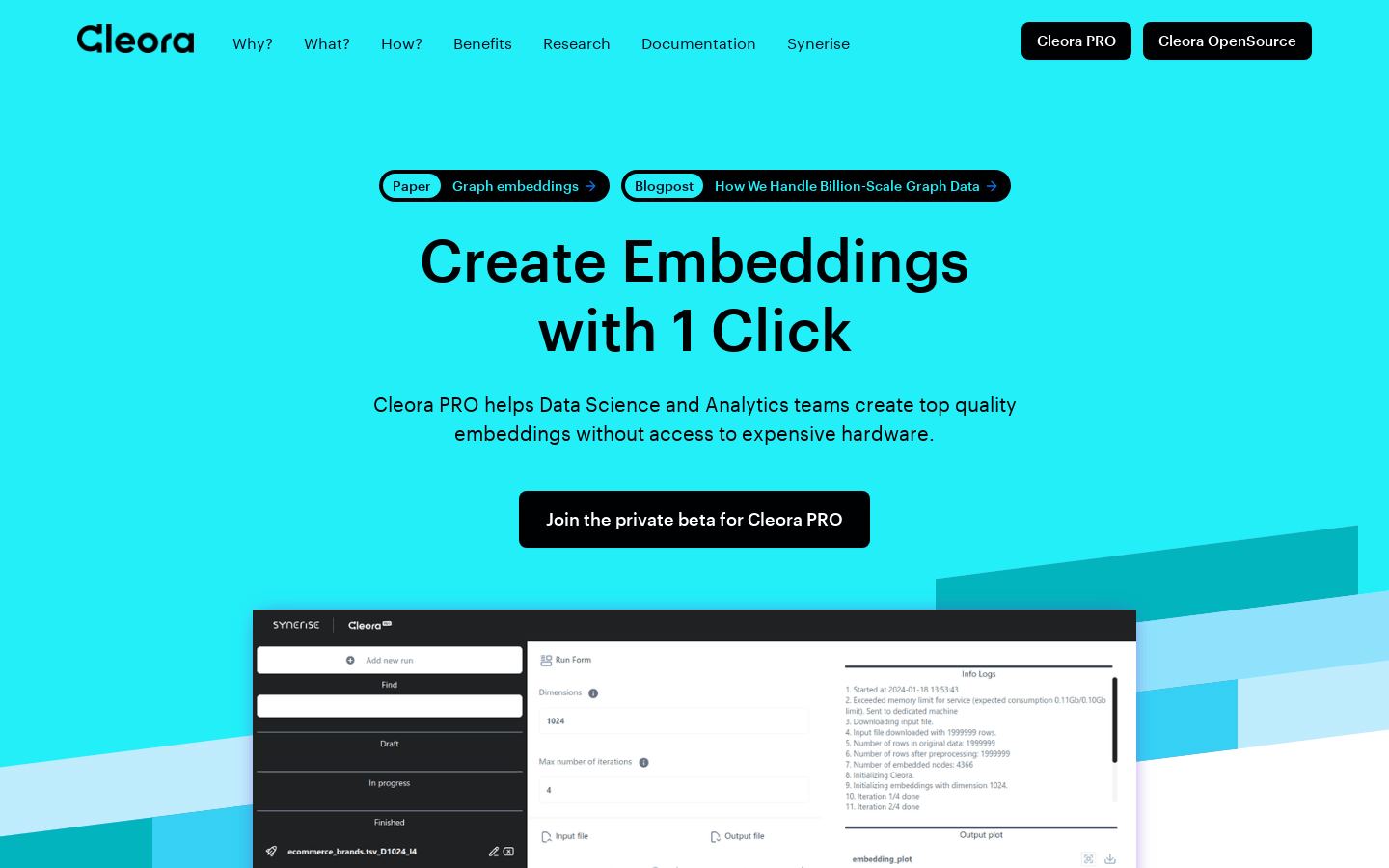
Cleora PRO是一款帮助数据科学团队在没有昂贵硬件的情况下创建高质量的客户和产品嵌入向量的工具。它可以将实体(例如客户、产品、店铺、账户等)通过嵌入向量表示,类似于文本中的Word2Vec或BERT,或者图像中的CLIP。Cleora的嵌入向量是行为型的,通过实体的行为历史来表示,这些历史以大型图的形式存在。使用Cleora PRO,您可以构建推荐系统、客户细分、倾向预测、生命周期价值建模、流失预测等企业模型。
需求人群:
Cleora PRO适用于数据科学和分析团队,帮助他们快速创建高质量的嵌入向量。它适用于各种企业模型,包括推荐系统、客户细分、倾向预测、生命周期价值建模、流失预测等。
使用场景示例:
使用Cleora PRO创建一个电子商务网站的推荐系统
利用Cleora PRO对客户进行细分,提高个性化营销效果
通过Cleora PRO预测客户的购买倾向,优化销售策略
产品特色:
创建高质量的嵌入向量
支持自动扩展,无需昂贵硬件
仅需3个数据库中的列信息
性能优化,嵌入速度快
支持最新的研究成果,嵌入质量显著提高
支持项目属性
浏览量:43
最新流量情况
月访问量
125
平均访问时长
00:00:00
每次访问页数
1.03
跳出率
24.57%
流量来源
直接访问
0
自然搜索
0
邮件
0
外链引荐
0
社交媒体
0
展示广告
0
截止目前所有流量趋势图
创建企业级嵌入向量,一键生成
Cleora PRO是一款帮助数据科学团队在没有昂贵硬件的情况下创建高质量的客户和产品嵌入向量的工具。它可以将实体(例如客户、产品、店铺、账户等)通过嵌入向量表示,类似于文本中的Word2Vec或BERT,或者图像中的CLIP。Cleora的嵌入向量是行为型的,通过实体的行为历史来表示,这些历史以大型图的形式存在。使用Cleora PRO,您可以构建推荐系统、客户细分、倾向预测、生命周期价值建模、流失预测等企业模型。
嵌入编辑器,优化向量搜索
Embedditor是一款开源的嵌入编辑器,类似于MS Word,能够帮助您充分利用向量搜索。通过用户友好的界面,改进您的嵌入元数据和嵌入标记。无缝应用高级NLP清洗技术,如TF-IDF,规范化和丰富您的嵌入标记,提高LLM相关应用的效率和准确性。优化您从向量数据库获取的内容的相关性,智能拆分或合并内容,基于其结构添加空白或隐藏标记,使块更具语义一致性。您可以完全控制您的数据,轻松在个人计算机上或专用企业云或本地环境中部署Embedditor,提高数据安全性。通过应用Embedditor的高级清洗技术,过滤掉嵌入中的无关标记,如停用词、标点符号和低相关性的常用词,您可以节省多达40%的嵌入和向量存储成本,同时获得更好的搜索结果。
Go语言库,用于嵌入式向量搜索和语义嵌入
kelindar/search 是一个Go语言库,它提供了嵌入式向量搜索和语义嵌入的功能,基于llama.cpp构建。这个库特别适合于小到中型项目,需要强大的语义搜索能力,同时保持简单高效的实现。它支持GGUF BERT模型,允许用户利用复杂的嵌入技术,而不需要深陷传统搜索系统的复杂性。该库还提供了GPU加速功能,能够在支持的硬件上快速进行计算。如果你的数据集少于100,000条目,这个库可以轻松集成到你的Go应用中,实现语义搜索功能。
AI助手嵌入工具
Embedditor是一个开源的嵌入工具,帮助您在向量搜索中发挥最大作用。通过用户友好的界面,改善嵌入元数据和嵌入令牌。无缝应用高级NLP清理技术,如TF-IDF,标准化和丰富您的嵌入令牌,提高在LLM相关应用中的效率和准确性。还可以通过智能拆分或合并内容,根据其结构增加空白或隐藏令牌,使块更具语义一致性,优化从向量数据库中获取的内容的相关性。并且您可以完全控制数据,轻松部署Embedditor在您的PC上,或者在专用企业云或本地环境中。通过应用Embedditor的高级清理技术,过滤嵌入的无关令牌,如停用词、标点符号和低相关性频繁词,您可以在嵌入和向量存储的成本上节省高达40%,同时获得更好的搜索结果。
同步向量存储,连接数据源
Neum AI帮助公司将数据与向量存储同步,确保AI应用程序始终具有准确和实时的上下文。通过内置连接器,将数据源(如Amazon S3和Azure Blob Storage)和向量存储(如Pinecone和Weaviate)自动复制到您的向量存储中,保持向量与数据的同步。您还可以使用内置连接器进行数据转换和嵌入,以及使用角色-based访问控制来控制对数据的访问权限。Neum AI可扩展且灵活,您可以自定义嵌入模型、向量存储和数据源。快速开始使用Neum AI,将您的AI应用程序的上下文保持准确和实时。
高性能AI应用的向量数据库
Pinecone是一个全面管理、开发人员友好且可轻松扩展的向量数据库,可通过API调用以毫秒级时间搜索数十亿个项目的相似匹配。它是下一代搜索技术,只需一个API调用即可使用。
ChatGPT 数据与分析是一个全面的资源、材料和指南目录,旨在帮助您掌握人工智能的艺术。
ChatGPT 数据与分析是一个包含资源、材料和指南的综合目录,涵盖了与 ChatGPT 相关的内容。该目录旨在帮助您提高 AI 技能。本书提供了 ChatGPT 的提示,可帮助您释放创造力,提高工作效率。提示清晰简明。本目录中的所有材料都经过精心策划,确保来源可靠和权威,为您提供高质量的信息和指导。
数据科学准备
Daetama 是领先的数据科学和面试准备平台,旨在为学生提供优质的 SQL 和数据科学相关学习资料。我们的数据科学材料由 Meta 和 Google 数据科学家精心策划,他们用相同的材料成功获得了心仪的工作。现在我们想通过提供这些高质量内容以可负担的月度订阅价格来为您提供同样的帮助。
开源数据科学公司
Posit是一家致力于为个人、团队和企业创建令人难以置信的开源工具的公司。它提供开源云和企业产品,包括RStudio IDE、Shiny、Posit Cloud等。Posit的产品能够加速数据分析和数据科学的过程,适用于不同规模的用户。Posit的产品定价灵活,适合个人用户、学术界、小型企业和大型企业。
一个用于多模型嵌入的图形库,支持多种模型和数据类型的可视化
vectrix-graphs 是一个强大的图形库,专注于多模型嵌入的可视化。它支持多种机器学习模型和数据类型,能够将复杂的数据结构以直观的图形形式展现出来。该库的主要优点在于其灵活性和扩展性,可以轻松集成到现有的数据科学工作流程中。vectrix-ai 团队开发了这个库,旨在帮助研究人员和开发者更好地理解和分析模型的嵌入结果。作为一个开源项目,它在 GitHub 上提供免费使用,适合各种规模的项目和团队。
Gemini Embedding 是一种先进的文本嵌入模型,通过 Gemini API 提供强大的语言理解能力。
Gemini Embedding 是 Google 推出的一种实验性文本嵌入模型,通过 Gemini API 提供服务。该模型在多语言文本嵌入基准测试(MTEB)中表现卓越,超越了之前的顶尖模型。它能够将文本转换为高维数值向量,捕捉语义和上下文信息,广泛应用于检索、分类、相似性检测等场景。Gemini Embedding 支持超过 100 种语言,具备 8K 输入标记长度和 3K 输出维度,同时引入了嵌套表示学习(MRL)技术,可灵活调整维度以满足存储需求。该模型目前处于实验阶段,未来将推出稳定版本。
AI优先的基础设施API,提供搜索、推荐和RAG服务
Trieve是一个AI优先的基础设施API,结合了语言模型和工具,用于微调排名和相关性,提供一站式的搜索、推荐、RAG和分析解决方案。它能够自动持续改进,基于数十个反馈信号,确保相关性。Trieve支持语义向量搜索、BM25和SPlade全文搜索,以及混合搜索,结合全文搜索和语义向量搜索。此外,它还提供了商品推销和相关性调整功能,帮助用户通过API或无代码仪表板调整搜索结果以实现KPI。Trieve建立在最佳基础之上,使用开源嵌入模型和LLMs,运行在自己的服务器上,确保数据安全。
高性能、成本效益的向量数据库,为GenAI应用打造。
Zilliz Cloud Serverless是一个为GenAI应用设计的高性能向量数据库服务,它提供了自动扩展的数据库能力,成本随着业务增长而增加。该产品使用分层存储系统,结合DRAM、SSD和对象存储自动优化数据放置,确保活跃数据快速访问的同时降低不常用信息的成本,无需手动管理。Zilliz Cloud Serverless以其成本效益、数据可移植性和自动扩展能力,为需要处理大规模向量数据的企业提供了一个强大的解决方案。
SvectorDB是一个从头开始构建的面向无服务器的向量数据库。专注于产品,而不是数据库。高性能,成本效益高,比其他替代方案节省多达20倍。
SvectorDB是一个面向无服务器的向量数据库,旨在最大程度地提高敏捷性并降低成本。它解决了数据库的痛点,让您能够专注于将产品从1个向量扩展到100万个向量。
出色的数据科学工具
MLJAR提供出色的数据科学工具和学习材料,帮助用户理解和利用他们的数据。产品功能包括自动化机器学习、将笔记本转换为交互式网络应用、使用LLMs生成Python图表、构建自己的SaaS以及服务器和网站监控。MLJAR的优势在于提供XAI能力、公平的机器学习、模型解释、公平度指标、以及快速检测异常并及时通知。定价方面,MLJAR提供了多种产品比较和决策树、随机森林、Xgboost、LightGBM、CatBoost等算法的比较。定位于数据科学工具领域。
Ploomber Cloud是一个面向数据科学的协作平台
Ploomber Cloud是一个面向数据科学家和机器学习工程师的在线协作平台。它通过版本控制和环境管理来实现数据科学项目的可重现性,让用户能够轻松地与团队成员分享代码、数据和运行环境。主要功能包括:追踪项目迭代历史;支持Jupyter和集成开发环境,平滑数据科学工作流程;利用Docker和Kubernetes实现环境一致性;支持Notebook和脚本的运行和调度。该产品采用按量计费的订阅模式,面向需要协同工作的企业数据科学团队。
一个AI驱动的数据科学团队,帮助用户更快地完成常见数据科学任务。
该产品是一个AI驱动的数据科学团队模型,旨在帮助用户以更快的速度完成数据科学任务。它通过一系列专业的数据科学代理(Agents),如数据清洗、特征工程、建模等,来自动化和加速数据科学工作流程。该产品的主要优点是能够显著提高数据科学工作的效率,减少人工干预,适用于需要快速处理和分析大量数据的企业和研究机构。产品目前处于Beta阶段,正在积极开发中,可能会有突破性变化。它采用MIT许可证,用户可以在GitHub上免费使用和贡献代码。
数据科学与机器学习云平台
Saturn Cloud是一个解决数据科学和机器学习所需复杂基础设施管理和扩展的云平台。它提供了使用R和Python进行数据科学的环境,支持GPU、Dask集群等功能。Saturn Cloud可以帮助数据科学家、数据科学领导者和软件工程师简化开发、部署和数据处理的流程。该产品提供不同的功能和定价计划以满足各种需求。
一个开源的企业级数据科学平台
Domino Data Lab是一个统一、协作、管控的端到端企业级AI平台。该平台可以在任何环境下构建、部署和管理AI模型,访问任何环境下的数据、工具、计算和项目。Domino Data Lab通过建立最佳实践、跟踪生产中的模型以及加强治理,帮助企业加速AI应用、扩大AI规模,同时确保治理并降低成本。
在线学习数据科学和 AI
DataCamp 是一个在线学习平台,提供数据科学、AI 及相关领域的课程。它提供动手实践的学习体验,包括交互式练习和短视频,涵盖了广泛的话题,包括 Python、R、SQL、ChatGPT、Power BI 等。DataCamp 还提供数据科学职业发展的认证和资源。
AI、机器学习和数据科学工作的最佳选择
Best AI Jobs是#1人工智能工作板,拥有2000多个工作职位,包括人工智能软件工程师、AI开发人员、机器学习工程师等。在AI领域找到一份工作,加入未来!
自动化科学研究的多智能体图推理系统。
SciAgentsDiscovery 是一个利用多智能体系统和大规模本体知识图谱,自动化科学研究的系统。它通过整合大型语言模型、数据检索工具和多智能体学习系统,能够自主生成和完善研究假设,揭示潜在的机制、设计原则和意外材料属性。该系统在生物启发材料领域展示了其跨学科关系的发现能力,超越了传统人类驱动的研究方法。
开源向量数据库,适用于开发者构建通用AI应用。
Milvus是一个为开发者设计的开源向量数据库,专门用于大规模高维向量的相似性搜索。它支持pip安装,可以与流行的AI开发工具一起使用,并且能够扩展到数十亿个向量。Milvus以其高效的向量相似性搜索能力,帮助开发者构建强大且可扩展的图像检索系统,无论是管理个人照片库还是开发商业图像搜索应用程序,Milvus都提供了一个强大的基础,帮助开发者发掘图像集合中的潜在价值。

© 2026 AIbase 备案号:闽ICP备08105208号-14