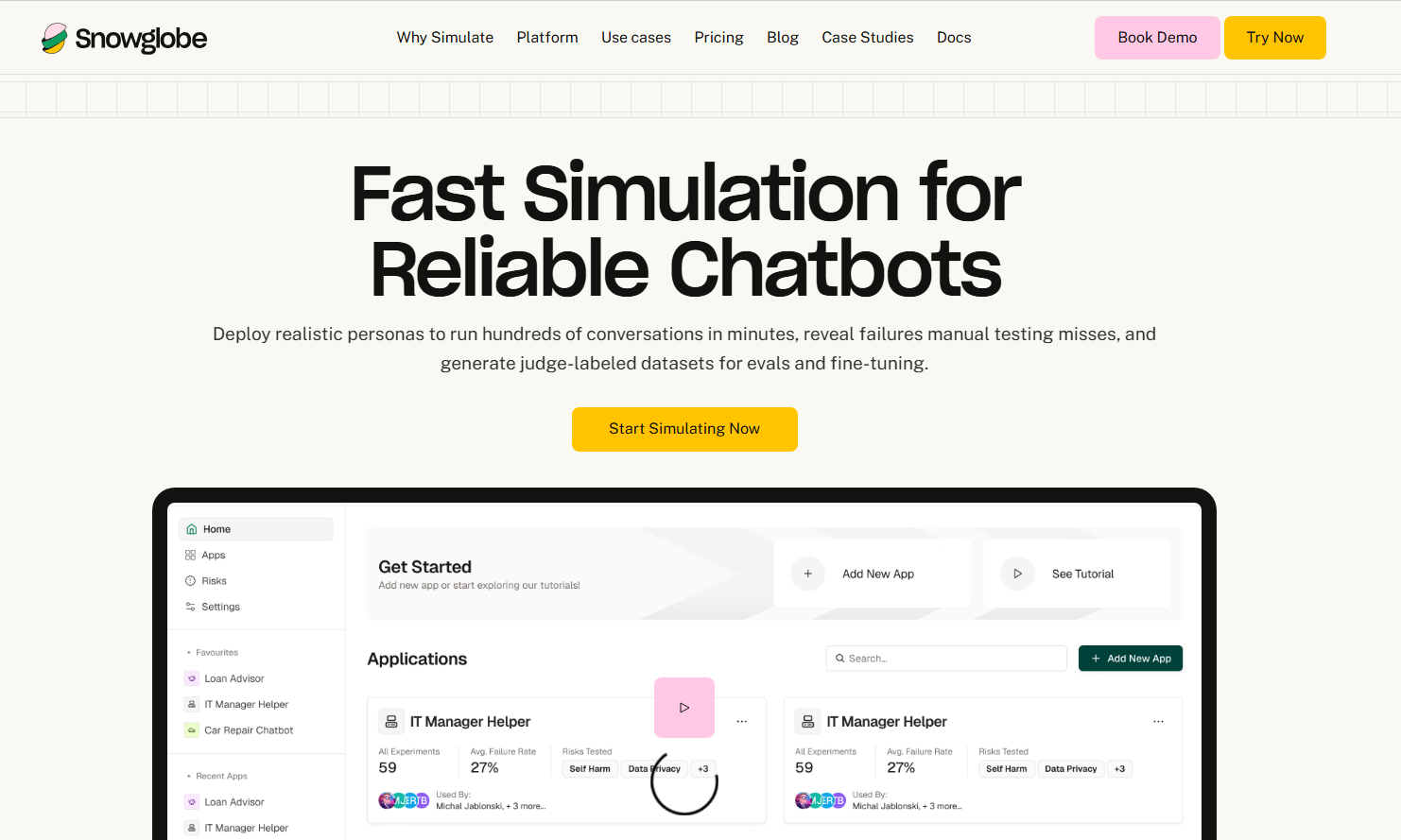
Snowglobe是一个帮助AI团队测试LLM应用的工具,通过模拟真实对话、发现潜在风险并提升模型性能,帮助用户在推出前进行充分测试。它的主要优点在于快速模拟大量对话、提供实时风险报告、生成评判标签数据集等。
需求人群:
Snowglobe适合AI团队和开发人员,帮助他们测试和优化LLM应用,提前发现潜在问题并改进模型性能。
使用场景示例:
AI团队使用Snowglobe进行大规模对话模拟,发现并解决潜在风险。
开发人员利用Snowglobe生成评判标签数据集,优化模型训练。
企业使用Snowglobe进行模型性能测试,提高产品质量。
产品特色:
快速模拟大量对话:Snowglobe可以在几分钟内运行数百个真实对话,揭示手动测试忽略的失败。
生成评判标签数据集:可在模拟对话中快速生成评判标签测试数据集,覆盖不同意图、人物、语调和多轮流程。
导出用于评估的数据:可将生成的数据导出到评估工具中进行评估。
生成优质训练数据:从运行中产生的数据中生成高信号训练数据,用于DPO或奖励模型。
运行套件用于回归测试:每次构建可运行数百个真实对话,捕获手动测试漏掉的问题。
跟踪错误率:可保存测试套件进行回归测试,跟踪错误率,确保问题不会达到生产环境。
使用教程:
连接您的AI代理:将您的API连接至Snowglobe,或使用其SDK轻松集成。
配置和探索:配置模拟对话参数,探索不同情境和目标。
分析和优化:分析生成的数据,优化模型性能和应用体验。
浏览量:22
Snowglobe帮助AI团队在规模上测试LLM应用。在推出之前模拟真实对话,发现风险并提高模型性能。
Snowglobe是一个帮助AI团队测试LLM应用的工具,通过模拟真实对话、发现潜在风险并提升模型性能,帮助用户在推出前进行充分测试。它的主要优点在于快速模拟大量对话、提供实时风险报告、生成评判标签数据集等。
将渗透测试和风险评估报告转化为协作工作空间,分配任务,跟踪进展,利用AI洞察
Mitigated.io是一个将渗透测试和风险评估报告转化为协作工作空间的平台。用户可以导入报告,邀请团队成员,共同解决问题,并追踪进展。该平台还提供AI增强的缓解指导,易于导入报告,Kanban等功能。此外,用户还可以从平台上直接获取安全缓解服务。Mitigated.io旨在帮助用户更高效地进行安全缓解,提高安全性。
AI驱动的网络安全风险评估与审计工具
CyberRiskAI是一款由AI驱动的网络安全风险评估与审计工具,提供全面的工具、模板和清单,帮助企业识别和减轻网络安全风险,并向客户传达信任。我们基于NIST 800-171或ISO/IEC 27001提供框架,以全面的风险评估模板和清单来快速、准确、经济地完成网络安全风险审核。通过获取潜在漏洞的有价值洞察,您可以优先考虑安全工作,并与合作伙伴建立信任。
实时AI模拟对话,提升沟通技能
AGOGE.AI利用OpenAI的尖端GPT-4技术,提供动态互动环境,让用户参与模拟对话,以增强他们的沟通能力。该应用采用先进的自然语言处理技术,生成实时、具有上下文意识的回应,让用户体验多样化的对话场景,并即时获得可操作的反馈,以有效地完善对话策略。对话潜力无限,让您的交流技能得到释放。
AI模型测试评估工具
Openlayer是一个评估工具,适用于您的开发和生产流程,帮助您自信地发布高质量的模型。它提供强大的测试、评估和可观察性,无需猜测您的提示是否足够好。支持LLMs、文本分类、表格分类、表格回归等功能。通过实时通知让您在AI模型失败时获得通知,让您自信地发布。
Mindgard是攻击者对齐的AI安全平台,可发现、评估和红队测试AI系统。
Mindgard是一款研究主导、攻击者对齐且面向企业的AI安全平台。其重要性在于帮助企业有效应对AI系统面临的安全威胁,确保AI的安全和稳定运行。主要优点包括能够发现隐藏的AI和代理,揭示AI攻击面,持续对AI进行红队测试,评估和修复安全漏洞,实时识别和响应攻击等。产品背景方面,随着AI技术的广泛应用,其安全问题愈发凸显,Mindgard应运而生以满足企业对AI安全的需求。关于价格,文档未提及。产品定位是为企业级用户提供全面的AI安全解决方案。
模拟对话的AI助手
Hey Mike's Betakey是一个模拟对话的AI助手,旨在通过模拟对话来帮助人们。它使用GPT-3技术,提供每月5000条消息的标准订阅,订阅费用为₹300/月。Premium订阅提供每月7000条消息,订阅费用为₹700/月。Premium+订阅提供每月10000条消息,订阅费用为₹800/月。消息保留时间分别为一个月、两个月和六个月。通过Hey Mike,您可以免费试用一周。
AI代理测试和评估平台
Coval是一个专注于AI代理测试和评估的平台,旨在通过模拟和评估来提高AI代理的可靠性和效率。该平台由自主测试领域的专家构建,支持语音和聊天代理的测试,并提供全面的评估报告,帮助用户优化AI代理的性能。Coval的主要优点包括简化测试流程、提供AI驱动的模拟、兼容语音AI,以及提供详细的性能分析。产品背景信息显示,Coval旨在帮助企业快速、可靠地部署AI代理,提高客户服务的质量和效率。Coval提供三种定价计划,满足不同规模企业的需求。
AI风险数据库与分类系统
AI Risk Repository是一个全面的生活数据库,收录了700多个AI风险,并根据其原因和风险领域进行了分类。它提供了一个易于访问的AI风险概览,是研究人员、开发者、企业、评估者、审计师、政策制定者和监管者共同参考的框架,有助于发展研究、课程、审计和政策。
Roark是一个声音AI的QA可观察性层,监控语音交互并进行测试和评估。
Roark是一个为团队提供可靠声音代理的平台,能够监控实时通话、进行规模模拟测试和将失败转化为测试。它提供全面的指标、多说话人分析、评估器运行等功能,帮助团队交付可靠的声音代理。
AI辅助的IELTS写作助手 | 模拟测试和即时反馈,提高你的分数
UpScore.ai是一款使用AI技术的教育助手,专门针对IELTS写作任务2进行准备,提供高质量的即时个性化结果。我们提供即时反馈和评分,深度分析和重写,30个写作任务2主题的模拟测试,以优化你的表现。无论是学生、专业人士、教师还是机构,都可以从我们的平台中受益。
AI辅助的对话模拟训练
ChatCoach是一款AI辅助对话模拟训练工具,帮助用户提升沟通技巧和自信心。通过实时情感分析和高级自然语言处理技术,用户可以在与虚拟对话伙伴交流中即时调整自己的表达方式,以确保每次交流都更加个性化和有影响力。ChatCoach提供逼真的模拟对话场景,涵盖工作面试、销售演讲等多种场景,帮助用户在面对真实挑战之前构建自信和专业技巧。
DeepMind推出的AI安全框架,旨在识别和减轻高级AI模型的未来风险。
Frontier Safety Framework是Google DeepMind提出的一套协议,用于主动识别未来AI能力可能导致严重伤害的情况,并建立机制来检测和减轻这些风险。该框架专注于模型层面的强大能力,如卓越的代理能力或复杂的网络能力。它旨在补充我们的对齐研究,即训练模型按照人类价值观和社会目标行事,以及Google现有的AI责任和安全实践。
用于评估文本、对话和RAG设置的通用评估模型
Patronus GLIDER是一个经过微调的phi-3.5-mini-instruct模型,可以作为通用评估模型,根据用户定义的标准和评分规则来评判文本、对话和RAG设置。该模型使用合成数据和领域适应数据进行训练,覆盖了183个指标和685个领域,包括金融、医学等。模型支持的最大序列长度为8192个token,但经过测试可以支持更长的文本(高达12000个token)。
测试你的vibe编码技能,评估AI使用能力,用于招聘AI人才
VibeOnly是一个专注于评估候选人AI使用技能的平台,在当今AI成为顶尖人才新基准的时代具有重要意义。其主要优点在于能够精准筛选出真正具备AI技能的精英人才,通过实际的UI挑战和评估,反映候选人在实际工作中运用AI进行批判性思考和解决问题的能力。平台采用智能评估引擎,可实时适应候选人的技能水平,评估结果更具准确性和客观性。该平台目前处于封闭测试阶段,价格信息未提及,定位是为现代以AI为先的团队提供强大的招聘工具,帮助企业招聘到AI原生人才。
自动化AI语音代理测试与性能分析平台,提供真实场景模拟与评估。
TestAI是一个专注于AI语音代理的自动化测试与性能分析平台。它通过真实世界的场景模拟和详细的性能评估,帮助企业确保其语音和聊天代理的可靠性和流畅性。该平台提供快速设置、可靠洞察以及自定义指标等功能,能够有效提升AI代理的性能和用户体验。TestAI主要面向需要快速部署和优化AI语音代理的企业,帮助他们节省时间和成本,同时提高AI代理的可信度和安全性。
提供PTE、IELTS、Duolingo、CELPIP免费在线模拟测试及AI打分
Gurully是一个在线英语语言模拟测试平台,旨在帮助用户备考PTE、IELTS、Duolingo、CELPIP等英语能力考试。平台提供免费的模拟测试和AI评分,具有即时、准确的优点,能帮助用户了解自己的英语水平,明确备考方向。用户可以通过详细的反馈和分析,有针对性地进行练习。平台提供PTE、DET、IELTS、CELPIP练习套餐,使用代码“XMAS20”在12月25日前可享20%折扣。平台定位为英语能力考试备考辅助工具,适合有英语考试需求的人群。
用于评估Windows PC或Apple Mac上AI推理引擎性能的基准测试工具。
Procyon AI Computer Vision Benchmark是由UL Solutions开发的一款专业基准测试工具,旨在帮助用户评估不同AI推理引擎在Windows PC或Apple Mac上的性能表现。该工具通过执行一系列基于常见机器视觉任务的测试,利用多种先进的神经网络模型,为工程团队提供独立、标准化的评估手段,以便他们了解AI推理引擎的实施质量和专用硬件的性能。产品支持多种主流的AI推理引擎,如NVIDIA® TensorRT™、Intel® OpenVINO™等,并可比较浮点和整数优化模型的性能。其主要优点包括易于安装和运行、无需复杂配置、可导出详细结果文件等。产品定位为专业用户,如硬件制造商、软件开发者和科研人员,以助力他们在AI领域的研发和优化工作。
AI文本生成性能测试工具
Procyon AI Text Generation Benchmark 是一款专门用于测试和评估AI本地大型语言模型(LLM)性能的基准测试工具。它通过与AI软硬件领域的领导者紧密合作,确保测试能够充分利用系统中的本地AI加速硬件。该工具简化了PC性能比较和成本合理化,验证和标准化PC性能,并简化IT团队的PC生命周期管理,允许快速做出决策,以提供PC性能,降低硬件成本,节省测试时间。
知识编辑基准测试,用于评估大型语言模型的知识编辑方法。
KnowEdit是一个专注于大型语言模型(LLMs)的知识编辑基准测试。它提供了一个综合的评估框架,用于测试和比较不同的知识编辑方法在修改特定领域内LLMs行为时的有效性,同时保持跨各种输入的整体性能。KnowEdit基准测试包括六个不同的数据集,涵盖了事实操作、情感修改和幻觉生成等多种编辑类型。该基准测试旨在帮助研究者和开发者更好地理解和改进知识编辑技术,推动LLMs的持续发展和应用。
用于评估文本到视觉生成的创新性指标和基准测试
Evaluating Text-to-Visual Generation with Image-to-Text Generation提出了一种新的评估指标VQAScore,能够更好地评估复杂的文本到视觉生成效果,并引入了GenAI-Bench基准测试集。VQAScore基于CLIP-FlanT5模型,能够在文本到图像/视频/3D生成评估中取得最佳性能,是一种强大的替代CLIPScore的方案。GenAI-Bench则提供了包含丰富组合语义的实际场景测试文本,可用于全面评估生成模型的性能。
模拟不同投资策略的表现,辅助投资决策。
投资策略模拟器是一个在线工具,它通过模拟不同的股价模型和投资策略,帮助用户理解各种投资策略在不同市场条件下的表现。该产品使用几何布朗运动模型来模拟股价的连续随机波动,适合相对稳定的大盘股。用户可以设置不同的投资周期和策略,比如买入持有、定投等,来观察投资收益的变化。这个工具的主要优点是简单易懂,能够帮助投资者在不承担实际风险的情况下,学习和比较不同的投资策略。它适合心态平和、不为短期波动所动的长线投资者。目前,该产品是免费的,主要面向教育和娱乐目的,不构成实际的投资建议。
跨平台AI性能基准测试工具
Geekbench AI 是一款使用真实世界机器学习任务来评估AI工作负载性能的跨平台AI基准测试工具。它通过测量CPU、GPU和NPU的性能,帮助用户确定他们的设备是否准备好应对当今和未来的尖端机器学习应用。
为机器人提供虚拟模拟和评估的先进世界模型。
1X 世界模型是一种机器学习程序,能够模拟世界如何响应机器人的行为。它基于视频生成和自动驾驶汽车世界模型的技术进步,为机器人提供了一个虚拟模拟器,能够预测未来的场景并评估机器人策略。这个模型不仅能够处理复杂的对象交互,如刚体、掉落物体的影响、部分可观察性、可变形物体和铰接物体,还能够在不断变化的环境中进行评估,这对于机器人技术的发展至关重要。
LLM prompt测试库
promptfoo是一个用于评估LLM prompt质量和进行测试的库。它能够帮助您创建测试用例,设置评估指标,并与现有的测试和CI流程集成。promptfoo还提供了一个Web Viewer,让您可以轻松地比较不同的prompt和模型输出。它被用于服务超过1000万用户的LLM应用程序。
免费AI认证,20分钟对话测试,含报告、证书,可加至LinkedIn
AISA是一个对话式AI技能评估平台,于2024年成立,创始人是Ozan Dagdeviren。它可以对开发者、产品经理、设计师和数据科学家等进行基于证据的评分,涵盖5个维度和11个标准。其主要优点在于能在20分钟的对话中完成AI技能评估,为用户提供免费的AI认证,证书可在LinkedIn上验证。该产品定位为快速、便捷地评估个人现有的AI技能水平,无需长时间学习课程,适合各类专业人士了解自身AI能力。产品完全免费,无需信用卡支付。
测试你的创意,降低失败风险
Checkmyidea-IA是一款通过人工智能评估服务来验证创业创意的工具。它帮助创业者在启动前快速了解自己的商业创意是否有市场需求、与竞争产品的差异、潜在风险以及定价策略等。通过使用Checkmyidea-IA,创业者可以提高成功的几率,降低失败的风险。

© 2026 AIbase 备案号:闽ICP备08105208号-14