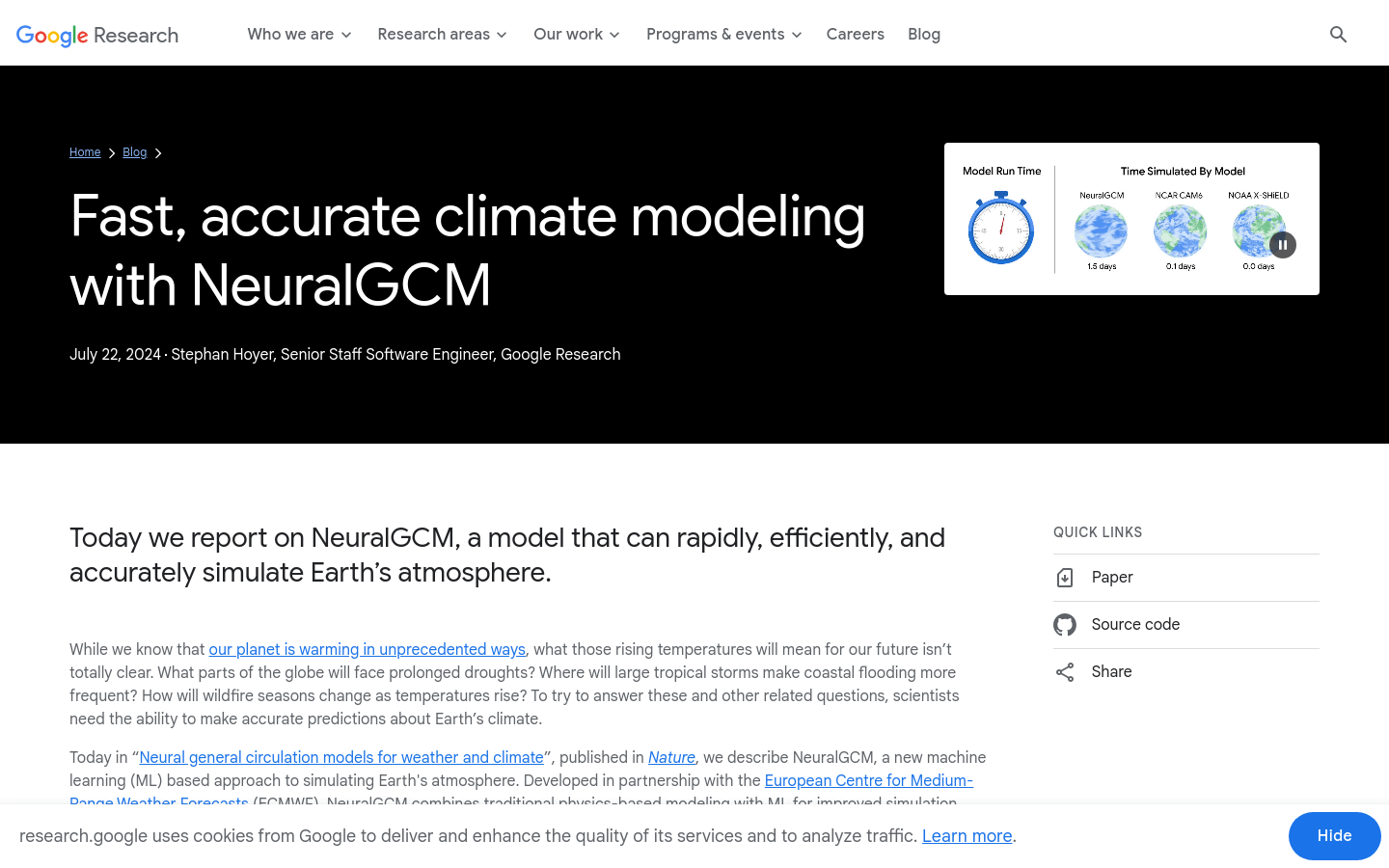
NeuralGCM是由谷歌研究团队开发的气候模型,与传统基于物理的气候模型相比,它结合了机器学习技术,提高了模拟的准确性和效率。NeuralGCM能够生成2至15天的天气预测,其准确性超过了当前的黄金标准物理模型,并且在重现过去40年的温度数据方面比传统大气模型更为准确。尽管NeuralGCM尚未构建为完整的气候模型,但它标志着开发更强大、更易用气候模型的重要一步。
需求人群:
"NeuralGCM的目标受众主要是气候科学家和研究人员,他们需要准确的气候预测来理解气候变化对全球各地的影响,如干旱、热带风暴和野火季节的变化。此外,由于NeuralGCM的高效性,它也适合需要快速气候模拟结果的决策者和规划者。"
使用场景示例:
气候科学家使用NeuralGCM来预测特定地区未来几十年的气候变化趋势。
政府机构利用NeuralGCM的预测结果来制定应对极端天气事件的政策和预案。
教育和研究机构使用NeuralGCM作为教学工具,帮助学生理解气候系统的复杂性。
产品特色:
结合传统物理模型与机器学习提高模拟准确性和效率
生成2-15天的高精度天气预测
重现过去40年的温度数据,准确性超过传统模型
使用神经网络从现有气象数据中学习小尺度事件的物理特性
在JAX中重写数值求解器,实现基于梯度的优化调整
在TPUs和GPUs上高效运行,与传统主要在CPU上运行的模型相比具有性能优势
提供开源代码和模型权重,便于研究人员进行非商业性使用和进一步开发
使用教程:
步骤1: 访问NeuralGCM的GitHub页面,下载源代码和模型权重。
步骤2: 根据文档说明,安装所需的依赖项和运行环境。
步骤3: 运行NeuralGCM模型,输入所需的气象数据集。
步骤4: 配置模型参数,如分辨率和模拟的时间范围。
步骤5: 启动模拟过程,等待模型生成预测结果。
步骤6: 分析预测结果,根据需要调整模型参数以优化预测准确性。
步骤7: 将预测结果应用于气候研究或决策制定中。
浏览量:60
最新流量情况
月访问量
1145.25k
平均访问时长
00:00:43
每次访问页数
3.16
跳出率
54.65%
流量来源
直接访问
40.21%
自然搜索
47.38%
邮件
0.10%
外链引荐
8.89%
社交媒体
2.81%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
中国
3.10%
英国
2.96%
印度
8.76%
泰国
2.87%
美国
27.52%
高效准确的气候模拟模型
NeuralGCM是由谷歌研究团队开发的气候模型,与传统基于物理的气候模型相比,它结合了机器学习技术,提高了模拟的准确性和效率。NeuralGCM能够生成2至15天的天气预测,其准确性超过了当前的黄金标准物理模型,并且在重现过去40年的温度数据方面比传统大气模型更为准确。尽管NeuralGCM尚未构建为完整的气候模型,但它标志着开发更强大、更易用气候模型的重要一步。
深度学习天气预测模型
GraphCast是由Google DeepMind开发的深度学习模型,专注于全球中期天气预报。该模型通过先进的机器学习技术,能够预测天气变化,提高预报的准确性和速度。GraphCast模型在科学研究中发挥重要作用,有助于更好地理解和预测天气模式,对气象学、农业、航空等多个领域具有重要价值。
利用AI技术预测天气和气候,助力人类适应极端天气
Brightband是一个致力于通过先进的地球系统AI技术,使天气和气候变得可预测,以帮助人类适应日益极端的天气变化。该平台通过开源基准数据集、模型和指标,鼓励全球社区共同提升天气预测的技术水平。Brightband提供给学术界、政府和公司使用的工具,旨在改善与天气和气候相关的决策,从而长期造福人类和地球。
简化机器学习和预测分析
Analyzr使机器学习和预测分析变得简单,为中型和企业客户提供B2B销售和营销分析。我们提供无代码界面,快速构建机器学习模型;采用零信任方法,用户数据经过编码和本地控制,保证安全;可扩展的托管Kubernetes集群,实现云端扩展性;全面托管,保证稳定运行和专属服务台;单独的API,不共享机密数据;输出结果反馈到本地系统,方便用户访问。
无代码机器学习平台,生成业务洞察和预测
Graphite Note是世界上最简单易用的无代码机器学习平台。它帮助用户在几分钟内生成业务洞察和预测,无需编码。通过Graphite Note,用户可以使用各种机器学习模型进行数据分析、预测和决策支持。平台提供直观的界面和易于使用的工具,使用户能够快速构建和训练模型,并将结果转化为实际的业务洞察。Graphite Note还提供了丰富的功能,包括数据可视化、特征工程、模型评估和优化等,以帮助用户充分利用机器学习的潜力。平台还支持多种数据源和格式,使用户能够灵活地处理和分析各种类型的数据。Graphite Note的定价灵活合理,适用于个人用户、小型团队和企业客户。无论您是数据科学家、业务分析师还是决策者,Graphite Note都是您实现业务洞察和预测的理想选择。
基于语言模型架构的预训练时间序列预测模型
Chronos是一系列基于语言模型架构的预训练时间序列预测模型。时间序列通过缩放和量化转换为一系列标记,然后使用交叉熵损失训练语言模型。训练完成后,通过给定历史上下文采样多个未来轨迹,获得概率性预测。Chronos模型已经在大量公开可用的时间序列数据和使用高斯过程生成的合成数据上进行了训练。
一键完成整个数据科学流程,构建机器学习算法,解释结果和预测结果
Obviously AI是一个最快、最精确的无代码AI工具,让您能够在几分钟内从原始数据转变为行业领先的预测模型,而不是几个月。它包括构建突破性的AI模型、将模型部署到生产环境、监控模型性能、集成和共享预测数据以及专业支持等功能。通过Obviously AI,您可以节省复杂的AI模型构建时间,并获得整个数据科学团队的支持。
由Google Research开发的预训练时间序列预测模型。
TimesFM是一个由Google Research开发的预训练时间序列预测模型,用于时间序列预测任务。该模型在多个数据集上进行了预训练,能够处理不同频率和长度的时间序列数据。其主要优点包括高性能、可扩展性强以及易于使用。该模型适用于需要准确预测时间序列数据的各种应用场景,如金融、气象、能源等领域。该模型在Hugging Face平台上免费提供,用户可以方便地下载和使用。
机器学习模型运行和部署的工具
Replicate是一款机器学习模型运行和部署的工具,无需自行配置环境,可以快速运行和部署机器学习模型。Replicate提供了Python库和API接口,支持运行和查询模型。社区共享了成千上万个可用的机器学习模型,涵盖了文本理解、视频编辑、图像处理等多个领域。使用Replicate和相关工具,您可以快速构建自己的项目并进行部署。
多令牌预测模型,提升语言模型的效率与性能
multi-token prediction模型是Facebook基于大型语言模型研究开发的技术,旨在通过预测多个未来令牌来提高模型的效率和性能。该技术允许模型在单次前向传播中生成多个令牌,从而加快生成速度并可能提高模型的准确性。该模型在非商业研究用途下免费提供,但使用时需遵守Meta的隐私政策和相关法律法规。
Apple官方机器学习模型训练框架
Create ML是一个Apple官方发布的机器学习模型训练框架,可以非常方便地在Mac设备上训练Core ML模型。它提供了图像、视频、文本等多种模型类型,用户只需要准备数据集和设置参数,就可以开始模型训练。Create ML还提供了Swift API,支持在iOS等平台进行模型训练。
强大的通用预测学习
通用预测学习器是一种利用元学习的强大方法,能够快速从有限数据中学习新任务。通过广泛接触不同的任务,可以获得通用的表示,从而实现通用问题解决。本产品探索了将最强大的通用预测器——Solomonoff归纳(SI)——通过元学习的方式进行摊销的潜力。我们利用通用图灵机(UTM)生成训练数据,让网络接触到广泛的模式。我们提供了UTM数据生成过程和元训练协议的理论分析。我们使用不同复杂度和普适性的算法数据生成器对神经架构(如LSTM、Transformer)进行了全面的实验。我们的结果表明,UTM数据是元学习的宝贵资源,可以用来训练能够学习通用预测策略的神经网络。
投资平台助力气候创业者融资
Dantia是一个投资平台,帮助气候相关的创业者从消费者、天使投资人和风险投资公司获得资金支持。创业者可以扩大人脉、与社区互动,获取初创采纳意见并定义市场策略。投资者可以加入气候意识投资者网络,构建投资组合。消费者可以找到气候积极的公司,支持气候创业项目。Dantia还提供个性化的投资机会推荐和AI辅助决策。
构建和部署AI模型的机器学习框架
Cerebrium是一个机器学习框架,通过几行代码轻松训练、部署和监控机器学习模型。我们在无服务器的CPU/GPU上运行所有内容,并仅根据使用量收费。您可以从Pytorch、Huggingface、Tensorflow等库部署模型。
找到最佳的机器学习API,无需麻烦地进行请求和预测
数据端点是一个机器学习API市场,用户可以在其中找到最佳的机器学习API端点,并进行请求和预测,无需繁琐的操作。产品提供了各种功能,优势,定价和定位等信息。
AI驱动的足球预测APP,分析超10000场比赛,精准预测,免费下载。
AI Betting Tips是一款由Blockdelve Ltd开发的AI驱动的足球预测APP。其核心技术是先进的机器学习算法和神经网络架构,每天能分析10000场比赛数据,包括球队统计、球员表现、历史赛果,甚至天气等外部因素。该APP的重要性在于为足球博彩者提供准确预测,帮助他们做出更明智的投注决策。产品定位为足球博彩辅助工具,通过持续学习和适应不断提高预测准确性。价格方面,APP可免费下载,提供免费预测,同时也有可选的高级功能供用户付费使用。
简化机器学习模型的训练和部署
Sagify是一个命令行工具,可以在几个简单步骤中训练和部署机器学习/深度学习模型在AWS SageMaker上!它消除了配置云实例进行模型训练的痛苦,简化了在云上运行超参数作业的过程,同时不再需要将模型交给软件工程师进行部署。Sagify提供了丰富的功能,包括AWS账户配置、Docker镜像构建、数据上传、模型训练、模型部署等。它适用于各种使用场景,帮助用户快速构建和部署机器学习模型。
上传数据,获取机器学习模型
Automated Machine Learning as a Service是一个提供自动化机器学习服务的网站。用户可以通过上传数据来获取他们的机器学习模型,该平台为用户提供了便捷的机器学习模型开发和部署流程。该平台还提供了丰富的功能和优势,包括简单易用的界面、自动化的模型训练和优化、灵活的定价策略等。用户可以根据自己的需求选择适合的定价方案,并在不同的场景中应用该机器学习模型。该产品的定位是为广大用户提供高效、便捷、灵活的机器学习解决方案。
简化机器学习云服务
Deploifai是一种管理机器学习项目云端的工具,让您可以专注于解决方案。它提供简化的云服务,帮助您管理和部署机器学习模型,包括数据集管理、模型训练、部署和监控。Deploifai的优势在于简化了复杂的基础设施设置,提供易于使用的界面和工具,以及高度可扩展的计算和存储资源。价格根据使用量和功能等级而定,适用于个人开发者和企业团队。
无代码,自动化机器学习
Qlik AutoML是一款为分析团队提供无代码、自动化机器学习的工具。它能够快速生成模型、进行预测和决策规划。用户可以轻松创建机器学习实验,识别数据中的关键因素并训练模型。同时,它还支持完全可解释的AI,可以展示预测的原因和影响。用户可以将数据发布或直接集成到Qlik Sense应用中进行全交互式分析和模拟。
强大的图可视化工具,帮助理解、调试和优化机器学习模型。
Model Explorer 是 Google 开发的一个用于机器学习模型的图可视化工具,它专注于以直观的层次格式可视化大型图,同时也适用于小型模型。该工具特别有助于简化大型模型在设备端平台的部署过程,通过可视化转换、量化和优化数据。Model Explorer 结合了3D游戏和动画制作中使用的图形技术,如实例化渲染和多通道有符号距离场(MSDF),并将其适应于机器学习图渲染。它支持多种图格式,包括 JAX、PyTorch、TensorFlow 和 TensorFlow Lite 使用的格式。Model Explorer 通过层次化视图和导航复杂结构的能力,使得大型模型更易于理解。
大规模基础模型,革新大气预测
Aurora 是由微软研究院开发的大规模基础模型,它利用超过百万小时的多样化天气和气候数据进行训练。Aurora 利用基础模型方法的优势,为各种大气预测问题提供操作性预测,包括那些训练数据有限、变量异质性和极端事件的问题。Aurora 能在不到一分钟内生成5天的全球空气污染预测和10天的高分辨率天气预报,性能超越了最先进的传统模拟工具和最好的专业深度学习模型。这些结果表明,基础模型可以改变环境预测。
开源时空基础模型,用于交通预测
OpenCity是一个开源的时空基础模型,专注于交通预测领域。该模型通过整合Transformer架构和图神经网络,有效捕捉和标准化交通数据中的复杂时空依赖关系,实现对不同城市环境的零样本泛化。它在大规模、异构的交通数据集上进行预训练,学习到丰富、可泛化的表示,能够无缝应用于多种交通预测场景。
AI天气预测模型,提供高达15天的高精度天气预报
GenCast是由Google DeepMind开发的一款新型高分辨率(0.25°)AI集合模型,它在预测日常天气和极端天气事件方面比欧洲中期天气预报中心(ECMWF)的ENS系统更准确,提前15天提供更快速、更准确的预测。该模型基于扩散模型,是最近在图像、视频和音乐生成中取得快速进展的生成性AI模型的一种。GenCast通过分析历史天气数据学习全球天气模式,并能够准确生成未来天气情景的复杂概率分布。该模型的代码、权重和预测结果将公开发布,以支持更广泛的天气预报社区。
一键部署机器学习模型到生产环境
PoplarML 是一个能够以极低的工程成本部署可扩展的机器学习系统到生产环境的平台。它提供了一键部署的功能,可无缝地将机器学习模型部署到一组GPU上。用户可以通过REST API端点实时调用模型进行推断。PoplarML 支持各种深度学习框架,如Tensorflow、Pytorch和JAX。除此之外,PoplarML 还提供了多项优势,包括高效的实时推断、自动扩展能力以适应流量需求、灵活的部署选项等。定价方面,请访问官方网站获取详细信息。
时序预测的解码器基础模型
TimesFM是一款基于大型时序数据集预训练的解码器基础模型,具有200亿参数。相较于大型语言模型,虽然规模较小,但在不同领域和时间粒度的多个未见数据集上,其零-shot性能接近最先进的监督方法。TimesFM无需额外训练即可提供出色的未见时间序列预测。
轻松创建你自己的机器学习模型
Teachable Machine是一个基于网页的工具,使用户可以快速轻松地创建机器学习模型,无需专业知识或编码能力。用户只需收集并整理样本数据,Teachable Machine将自动训练模型,然后用户可以测试模型准确性,最后将模型导出使用。
机器学习加速 API
DirectML 是Windows上的机器学习平台API,为硬件供应商提供了一个通用的抽象层来暴露他们的机器学习加速器。它可以与任何兼容DirectX 12的设备一起使用,包括GPU和NPU。通过减少编写机器学习代码的成本,DirectML使得AI功能集成更加容易。

© 2026 AIbase 备案号:闽ICP备08105208号-14