够理解自然图像和文档,具备出色的多模态任务处理能力,同时在文本基准测试中也保持了最先进的性能。该模型支持多种图像尺寸和宽高比,能够在长上下文窗口中处理任意数量的图像,是 Mistral Nemo 12B 的升级版,专为多模态推理而设计,不牺牲关键文本处理能力。
Gemini Embedding 是一种先进的文本嵌入模型,通过 Gemini API 提供强大的语言理解能力。
Gemini Embedding 是 Google 推出的一种实验性文本嵌入模型,通过 Gemini API 提供服务。该模型在多语言文本嵌入基准测试(MTEB)中表现卓越,超越了之前的顶尖模型。它能够将文本转换为高维数值向量,捕捉语义和上下文信息,广泛应用于检索、分类、相似性检测等场景。Gemini Embedding 支持超过 100 种语言,具备 8K 输入标记长度和 3K 输出维度,同时引入了嵌套表示学习(MRL)技术,可灵活调整维度以满足存储需求。该模型目前处于实验阶段,未来将推出稳定版本。
高效处理长文本的双向编码器模型
ModernBERT-base是一个现代化的双向编码器Transformer模型,预训练于2万亿英文和代码数据,原生支持长达8192个token的上下文。该模型采用了Rotary Positional Embeddings (RoPE)、Local-Global Alternating Attention和Unpadding等最新架构改进,使其在长文本处理任务中表现出色。ModernBERT-base适用于需要处理长文档的任务,如检索、分类和大型语料库中的语义搜索。模型训练数据主要为英文和代码,因此可能在其他语言上的表现会有所降低。
一键用AI优化文本,修正错误、调整风格、多语言处理等
AITextTune是一款专为提升写作效率和质量而设计的桌面客户端软件(仅支持Windows系统)。它依托强大的Google Gemini AI技术,能够实时处理文本。主要优点在于操作简便,一键即可完成文本处理,支持多种语言,功能丰富多样,可满足不同的写作需求。该产品定位为写作辅助工具,帮助用户轻松解决写作过程中的各类问题,如修正错误、优化文本风格等。不过,所有功能均需要有效的Gemini API密钥,且由于Google的限制,部分市场可能无法使用。关于价格信息,页面未提及。
先进的AI语言模型
Claude 2 AI是Anthropic AI开发的先进语言模型,为Claude AI聊天机器人提供基础。Claude 2 AI的训练数据包括从互联网各个领域收集的大量数据。Claude的目标是在保持安全性的同时,培养流畅、富有想象力的对话。
一键发送文本到OpenAI GPTs,快速定制
GPTs Enhancer是一个强大的工具,旨在增强与OpenAI GPT模型的交互。它允许用户定制命令,自动将网页上的文本发送到GPT,并快速获得智能反馈。它可用于语言模型训练、写作支持或简单的互动娱乐。
精准批量处理文本转换工具
Chunker AI擅长将文本分解为块,并使用ChatGPT进行批量处理。它的优势在于可以修复扫描文档中的错误、将简要草稿扩展为详细内容、简化科学语言、提取要点和批量翻译国际语言。产品定位于成为文本处理的未来。
多模态大型语言模型,优化图像与文本交互能力
InternVL2_5-4B-MPO-AWQ是一个多模态大型语言模型(MLLM),专注于提升模型在图像和文本交互任务中的表现。该模型基于InternVL2.5系列,并通过混合偏好优化(MPO)进一步提升性能。它能够处理包括单图像和多图像、视频数据在内的多种输入,适用于需要图像和文本交互理解的复杂任务。InternVL2_5-4B-MPO-AWQ以其卓越的多模态能力,为图像-文本到文本的任务提供了一个强大的解决方案。
多模态大型模型,处理文本、图像和视频数据
Valley-Eagle-7B是由字节跳动开发的多模态大型模型,旨在处理涉及文本、图像和视频数据的多种任务。该模型在内部电子商务和短视频基准测试中取得了最佳结果,并在OpenCompass测试中展现出与同规模模型相比的卓越性能。Valley-Eagle-7B结合了LargeMLP和ConvAdapter构建投影器,并引入了VisionEncoder,以增强模型在极端场景下的性能。
PaliGemma 2是一款强大的视觉-语言模型,支持多种语言的图像和文本处理任务。
PaliGemma 2是由Google开发的视觉-语言模型,它结合了SigLIP视觉模型和Gemma 2语言模型的能力,能够处理图像和文本输入,并生成相应的文本输出。该模型在多种视觉-语言任务上表现出色,如图像描述、视觉问答等。其主要优点包括强大的多语言支持、高效的训练架构以及在多种任务上的优异性能。PaliGemma 2的开发背景是为了解决视觉和语言之间的复杂交互问题,帮助研究人员和开发者在相关领域取得突破。
一款由Gradient AI团队开发的高性能语言模型,支持长文本生成和对话。
Llama-3 70B Instruct Gradient 1048k是一款由Gradient AI团队开发的先进语言模型,它通过扩展上下文长度至超过1048K,展示了SOTA(State of the Art)语言模型在经过适当调整后能够学习处理长文本的能力。该模型使用了NTK-aware插值和RingAttention技术,以及EasyContext Blockwise RingAttention库,以高效地在高性能计算集群上进行训练。它在商业和研究用途中具有广泛的应用潜力,尤其是在需要长文本处理和生成的场景中。
增强文本与视觉任务处理能力的开源模型。
Mistral-Small-3.1-24B-Base-2503 是一款具有 240 亿参数的先进开源模型,支持多语言和长上下文处理,适用于文本与视觉任务。它是 Mistral Small 3.1 的基础模型,具有较强的多模态能力,适合企业需求。
Python自然语言处理工具包
NLTK是一个领先的Python平台,用于处理人类语言数据。它提供了易于使用的接口,用于访问50多个语料库和词汇资源,如WordNet,并提供了一套文本处理库,用于分类、标记、解析和语义推理。它还提供了工业级NLP库的封装,并有一个活跃的讨论论坛。NLTK适用于语言学家、工程师、学生、教育者、研究人员和行业用户。NLTK可以免费使用,并且是一个开源的社区驱动项目。

© 2026 AIbase 备案号:闽ICP备08105208号-14