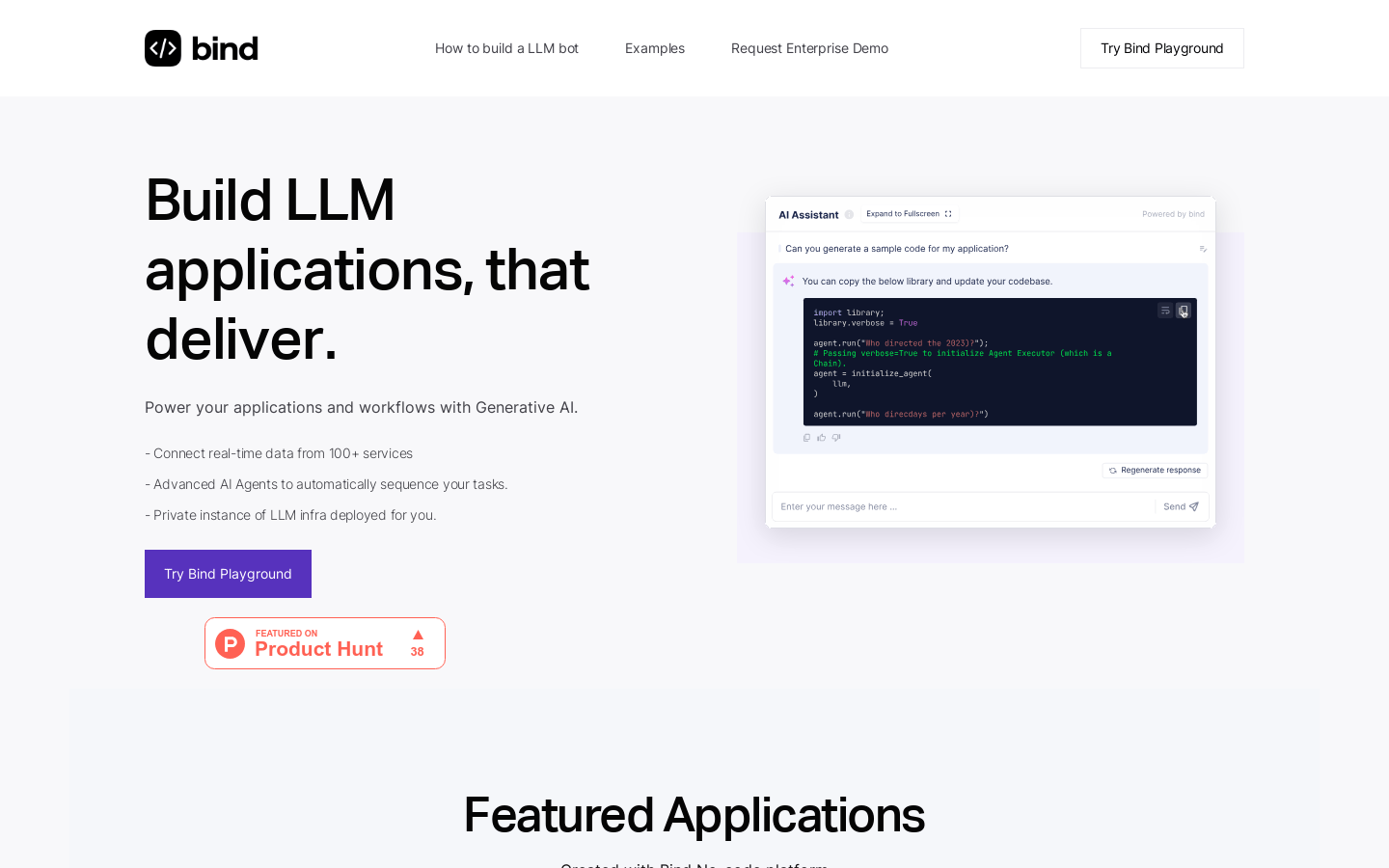
Bind
Bind是一个协作式的Generative AI应用开发平台,可帮助开发者快速构建和部署强大的语言模型应用。提供丰富的工具和功能,包括实时测试和调试LLM响应的提示场景,简易的部署LLM助手等应用到生产环境的平台。
需求人群:
["构建个性化LLM助手","从海量法律文件中提取insights","分析患者健康数据"]
使用场景示例:
构建自定义Yoda AI助手
从新闻、法庭记录中提取JSON实体
根据标准发现B2B线索
产品特色:
实时测试和调试LLM回复
轻松部署LLM应用
连接100+第三方服务
浏览量:61
最新流量情况
月访问量
132.14k
平均访问时长
00:00:24
每次访问页数
1.50
跳出率
44.93%
流量来源
直接访问
31.19%
自然搜索
51.90%
邮件
0.12%
外链引荐
8.43%
社交媒体
7.40%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
德国
3.98%
法国
3.21%
印度尼西亚
3.71%
印度
10.40%
美国
10.78%
Bind帮助开发者快速构建部署强大的LLM应用
Bind是一个协作式的Generative AI应用开发平台,可帮助开发者快速构建和部署强大的语言模型应用。提供丰富的工具和功能,包括实时测试和调试LLM响应的提示场景,简易的部署LLM助手等应用到生产环境的平台。
比较各种大型语言模型(LLM)的定价信息
LLM Pricing是一个聚合并比较各种大型语言模型(LLMs)定价信息的网站,这些模型由官方AI提供商和云服务供应商提供。用户可以在这里找到最适合其项目的语言模型定价。
高效的 Intel GPU 上的 LLM 推理解决方案
这是一种在 Intel GPU 上实现的高效的 LLM 推理解决方案。通过简化 LLM 解码器层、使用分段 KV 缓存策略和自定义的 Scaled-Dot-Product-Attention 内核,该解决方案在 Intel GPU 上相比标准的 HuggingFace 实现可实现高达 7 倍的令牌延迟降低和 27 倍的吞吐量提升。详细功能、优势、定价和定位等信息请参考官方网站。
使用 Generative AI 优化您的网站
ABHero 使用 Generative AI 和数据驱动分析来提高您的网站转化率。它提供自动化建议来改进网站,并生成基于建议的多个变体。然后自动进行 A/B 测试,为访问者个性化定制网站。
扩展LLM上下文窗口
LLM Context Extender是一款旨在扩展大型语言模型(LLMs)上下文窗口的工具。它通过调整RoPE的基础频率和缩放注意力logits的方式,帮助LLMs有效适应更大的上下文窗口。该工具在精细调整性能和稳健性方面验证了其方法的优越性,并展示了在仅有100个样本和6个训练步骤的情况下,将LLaMA-2-7B-Chat的上下文窗口扩展到16,384的非凡效率。此外,还探讨了数据组成和训练课程如何影响特定下游任务的上下文窗口扩展,建议以长对话进行LLMs的精细调整作为良好的起点。
构建LLM应用的开发平台
LLM Spark是一个开发平台,可用于构建基于LLM的应用程序。它提供多个LLM的快速测试、版本控制、可观察性、协作、多个LLM支持等功能。LLM Spark可轻松构建AI聊天机器人、虚拟助手等智能应用程序,并通过与提供商密钥集成,实现卓越性能。它还提供了GPT驱动的模板,加速了各种AI应用程序的创建,同时支持从零开始定制项目。LLM Spark还支持无缝上传数据集,以增强AI应用程序的功能。通过LLM Spark的全面日志和分析,可以比较GPT结果、迭代和部署智能AI应用程序。它还支持多个模型同时测试,保存提示版本和历史记录,轻松协作,以及基于意义而不仅仅是关键字的强大搜索功能。此外,LLM Spark还支持将外部数据集集成到LLM中,并符合GDPR合规要求,确保数据安全和隐私保护。
使用简单、原始的 C/CUDA 进行 LLM 训练
karpathy/llm.c 是一个使用简单的 C/CUDA 实现 LLM 训练的项目。它旨在提供一个干净、简单的参考实现,同时也包含了更优化的版本,可以接近 PyTorch 的性能,但代码和依赖大大减少。目前正在开发直接的 CUDA 实现、使用 SIMD 指令优化 CPU 版本以及支持更多现代架构如 Llama2、Gemma 等。
一个为LLM生成Git提交信息的插件
llm-commit 是一个为 LLM(Large Language Model)设计的插件,用于生成 Git 提交信息。该插件通过分析 Git 的暂存区差异,利用 LLM 的语言生成能力,自动生成简洁且有意义的提交信息。它不仅提高了开发者的提交效率,还确保了提交信息的质量和一致性。该插件适用于任何使用 Git 和 LLM 的开发环境,免费开源,易于安装和使用。
无限令牌,无限制,成本效益高的LLM推理API平台。
Awan LLM是一个提供无限令牌、无限制、成本效益高的LLM(大型语言模型)推理API平台,专为高级用户和开发者设计。它允许用户无限制地发送和接收令牌,直到模型的上下文限制,并且使用LLM模型时没有任何约束或审查。用户只需按月付费,而无需按令牌付费,这大大降低了成本。Awan LLM拥有自己的数据中心和GPU,因此能够提供这种服务。此外,Awan LLM不记录任何提示或生成内容,保护用户隐私。
基于ComfyUI前端开发的LLM工作流节点集合
ComfyUI LLM Party旨在基于ComfyUI前端开发一套完整的LLM工作流节点集合,使用户能够快速便捷地构建自己的LLM工作流,并轻松地将它们集成到现有的图像工作流中。
将GitHub链接转换为适合LLM的格式
GitHub to LLM Converter是一个在线工具,旨在帮助用户将GitHub上的项目、文件或文件夹链接转换成适合大型语言模型(LLM)处理的格式。这一工具对于需要处理大量代码或文档数据的开发者和研究人员来说至关重要,因为它简化了数据准备过程,使得这些数据可以被更高效地用于机器学习或自然语言处理任务。该工具由Skirano开发,提供了一个简洁的用户界面,用户只需输入GitHub链接,即可一键转换,极大地提高了工作效率。
在一个工作区使用主流AI模型创建、比较、优化和发布内容,无供应商锁定。
xeditai - Gen AI Studio是一个生成式AI工作室,允许用户在一个工作区内使用GPT - 4、Claude、Gemini、Llama和Qwen等主流AI模型。其重要性在于打破了供应商锁定的限制,用户可以灵活选择最适合的模型。主要优点包括无需提示工程、内容可编辑且完全归用户所有、支持并行和策略模式、具备云存储等。产品背景是为满足创作者、开发者、研究者等对多模型AI协作的需求。价格方面,提供免费试用。产品定位是帮助用户将想法转化为结构化的成品输出,适用于各种需要内容创作的场景。
设计、部署和优化LLM应用与Klu
Klu是一款全能的LLM应用平台,可以在Klu上快速构建、评估和优化基于LLM技术的应用。它提供了多种最先进的LLM模型选择,让用户可以根据自己的需求进行选择和调整。Klu还支持团队协作、版本管理、数据评估等功能,为AI团队提供了一个全面而便捷的开发平台。
监控和调试你的LLM模型
Athina AI是一个用于监控和调试LLM(大型语言模型)模型的工具。它可以帮助你发现和修复LLM模型在生产环境中的幻觉和错误,并提供详细的分析和改进建议。Athina AI支持多种LLM模型,可以配置定制化的评估来满足不同的使用场景。你可以通过Athina AI来检测错误的输出、分析成本和准确性、调试模型输出、探索对话内容以及比较不同模型的性能表现等。
一个用于LLM预训练的高效网络爬虫工具,专注于高效爬取高质量网页数据。
Crawl4LLM是一个开源的网络爬虫项目,旨在为大型语言模型(LLM)的预训练提供高效的数据爬取解决方案。它通过智能选择和爬取网页数据,帮助研究人员和开发者获取高质量的训练语料。该工具支持多种文档评分方法,能够根据配置灵活调整爬取策略,以满足不同的预训练需求。项目基于Python开发,具有良好的扩展性和易用性,适合在学术研究和工业应用中使用。
LLM应用开发者平台
LangSmith是一个统一的DevOps平台,用于开发、协作、测试、部署和监控LLM应用程序。它支持LLM应用程序开发生命周期的所有阶段,为构建LLM应用提供端到端的解决方案。主要功能包括:链路追踪、提示工具、数据集、自动评估、线上部署等。适用于构建基于LLM的AI助手、 ChatGPT应用的开发者。
用于记录和测试LLM提示的MLops工具
Prompt Joy是一个用于帮助理解和调试LLM(大语言模型)提示的工具。主要功能包括日志记录和分割测试。日志记录可以记录LLM的请求与响应,便于检查输出结果。分割测试可以轻松进行A/B测试,找出效果最佳的提示。它与具体的LLM解耦,可以配合OpenAI、Anthropic等LLM使用。它提供了日志和分割测试的API。采用Node.js+PostgreSQL构建。
企业软件开发的AI LLM平台
Lamini是一款面向企业软件开发的AI LLM平台,利用生成式人工智能和机器学习技术,自动化工作流程,优化软件开发过程,提高生产效率。体验Lamini,感受软件开发的未来。
Generative AI 模型评估工具
Deepmark AI 是一款用于评估大型语言模型(LLM)的基准工具,可在自己的数据上对各种任务特定指标进行评估。它与 GPT-4、Anthropic、GPT-3.5 Turbo、Cohere、AI21 等领先的生成式 AI API 进行预集成。
无需编程背景,通过自然语言快速生成应用。
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
一个关于大型语言模型(LLM)后训练方法的教程、调查和指南资源库。
Awesome-LLM-Post-training 是一个专注于大型语言模型(LLM)后训练方法的资源库。它提供了关于 LLM 后训练的深入研究,包括教程、调查和指南。该资源库基于论文《LLM Post-Training: A Deep Dive into Reasoning Large Language Models》,旨在帮助研究人员和开发者更好地理解和应用 LLM 后训练技术。该资源库免费开放,适合学术研究和工业应用。
LLM Pulse是您在生成式AI世界中的雷达。跟踪您的关键提示,了解AI来源如何引用您的品牌。
LLM Pulse是一款实时监控生成式AI世界中您品牌可见度和影响力的工具。它帮助您了解AI模型引用您的品牌的情况,并提供对竞争对手的比较。
100% Java实现的LLM代理和大型行动模型
Tools4AI是100%用Java实现的大型行动模型(LAM),可作为企业Java应用程序的LLM代理。该项目演示了如何将AI与企业工具或外部工具集成,将自然语言提示转换为可执行行为。这些提示可以被称为"行动提示"或"可执行提示"。通过利用AI能力,它简化了用户与复杂系统的交互,提高了生产力和创新能力。
AI决策指南
《Generative AI: An Executive Guide》是一本关于生成式人工智能技术的权威指南,提供了应用大型语言模型(LLMs)在组织中创造价值的方法和案例研究。本指南适用于C级高管、负责AI战略的高级经理、私营、公共和第三部门组织、创业者、初创企业和成长团队、投资者、分析师和投资专业人士。
开发LLM应用的平台
Vellum是一个用于构建LLM驱动应用的开发平台。它具有提示工程、语义搜索、版本控制、测试和监控等工具,可以帮助开发者将LLM的功能引入生产环境。它与所有主要的LLM提供商兼容,开发者可以选择最适合的模型,也可以随时切换,避免业务过于依赖单一的LLM提供商。
3D可视化的GPT-style LLM
LLM Visualization项目显示了一个GPT-style网络的3D模型。也就是OpenAI的GPT-2、GPT-3(可能还有GPT-4)中使用的网络拓扑。第一个显示工作权重的网络是一个小型网络,对由字母A、B和C组成的小列表进行排序。这是Andrej Karpathy的minGPT实现中的演示示例模型。渲染器还支持可视化任意大小的网络,并且与较小的gpt2大小一起工作,尽管权重没有被下载(它有数百MB)。CPU Simulation项目运行2D原理数字电路,具有完整的编辑器。意图是添加一些演练,展示诸如:如何构建一个简单的RISC-V CPU;构成部分下至门级:指令解码、ALU、加法等;更高级的CPU思想,如各种级别的流水线、缓存等。
一站式LLM模型比较与优化平台
Unify AI是一个为开发者设计的平台,它允许用户通过一个统一的API访问和比较来自不同提供商的大型语言模型(LLMs)。该平台提供了实时性能基准测试,帮助用户根据质量、速度和成本效率来选择和优化最合适的模型。Unify AI还提供了定制路由功能,允许用户根据自己的需求设置成本、延迟和输出速度的约束,并定义自定义质量指标。此外,Unify AI的系统会根据最新的基准数据,每10分钟更新一次,将查询发送到最快提供商,确保持续达到峰值性能。

© 2026 AIbase 备案号:闽ICP备08105208号-14