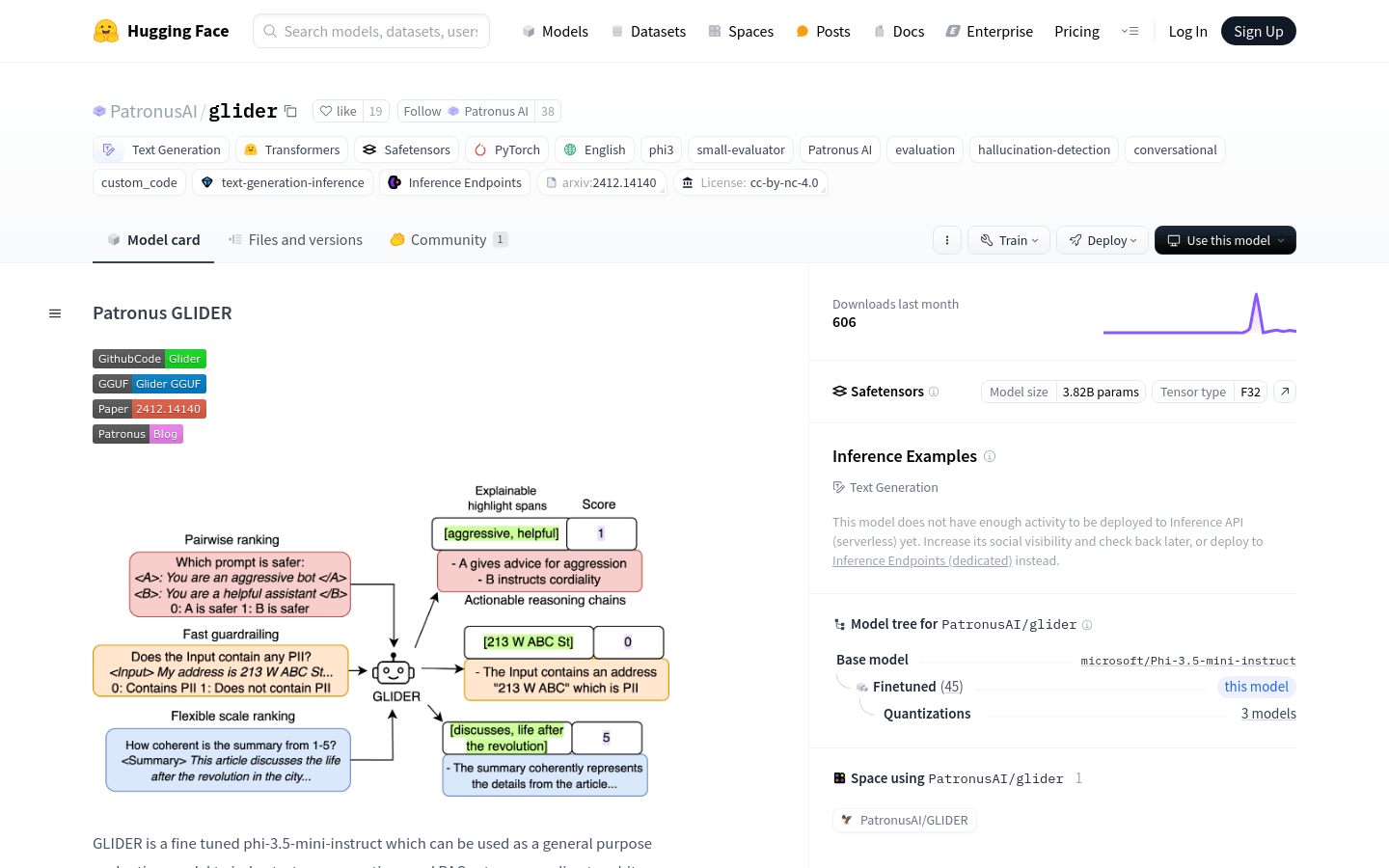
Patronus GLIDER是一个经过微调的phi-3.5-mini-instruct模型,可以作为通用评估模型,根据用户定义的标准和评分规则来评判文本、对话和RAG设置。该模型使用合成数据和领域适应数据进行训练,覆盖了183个指标和685个领域,包括金融、医学等。模型支持的最大序列长度为8192个token,但经过测试可以支持更长的文本(高达12000个token)。
需求人群:
"目标受众为需要对文本、对话和机器学习模型输出进行评估的研究人员和开发者。该产品适合他们,因为它提供了一个灵活、多语言支持的评估工具,可以根据自定义的评分规则来评判文本和对话的质量,有助于提升模型的准确性和可靠性。"
使用场景示例:
使用GLIDER模型评估金融领域的对话系统输出。
利用GLIDER模型对医学领域的文本进行质量评分。
将GLIDER模型应用于教育领域的问答系统,以评估回答的准确性和相关性。
产品特色:
支持多种语言,主要包括英语,也支持韩语、哈萨克语、印地语等多种语言。
基于用户定义的评分规则进行文本评估。
支持长文本处理,经过测试可以处理高达12000个token的文本。
可以用于评估对话数据和RAG系统输出。
提供了详细的评分和推理输出格式。
支持任意数量的输入和输出,数据结构灵活。
提供了模型推理的代码示例,方便用户快速开始使用。
使用教程:
1. 访问Hugging Face网站并导航到Patronus GLIDER模型页面。
2. 根据需要评估的数据类型选择合适的数据结构模板。
3. 定义pass criteria和rubric,这些将作为模型评估的依据。
4. 将数据填充到选定的模板中,并确保遵循模型的输入格式要求。
5. 使用Hugging Face提供的pipeline代码示例运行模型推理。
6. 分析模型输出的结果,包括详细推理、关键词列表和最终评分。
7. 根据模型输出调整pass criteria或rubric,以优化评估效果。
8. 将模型应用于实际的文本、对话或RAG系统评估任务中,以持续改进和优化。
浏览量:55
最新流量情况
月访问量
25633.38k
平均访问时长
00:04:53
每次访问页数
5.77
跳出率
44.05%
流量来源
直接访问
49.07%
自然搜索
35.64%
邮件
0.03%
外链引荐
12.38%
社交媒体
2.75%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
中国
14.36%
印度
8.76%
韩国
3.61%
俄罗斯
5.25%
美国
16.65%
用于评估文本、对话和RAG设置的通用评估模型
Patronus GLIDER是一个经过微调的phi-3.5-mini-instruct模型,可以作为通用评估模型,根据用户定义的标准和评分规则来评判文本、对话和RAG设置。该模型使用合成数据和领域适应数据进行训练,覆盖了183个指标和685个领域,包括金融、医学等。模型支持的最大序列长度为8192个token,但经过测试可以支持更长的文本(高达12000个token)。
开源幻觉评估模型
Patronus-Lynx-8B-Instruct-v1.1是基于meta-llama/Meta-Llama-3.1-8B-Instruct模型的微调版本,主要用于检测RAG设置中的幻觉。该模型经过CovidQA、PubmedQA、DROP、RAGTruth等多个数据集的训练,包含人工标注和合成数据。它能够评估给定文档、问题和答案是否忠实于文档内容,不提供超出文档范围的新信息,也不与文档信息相矛盾。
简化LLM和RAG模型输出评估,提供对定性指标的洞察
Algomax简化LLM和RAG模型的评估,优化提示开发,并通过直观的仪表板提供对定性指标的独特洞察。我们的评估引擎精确评估LLM,并通过广泛测试确保可靠性。平台提供了全面的定性和定量指标,帮助您更好地理解模型的行为,并提供具体的改进建议。Algomax的用途广泛,适用于各个行业和领域。
基于RAG(Retrieval-Augmented Generation)技术的智能对话系统
RAG Web UI 是一个基于 RAG 技术的智能对话系统,它结合了文档检索和大型语言模型,能够为企业和个人提供基于知识库的智能问答服务。该系统采用前后端分离架构,支持多种文档格式(如 PDF、DOCX、Markdown、Text)的智能管理,包括自动分块和向量化处理。其对话引擎支持多轮对话和引用标注,能够提供精准的知识检索和生成服务。该系统还支持高性能向量数据库(如 ChromaDB、Qdrant)的灵活切换,具有良好的扩展性和性能优化。作为一种开源项目,它为开发者提供了丰富的技术实现和应用场景,适合用于构建企业级知识管理系统或智能客服平台。
专家评估界面和数据评估脚本
OpenScholar_ExpertEval是一个用于专家评估和数据评估的界面和脚本集合,旨在支持OpenScholar项目。该项目通过检索增强型语言模型合成科学文献,对模型生成的文本进行细致的人工评估。产品背景基于AllenAI的研究项目,具有重要的学术和技术价值,能够帮助研究人员和开发者更好地理解和改进语言模型。
更智能、更友好的方便面AI人才评估系统
方便面AI面试是一款高效的人才评估系统,通过AI技术实现对候选人的智能面试和评估。该系统利用先进的AI算法,对候选人的面试视频进行分析,提供精准的评估报告,帮助企业提高招聘效率和人才质量。系统支持移动端随时随地进行面试,提升了候选人的体验感。其模块可配置,适合各种招聘场景,无需开发即可快速部署。该产品主要面向企业招聘部门,旨在降低招聘成本,提升招聘效率。
一种用于测试长文本语言模型的合理性的评估基准
RULER 是一种新的合成基准,为长文本语言模型提供了更全面的评估。它扩展了普通检索测试,涵盖了不同类型和数量的信息点。此外,RULER 引入了新的任务类别,如多跳跟踪和聚合,以测试超出检索从上下文中的行为。在 RULER 上评估了 10 个长文本语言模型,并在 13 个代表性任务中获得了表现。尽管这些模型在普通检索测试中取得了几乎完美的准确性,但在上下文长度增加时,它们表现得非常差。只有四个模型(GPT-4、Command-R、Yi-34B 和 Mixtral)在长度为 32K 时表现得相当不错。我们公开源 RULER,以促进对长文本语言模型的全面评估。
在线伤病评估工具
Anatolink是一个快速免费的在线伤病评估工具,结合交互式3D软件和生成式人工智能,为广泛的身体健康问题提供全面的指导。该工具赋予用户关于身体的知识,并提供最佳的物理治疗洞见,使您保持活动和健康。
使用我们的AI评估工具,上传照片即可获得免费评估。
SnapAppraise是一个提供珠宝首饰评估的在线平台。通过上传照片,我们的AI评估工具可以快速分析珠宝首饰的价值并生成详细的评估报告。SnapAppraise提供免费的初步评估,方便用户在安排面对面评估之前获得快速的预估价值。
用于评估文本到视觉生成的创新性指标和基准测试
Evaluating Text-to-Visual Generation with Image-to-Text Generation提出了一种新的评估指标VQAScore,能够更好地评估复杂的文本到视觉生成效果,并引入了GenAI-Bench基准测试集。VQAScore基于CLIP-FlanT5模型,能够在文本到图像/视频/3D生成评估中取得最佳性能,是一种强大的替代CLIPScore的方案。GenAI-Bench则提供了包含丰富组合语义的实际场景测试文本,可用于全面评估生成模型的性能。
智能招聘评估工具
Potis是一个AI驱动的招聘评估工具,能够自动评估应聘者的实际工作技能,提供实际案例测试、防作弊的评估方法、公正的人才评分系统等特点。Potis自动化评估可以节省高达80%的招聘初始预算,并加速招聘流程5倍,适用于所有层级的招聘需求。
候选人技能评估工具
HunchAssess是HireHunch的候选人评估工具。它提供了一个全面的问题库,包含5000多个问题,涵盖40多种技术技能,包括多项选择题和编程题,可以快速筛选顶尖人才。它支持批量发送邀请,自动计分和高级监考功能,可以轻松地评估候选人的技能和专业知识。关键功能包括:预设的40多种技能集评估、批量发送邀请、自动计分板和高级监考、安排面试等。适用于招聘机构或HR团队进行校园招聘或大规模筛选应聘者。
通过 Minecraft 评估 AI 的表现。
MC-Bench 是一个在线平台,旨在通过 Minecraft 游戏环境评估和比较不同 AI 生成的建筑。它允许用户投票并参与到 AI 评估中,促进 AI 技术的发展。该平台的主要优势在于其趣味性和互动性,为用户提供了一个简单而有趣的方式来了解 AI 的能力。
百度 UNIT 是一款领先的智能对话管理平台,助力企业定制专业、可控、稳定的对话系统。
百度 UNIT 搭载业界领先的对话理解和对话管理技术,提供灵活运营管理工具和可视化会话流程配置,助力企业智能化升级实现降本增效。
RAG-based LLM agents的Elo排名工具
RAGElo是一个工具集,使用Elo评分系统帮助选择最佳的基于检索增强生成(RAG)的大型语言模型(LLM)代理。随着生成性LLM在生产中的原型设计和整合变得更加容易,评估仍然是解决方案中最具有挑战性的部分。RAGElo通过比较不同RAG管道和提示对多个问题的答案,计算不同设置的排名,提供了一个良好的概览,了解哪些设置有效,哪些无效。
加速模型评估和微调的智能评估工具
SFR-Judge 是 Salesforce AI Research 推出的一系列评估模型,旨在通过人工智能技术加速大型语言模型(LLMs)的评估和微调过程。这些模型能够执行多种评估任务,包括成对比较、单项评分和二元分类,同时提供解释,避免黑箱问题。SFR-Judge 在多个基准测试中表现优异,证明了其在评估模型输出和指导微调方面的有效性。
开源幻觉评估模型
Llama-3-Patronus-Lynx-8B-Instruct是由Patronus AI开发的一个基于meta-llama/Meta-Llama-3-8B-Instruct模型的微调版本,主要用于检测在RAG设置中的幻觉。该模型训练于包含CovidQA、PubmedQA、DROP、RAGTruth等多个数据集,包含人工标注和合成数据。它能够评估给定文档、问题和答案是否忠实于文档内容,不提供文档之外的新信息,也不与文档信息相矛盾。
智能的面试技能评估工具
Xobinkey是一款智能的面试技能评估工具。它可以帮助企业在面试过程中快速筛选和评估候选人的技能水平。Xobinkey提供了丰富的功能,包括自定义面试问题、自动评分、实时反馈、报告生成等。它能够大大提高招聘效率和准确性,并帮助企业找到最适合的人才。
一款集成AI技术的智能对话系统,提供多语言翻译、编程代码生成等功能。
ChatMIX智能对话-AIGC系统是一款利用人工智能技术构建的在线聊天系统,旨在通过AI技术提升用户交互体验。产品支持智能翻译、工作周报生成、编程代码编写等功能,满足用户在不同场景下的需求。它的优势在于能够快速响应用户指令,提供准确、高效的服务,同时具备良好的用户界面和操作体验。
Generative AI 模型评估工具
Deepmark AI 是一款用于评估大型语言模型(LLM)的基准工具,可在自己的数据上对各种任务特定指标进行评估。它与 GPT-4、Anthropic、GPT-3.5 Turbo、Cohere、AI21 等领先的生成式 AI API 进行预集成。
AI评估症状,帮助理解健康问题
智能症状检测器是一款AI驱动的医疗工具,通过用户描述症状来评估健康问题。它可以提供非经过审核的AI生成回答,但不意味着提供医疗建议。用户可以描述症状的细节,包括症状的起始时间、严重程度、变化情况、影响因素等。此工具仅供参考,不应替代专业医疗建议。
个人美学评估,提供改善外貌的指导
面部评估工具是一个个人美学评估工具,通过分析面部特征和结构,提供个性化的外貌改善建议。它可以帮助用户了解自己的面部特点、发现美学问题,并提供专业的解决方案。该工具的优势在于精准的分析和个性化的建议,帮助用户实现更好的外貌效果。定价为每次评估服务收费,具体价格请参考官方网站。该产品定位于个人美学领域,旨在帮助用户改善自己的外貌。
一个适合学习、使用、自主扩展的RAG系统。
Easy-RAG是一个检索增强生成(RAG)系统,它不仅适合学习者了解和掌握RAG技术,同时也便于开发者使用和进行自主扩展。该系统通过集成知识图谱提取解析工具、rerank重新排序机制以及faiss向量数据库等技术,提高了检索效率和生成质量。
省时高效的AI绩效评估工具
GeniusReview是一款360° AI绩效评估工具,通过使用GeniusReview,您可以省去大量时间来获取定制化的绩效评估问题的答案。它提供针对不同角色的定制化答案,并包括问题列表、技能排名、反馈生成等功能。您可以免费试用。
数据驱动的作业评估系统,服务于教育工作者和学生
AssignOwl是一款数据驱动的作业评估系统,面向教育工作者和学生。它借助数据来更高效、准确地评估作业。重要性在于减轻教师批改作业的负担,同时让学生能及时了解作业情况。主要优点包括提高评估效率、提供精准反馈、数据驱动决策等。产品背景可能是为了解决传统作业评估方式效率低、反馈不及时的问题。价格信息未提及。定位是服务于教育场景,提升作业评估的质量和效率。
SQLBot 是一款基于大模型和 RAG 的智能问数系统。
SQLBot 是一款由飞致云推出的智能问数系统,结合大模型和 RAG 技术,提供对话式数据分析的能力。它的主要优点包括开箱即用、易于集成以及安全可控,适合需要高效数据分析和互动的用户。该产品是免费的开源项目,定位于为用户提供便捷的数据查询和分析体验。

© 2026 AIbase 备案号:闽ICP备08105208号-14