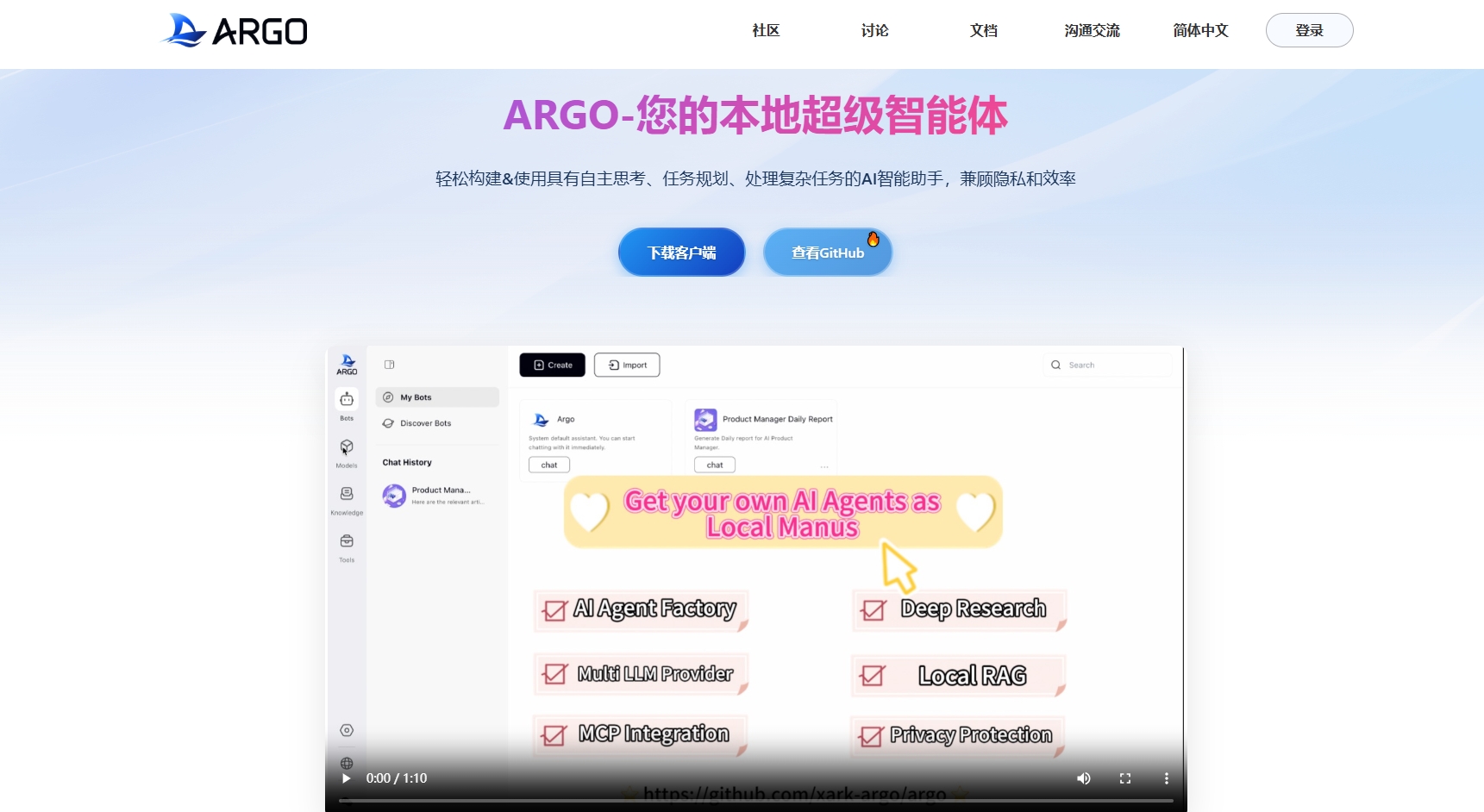
ARGO 是一个多平台 AI 客户端,旨在为用户提供强大的人工智能助手,具备自主思考、任务规划和复杂任务处理的能力。其主要优势在于在用户设备上本地运行,确保数据隐私与安全。适合需要高效管理和处理任务的用户群体,支持多种操作系统。永久开源免费。
需求人群:
"该产品适合需要高效处理文本和知识管理的个人和企业用户,尤其是对数据安全和隐私有较高要求的用户群体。它可以帮助用户快速部署和使用大语言模型,提升工作效率,同时支持本地化部署,确保数据不外泄。此外,其扩展工具插件功能为开发者提供了更多可能性,使其能够根据自身需求定制和扩展模型能力。"
使用场景示例:
使用 ARGO 规划旅行行程,自动生成行程表和建议。
利用 ARGO 进行行业分析,获取数据支持和决策建议。
通过 ARGO 解决法律咨询问题,自动汇总相关法律文件和建议。
产品特色:
高度整合的智能体平台,提升数字助手的智能化水平。
集成 Ollama 和主流供应商,方便用户获取和使用 AI 模型。
智能体工厂,支持用户自定义场景智能体,快速生成所需助手。
DeepResearch 能力,能够处理复杂任务,如深度调研。
本地 RAG 知识库,支持动态同步更新文件及信息。
MCP 协议支持,集成多种实用工具如浏览器控制。
隐私保护措施,确保用户数据安全,本地存储。
多平台支持,提供 Windows、macOS 及 Docker 版本。
使用教程:
访问 ARGO 官网并下载适合您操作系统的客户端。
安装并启动 ARGO,创建您的用户账户。
选择所需的智能体功能或场景,进行简单配置。
上传相关文件或输入任务要求,开始使用智能助手。
根据生成的建议或结果进行调整,优化任务处理流程。
浏览量:534
基于RAG(Retrieval-Augmented Generation)技术的智能对话系统
RAG Web UI 是一个基于 RAG 技术的智能对话系统,它结合了文档检索和大型语言模型,能够为企业和个人提供基于知识库的智能问答服务。该系统采用前后端分离架构,支持多种文档格式(如 PDF、DOCX、Markdown、Text)的智能管理,包括自动分块和向量化处理。其对话引擎支持多轮对话和引用标注,能够提供精准的知识检索和生成服务。该系统还支持高性能向量数据库(如 ChromaDB、Qdrant)的灵活切换,具有良好的扩展性和性能优化。作为一种开源项目,它为开发者提供了丰富的技术实现和应用场景,适合用于构建企业级知识管理系统或智能客服平台。
您的本地超级智能体,构建自主思考的 AI 助手,兼顾隐私与效率。
ARGO 是一个多平台 AI 客户端,旨在为用户提供强大的人工智能助手,具备自主思考、任务规划和复杂任务处理的能力。其主要优势在于在用户设备上本地运行,确保数据隐私与安全。适合需要高效管理和处理任务的用户群体,支持多种操作系统。永久开源免费。
开源的RAG应用日志工具
RAG-logger是一个为检索增强生成(Retrieval-Augmented Generation, RAG)应用设计的开源日志工具。它是一个轻量级的、针对RAG特定日志需求的开源替代方案,专注于为RAG应用提供全面的日志记录功能,包括查询跟踪、检索结果记录、LLM交互记录以及逐步性能监控。它采用基于JSON的日志格式,支持每日日志组织、自动文件管理和元数据丰富化。RAG-logger以其开源、轻量级和专注于RAG应用的特性,为开发者提供了一个有效的工具来监控和分析RAG应用的性能。
AI驱动的深度研究工具
Gemini Deep Research是Google推出的一款AI驱动的深度研究工具,旨在帮助用户快速、准确地获取复杂话题的全面信息。它通过AI技术自动探索网络,搜集和分析数据,最终生成包含关键发现和原始来源链接的综合报告。这一工具不仅节省了用户大量的研究时间,还提高了信息获取的效率和准确性。
掌握RAG技术,提升AI生成内容的准确性和相关性。
Retrieval-Augmented Generation (RAG) 是一种前沿技术,通过整合外部知识源来增强生成模型的能力,提高生成内容的质量和可靠性。LangChain是一个强大的框架,专为构建和部署稳健的语言模型应用而设计。本教程系列将提供全面的、分步骤的指南,帮助您使用LangChain实现RAG,从基础RAG流程的介绍开始,逐步深入到查询转换、文档嵌入、路由机制、查询构建、索引策略、检索技术以及生成阶段,最终将所有概念整合到一个实际场景中,展示RAG的强大和灵活性。
AI驱动的深度研究工具
Inquisite是一个利用人工智能技术进行深度研究的平台,它通过AI代理引擎和强大的文档构建功能,帮助用户快速地在复杂主题上进行深入研究,并构建基于研究的高价值报告、文章和演示文稿。Inquisite与传统搜索引擎不同,它使用AI代理以迭代过程查找、审查和排名信息源,以识别最相关、最可靠的信息,从而为用户提供可信的洞察,并引用可信的来源。
一个为RAG(检索增强生成)AI助手设计的React组件,可快速集成到Next.js应用中。
该产品是一个React组件,专为RAG(检索增强生成)AI助手设计。它结合了Upstash Vector进行相似性搜索、Together AI作为LLM(大型语言模型)以及Vercel AI SDK用于流式响应。这种组件化设计使得开发者可以快速将RAG能力集成到Next.js应用中,极大地简化了开发流程,同时提供了高度的可定制性。其主要优点包括响应式设计、支持流式响应、持久化聊天历史以及支持暗黑/浅色模式等。该组件主要面向需要在Web应用中集成智能聊天功能的开发者,尤其是那些使用Next.js框架的团队。它通过简化集成过程,降低了开发成本,同时提供了强大的功能。
一个集成了Django、Llamaindex和Google Drive的RAG应用框架。
Omakase RAG Orchestrator是一个旨在解决构建RAG应用时遇到的挑战的项目,它通过提供一个综合的Web应用程序和API来封装大型语言模型(LLMs)及其包装器。该项目整合了Django、Llamaindex和Google Drive,以提高应用的可用性、可扩展性和数据及用户访问管理。
一个适合学习、使用、自主扩展的RAG系统。
Easy-RAG是一个检索增强生成(RAG)系统,它不仅适合学习者了解和掌握RAG技术,同时也便于开发者使用和进行自主扩展。该系统通过集成知识图谱提取解析工具、rerank重新排序机制以及faiss向量数据库等技术,提高了检索效率和生成质量。
开源的RAG基础聊天工具,与文档对话。
kotaemon是一个开源的、基于RAG(Retrieval-Augmented Generation)模型的工具,旨在通过聊天界面与用户文档进行交互。它支持多种语言模型API提供商和本地语言模型,提供了一个干净、可定制的用户界面,适用于终端用户进行文档问答以及开发者构建自己的RAG问答流程。
Outset.ai -- 深度洞察,AI助力
Outset.ai是一个AI智能辅助研究平台,通过AI主持访谈,为您提供所需的深度洞察。借助Outset.ai,您可以进行1000次同时访谈,无论是哪种语言。我们的AI面试官将与参与者进行丰富的讨论,并深入探究背后的原因。同时,我们的AI引擎将为您分析和综合研究项目的结果,生成摘要、提取和计数主题,并突出强大的原话,以便讲述您的故事。Outset.ai让您快速获取深入的洞察。
CNKI AI 学术研究助手是基于 AI 技术的智能化学术研究助手,实现问答式增强检索和生成式知识服务。
CNKI AI 学术研究助手是同方知网结合 AI 技术推出的全新智能化服务,能够简化繁复的检索与研究流程,提供快速的问答式检索和智能创作辅助。该产品背景信息丰富,定位于提升学术研究效率。
QwQ是一款专注于深度推理能力的AI研究模型。
QwQ(Qwen with Questions)是一款由Qwen团队开发的实验性研究模型,旨在提升人工智能的推理能力。它以一种哲学精神,对每个问题都抱有真正的好奇和怀疑,通过自我提问和反思来寻求更深层次的真理。QwQ在数学和编程领域表现出色,尤其是在处理复杂问题时。尽管它仍在学习和成长,但它已经展现出了在技术领域深度推理的重要潜力。
通过深度研究生成文章,支持自定义知识或公共互联网资源。
CustomGPT.ai Researcher 是一款基于人工智能的深度研究工具,旨在帮助用户快速生成高质量的文章。它结合了先进的自然语言处理技术,能够从用户提供的自定义知识库或公共互联网资源中提取信息,并生成结构化、逻辑清晰的文章。该工具对于需要进行大量研究和写作的用户来说非常实用,能够显著提高工作效率,节省时间和精力。其价格和具体定位尚未明确,但根据其功能和目标受众,可能主要面向企业和专业人士。
定制深度个性化智能体
通义星尘是一个提供定制深度个性化智能体能力的产品,可以快速创造拥有独特人设和风格的智能体,并在不同场景中进行丰富的互动。它具备拟人化、场景化、多模态和共情的对话能力,以及复杂任务执行能力,可应用于IP复刻、恋爱&交友、萌宠&养成、游戏NPC、教育&服务等多个场景。通义星尘可以深度定义人设,包括基本信息、说话风格、专业知识或特殊技能等。它还能创造丰富的事件,如时空背景、故事情节、人物关系、任务和目标等。用户可以通过语言聊天、肢体动作、图片表情包等多种形式与通义星尘进行互动,并与其建立记忆、关系和情感的链接。
人工智能入门教程网站,提供全面的机器学习与深度学习知识。
该网站由作者从 2015 年开始学习机器学习和深度学习,整理并编写的一系列实战教程。涵盖监督学习、无监督学习、深度学习等多个领域,既有理论推导,又有代码实现,旨在帮助初学者全面掌握人工智能的基础知识和实践技能。网站拥有独立域名,内容持续更新,欢迎大家关注和学习。
一个社区驱动的深度研究框架,结合语言模型与多种工具。
DeerFlow 是一个深度研究框架,旨在结合语言模型与如网页搜索、爬虫及 Python 执行等专用工具,以推动深入研究工作。该项目源于开源社区,强调贡献回馈,具备多种灵活的功能,适合各类研究需求。
投资研究深度问答平台
投搜AI是一个专注于投资研究的深度问答平台,它通过AI技术为用户提供个股分析、财报解读、行业趋势等深度内容。该平台利用先进的数据分析技术,帮助投资者快速获取关键信息,支持投资决策。产品背景信息显示,投搜AI旨在为投资者提供一个全面、高效的投资研究工具,其主要优点在于能够提供实时的市场数据和深度的行业分析,适合专业投资者和分析师使用。目前,该平台提供免费试用,具体价格信息需进一步查询。
基于GPT算法的智能聊天机器人
Open-GPT 开放版·直连GPT聊天机器人,是一款基于的GPT算法开发的聊天机器人,具备较高的智能度和语言理解能力,可以进行智能问答、闲聊、教育咨询等多种交互,为用户提供更加便利和快捷的服务。系统聊天记录不会被上传到第三方服务器,用户的隐私得到了更好的保护。
智能搜索API,提供高效信息检索。
RAG Search API是一个由thinkany.ai开发的智能搜索API,它利用RAG(Retrieval-Augmented Generation)技术,结合了检索和生成的特点,为用户提供高效、准确的信息检索服务。该API支持自定义配置,包括搜索数量、是否进行重排、过滤等,能够满足不同用户的需求。
研究文献的智能助手
StudyRecon是一款旨在简化和协助研究过程中文献综述的智能工具。它通过提供学术景观的全景视图、查询建议、跨数据库搜索、关键词可视化、论文摘要和注释等功能,帮助用户快速获取全面准确的文献资料,从而提高文献综述的质量与效率。
转换PDF文件,即时聊天与PDF并获取深度答案
PDF Flex是一款能够帮助用户转换PDF文件格式并与PDF进行即时聊天的工具。它可以将PDF文件转换成多种格式,并且可以向PDF提问问题并立即获得详细回答,提高研究效率。PDF Flex还提供了丰富的功能和使用场景,适用于个人和企业用户。定价方案包括免费和付费版本,用户可以根据自己的需求选择合适的版本。
DeepPDF是一个AI研究助手,用于深度学习PDF文档,提供聊天、摘要、翻译比较以及关键术语、图片和公式分析功能。
DeepPDF是一个AI工具,通过聊天、生成摘要、比较翻译、解释关键术语、分析图片和公式,帮助用户深入了解和更好地学习PDF文档。
一个简单的代理框架,支持浏览器使用、深度研究等功能。
Minion Agent 是一个简单而强大的代理框架,能够与浏览器交互,支持深度研究、自动规划等功能,适用于需要进行复杂任务和研究的用户。它提供了一种灵活的工具集,使开发者能够轻松集成不同的模型和工具。该框架不仅提高了工作的效率,还为用户提供了便捷的使用体验,适合各类科研和商业应用。该产品是开源的,用户可以自由使用和修改。
将简单输入转化为多模态内容 - 文档、幻灯片、表格和深度研究、播客及网页。
Skywork是一款先驱的AI办公智能体,可以将简单的输入转化为多模态内容,包括文档、幻灯片、表格、深度研究、播客和网页。它通过深度研究和多种工具提供高效的办公体验。
AI 驱动的智能搜索工具,助您深入研究。
Firesearch 是一款利用先进的人工智能技术,帮助用户进行深度研究的搜索工具。它结合了 Firecrawl 和 LangGraph 的强大能力,可以提供更为精准和高效的搜索体验,特别适合需要大量信息和数据分析的用户。该工具以其高效的智能搜索引擎、简洁的界面和强大的数据处理能力,帮助用户更快地找到所需的信息。
构建RAG驱动的内部工具
RagHost是一个提供简单API的服务,可以上传文档并进行查询。您可以在几分钟内构建一个内部工具,用于搜索文档或回答问题。RagHost使用检索增强生成技术,通过将上下文数据与问题一起提供给模型,从而为您的模型提供所需的上下文。您无需处理文档解析、分块和向量嵌入等复杂工作,我们为您完成。RagHost支持自定义的分块策略,并提供流式响应以确保用户获得及时的回答。我们正在开发公平定价策略,使您能够轻松使用RagHost而无需担心高额费用。

© 2026 AIbase 备案号:闽ICP备08105208号-14