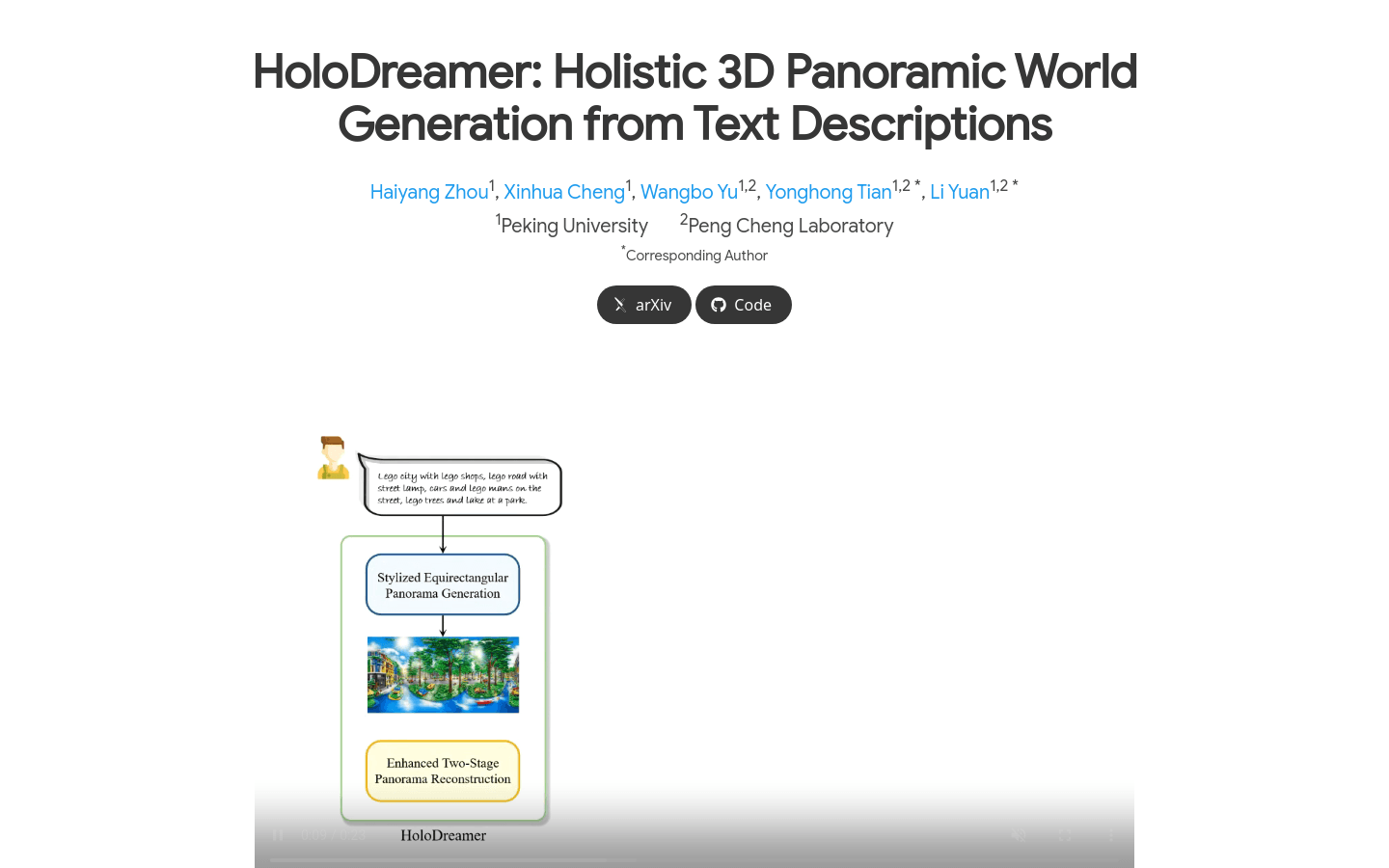
HoloDreamer是一个文本驱动的3D场景生成框架,能够生成沉浸式且视角一致的全封闭3D场景。它由两个基本模块组成:风格化等矩形全景生成和增强两阶段全景重建。该框架首先生成高清晰度的全景图作为完整3D场景的整体初始化,然后利用3D高斯散射(3D-GS)技术快速重建3D场景,从而实现视角一致和完全封闭的3D场景生成。HoloDreamer的主要优点包括高视觉一致性、和谐性以及重建质量和渲染的鲁棒性。
需求人群:
"HoloDreamer的目标受众包括虚拟现实、游戏和电影行业的专业人士。这些领域需要高质量的3D场景生成技术来提升用户体验。HoloDreamer通过文本提示生成3D场景,提供了一种快速、灵活且成本效益高的解决方案,适合需要快速原型设计和场景预览的专业人士。"
使用场景示例:
在虚拟现实中,设计师可以使用HoloDreamer快速生成一个虚拟城市,进行初步设计和测试。
游戏开发者可以利用HoloDreamer生成独特的游戏场景,提升游戏的沉浸感和视觉效果。
电影制作者可以利用HoloDreamer生成复杂的电影场景,进行预览和修改,优化最终的视觉效果。
产品特色:
风格化等矩形全景生成:结合多个扩散模型,从复杂的文本提示生成风格化和详细的等矩形全景图。
增强两阶段全景重建:进行深度估计并投影RGBD数据以获取点云,使用基础相机和辅助相机在不同场景下进行投影和渲染。
3D高斯散射(3D-GS):快速重建3D场景,增强场景的完整性。
多视图监督:利用2D扩散模型生成初始局部图像,然后逐步生成场景,提高全局一致性。
全景图旋转无裂缝:应用圆形混合技术,避免在旋转全景图时出现裂缝。
两阶段优化:在传递优化阶段对重建场景的渲染图像进行内绘,优化3D-GS,生成最终重建场景。
高清晰度全景初始化:生成高清晰度全景图作为3D场景的整体初始化,提高重建的质量和一致性。
使用教程:
1. 输入文本描述:用户输入描述3D场景的文本提示。
2. 生成全景图:HoloDreamer使用多个扩散模型生成风格化和详细的等矩形全景图。
3. 深度估计:对生成的全景图进行深度估计,生成RGBD数据。
4. 点云生成:将RGBD数据投影到3D空间,生成点云。
5. 3D场景重建:利用3D高斯散射技术快速重建3D场景。
6. 两阶段优化:在传递优化阶段对重建场景的渲染图像进行内绘,优化3D-GS,生成最终重建场景。
7. 渲染和输出:最终生成的3D场景可以用于虚拟现实、游戏或电影制作中。
浏览量:189
从文本描述生成全息3D全景世界
HoloDreamer是一个文本驱动的3D场景生成框架,能够生成沉浸式且视角一致的全封闭3D场景。它由两个基本模块组成:风格化等矩形全景生成和增强两阶段全景重建。该框架首先生成高清晰度的全景图作为完整3D场景的整体初始化,然后利用3D高斯散射(3D-GS)技术快速重建3D场景,从而实现视角一致和完全封闭的3D场景生成。HoloDreamer的主要优点包括高视觉一致性、和谐性以及重建质量和渲染的鲁棒性。
Formy 3D可将照片、文本快速转化为专业3D模型
Formy 3D是一款先进的AI 3D生成器,于2024年创立。它利用拥有100亿参数的扩散模型技术,能理解自然语言和视觉参考,将文本描述和图像转化为高质量3D模型。与传统3D建模软件不同,它无需专业经验,即可在几分钟内创建出专业的3D资产。该平台提供免费的基础计划,也有每月24.99美元的Plus计划,适用于需要快速创建3D模型的个人和企业。
使用Hunyuan 3D和Seed3D,从文本或图像生成AI 3D模型,免费在线生成。
该产品是一个在线的AI 3D模型生成平台,整合了腾讯的Hunyuan 3D和字节跳动的Seed 3D。其重要性在于打破了传统3D建模的技术门槛,让没有3D技能的用户也能轻松生成3D模型。主要优点包括生成速度快,能在短时间内从文本或图像生成具有完整PBR材质的3D模型;支持多种格式导出,方便在不同的3D软件和平台中使用;用户可以同时运行两个模型并选择最佳输出。价格方面,生成模型需要消耗积分,比如生成一次需要20积分,但也提供免费使用的机会。产品定位是为广大需要3D模型的用户提供便捷、高效的3D模型生成服务。
从单张图片生成交互式3D场景
WonderWorld是一个创新的3D场景扩展框架,允许用户基于单张输入图片和用户指定的文本探索和塑造虚拟环境。它通过快速高斯体素和引导扩散的深度估计方法,显著减少了计算时间,生成几何一致的扩展,使3D场景的生成时间少于10秒,支持实时用户交互和探索。这为虚拟现实、游戏和创意设计等领域提供了快速生成和导航沉浸式虚拟世界的可能性。
文本引导的高保真3D场景合成
SceneWiz3D是一种新颖的方法,可以从文本中合成高保真的3D场景。它采用混合的3D表示,对对象采用显式表示,对场景采用隐式表示。用户可以通过传统的文本到3D方法或自行提供对象来生成对象。为了配置场景布局并自动放置对象,我们在优化过程中应用了粒子群优化技术。此外,在文本到场景的情况下,对于场景的某些部分(例如角落、遮挡),很难获得多视角监督,导致几何形状劣质。为了缓解这种监督缺失,我们引入了RGBD全景扩散模型作为额外先验,从而实现了高质量的几何形状。广泛的评估支持我们的方法实现了比以前的方法更高的质量,可以生成详细且视角一致的3D场景。
文本到3D沉浸场景生成
Text2Immersion是一个优雅的从文本提示生成高质量3D沉浸场景的方法。我们提出的流水线首先使用预训练的2D扩散和深度估计模型逐步生成高斯云。接下来是对高斯云进行精炼,插值和精炼以增强生成场景的细节。与仅关注单个物体或室内场景,或采用缩小轨迹的主流方法不同,我们的方法可以生成包含各种物体的不同场景,甚至扩展到创造想象中的场景。因此,Text2Immersion可以对各种应用产生广泛的影响,如虚拟现实、游戏开发和自动内容创建。大量的评估证明我们的系统在渲染质量和多样性方面优于其他方法,并且继续推进面向文本的3D场景生成。
从单张图片生成高质量3D网格模型
Unique3D是由清华大学团队开发的一项技术,能够从单张图片中生成高保真度的纹理3D网格模型。这项技术在图像处理和3D建模领域具有重要意义,它使得用户能够快速将2D图像转化为3D模型,为游戏开发、动画制作、虚拟现实等领域提供了强大的技术支持。
AI 3D工具,可从文本或图像快速创建、动画高质量3D模型
VARCO 3D是一款前沿的AI 3D创作工具,其核心技术是利用人工智能算法,将用户输入的文本或图像转化为高质量的3D模型。该产品的重要性在于极大地降低了3D建模的门槛,让不同技能水平的创作者都能轻松参与到3D内容创作中。主要优点包括速度极快,能在短时间内生成3D模型,显著缩短从概念到成品的时间;支持多语言输入,方便全球用户使用;具有丰富的模型编辑功能,如网格变化、纹理变化等;还能实现一键绑定和动画制作。产品定位为面向广大3D创作爱好者、专业艺术家以及游戏开发者等群体,助力他们更高效地完成3D内容创作。关于价格,文档未提及。
AI 生成定制 3D 模型
3D AI Studio 是一款基于人工智能技术的在线工具,可以轻松生成定制的 3D 模型。适用于设计师、开发者和创意人士,提供高质量的数字资产。用户可以通过AI生成器快速创建3D模型,并以FBX、GLB或USDZ格式导出。3D AI Studio具有高性能、用户友好的界面、自动生成真实纹理等特点,可大幅缩短建模时间和降低成本。
Tripo AI 3D 模型生成器可将文本和图片几秒内转为可用于生产的3D模型。
Tripo AI 3D 模型生成器是一款在线的AI 3D模型生成工具,集成在一个流畅的工作流程中,能将文字、图片或草图快速转化为可用于生产的3D资产。其主要优点在于速度快,能将数小时的人工3D作业缩短至秒级完成;成本低,借助智能算法提高效率从而降低成本;功能强大,具备文字和图片生成3D模型、智能分割、AI纹理、绑骨与动画等多种功能。产品背景是为了满足创意行业对于高效3D建模的需求。该产品提供免费试用,无需注册,支持导出GLB/STL/OBJ格式,用于游戏和3D打印等领域,定位是为全球创作者提供更智能、更简化的3D建模解决方案。
3D场景重建与动态物体追踪技术
EgoGaussian是一项先进的3D场景重建与动态物体追踪技术,它能够仅通过RGB第一人称视角输入,同时重建3D场景并动态追踪物体的运动。这项技术利用高斯散射的独特离散特性,从背景中分割出动态交互,并通过片段级别的在线学习流程,利用人类活动的动态特性,以时间顺序重建场景的演变并追踪刚体物体的运动。EgoGaussian在野外视频的挑战中超越了先前的NeRF和动态高斯方法,并且在重建模型的质量上也表现出色。
3D场景创造革命,电影级效果
Lixel CyberColor(LCC),由XGRIDS公司研发的先进技术产品,为3D场景的创建带来革命性变化。LCC能自动生成电影级效果的无限大3D场景,使用Multi-SLAM和高斯溅射技术。其核心优势在于精确捕捉并复现真实细节,为虚拟现实、游戏开发、电影制作等领域带来真实性体验。 XGRIDS作为一套集成软硬件解决方案,展现出在微米到千米级别的高精度3D重建和智能空间计算方面的强大能力。采用Multi-SLAM算法和优化的3DGS技术,自动创建超逼真大型3D模型,沉浸式体验。优化算法实现逼真渲染效果,通过数据压缩技术将模型大小减小90%,LiDAR集成技术实现厘米级模型精度,提供AI驱动的动态物体去除算法。推出LCC插件和SDK,在Unity、UE、Web、移动平台使用,为3D内容提供强大支持。
SAM 3D:AI驱动,秒速将2D图像转化为专业级3D模型
SAM 3D是一款由人工智能驱动的3D重建平台,它基于先进的SAM(Segment Anything Model)技术,实现了将单张2D照片转化为精确、全纹理3D模型的突破。该平台打破了传统3D建模的壁垒,无需昂贵设备和专业技术知识,为全球开发者、设计师、研究人员和内容创作者提供了企业级的3D重建能力。其重要性在于降低了3D建模的门槛,使更多人能够轻松获得高质量的3D模型。价格方面,提供免费使用,无需信用卡信息。产品定位是为各行业提供便捷、高效的3D重建解决方案。
快速从单张图片生成3D模型。
Stable Fast 3D (SF3D) 是一个基于TripoSR的大型重建模型,能够从单张物体图片生成带有纹理的UV展开3D网格资产。该模型训练有素,能在不到一秒的时间内创建3D模型,具有较低的多边形计数,并且进行了UV展开和纹理处理,使得模型在下游应用如游戏引擎或渲染工作中更易于使用。此外,模型还能预测每个物体的材料参数(粗糙度、金属感),在渲染过程中增强反射行为。SF3D适用于需要快速3D建模的领域,如游戏开发、电影特效制作等。
逼真可动的3D头像生成模型
UltrAvatar是一款逼真可动的3D头像生成模型,旨在缩小虚拟与现实世界体验之间的差距。它采用Score Distillation Sampling (SDS) loss和可微分渲染器以及文本条件来引导扩散模型生成3D头像。与现有作品相比,UltrAvatar通过增强几何保真度和优越的物理渲染纹理质量,提出了一种新颖的3D头像生成方法。它通过扩散色彩提取模型和真实性引导纹理扩散模型,去除不需要的光照效果,呈现真实的扩散颜色,使生成的头像能够在各种光照条件下呈现。我们在实验证明了该方法的有效性和鲁棒性,在实验中大幅优于现有最先进的方法。
高质量3D资产生成技术
Edify 3D是NVIDIA推出的一款AI驱动的3D资产生成技术,它能够在两分钟内生成详细的、生产就绪的3D资产,包括组织良好的UV贴图、4K纹理和PBR材料。这项技术使用多视图扩散模型和基于Transformer的重建,能够从文本提示或参考图像合成高质量的3D资产,实现卓越的效率和可扩展性。Edify 3D对于视频游戏设计、扩展现实、电影制作和仿真等需要严格生产标准的行业至关重要。
Kreat3D是AI驱动的3D模型创建平台,可快速将图像和文本转化为3D模型。
Kreat3D是一款由人工智能驱动的3D模型创建平台,其重要性在于降低了3D模型创建的门槛,让更多人能够轻松参与到3D内容的创作中。主要优点包括:能够快速将图像和文本转化为3D模型,无需复杂的建模工具;支持多种输入方式和输出格式,适用于不同的使用场景;集成了多个先进的生成模型,具备灵活和不断进化的能力。产品背景是为了满足设计师、开发者和创作者对于高效创建3D模型的需求。价格方面,提供免费试用,付费计划则解锁更高的生成限制、高级参数、更快的处理优先级和商业使用权。定位是面向广大3D内容创作者,提供便捷、高效、高质量的3D模型创建解决方案。
腾讯推出的3D生成框架,支持文本和图像到3D的生成。
Hunyuan3D-1是腾讯推出的一个统一框架,用于文本到3D和图像到3D的生成。该框架采用两阶段方法,第一阶段使用多视图扩散模型快速生成多视图RGB图像,第二阶段通过前馈重建模型快速重建3D资产。Hunyuan3D-1.0在速度和质量之间取得了令人印象深刻的平衡,显著减少了生成时间,同时保持了生成资产的质量和多样性。
Pixal3D是像素对齐AI 3D生成器,支持图转3D和文本生成动画
Pixal3D是一款AI 3D生成器,通过像素对齐技术和PBR纹理,可将图像转换为GLB模型。其重要性在于为3D内容创作提供了高效、精确的解决方案。主要优点包括像素对齐的高精度3D生成、支持多种模型和输出格式、提供浏览器免费工具等。该产品面向3D设计、游戏开发、广告制作等领域,价格根据不同计划而定,需要登录账号使用,登录后可更新信用点数,有180 - 390信用点的相关设定。
探索3D虚拟世界,体验梦想家宇宙。
Aiuni是一个提供3D虚拟世界体验的平台,用户可以在这里创建和探索个性化的3D模型,享受沉浸式的宇宙探索之旅。Aiuni以其创新的3D技术、丰富的互动性和高度的个性化定制,为用户提供了一个全新的虚拟体验空间。
将2D图片转换为3D模型的AI系统
Any Image to 3D是一款创新的AI系统,可以将复杂的2D图片转换为3D模型。它消除了生成3D内容的技术难题,使得任何人都可以轻松地生成3D模型。它适用于游戏、机器人、混合现实、视觉特效和电子商务等领域。通过简单的可视化,用户可以将想法转化为详细的3D模型。
通过文本生成3D场景中的对象插入
InseRF是一种通过文本提示和2D边界框在NeRF重建的3D场景中生成新对象的方法。它能够从用户提供的文本描述和一个参考视点中的2D边界框中生成新的3D对象,并将其插入到场景中。该方法能够在不需要显式3D信息的情况下实现可控的、与3D一致的对象插入。通过在多个3D场景中进行试验,证明了InseRF方法相对于现有方法的有效性。
虚拟现实社交平台
IllusionDiffusion是一款虚拟现实社交平台,用户可以在其中创建自己的虚拟形象,与其他用户进行社交互动。IllusionDiffusion支持多种虚拟现实设备,包括头戴式显示器和智能手机,用户可以使用手势和语音进行操作。Spaces还提供了多种虚拟场景和游戏,让用户在虚拟世界中尽情探索和体验。IllusionDiffusion的定价策略灵活,提供了免费和付费两种服务方案。
Hunyuan 3D AI将文本和图像转化为含PBR纹理的高质量3D模型,无需建模经验。
Hunyuan 3D是腾讯的革命性Hunyuan3D v3平台,采用先进3D AI技术,能快速将文本和图像转化为专业3D模型。其重要性在于降低了3D建模门槛,让非专业人士也能参与创作。主要优点是速度快、精度高、纹理质量好,使用100亿参数模型。产品定位为面向广泛用户的3D建模平台。价格方面,有免费的基础计划和每月24.99美元的Plus计划。
基于Meta的SAM 3D模型,可秒将单张图像转换成高质量3D模型。
SAM 3D是一款在线工具,基于Meta的SAM 3D研究模型,可将单张图像快速转换为高质量的3D模型。其重要性在于打破了传统摄影测量和仅使用合成数据训练的限制,为3D重建带来了语义理解。主要优点包括在复杂真实场景下的高鲁棒性、快速推理、支持标准3D格式导出等。产品背景是Meta在计算机视觉领域的研究成果,页面未提及价格信息,定位是为用户提供便捷的3D重建服务。

© 2026 AIbase 备案号:闽ICP备08105208号-14