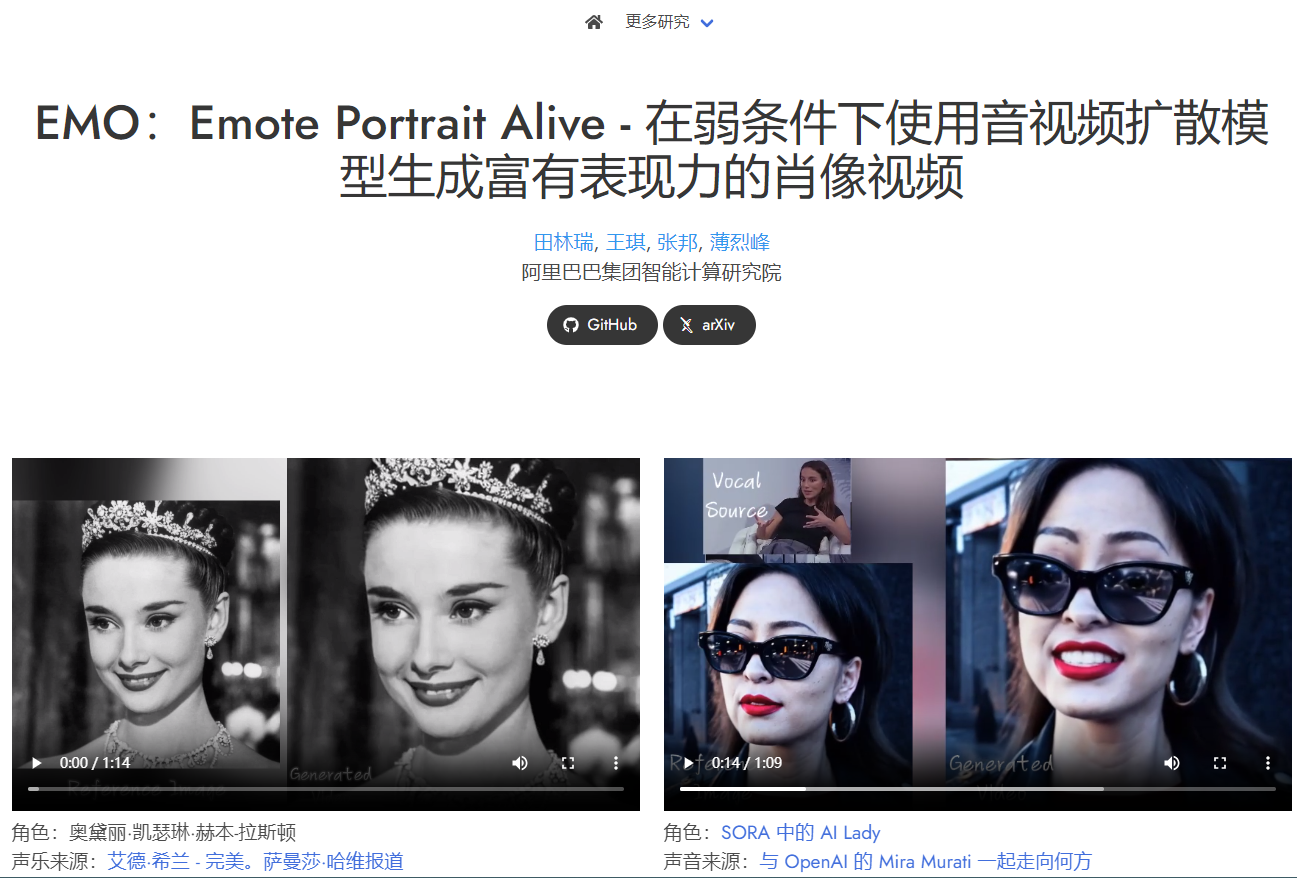
阿里巴巴的EMO: 是一款生成具有表情丰富的面部表情视频的工具,可以根据输入的角色图像和声音音频生成各种头部姿势和表情的声音头像视频。支持多语言歌曲和各种肖像风格,能够根据音频节奏生成动态、表现丰富的动画角色。
需求人群:
"适用于艺术家、创作者、视频制作人等需要生成具有表情丰富的面部表情视频的用户"
使用场景示例:
艺术家使用 EMO 将肖像转化为具有表情的动态视频
视频制作人利用 EMO 为不同语言歌曲添加生动的表情角色
跨文化艺术表演者使用 EMO 进行跨语言表演
产品特色:
根据输入的角色图像和声音音频生成具有表情丰富的面部表情视频
支持多语言歌曲和肖像风格
能够根据音频节奏生成动态、表现丰富的动画角色
适用于生成肖像视频、艺术创作、跨语言表演等场景
浏览量:25698
最新流量情况
月访问量
51.11k
平均访问时长
00:00:40
每次访问页数
1.48
跳出率
48.88%
流量来源
直接访问
38.83%
自然搜索
44.65%
邮件
0.12%
外链引荐
9.85%
社交媒体
5.63%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
德国
5.56%
印度
6.02%
韩国
5.31%
俄罗斯
7.32%
美国
14.37%
通过音频生成充满表情的肖像视频
阿里巴巴的EMO: 是一款生成具有表情丰富的面部表情视频的工具,可以根据输入的角色图像和声音音频生成各种头部姿势和表情的声音头像视频。支持多语言歌曲和各种肖像风格,能够根据音频节奏生成动态、表现丰富的动画角色。
音频驱动的表情丰富的视频生成模型
MEMO是一个先进的开放权重模型,用于音频驱动的说话视频生成。该模型通过记忆引导的时间模块和情感感知的音频模块,增强了长期身份一致性和运动平滑性,同时通过检测音频中的情感来细化面部表情,生成身份一致且富有表情的说话视频。MEMO的主要优点包括更真实的视频生成、更好的音频-唇形同步、身份一致性和表情情感对齐。该技术背景信息显示,MEMO在多种图像和音频类型中生成更真实的说话视频,超越了现有的最先进方法。
生成具有身份一致性和表情丰富性的3D人头模型
ID-to-3D是一种创新的方法,它能够从一张随意拍摄的野外图片中生成具有身份和文本引导的3D人头模型,具有分离的表情。该方法基于组合性,使用特定任务的2D扩散模型作为优化的先验。通过扩展基础模型并添加轻量级的表情感知和身份感知架构,创建了2D先验,用于几何和纹理生成,并通过微调仅0.2%的可用训练参数。结合强大的面部身份嵌入和神经表示,该方法不仅能够准确重建面部特征,还能重建配饰和头发,并可提供适用于游戏和远程呈现的渲染就绪资产。
通过表情丰富的掩蔽音频手势建模实现整体共话手势生成
EMAGE是一种统一的整体共话手势生成模型,通过表情丰富的掩蔽音频手势建模来生成自然的手势动作。它可以从音频输入中捕捉语音和韵律信息,并生成相应的身体姿势和手势动作序列。EMAGE能够生成高度动态和表现力丰富的手势,从而增强虚拟人物的互动体验。
Loopy,仅凭音频驱动肖像头像,实现逼真动态。
Loopy是一个端到端的音频驱动视频扩散模型,专门设计了跨剪辑和内部剪辑的时间模块以及音频到潜在表示模块,使模型能够利用数据中的长期运动信息来学习自然运动模式,并提高音频与肖像运动的相关性。这种方法消除了现有方法中手动指定的空间运动模板的需求,实现了在各种场景下更逼真、高质量的结果。
将静态肖像和输入音频转化为生动的动画对话视频
AniTalker是一个创新的框架,它能够从单一的肖像生成逼真的对话面部动画。它通过两个自监督学习策略增强了动作表现力,同时通过度量学习开发了一个身份编码器,有效减少了对标记数据的需求。AniTalker不仅能够创建详细且逼真的面部动作,还强调了其在现实世界应用中制作动态头像的潜力。
文字转表情,让你的文字更丰富
Usemoji是一个文字转表情的工具,可以让你的文字更加丰富有趣。它提供了丰富的表情选项,让你的文字更生动形象。无论是在聊天、社交媒体还是其他场景,Usemoji都能为你的文字增添一份活力。Usemoji的使用非常简单,只需输入文字即可自动转换为相应的表情。无论你是在写作、聊天还是其他场景中使用,Usemoji都能让你的文字更加生动有趣。
表情包生成器
SDXL表情包生成器是一款基于Apple表情包的Fine-tune模型,可以根据输入的图片生成表情包。用户可以通过上传图片、选择输出图片的大小和数量、选择不同的refine style等参数来生成自己想要的表情包。该产品的优势在于生成速度快、效果好、操作简单,适用于需要大量表情包的用户。定价方面,该产品提供免费试用版和付费版,付费版价格根据使用情况而定。
2D肖像视频转4D高斯场编辑工具
PortraitGen是一个基于多模态生成先验的2D肖像视频编辑工具,能够将2D肖像视频提升到4D高斯场,实现多模态肖像编辑。该技术通过追踪SMPL-X系数和使用神经高斯纹理机制,可以快速生成3D肖像并进行编辑。它还提出了一种迭代数据集更新策略和多模态人脸感知编辑模块,以提高表情质量和保持个性化面部结构。
视频到音乐生成框架,实现音视频内容的语义对齐和节奏同步。
MuVi是一个创新的框架,它通过分析视频内容提取与上下文和时间相关的特征,生成与视频情绪、主题、节奏和节奏相匹配的音乐。该框架引入了对比性音乐-视觉预训练方案,确保音乐短语的周期性同步,并展示了基于流匹配的音乐生成器具有上下文学习能力,允许控制生成音乐的风格和类型。MuVi在音频质量和时间同步方面展现出优越的性能,为音视频内容的融合和沉浸式体验提供了新的解决方案。
音频采样器,创造音乐节奏
ComfyUI-StableAudioSampler 是一款集成在 ComfyUI 节点中的音频采样器插件,它允许用户生成音频并输出原始字节和采样率,支持所有原始 Stable Audio Open 参数,并可以保存音频到文件。这个插件是开源的,并且正在积极开发中,旨在为音乐制作者提供一个易于使用且功能强大的工具。
音频驱动的视频编辑,实现高质量唇形同步
VideoReTalking是一个新的系统,可以根据输入的音频编辑真实世界的说话头部视频的面部,产生高质量的唇形同步输出视频,即使情感不同。该系统将此目标分解为三个连续的任务:(1)使用表情编辑网络生成带有规范表情的面部视频;(2)音频驱动的唇形同步;(3)用于提高照片逼真度的面部增强。给定一个说话头部视频,我们首先使用表情编辑网络根据相同的表情模板修改每个帧的表情,从而得到具有规范表情的视频。然后将该视频与给定的音频一起输入到唇形同步网络中,生成唇形同步视频。最后,我们通过一个身份感知的面部增强网络和后处理来提高合成面部的照片逼真度。我们对所有三个步骤使用基于学习的方法,所有模块都可以在顺序管道中处理,无需任何用户干预。
快速、准确、免费的音频转文字服务
AIbase音频提取文字工具利用人工智能技术,通过机器学习模型快速生成高质量的音频文本描述,优化文本排版,提升可读性,同时完全免费使用,无需安装、下载或付款,为创意人员提供便捷的基础服务。
肖像大师中文版comfyui-portrait-master
肖像大师是一个人物肖像提示词生成插件,可优化肖像生成,选择永远比填空更适合人类!它可以根据用户的需求,生成各种肖像的提示词,包括镜头类型、性别、国籍、面部表情、发型等参数。用户可以根据自己的需要自定义增加内容,例如发型、表情等。肖像大师支持多种工作流,适用于各种场景,如视频制作、设计等。
视频和音频通信平台
Trivoh是一个基于人工智能驱动的视频和音频通信平台,通过自动化提升用户参与度,为您的团队提供全面的协作和通信解决方案,提高整体生产力和效率。Trivoh提供虚拟会议、聊天系统和易于插件等功能,支持多种使用场景。价格根据定制需求而定。
视频到音频生成模型
vta-ldm是一个专注于视频到音频生成的深度学习模型,能够根据视频内容生成语义和时间上与视频输入对齐的音频内容。它代表了视频生成领域的一个新突破,特别是在文本到视频生成技术取得显著进展之后。该模型由腾讯AI实验室的Manjie Xu等人开发,具有生成与视频内容高度一致的音频的能力,对于视频制作、音频后期处理等领域具有重要的应用价值。
免费在线AI表情生成器,多种风格模板,轻松打造个性表情
AI Emoji是一款免费在线的AI表情生成器,它利用先进的AI技术,能将用户上传的照片转化为独特有趣的表情。产品背景是满足用户对于个性化表情的需求,用户可以在日常交流、工作场景、节日庆祝等多个场景中使用这些表情,增添趣味。其主要优点包括操作简单快捷、风格多样、AI智能分析生成等。价格方面,有免费套餐,包含有限的使用额度,也可购买更多额度进行创作。产品定位为面向广大用户群体,提供便捷、有趣的个性化表情制作服务。
可搜索、复制21,857+表情和ASCII艺术,为任何心情找到完美表情。
CuteEmoji.AI是一个在线网站,主要功能是提供丰富的表情符号和ASCII艺术供用户搜索和复制。其重要性在于满足用户在各种社交平台交流时使用多样化表情的需求。优点包括拥有超过21857个表情和ASCII艺术,用户可以即时搜索并复制,适用于WhatsApp、Instagram、Twitter、Discord等多个社交平台。产品背景未提及,目前未发现收费信息,定位为满足用户日常社交中表情使用需求的工具。
生成会说话、唱歌的动态视频
AniPortrait是一个根据音频和图像输入生成会说话、唱歌的动态视频的项目。它能够根据音频和静态人脸图片生成逼真的人脸动画,口型保持一致。支持多种语言和面部重绘、头部姿势控制。功能包括音频驱动的动画合成、面部再现、头部姿势控制、支持自驱动和音频驱动的视频生成、高质量动画生成以及灵活的模型和权重配置。
将您想阅读的文章转化为丰富的音频摘要
Recast是一个插件,可以将您想阅读的文章转化为丰富的音频摘要。它使用机器学习技术将文章进行自动摘要和语音合成,让您可以通过听音频的方式轻松消化大量的文章内容。Recast还提供了多种定价选项,适合不同需求和预算。无论您是在工作中需要阅读大量的资料,还是在休闲时间想要了解最新的新闻和文章,Recast都能帮助您节省时间,提高阅读效率。
音频转文字及视频字幕服务
Happy Scribe 提供自动和人工转录服务,将音频转换为文本,准确率达到 85-99%,支持 120 多种语言和 45 多种格式。定位于为用户提供高效的音视频转录及字幕服务。
生成逼真的AI肖像
PhotoStudio是一款利用人工智能生成逼真肖像的应用。用户可以使用PhotoStudio来生成逼真的AI肖像。该应用提供了30个AI肖像的内购选项,定价为26.99美元。PhotoStudio支持多种语言,适用于iOS 14.0及更高版本的iPhone和iPod touch。
实时AI代理,将音频视频直接集成至视频会议。
Recall.ai Output Media是一个创新的AI技术,它允许用户将任何基于Web的AI应用实时集成到视频会议中。这项技术通过渲染超低延迟的音频和视频,并通过机器人将其流式传输到视频会议中,极大地扩展了AI在会议场景中的应用。Recall.ai的这项技术不仅提高了会议的互动性,还为各种行业提供了构建实时、互动AI代理的可能性,如销售代理、教练、招聘人员、项目经理等。
一键将视频和音频转化为各种风格的文档。
AI 视频图文创作助手是一个开源工具,旨在将视频和音频内容转化为多种格式的文档,帮助用户进行二次阅读和思考。该产品的主要优势在于其完全开源、无需注册,用户可以在本地处理音视频文件,降低了使用成本。它非常适合需要将视听内容转化为文本的学生、研究人员和内容创作者。
找到您想要的表情符号或表情图标
emoticon.pro是一个在线平台,用于描述和查找表情符号或表情图标。它提供了一个广泛的表情符号和表情图标库,用户可以通过搜索或浏览来找到他们想要的表情符号。该平台还提供了详细的描述和解释,帮助用户更好地理解和使用表情符号。emoticon.pro的优势在于其丰富的表情符号库和用户友好的界面。该平台是免费的,并且不需要用户注册。用户可以直接访问网站,搜索并使用他们想要的表情符号。
视频音频全流程再利用
GlossAi是一款全流程视频和音频内容再利用工具,可将长篇内容转化为适用于各种社交媒体平台的短视频片段,提高用户参与度,降低成本,节省时间。同时,它还能生成多渠道的数字和有机营销活动。
全球最大的音频库,提供有声书、播客等丰富音频资源。
Azalea Labs是一个音频资源平台,作为全球最大的音频库,它拥有海量的有声书、播客等资源。其重要性在于为用户提供了便捷获取各类音频内容的途径,满足了不同用户的音频需求。主要优点包括资源丰富、可免费试用一段时间。产品定位是打造一个集多种音频内容于一体的平台,让用户能够轻松享受音频带来的乐趣。目前未提及价格相关信息,推测可免费试用。

© 2026 AIbase 备案号:闽ICP备08105208号-14