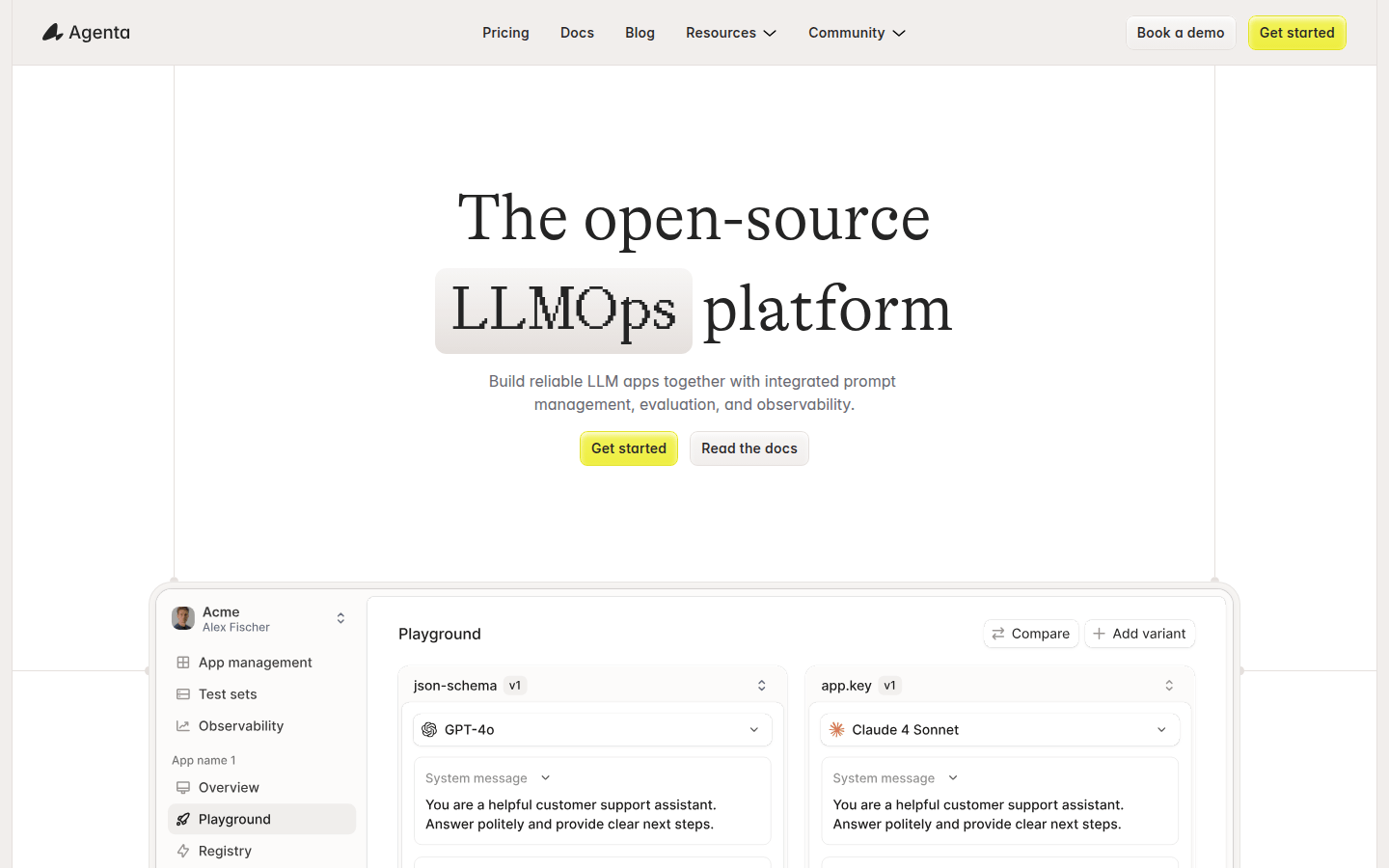
Agenta是一个开源的LLMOps平台,专为LLM开发团队提供基础设施。其重要性在于解决了AI团队在LLM开发中的诸多问题,如工作流程分散、缺乏可观测性和调试困难等。产品的主要优点包括集中管理提示、评估和跟踪信息,支持团队协作,提供统一的实验和评估环境,以及模型无关性等。产品背景是随着大语言模型的广泛应用,开发团队需要更高效的工具来管理和优化开发流程。价格方面文档未提及,定位是成为LLM开发团队的一站式解决方案,帮助团队遵循LLMOps最佳实践。
需求人群:
["LLM开发团队:Agenta为开发团队提供了完整的基础设施,帮助他们从分散的工作流程转变为结构化的流程,遵循LLMOps最佳实践,提高开发效率和产品质量。", "产品经理:产品经理可以使用Agenta的评估功能来验证产品的性能,比较不同的实验结果,从而做出更明智的决策。", "领域专家:领域专家可以通过Agenta的用户界面安全地编辑和实验提示,同时提供反馈,参与到产品的开发和优化过程中。", "开发者:开发者可以利用Agenta的版本管理、调试和评估功能,更好地管理代码和模型,快速定位和解决问题。"]
使用场景示例:
开发智能客服系统:使用Agenta管理提示和评估模型性能,确保客服系统能够准确回答用户问题。
构建智能写作助手:通过Agenta优化提示,提高写作助手的生成质量,并评估不同模型的表现。
打造智能问答机器人:利用Agenta的调试和观测功能,快速定位和解决机器人回答错误的问题,提高机器人的可靠性。
产品特色:
集中管理:将提示、评估和跟踪信息集中在一个平台上,方便团队成员访问和管理,避免信息分散在不同工具中。
团队协作:促进产品经理、开发者和领域专家之间的协作,使他们能够在一个统一的环境中共同工作,提高工作效率。
统一的实验环境:提供统一的游乐场,允许用户并排比较提示和模型,支持完整的版本历史记录,方便跟踪提示的变化。
自动化评估:创建系统的实验流程,自动运行实验、跟踪结果并验证每一个变更,减少人工猜测,提高实验的准确性。
模型无关性:支持使用来自任何提供商的最佳模型,避免供应商锁定,让用户能够灵活选择最适合的模型。
观测和调试:跟踪每个请求,找出确切的失败点,支持对跟踪信息进行注释和反馈,方便调试和改进AI系统。
集成评估器:可以集成任何评估器,包括使用大语言模型作为评判者,内置或自定义代码评估器,支持对整个跟踪过程进行评估。
用户界面支持:为领域专家提供安全的界面,允许他们在不接触代码的情况下编辑和实验提示,同时支持产品经理和专家直接从UI运行评估和比较实验。
使用教程:
步骤1:访问Agenta官方网站(https://agenta.ai/),点击“Get started”开始注册账号。
步骤2:注册完成后,登录Agenta平台,在平台上集中管理提示、评估和跟踪信息。
步骤3:使用统一的游乐场比较提示和模型,进行实验和迭代。
步骤4:创建自动化评估流程,运行实验并跟踪结果。
步骤5:利用观测功能调试AI系统,找出失败点并进行改进。
步骤6:邀请团队成员加入平台,进行协作开发和管理。
浏览量:29
开源平台,提供LLM应用的提示管理、评估和可观测性工具。
Agenta是一个开源的LLMOps平台,专为LLM开发团队提供基础设施。其重要性在于解决了AI团队在LLM开发中的诸多问题,如工作流程分散、缺乏可观测性和调试困难等。产品的主要优点包括集中管理提示、评估和跟踪信息,支持团队协作,提供统一的实验和评估环境,以及模型无关性等。产品背景是随着大语言模型的广泛应用,开发团队需要更高效的工具来管理和优化开发流程。价格方面文档未提及,定位是成为LLM开发团队的一站式解决方案,帮助团队遵循LLMOps最佳实践。
Currai提供LLM可观测性、追踪、评估和提示A/B测试等功能。
Currai是一款针对LLM应用的可观测性平台。其重要性在于帮助团队更好地管理和优化LLM应用。主要优点包括能够追踪每个提示、令牌和工具调用,在生产环境中运行评估和提示A/B测试,让团队有信心发布产品。产品背景是为了解决LLM应用在开发和部署过程中的可观测性难题。它提供7天免费试用,定位是为开发和管理LLM应用的团队提供全面的可观测性解决方案。
Respan是统一可观测性、评估、提示优化和LLM网关的工程平台。
Respan是一个LLM工程平台,它将可观测性、评估、提示优化和统一的LLM网关集成于一体。其重要性在于帮助团队可靠地部署AI应用,确保AI系统按预期运行。主要优点包括提供端到端的执行路径追踪、灵活的评估工作流、有效的优化机制、便捷的部署方式以及实时监控功能。产品背景信息暂不明确,价格方面提供免费试用。其定位是为处理大量API调用、需要确保AI系统可靠性和高效性的团队提供支持。
监控、评估和优化你的LLM应用
LangWatch是一个专为大型语言模型(LLM)设计的监控、评估和优化平台。它通过科学的方法来衡量LLM的质量,自动寻找最佳的提示和模型,并提供一个直观的分析仪表板,帮助AI团队以10倍的速度交付高质量的产品。LangWatch的主要优点包括减少手动优化过程、提高开发效率、确保产品质量和安全性,以及支持企业级的数据控制和合规性。产品背景信息显示,LangWatch利用Stanford的DSPy框架,帮助用户在几分钟内而非几周内找到合适的提示或模型,从而加速产品从概念验证到生产的转变。
以提示语为纽带,连接各类 AI 模型快速构建 AI 应用
AI提示语是一个以提示语为纽带,连接各类 AI 模型快速构建 AI 应用的平台。它让每个人都能轻松使用 AI,提高 10 倍生产力。通过丰富的 AI 大模型和自由的连接组合,用户可以创建自己想要的 AI 应用,并实时预览、编辑和测试应用的工作效果。用户还可以从提示语应用商店免费获取现成的应用,轻松开启自己的 AI 之旅。
构建LLM应用的开发平台
LLM Spark是一个开发平台,可用于构建基于LLM的应用程序。它提供多个LLM的快速测试、版本控制、可观察性、协作、多个LLM支持等功能。LLM Spark可轻松构建AI聊天机器人、虚拟助手等智能应用程序,并通过与提供商密钥集成,实现卓越性能。它还提供了GPT驱动的模板,加速了各种AI应用程序的创建,同时支持从零开始定制项目。LLM Spark还支持无缝上传数据集,以增强AI应用程序的功能。通过LLM Spark的全面日志和分析,可以比较GPT结果、迭代和部署智能AI应用程序。它还支持多个模型同时测试,保存提示版本和历史记录,轻松协作,以及基于意义而不仅仅是关键字的强大搜索功能。此外,LLM Spark还支持将外部数据集集成到LLM中,并符合GDPR合规要求,确保数据安全和隐私保护。
优化LLM应用的提示设计、测试和优化工具
Query Vary提供开发人员设计、测试和优化提示的工具,确保可靠性、降低延迟并优化成本。它具有强大的功能,包括比较不同的LLM模型、跟踪成本、延迟和质量、版本控制提示、将调优的LLM直接嵌入JavaScript等。Query Vary适用于个人开发者、初创公司和大型企业,提供灵活的定价计划。
AI提示工程师,优化大型语言模型应用
Weavel是一个AI提示工程师,它通过追踪、数据集管理、批量测试和评估等功能,帮助用户优化大型语言模型(LLM)的应用。Weavel与Weavel SDK结合使用,能够自动记录并添加LLM生成的数据到您的数据集中,实现无缝集成和针对特定用例的持续改进。此外,Weavel能够自动生成评估代码,并使用LLM作为复杂任务的公正裁判,简化评估流程,确保准确、细致的性能指标。
开发者首选的LLM应用开发实验和协作平台
Inductor Custom Playgrounds是一个针对开发者设计的平台,旨在通过自动化生成可即时分享的LLM应用开发环境,加速开发过程,缩短上市时间,并创建更有效的LLM应用和功能。该平台支持开发者快速迭代和实验,通过协作和数据驱动的方式,构建高质量的LLM应用程序。
简化LLM和RAG模型输出评估,提供对定性指标的洞察
Algomax简化LLM和RAG模型的评估,优化提示开发,并通过直观的仪表板提供对定性指标的独特洞察。我们的评估引擎精确评估LLM,并通过广泛测试确保可靠性。平台提供了全面的定性和定量指标,帮助您更好地理解模型的行为,并提供具体的改进建议。Algomax的用途广泛,适用于各个行业和领域。
LLM提示管理与团队协作
LangTale是一个旨在简化LLM提示管理的平台,提供协作、版本控制、测试和性能监控等功能。LangTale使团队成员能够轻松管理和优化LLM提示,提高工作效率。定价详情请访问官方网站。
开源评估基础设施,为 LLM 提供信心
Confident AI 是一个开源的评估基础设施,为 LLM(Language Model)提供信心。用户可以通过编写和执行测试用例来评估自己的 LLM 应用,并使用丰富的开源指标来衡量其性能。通过定义预期输出并与实际输出进行比较,用户可以确定 LLM 的表现是否符合预期,并找出改进的方向。Confident AI 还提供了高级的差异跟踪功能,帮助用户优化 LLM 配置。此外,用户还可以利用全面的分析功能,识别重点关注的用例,实现 LLM 的有信心地投产。Confident AI 还提供了强大的功能,帮助用户自信地将 LLM 投入生产,包括 A/B 测试、评估、输出分类、报告仪表盘、数据集生成和详细监控。
AI提示管理工具
Orquesta是一款AI提示管理工具,为工程师提供了管理提示的工具,包括集中存储、实验、个性化定制和收集反馈等功能。它能够帮助您丰富产品的功能,并实现AI和LLM的能力,同时集中管理和优化提示的生命周期。
设计、部署和优化LLM应用与Klu
Klu是一款全能的LLM应用平台,可以在Klu上快速构建、评估和优化基于LLM技术的应用。它提供了多种最先进的LLM模型选择,让用户可以根据自己的需求进行选择和调整。Klu还支持团队协作、版本管理、数据评估等功能,为AI团队提供了一个全面而便捷的开发平台。
AI提示生成、优化与管理工具,轻松生成优化提示,管理复用提示。
Promtist是一款专注于AI提示词的生成、优化和管理的工具。在当今AI广泛应用的时代,优质的提示词对于获取高质量的AI生成结果至关重要,但编写良好的提示词并非易事,需要丰富的经验和知识,且处理复杂任务时专业提示词可能很长,编写耗时,还需要多种技能。Promtist应运而生,它提供各种算法和工具,帮助用户轻松生成和优化提示词。该产品提供免费试用,无需注册和信用卡信息,其定位是为需要使用AI进行内容生成的用户提供便捷、高效的提示词解决方案。
开发LLM应用的平台
Vellum是一个用于构建LLM驱动应用的开发平台。它具有提示工程、语义搜索、版本控制、测试和监控等工具,可以帮助开发者将LLM的功能引入生产环境。它与所有主要的LLM提供商兼容,开发者可以选择最适合的模型,也可以随时切换,避免业务过于依赖单一的LLM提供商。
快速直观地进行LLM实验
Terracotta是一个易于使用的平台,通过Terracotta,可以快速高效地进行LLM开发工作流。在Terracotta上管理所有精调模型,通过定性和定量评估快速迭代改进模型。同时支持与OpenAI和Cohere等多个提供商的连接。Terracotta通过上传数据来开展LLM模型的精调工作,提供安全存储数据的功能。用户可以对数据进行分类和文本生成的精调。Terracotta提供了定性和定量评估功能,可以同时输入多个模型的提示并比较模型输出,也可以使用我们的工具在包括准确度、BLEU和混淆矩阵等多种评估指标下评估模型。Terracotta由两位斯坦福大学人工智能研究生Beri Kohen和Lucas Pauker共同创建。欢迎您订阅我们的邮件列表,以便及时了解我们的最新进展!
解锁你的创造力,管理AI提示
PromptLocker是一款专注于管理和组织AI提示的应用。它可以帮助用户存储、整理和搜索各种AI提示,包括创意写作、编码等领域。PromptLocker提供了存储提示、整理提示到文件夹和子文件夹、快速搜索提示、一键复制提示等多种功能。无论你是在Twitter、Midjourney、YouTube还是其他平台上发现了好的AI提示,PromptLocker都能让你方便地管理和查找它们。通过PromptLocker,你的提示将始终在指尖,随时点燃你的下一个创作。
高效的 Intel GPU 上的 LLM 推理解决方案
这是一种在 Intel GPU 上实现的高效的 LLM 推理解决方案。通过简化 LLM 解码器层、使用分段 KV 缓存策略和自定义的 Scaled-Dot-Product-Attention 内核,该解决方案在 Intel GPU 上相比标准的 HuggingFace 实现可实现高达 7 倍的令牌延迟降低和 27 倍的吞吐量提升。详细功能、优势、定价和定位等信息请参考官方网站。
比较各种大型语言模型(LLM)的定价信息
LLM Pricing是一个聚合并比较各种大型语言模型(LLMs)定价信息的网站,这些模型由官方AI提供商和云服务供应商提供。用户可以在这里找到最适合其项目的语言模型定价。
构建应用程序的LLM通过组合性
LangChain是一个帮助开发人员构建应用程序的库,通过组合性将大型语言模型(LLMs)与其他计算或知识源结合起来。它提供了各种应用场景的端到端示例,包括问题回答、聊天机器人和代理等。LangChain还提供了对LLMs的通用接口、链式调用、数据增强生成、记忆和评估等功能。定价信息请访问官方网站。
LLM的评估和单元测试框架
DeepEval提供了不同方面的度量来评估LLM对问题的回答,以确保答案是相关的、一致的、无偏见的、非有毒的。这些可以很好地与CI/CD管道集成在一起,允许机器学习工程师快速评估并检查他们改进LLM应用程序时,LLM应用程序的性能是否良好。DeepEval提供了一种Python友好的离线评估方法,确保您的管道准备好投入生产。它就像是“针对您的管道的Pytest”,使生产和评估管道的过程与通过所有测试一样简单直接。
简化 LLM 提示管理和促进团队协作
Langtail 是一个旨在简化大型语言模型(LLM)提示管理的平台。通过Langtail,您可以增强团队协作、提高效率,并更深入地了解您的AI工作原理。尝试Langtail,以更具协作和洞察力的方式构建LLM应用。
以提示语为纽带,连接各类 AI 模型快速构建 AI 应用
AI 提示语是一款以提示语为纽带,连接各类 AI 模型的产品。它提供了丰富的 AI 大模型自由连接组合,用户可以通过聊天和绘画等方式快速构建 AI 应用。AI 提示语让每个人都能轻松使用 AI,提高 10 倍生产力。它无需编写代码,用户可以实时预览和编辑应用,免费获取提示语应用,应用数据完全互通,支持电脑端、手机端和微信小程序使用。

© 2026 AIbase 备案号:闽ICP备08105208号-14