Replicate上的“SDXL fine-tunes”收藏包含了一系列基于SDXL模型的精选微调模型。这些微调模型利用大型生成模型SDXL,针对特定的视觉风格、内容或主题进行了优化和调整,以产生高质量的图像生成效果。包括但不限于表情符号、动画风格、应用图标和特定电影艺术风格。每个微调模型都被设计来在特定的视觉任务上产生特定风格的图像,支持创作者、设计师和开发者以更少的努力创造出更丰富、更具特色的视觉内容。通过Replicate平台,用户可以直接访问和运行这些微调模型,将这些先进的图像生成能力应用到自己的项目中,无论是进行创意探索还是解决实际的设计挑战。
需求人群:
"用于图像生成、创意探索、设计挑战解决等。"
使用场景示例:
fofr/sdxl-emoji
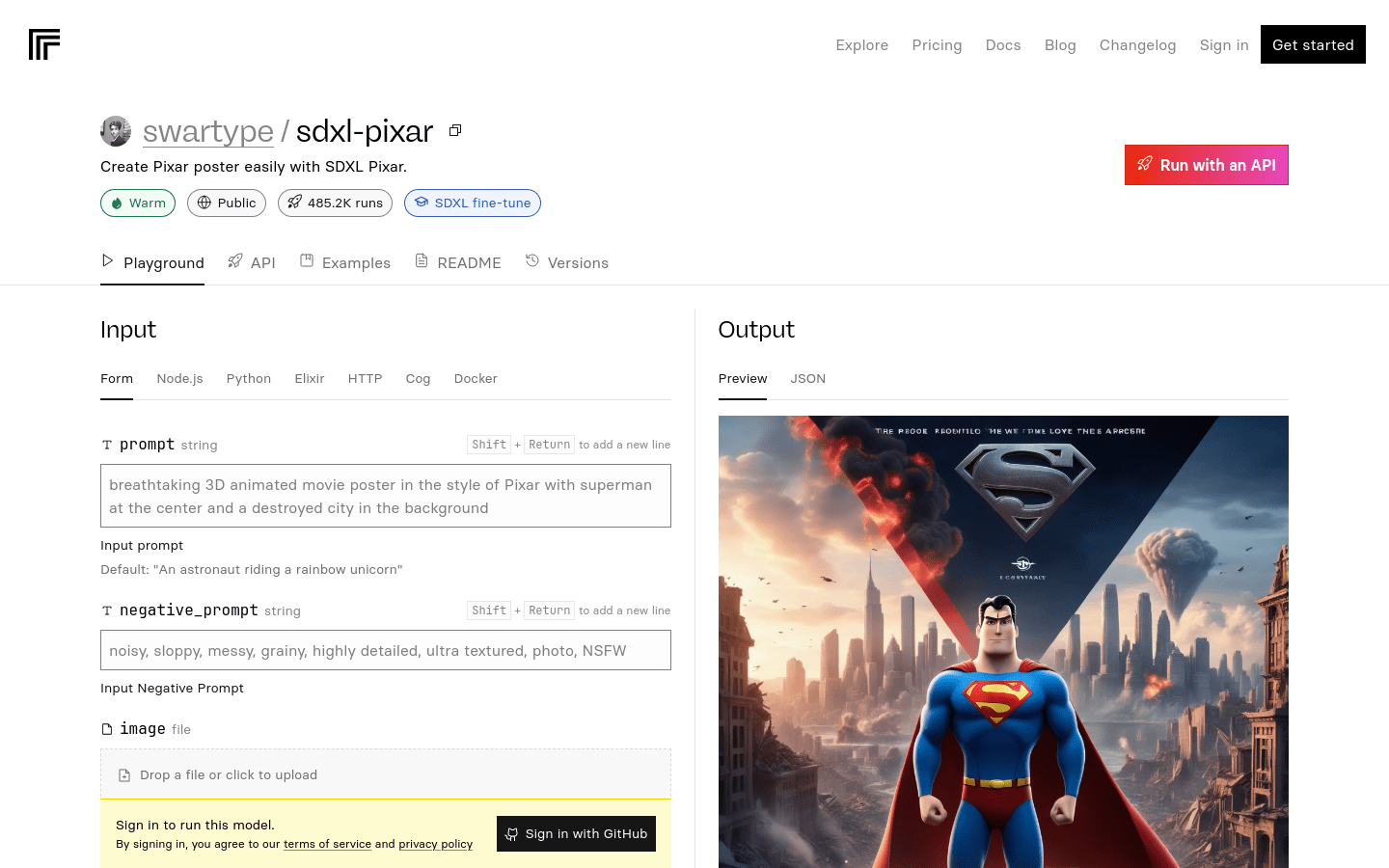
swartype/sdxl-pixar
mejiabrayan/logoai
产品特色:
利用SDXL模型进行微调
生成特定风格的图像
支持创作者、设计师和开发者
浏览量:219
最新流量情况
月访问量
2341.84k
平均访问时长
00:06:31
每次访问页数
6.54
跳出率
38.04%
流量来源
直接访问
57.28%
自然搜索
30.83%
邮件
0.05%
外链引荐
7.96%
社交媒体
3.59%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
巴西
5.06%
中国
3.86%
法国
3.99%
印度
8.45%
美国
16.79%
基于SDXL模型的精选微调模型收藏。
Replicate上的“SDXL fine-tunes”收藏包含了一系列基于SDXL模型的精选微调模型。这些微调模型利用大型生成模型SDXL,针对特定的视觉风格、内容或主题进行了优化和调整,以产生高质量的图像生成效果。包括但不限于表情符号、动画风格、应用图标和特定电影艺术风格。每个微调模型都被设计来在特定的视觉任务上产生特定风格的图像,支持创作者、设计师和开发者以更少的努力创造出更丰富、更具特色的视觉内容。通过Replicate平台,用户可以直接访问和运行这些微调模型,将这些先进的图像生成能力应用到自己的项目中,无论是进行创意探索还是解决实际的设计挑战。
图像条件扩散模型的微调工具
diffusion-e2e-ft是一个开源的图像条件扩散模型微调工具,它通过微调预训练的扩散模型来提高特定任务的性能。该工具支持多种模型和任务,如深度估计和法线估计,并提供了详细的使用说明和模型检查点。它在图像处理和计算机视觉领域具有重要应用,能够显著提升模型在特定任务上的准确性和效率。
OFT可有效稳定微调文本到图像扩散模型
Controlling Text-to-Image Diffusion研究了如何有效引导或控制强大的文本到图像生成模型进行各种下游任务。提出了正交微调(OFT)方法,可以保持模型的生成能力。OFT可以保持神经元之间的超球面能量不变,防止模型坍塌。作者考虑了两种重要的微调任务:主体驱动生成和可控生成。结果表明,OFT方法在生成质量和收敛速度上优于现有方法。
提高图像生成模型的美感
Emu是一个用于提高图像生成模型美感的质量调整工具。它可以通过有限的高质量图像进行微调,从而显著提高生成质量。Emu在1.1亿个图像-文本对上进行了预训练,并使用了几千个精心挑选的高质量图像进行了微调。与仅进行预训练的模型相比,Emu的胜率达到了82.9%。与最先进的SDXLv1.0相比,Emu在视觉吸引力方面的偏好率分别为68.4%和71.3%。Emu还可以用于其他架构,包括像素扩散和掩蔽生成变压器模型。
LLaVA-3b是一种基于Dolphin 2.6 Phi进行微调的模型,使用SigLIP 400M的视觉塔以LLaVA方式进行微调。模型具有多个图像标记、使用视觉编码器的最新层输出等特点。
LLaVA-3b是一种基于Dolphin 2.6 Phi进行微调的模型,使用SigLIP 400M的视觉塔以LLaVA方式进行微调。模型具有多个图像标记、使用视觉编码器的最新层输出等特点。此模型基于Phi-2,受微软研究许可证约束,禁止商业使用。感谢ML Collective提供的计算资源积分。
连接不同语言模型和生成视觉模型进行文本到图像生成
LaVi-Bridge是一种针对文本到图像扩散模型设计的桥接模型,能够连接各种预训练的语言模型和生成视觉模型。它通过利用LoRA和适配器,提供了一种灵活的插拔式方法,无需修改原始语言和视觉模型的权重。该模型与各种语言模型和生成视觉模型兼容,可容纳不同的结构。在这一框架内,我们证明了通过整合更高级的模块(如更先进的语言模型或生成视觉模型)可以明显提高文本对齐或图像质量等能力。该模型经过大量评估,证实了其有效性。
图像生成模型,提供前所未有的风格控制。
Frames是Runway Research推出的最新图像生成基础模型,它在风格控制和视觉保真度方面迈出了一大步。该模型擅长保持风格一致性,同时允许广泛的创意探索,能够为项目建立特定的外观,并可靠地生成忠实于您美学的变化。Frames的推出标志着在创意工作流程中,用户可以构建更多属于自己的世界,实现更大、更无缝的创意流程。
小红书真实感风格模型,生成极度真实自然的日常照片
Flux_小红书真实风格模型是一款专注于生成极度真实自然日常照片的AI模型。它利用最新的人工智能技术,通过深度学习算法,能够生成具有小红书真实感风格的照片。该模型特别适合需要在社交媒体上发布高质量、真实感照片的用户,以及进行艺术创作和设计工作的专业人士。模型提供了多种参数设置,以适应不同的使用场景和需求。
朱雀大模型检测,精准识别AI生成图像,助力内容真实性鉴别。
朱雀大模型检测是腾讯推出的一款AI检测工具,主要功能是检测图片是否由AI模型生成。它经过大量自然图片和生成图片的训练,涵盖摄影、艺术、绘画等内容,可检测多类主流文生图模型生成图片。该产品具有高精度检测、快速响应等优点,对于维护内容真实性、打击虚假信息传播具有重要意义。目前暂未明确其具体价格,但从功能来看,主要面向需要进行内容审核、鉴别真伪的机构和个人,如媒体、艺术机构等。
一款基于指令微调的大型语言模型
Mistral-7B-Instruct-v0.2 是一款基于 Mistral-7B-v0.2 模型进行指令微调的大型语言模型。它拥有 32k 的上下文窗口和 1e6 的 Rope Theta 值等特性。该模型可以根据给定的指令生成相应的文本输出,支持各种任务,如问答、写作、翻译等。通过指令微调,模型可以更好地理解和执行指令。虽然该模型目前还没有针对性的审核机制,但未来将继续优化,以支持更多场景的部署。
基于强化学习技术的视觉思考模型,理科测试行业领先
Kimi视觉思考模型k1是基于强化学习技术打造的AI模型,原生支持端到端图像理解和思维链技术,并将能力扩展到数学之外的更多基础科学领域。在数学、物理、化学等基础科学学科的基准能力测试中,k1模型的表现超过了全球标杆模型。k1模型的发布标志着AI在视觉理解和思考能力上的新突破,尤其在处理图像信息和基础科学问题上展现出色的表现。
Stability AI 生成模型是一个开源的生成模型库。
Stability AI 生成模型是一个开源的生成模型库,提供了各种生成模型的训练、推理和应用功能。该库支持各种生成模型的训练,包括基于 PyTorch Lightning 的训练,提供了丰富的配置选项和模块化的设计。用户可以使用该库进行生成模型的训练,并通过提供的模型进行推理和应用。该库还提供了示例训练配置和数据处理的功能,方便用户进行快速上手和定制。
PaliGemma 2是一个强大的视觉-语言模型,支持多种视觉语言任务。
PaliGemma 2是一个由Google开发的视觉-语言模型,继承了Gemma 2模型的能力,能够处理图像和文本输入并生成文本输出。该模型在多种视觉语言任务上表现出色,如图像描述、视觉问答等。其主要优点包括强大的多语言支持、高效的训练架构和广泛的适用性。该模型适用于需要处理视觉和文本数据的各种应用场景,如社交媒体内容生成、智能客服等。
OpenAI下一代AI图像生成模型,可免费在线试用,用于多类型视觉创作。
GPT Image 2是OpenAI推出的下一代AI图像生成模型,可通过网页在线使用。其重要性在于能快速将文本转化为高分辨率的图像和视频,满足多领域的视觉创作需求。主要优点包括对提示理解更准确、生成图像质量更高、支持精确图像编辑、能生成结构化视觉内容、文本渲染清晰准确、支持多语言、风格多样且一致性好,还能结合实时网络信息。该产品提供免费试用,定位为一站式AI图像和视频生成平台,适用于品牌营销、电商、创意设计等领域。
文本到图像生成中风格保留的 InstantStyle。
InstantStyle 是一个通用框架,利用两种简单但强大的技术,实现对参考图像中风格和内容的有效分离。其原则包括将内容从图像中分离出来、仅注入到风格块中,并提供样式风格的合成和图像生成等功能。InstantStyle 可以帮助用户在文本到图像生成过程中保持风格,为用户提供更好的生成体验。
先进的视觉基础模型,支持多种视觉和视觉-语言任务。
Florence-2是由微软开发的高级视觉基础模型,采用基于提示的方法处理广泛的视觉和视觉-语言任务。该模型能够解释简单的文本提示,执行如描述、目标检测和分割等任务。它利用包含54亿个注释的5.4亿张图像的FLD-5B数据集,精通多任务学习。模型的序列到序列架构使其在零样本和微调设置中都表现出色,证明其为有竞争力的视觉基础模型。
对视觉生成模型进行基准测试
GenAI-Arena是一个用于在野外对视觉生成模型进行基准测试的平台。用户可以匿名参与竞技,对比目标模型的表现,并投票选出更优秀的模型。平台支持不同领域的匿名模型对决,帮助用户找到最佳的条件图像生成模型。用户可以点击“New Round”开始新的对决,并通过点击按钮投票选择更优秀的模型。
加速模型评估和微调的智能评估工具
SFR-Judge 是 Salesforce AI Research 推出的一系列评估模型,旨在通过人工智能技术加速大型语言模型(LLMs)的评估和微调过程。这些模型能够执行多种评估任务,包括成对比较、单项评分和二元分类,同时提供解释,避免黑箱问题。SFR-Judge 在多个基准测试中表现优异,证明了其在评估模型输出和指导微调方面的有效性。
动漫风格图像生成模型
Momo XL是一个基于SDXL的动漫风格模型,经过微调,能够生成高质量、细节丰富、色彩鲜艳的动漫风格图像。它特别适合艺术家和动漫爱好者使用,并且支持基于标签的提示,确保输出结果的准确性和相关性。此外,Momo XL还兼容大多数LoRA模型,允许用户进行多样化的定制和风格转换。
轻量级代码库,用于高效微调Mistral模型。
mistral-finetune是一个轻量级的代码库,它基于LoRA训练范式,允许在冻结大部分权重的情况下,只训练1-2%的额外权重,以低秩矩阵微扰的形式进行微调。它被优化用于多GPU单节点训练设置,对于较小模型,例如7B模型,单个GPU就足够了。该代码库旨在提供简单、有指导意义的微调入口,特别是在数据格式化方面,并不旨在涵盖多种模型架构或硬件类型。
大型语言模型是视觉推理协调器
Cola是一种使用语言模型(LM)来聚合2个或更多视觉-语言模型(VLM)输出的方法。我们的模型组装方法被称为Cola(COordinative LAnguage model or visual reasoning)。Cola在LM微调(称为Cola-FT)时效果最好。Cola在零样本或少样本上下文学习(称为Cola-Zero)时也很有效。除了性能提升外,Cola还对VLM的错误更具鲁棒性。我们展示了Cola可以应用于各种VLM(包括大型多模态模型如InstructBLIP)和7个数据集(VQA v2、OK-VQA、A-OKVQA、e-SNLI-VE、VSR、CLEVR、GQA),并且它始终提高了性能。
Animagine XL 4.0 是一款专注于动漫风格的Stable Diffusion XL模型,专为生成高质量动漫图像而设计。
Animagine XL 4.0 是一款基于Stable Diffusion XL 1.0微调的动漫主题生成模型。它使用了840万张多样化的动漫风格图像进行训练,训练时长达到2650小时。该模型专注于通过文本提示生成和修改动漫主题图像,支持多种特殊标签,可控制图像生成的不同方面。其主要优点包括高质量的图像生成、丰富的动漫风格细节以及对特定角色和风格的精准还原。该模型由Cagliostro Research Lab开发,采用CreativeML Open RAIL++-M许可证,允许商业使用和修改。
强大的开源视觉语言模型
CogVLM是一个强大的开源视觉语言模型。CogVLM-17B拥有100亿个视觉参数和70亿个语言参数。CogVLM-17B在10个经典的跨模态基准测试中取得了最先进的性能,包括NoCaps、Flicker30k字幕、RefCOCO、RefCOCO+、RefCOCOg、Visual7W、GQA、ScienceQA、VizWiz VQA和TDIUC,并在VQAv2、OKVQA、TextVQA、COCO字幕等方面排名第二,超过或与PaLI-X 55B相匹配。CogVLM还可以与您就图像进行对话。
视觉语言模型,结合图像和文本信息进行智能处理。
Aquila-VL-2B模型是一个基于LLava-one-vision框架训练的视觉语言模型(VLM),选用Qwen2.5-1.5B-instruct模型作为语言模型(LLM),并使用siglip-so400m-patch14-384作为视觉塔。该模型在自建的Infinity-MM数据集上进行训练,包含约4000万图像-文本对。该数据集结合了从互联网收集的开源数据和使用开源VLM模型生成的合成指令数据。Aquila-VL-2B模型的开源,旨在推动多模态性能的发展,特别是在图像和文本的结合处理方面。
通过强化学习微调大型视觉-语言模型作为决策代理
RL4VLM是一个开源项目,旨在通过强化学习微调大型视觉-语言模型,使其成为能够做出决策的智能代理。该项目由Yuexiang Zhai, Hao Bai, Zipeng Lin, Jiayi Pan, Shengbang Tong, Alane Suhr, Saining Xie, Yann LeCun, Yi Ma, Sergey Levine等研究人员共同开发。它基于LLaVA模型,并采用了PPO算法进行强化学习微调。RL4VLM项目提供了详细的代码库结构、入门指南、许可证信息以及如何引用该研究的说明。
使用扩散指引对文本感知图像进行细粒度风格控制
DreamWalk是一种基于扩散指引的文本感知图像生成方法,可对图像的风格和内容进行细粒度控制,无需对扩散模型进行微调或修改内部层。支持多种风格插值和空间变化的引导函数,可广泛应用于各种扩散模型。
先进的多模态图像生成模型,结合文本提示和视觉参考生成高质量图像。
Qwen2vl-Flux是一个结合了Qwen2VL视觉语言理解能力的FLUX框架的先进多模态图像生成模型。该模型擅长基于文本提示和视觉参考生成高质量图像,提供卓越的多模态理解和控制。产品背景信息显示,Qwen2vl-Flux集成了Qwen2VL的视觉语言能力,增强了FLUX的图像生成精度和上下文感知能力。其主要优点包括增强的视觉语言理解、多种生成模式、结构控制、灵活的注意力机制和高分辨率输出。

© 2026 AIbase 备案号:闽ICP备08105208号-14