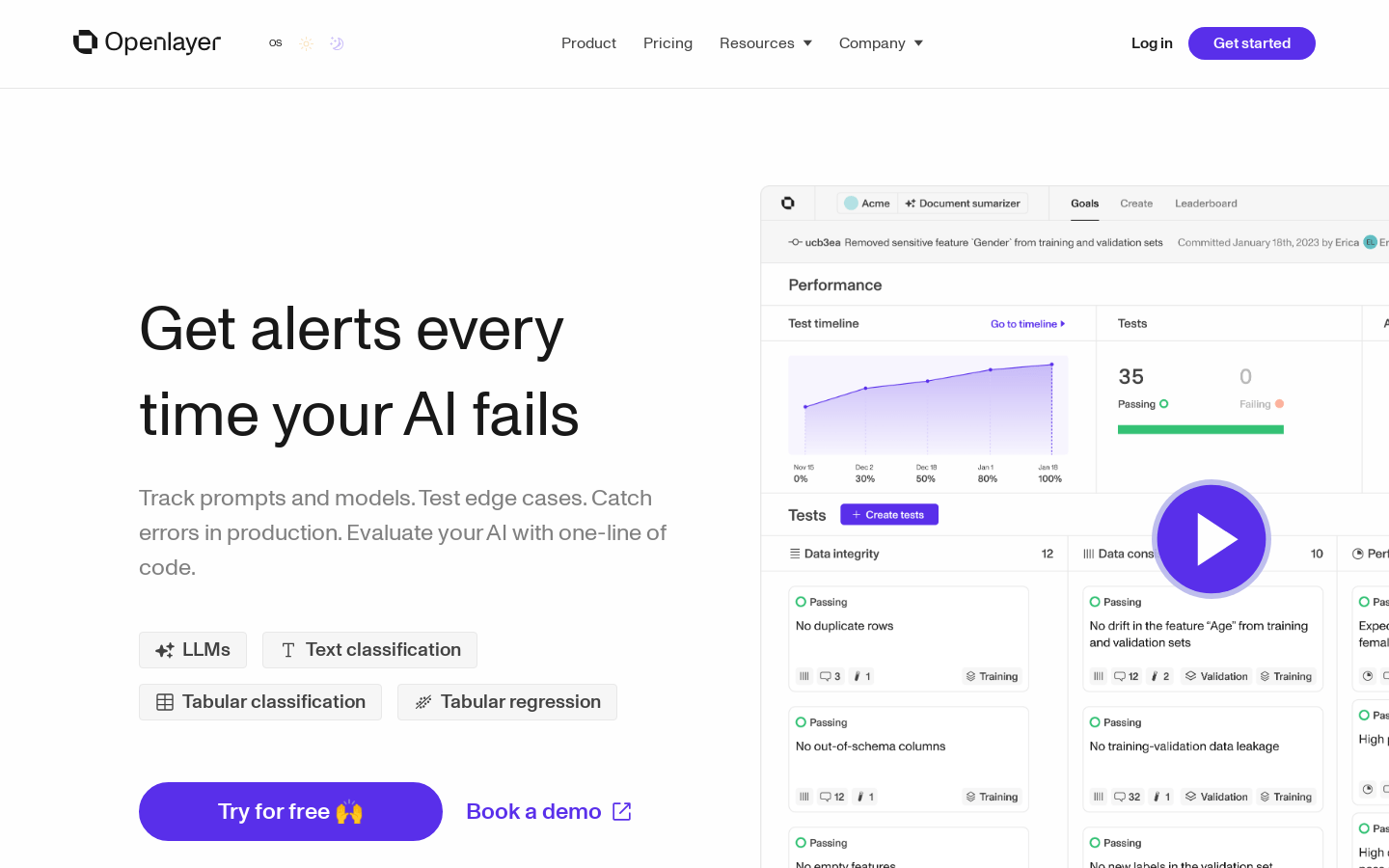
Openlayer是一个评估工具,适用于您的开发和生产流程,帮助您自信地发布高质量的模型。它提供强大的测试、评估和可观察性,无需猜测您的提示是否足够好。支持LLMs、文本分类、表格分类、表格回归等功能。通过实时通知让您在AI模型失败时获得通知,让您自信地发布。
需求人群:
"适用于数据科学家、机器学习工程师、产品经理、CTO和领域专家"
使用场景示例:
数据科学家使用Openlayer进行AI模型测试和评估
机器学习工程师使用Openlayer进行实时监控和版本控制
产品经理使用Openlayer进行模型部署和安全测试
产品特色:
支持LLMs、文本分类、表格分类、表格回归
推动工作流程,只需几行代码
创建测试
跟踪进度
监控实时警报
跟踪和版本控制
开发者优先设计
无缝通知
安全部署
加入Discord社区
阅读文档
获取API参考
免费试用
浏览量:50
最新流量情况
月访问量
12.92k
平均访问时长
00:00:21
每次访问页数
1.75
跳出率
41.18%
流量来源
直接访问
39.54%
自然搜索
41.12%
邮件
0.13%
外链引荐
11.63%
社交媒体
6.49%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
巴西
8.40%
印度尼西亚
5.38%
印度
19.17%
美国
37.68%
越南
5.61%
AI模型测试评估工具
Openlayer是一个评估工具,适用于您的开发和生产流程,帮助您自信地发布高质量的模型。它提供强大的测试、评估和可观察性,无需猜测您的提示是否足够好。支持LLMs、文本分类、表格分类、表格回归等功能。通过实时通知让您在AI模型失败时获得通知,让您自信地发布。
AI模型软件工程能力评估工具
SWE-bench Verified是OpenAI发布的一个经过人工验证的SWE-bench子集,旨在更可靠地评估AI模型解决现实世界软件问题的能力。它通过提供代码库和问题描述,挑战AI生成解决所描述问题的补丁。这个工具的开发是为了提高模型自主完成软件工程任务的能力评估的准确性,是OpenAI准备框架中中等风险级别的关键组成部分。
知识编辑基准测试,用于评估大型语言模型的知识编辑方法。
KnowEdit是一个专注于大型语言模型(LLMs)的知识编辑基准测试。它提供了一个综合的评估框架,用于测试和比较不同的知识编辑方法在修改特定领域内LLMs行为时的有效性,同时保持跨各种输入的整体性能。KnowEdit基准测试包括六个不同的数据集,涵盖了事实操作、情感修改和幻觉生成等多种编辑类型。该基准测试旨在帮助研究者和开发者更好地理解和改进知识编辑技术,推动LLMs的持续发展和应用。
Generative AI 模型评估工具
Deepmark AI 是一款用于评估大型语言模型(LLM)的基准工具,可在自己的数据上对各种任务特定指标进行评估。它与 GPT-4、Anthropic、GPT-3.5 Turbo、Cohere、AI21 等领先的生成式 AI API 进行预集成。
加速模型评估和微调的智能评估工具
SFR-Judge 是 Salesforce AI Research 推出的一系列评估模型,旨在通过人工智能技术加速大型语言模型(LLMs)的评估和微调过程。这些模型能够执行多种评估任务,包括成对比较、单项评分和二元分类,同时提供解释,避免黑箱问题。SFR-Judge 在多个基准测试中表现优异,证明了其在评估模型输出和指导微调方面的有效性。
用于评估Windows PC或Apple Mac上AI推理引擎性能的基准测试工具。
Procyon AI Computer Vision Benchmark是由UL Solutions开发的一款专业基准测试工具,旨在帮助用户评估不同AI推理引擎在Windows PC或Apple Mac上的性能表现。该工具通过执行一系列基于常见机器视觉任务的测试,利用多种先进的神经网络模型,为工程团队提供独立、标准化的评估手段,以便他们了解AI推理引擎的实施质量和专用硬件的性能。产品支持多种主流的AI推理引擎,如NVIDIA® TensorRT™、Intel® OpenVINO™等,并可比较浮点和整数优化模型的性能。其主要优点包括易于安装和运行、无需复杂配置、可导出详细结果文件等。产品定位为专业用户,如硬件制造商、软件开发者和科研人员,以助力他们在AI领域的研发和优化工作。
AI代理测试和评估平台
Coval是一个专注于AI代理测试和评估的平台,旨在通过模拟和评估来提高AI代理的可靠性和效率。该平台由自主测试领域的专家构建,支持语音和聊天代理的测试,并提供全面的评估报告,帮助用户优化AI代理的性能。Coval的主要优点包括简化测试流程、提供AI驱动的模拟、兼容语音AI,以及提供详细的性能分析。产品背景信息显示,Coval旨在帮助企业快速、可靠地部署AI代理,提高客户服务的质量和效率。Coval提供三种定价计划,满足不同规模企业的需求。
多语言多任务基准测试,用于评估大型语言模型(LLMs)
P-MMEval是一个多语言基准测试,覆盖了基础和能力专业化的数据集。它扩展了现有的基准测试,确保所有数据集在语言覆盖上保持一致,并在多种语言之间提供平行样本,支持多达10种语言,涵盖8个语言家族。P-MMEval有助于全面评估多语言能力,并进行跨语言可转移性的比较分析。
AI文本生成性能测试工具
Procyon AI Text Generation Benchmark 是一款专门用于测试和评估AI本地大型语言模型(LLM)性能的基准测试工具。它通过与AI软硬件领域的领导者紧密合作,确保测试能够充分利用系统中的本地AI加速硬件。该工具简化了PC性能比较和成本合理化,验证和标准化PC性能,并简化IT团队的PC生命周期管理,允许快速做出决策,以提供PC性能,降低硬件成本,节省测试时间。
跨平台AI性能基准测试工具
Geekbench AI 是一款使用真实世界机器学习任务来评估AI工作负载性能的跨平台AI基准测试工具。它通过测量CPU、GPU和NPU的性能,帮助用户确定他们的设备是否准备好应对当今和未来的尖端机器学习应用。
用于评估其他语言模型的开源工具集
Prometheus-Eval 是一个用于评估大型语言模型(LLM)在生成任务中表现的开源工具集。它提供了一个简单的接口,使用 Prometheus 模型来评估指令和响应对。Prometheus 2 模型支持直接评估(绝对评分)和成对排名(相对评分),能够模拟人类判断和专有的基于语言模型的评估,解决了公平性、可控性和可负担性的问题。
智能测试工具
Teste.ai是一款智能测试工具,提供创建测试用例、场景和步骤的功能。通过使用人工智能技术,它能够生成测试数据和测试计划,并帮助测试人员提高测试效率和质量。Teste.ai具有高级和高效的测试功能,可以帮助测试人员转变测试方式。
测试你的vibe编码技能,评估AI使用能力,用于招聘AI人才
VibeOnly是一个专注于评估候选人AI使用技能的平台,在当今AI成为顶尖人才新基准的时代具有重要意义。其主要优点在于能够精准筛选出真正具备AI技能的精英人才,通过实际的UI挑战和评估,反映候选人在实际工作中运用AI进行批判性思考和解决问题的能力。平台采用智能评估引擎,可实时适应候选人的技能水平,评估结果更具准确性和客观性。该平台目前处于封闭测试阶段,价格信息未提及,定位是为现代以AI为先的团队提供强大的招聘工具,帮助企业招聘到AI原生人才。
用于评估大型语言模型事实性的最新基准
FACTS Grounding是Google DeepMind推出的一个全面基准测试,旨在评估大型语言模型(LLMs)生成的回应是否不仅在给定输入方面事实准确,而且足够详细,能够为用户提供满意的答案。这一基准测试对于提高LLMs在现实世界中应用的信任度和准确性至关重要,有助于推动整个行业在事实性和基础性方面的进步。
AI模型比较平台
thisorthis.ai是一个在线平台,用户可以在这里输入提示并选择不同的AI模型来生成响应,然后比较这些响应的风格、准确性和相关性。平台支持用户分享和投票,以发现哪些AI模型在公共意见中表现最佳。
比较、测试、构建和部署低代码AI模型
Contentable.ai是一个综合的AI模型测试平台,可以帮助用户快速测试、原型和共享AI模型。它提供了一套完整的工具和功能,使用户能够轻松构建和部署AI模型,从而提高工作效率。
一种用于测试长文本语言模型的合理性的评估基准
RULER 是一种新的合成基准,为长文本语言模型提供了更全面的评估。它扩展了普通检索测试,涵盖了不同类型和数量的信息点。此外,RULER 引入了新的任务类别,如多跳跟踪和聚合,以测试超出检索从上下文中的行为。在 RULER 上评估了 10 个长文本语言模型,并在 13 个代表性任务中获得了表现。尽管这些模型在普通检索测试中取得了几乎完美的准确性,但在上下文长度增加时,它们表现得非常差。只有四个模型(GPT-4、Command-R、Yi-34B 和 Mixtral)在长度为 32K 时表现得相当不错。我们公开源 RULER,以促进对长文本语言模型的全面评估。
研究项目,探索自动语言模型基准测试中的作弊行为。
Cheating LLM Benchmarks 是一个研究项目,旨在通过构建所谓的“零模型”(null models)来探索在自动语言模型(LLM)基准测试中的作弊行为。该项目通过实验发现,即使是简单的零模型也能在这些基准测试中取得高胜率,这挑战了现有基准测试的有效性和可靠性。该研究对于理解当前语言模型的局限性和改进基准测试方法具有重要意义。
用于评估文本到视觉生成的创新性指标和基准测试
Evaluating Text-to-Visual Generation with Image-to-Text Generation提出了一种新的评估指标VQAScore,能够更好地评估复杂的文本到视觉生成效果,并引入了GenAI-Bench基准测试集。VQAScore基于CLIP-FlanT5模型,能够在文本到图像/视频/3D生成评估中取得最佳性能,是一种强大的替代CLIPScore的方案。GenAI-Bench则提供了包含丰富组合语义的实际场景测试文本,可用于全面评估生成模型的性能。
LLM prompt测试库
promptfoo是一个用于评估LLM prompt质量和进行测试的库。它能够帮助您创建测试用例,设置评估指标,并与现有的测试和CI流程集成。promptfoo还提供了一个Web Viewer,让您可以轻松地比较不同的prompt和模型输出。它被用于服务超过1000万用户的LLM应用程序。
API测试工具
HTTPie是一个使API简单易用的测试工具,它提供友好的命令行界面和图形界面,帮助开发者测试HTTP服务器、RESTful API和Web服务。它受到全球开发者的信赖,被广泛应用于API测试和开发工作中。
Snowglobe帮助AI团队在规模上测试LLM应用。在推出之前模拟真实对话,发现风险并提高模型性能。
Snowglobe是一个帮助AI团队测试LLM应用的工具,通过模拟真实对话、发现潜在风险并提升模型性能,帮助用户在推出前进行充分测试。它的主要优点在于快速模拟大量对话、提供实时风险报告、生成评判标签数据集等。
AI 网站测试工具,简单高效
Aitida Test Suite是一个简单高效的工具,用于自动化测试网站的功能和外观。它可以模拟用户在网站上的操作,检查页面的正确性和响应性,并提供详细的测试报告。通过 AI 技术,可以提高测试效率并减少人工测试的工作量。Aitida Test Suite还提供了丰富的功能点列表,包括页面布局、链接、表单提交、登录等常见功能的测试。使用场景包括网站开发、网站更新、网站维护等。
用于衡量设备 AI 加速器推理性能的基准测试工具。
Procyon AI Image Generation Benchmark 是一款由 UL Solutions 开发的基准测试工具,旨在为专业用户提供一个一致、准确且易于理解的工作负载,用以测量设备上 AI 加速器的推理性能。该基准测试与多个关键行业成员合作开发,确保在所有支持的硬件上产生公平且可比较的结果。它包括三个测试,可测量从低功耗 NPU 到高端独立显卡的性能。用户可以通过 Procyon 应用程序或命令行进行配置和运行,支持 NVIDIA® TensorRT™、Intel® OpenVINO™ 和 ONNX with DirectML 等多种推理引擎。产品主要面向工程团队,适用于评估推理引擎实现和专用硬件的通用 AI 性能。价格方面,提供免费试用,正式版为年度场地许可,需付费获取报价。
Mindgard是攻击者对齐的AI安全平台,可发现、评估和红队测试AI系统。
Mindgard是一款研究主导、攻击者对齐且面向企业的AI安全平台。其重要性在于帮助企业有效应对AI系统面临的安全威胁,确保AI的安全和稳定运行。主要优点包括能够发现隐藏的AI和代理,揭示AI攻击面,持续对AI进行红队测试,评估和修复安全漏洞,实时识别和响应攻击等。产品背景方面,随着AI技术的广泛应用,其安全问题愈发凸显,Mindgard应运而生以满足企业对AI安全的需求。关于价格,文档未提及。产品定位是为企业级用户提供全面的AI安全解决方案。
用于评估文本、对话和RAG设置的通用评估模型
Patronus GLIDER是一个经过微调的phi-3.5-mini-instruct模型,可以作为通用评估模型,根据用户定义的标准和评分规则来评判文本、对话和RAG设置。该模型使用合成数据和领域适应数据进行训练,覆盖了183个指标和685个领域,包括金融、医学等。模型支持的最大序列长度为8192个token,但经过测试可以支持更长的文本(高达12000个token)。
LLM的评估和单元测试框架
DeepEval提供了不同方面的度量来评估LLM对问题的回答,以确保答案是相关的、一致的、无偏见的、非有毒的。这些可以很好地与CI/CD管道集成在一起,允许机器学习工程师快速评估并检查他们改进LLM应用程序时,LLM应用程序的性能是否良好。DeepEval提供了一种Python友好的离线评估方法,确保您的管道准备好投入生产。它就像是“针对您的管道的Pytest”,使生产和评估管道的过程与通过所有测试一样简单直接。

© 2026 AIbase 备案号:闽ICP备08105208号-14