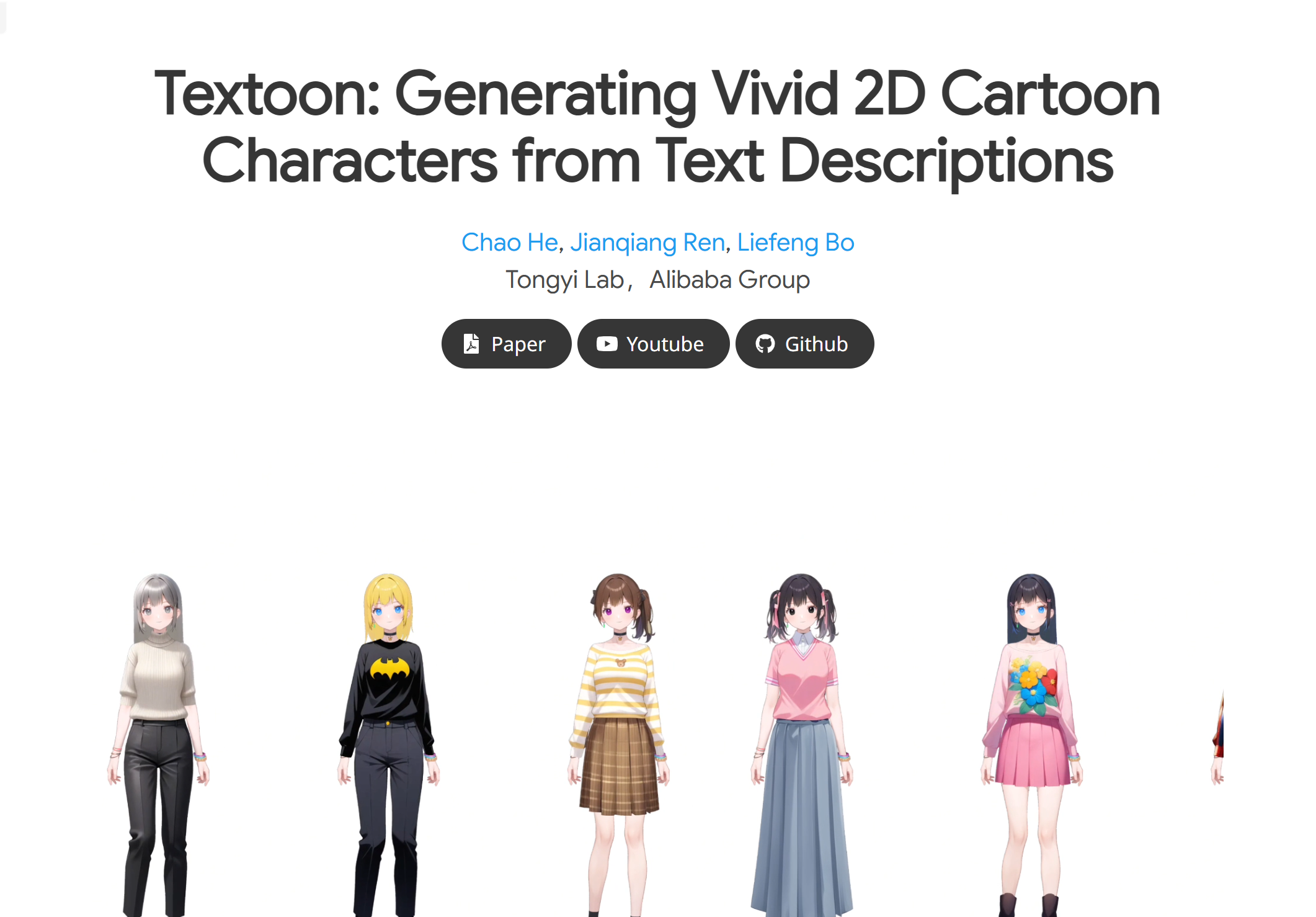
Textoon 是由阿里巴巴集团通义实验室推出的一种创新方法,能够根据文本描述快速生成多样化的 2D 卡通角色。该技术利用先进的语言和视觉模型,将文本意图转化为 2D 角色外观,生成的 Live2D 模型具有高效性和兼容性。它不仅满足了数字角色创作中对 2D 卡通风格的需求,还填补了当前 3D 角色研究中对 2D 互动角色关注不足的空白。其主要优点包括高效的渲染性能、灵活的文本解析能力和可编辑性,适用于快速生成高质量的 2D 卡通角色。
需求人群:
"该产品适合需要快速生成 2D 卡通角色的动画师、游戏开发者、数字内容创作者以及相关领域的研究人员,能够帮助他们高效地将创意转化为具体角色形象,节省时间和精力。"
使用场景示例:
根据文本描述生成一个长发女孩,拥有珊瑚红色头发、深蓝色眼睛,穿着方领短袖上衣、深蓝色短裙和咖啡色中筒靴。
生成一个拥有长双马尾和蓝宝石色眼睛的女孩,搭配深蓝色高领羊绒毛衣、白色蕾丝裙和黑色过膝靴。
创建一个单马尾女孩,紫色眼睛,穿着 V 领粉色短袖上衣、红色短裙和马丁靴。
产品特色:
准确文本解析:能够从复杂描述中提取详细信息,如发型、发色、眼睛、服装等。
可控外观生成:通过组件合成生成角色模板,精确控制角色形状和纹理。
可编辑性:用户可修改生成结果中的特定细节。
动画支持:集成 ARKit 能力,提升 Live2D 模型的动画表现力。
多语言支持:支持中英文提示词,满足不同用户需求。
使用教程:
访问产品页面,了解基本信息。
根据需要生成的角色特征,编写详细的文本描述。
输入文本描述后,系统将基于文本解析生成 2D 卡通角色。
查看生成的角色模型,如有需要可对细节进行编辑调整。
导出生成的 Live2D 模型,用于后续的动画制作或其他用途。
浏览量:254
基于Unity的Live2D虚拟人实时聊天系统
AI女友是一款基于Unity开发的Live2D虚拟人实时聊天系统,它利用Live2D技术提供动态的虚拟人形象,结合Unity的实时渲染功能,实现与用户的动态交互和聊天。主要功能包括Live2D虚拟人形象集成、实时聊天、图像处理和人脸检测,支持高清分辨率显示,并且可自定义和扩展。
Textoon 是一款基于文本描述生成生动 2D 卡通角色的创新工具。
Textoon 是由阿里巴巴集团通义实验室推出的一种创新方法,能够根据文本描述快速生成多样化的 2D 卡通角色。该技术利用先进的语言和视觉模型,将文本意图转化为 2D 角色外观,生成的 Live2D 模型具有高效性和兼容性。它不仅满足了数字角色创作中对 2D 卡通风格的需求,还填补了当前 3D 角色研究中对 2D 互动角色关注不足的空白。其主要优点包括高效的渲染性能、灵活的文本解析能力和可编辑性,适用于快速生成高质量的 2D 卡通角色。
易用的2D/3D家居设计工具
Planner 5D是一款易用的2D/3D家居设计工具,拥有5000多个物品,可帮助用户设计梦想家园。用户可以使用2D模式创建平面图和设计布局,也可以切换到3D模式从任何角度探索和编辑设计。用户可以编辑颜色、图案和材料,创建独特的家具、墙壁、地板等,甚至可以调整物品大小以找到完美的匹配。Planner 5D还提供渲染功能,可以将设计捕捉为逼真的图像,添加阴影、照明和丰富的颜色,使作品看起来像一张照片。Planner 5D适用于业余设计师和专业设计师,用户可以加入社区,上传和定制项目,获取其他用户创建的设计灵感。
SAM 3D:AI驱动,秒速将2D图像转化为专业级3D模型
SAM 3D是一款由人工智能驱动的3D重建平台,它基于先进的SAM(Segment Anything Model)技术,实现了将单张2D照片转化为精确、全纹理3D模型的突破。该平台打破了传统3D建模的壁垒,无需昂贵设备和专业技术知识,为全球开发者、设计师、研究人员和内容创作者提供了企业级的3D重建能力。其重要性在于降低了3D建模的门槛,使更多人能够轻松获得高质量的3D模型。价格方面,提供免费使用,无需信用卡信息。产品定位是为各行业提供便捷、高效的3D重建解决方案。
2D游戏动画生成模型
godmodeanimation是一个开源的2D游戏动画生成模型,它通过训练文本到视频和图像到视频的模型来生成2D游戏动画。开发者使用了公共游戏动画数据和3D mixamo模型渲染动画来训练动画生成模型,并开源了模型、训练数据、训练代码和数据生成代码。
Formy 3D可将照片、文本快速转化为专业3D模型
Formy 3D是一款先进的AI 3D生成器,于2024年创立。它利用拥有100亿参数的扩散模型技术,能理解自然语言和视觉参考,将文本描述和图像转化为高质量3D模型。与传统3D建模软件不同,它无需专业经验,即可在几分钟内创建出专业的3D资产。该平台提供免费的基础计划,也有每月24.99美元的Plus计划,适用于需要快速创建3D模型的个人和企业。
DepthFlow AI是下一代2D转3D渲染平台,可将2D图像转化为惊艳3D动态效果。
DepthFlow AI是一个由人工智能驱动的平台,其核心功能是把2D图像转换为具有真实感的3D深度和动态渲染效果。该平台的重要性在于为创作者提供了便捷、高效的2D转3D解决方案,大大降低了3D内容创作的门槛。主要优点包括闪电般的处理速度、高保真的3D效果、易于上传操作等。其价格具有灵活性,起始计划仅需3.99美元,用户可随时使用。平台定位是面向广大创作者,无论是专业设计师还是初学者,都能借助该平台轻松实现2D到3D的转换。
打造有温度的数字人,注入灵魂。
awesome-digital-human-live2d 是一个开源项目,旨在创建具有交互性的数字人物模型。它支持Docker快速部署,集成了Dify服务,支持ASR、LLM、TTS、Agent等模块化扩展,并且可以控制Live2d人物模型。该项目通过模块化设计,简化了数字人的创建过程,使得开发者能够更专注于个性化和创新。
快速将2D图像转换为3D,开启全新的视觉体验和无限可能性。
Stylar AI的2D to 3D Image Converter是一个强大的图像转换工具,它利用先进的Image-to-Image技术,将平面2D图像转换为3D图像。这款工具提供高质量的图像转换和多种风格选项,能够满足用户对图像进行3D化的需求。产品的主要功能包括上传图片、选择3D效果、下载3D创作等。它还提供了多种3D风格,如3D卡通效果、3D艺术作品等,以及将草图转换为3D设计的功能。
基于2D扩散的文本到3D生成
DreamFusion是一款基于预训练的2D文本到图像扩散模型,用于生成高保真度的、可调光的3D对象。它通过使用梯度下降优化随机初始化的3D模型(Neural Radiance Field)来生成3D对象,并且可以从任意角度观察、任意照明重新照亮或与任何3D环境合成。DreamFusion不需要3D训练数据,也不需要对图像扩散模型进行修改,展示了预训练图像扩散模型作为先验的有效性。
轻量级、先进的2B参数文本生成模型。
Gemma 2 2B是谷歌开发的轻量级、先进的文本生成模型,属于Gemma模型家族。该模型基于与Gemini模型相同的研究和技术构建,是一个文本到文本的解码器仅大型语言模型,提供英文版本。Gemma 2 2B模型适用于问答、摘要和推理等多种文本生成任务,其较小的模型尺寸使其能够部署在资源受限的环境中,如笔记本电脑或桌面电脑,促进了对最先进AI模型的访问,并推动了创新。
稳定扩散:距离快速多样的文本生成3D仅一步之遥
HexaGen3D是一种用于从文本提示生成高质量3D资产的创新方法。它利用大型预训练的2D扩散模型,通过微调预训练的文本到图像模型来联合预测6个正交投影和相应的潜在三面体,然后解码这些潜在值以生成纹理网格。HexaGen3D不需要每个样本的优化,可在7秒内从文本提示中推断出高质量且多样化的对象,相较于现有方法,提供了更好的质量与延迟权衡。此外,HexaGen3D对于新对象或组合具有很强的泛化能力。
用AI瞬间生成2D、2.5D和3D房屋布局,简单易用的房屋设计工具
HousePlan是一款由AI驱动的工具,可用于快速创建2D、2.5D和3D房屋布局。其主要优点在于操作简单,无需设计经验,用户能在数秒内生成完整的房屋平面图,节省大量时间和精力。该产品适用于各种房屋设计场景,无论是初步构思还是实际项目。其价格方面,每次生成房屋平面图需花费6个信用点。它定位为满足不同用户需求的房屋设计解决方案,为用户提供灵活、高效的设计体验。
将2D图片转换为3D模型的AI系统
Any Image to 3D是一款创新的AI系统,可以将复杂的2D图片转换为3D模型。它消除了生成3D内容的技术难题,使得任何人都可以轻松地生成3D模型。它适用于游戏、机器人、混合现实、视觉特效和电子商务等领域。通过简单的可视化,用户可以将想法转化为详细的3D模型。
快速将 2D 图像转换为专业 3D 模型的 AI 工具。
Modelfy 3D 是一个先进的 AI 图像转 3D 模型生成器,允许用户在几秒钟内将 2D 图像转换为 3D 模型,支持高达 30 万多边形的精度,非常适合 3D 打印、游戏开发和专业项目。该平台采用自研的 AI 算法和企业级基础设施,提供高效、可靠的 3D 模型生成服务,用户可以按需选择不同的质量级别进行下载,满足多种需求。价格体系灵活,支持免费试用和付费订阅,适合从个人创作者到企业用户的广泛使用。
Pixal3D是像素对齐AI 3D生成器,支持图转3D和文本生成动画
Pixal3D是一款AI 3D生成器,通过像素对齐技术和PBR纹理,可将图像转换为GLB模型。其重要性在于为3D内容创作提供了高效、精确的解决方案。主要优点包括像素对齐的高精度3D生成、支持多种模型和输出格式、提供浏览器免费工具等。该产品面向3D设计、游戏开发、广告制作等领域,价格根据不同计划而定,需要登录账号使用,登录后可更新信用点数,有180 - 390信用点的相关设定。
强大的无代码2D引擎,为富有故事性的游戏而设计
故事机器是一个通用的2D引擎,旨在为富有故事性的游戏创作提供简单的无代码解决方案。它具有直观的可视化界面,让故事讲述者拥有创作的权力。主要功能包括通过拖放操作构建游戏逻辑、快速创建场景布局的动画过渡、简单易用的工具集等。故事机器还融入了人工智能技术,可以直接在引擎中生成AI艺术。它适用于开发2D冒险游戏,无需编程。
用AI制作2D游戏,从概念艺术到角色、动画,均可在浏览器构建。
Makko AI是一款基于人工智能技术的2D游戏制作平台。其重要性在于,它降低了游戏制作的门槛,让没有绘画和编程基础的人也能轻松制作游戏。主要优点包括操作简单,只需用英语描述需求,AI就能完成大部分工作;节省时间和精力,能快速生成游戏原型;风格统一,所有元素都能保持一致的艺术风格。产品背景是为满足广大游戏创作者的需求而开发。价格方面,提供免费使用,每月有150艺术预算和70次AI编码请求,也有订阅计划可供选择。定位是面向各类有创意的人群,帮助他们实现游戏制作梦想。
高保真文本到4D生成
4D-fy是一种文本到4D生成方法,通过混合分数蒸馏采样技术,结合了多种预训练扩散模型的监督信号,实现了高保真的文本到4D场景生成。其方法通过神经表示参数化4D辐射场,使用静态和动态多尺度哈希表特征,并利用体积渲染从表示中渲染图像和视频。通过混合分数蒸馏采样,首先使用3D感知文本到图像模型(3D-T2I)的梯度来优化表示,然后结合文本到图像模型(T2I)的梯度来改善外观,最后结合文本到视频模型(T2V)的梯度来增加场景的运动。4D-fy可以生成具有引人入胜外观、3D结构和运动的4D场景。
微软Trellis 2 AI,快速将图像转为含PBR纹理的高质量3D模型
Trellis 2 AI是微软研发的先进3D生成模型,拥有40亿参数。其核心是创新的O - Voxel表示,能处理复杂拓扑结构。该模型可在数秒内将2D图像转换为带有PBR纹理的3D资产,无需额外优化和手动操作,实现端到端工作流程。它在速度和质量上达到了前所未有的平衡,能生成高达1536³分辨率的逼真资产。在trellis3d.net平台上可直接使用,暂未提及价格信息。定位为专业的3D生成解决方案,适合有3D模型创建需求的用户。
2D视频转3D模型
Neuralangelo是NVIDIA研究推出的一款利用神经网络进行3D重建的人工智能模型,可以将2D视频片段转换为详细的3D结构,生成逼真的虚拟建筑、雕塑等物体。它能够准确地提取复杂材料的纹理,包括屋顶瓦片、玻璃窗格和光滑的大理石。创意专业人员可以将这些3D对象导入设计应用程序,进一步进行编辑,用于艺术、视频游戏开发、机器人技术和工业数字双胞胎等领域。Neuralangelo的3D重建能力将对创作者产生巨大的帮助,帮助他们在数字世界中重新创建真实世界。该工具最终将使开发人员能够将详细的对象(无论是小雕塑还是巨大的建筑物)导入到虚拟环境中,用于视频游戏或工业数字双胞胎等应用。
微软研发的AI图像转3D模型工具,1 - 3分钟出高质量3D模型,支持多软件。
Trellis 2是由微软研究院开发的一款AI图像到3D模型生成器。其重要性在于为用户提供了高效、便捷的2D图像转3D模型的解决方案。主要优点包括:无需GPU,完全基于云端运行,降低了硬件门槛;转换速度快,通常1 - 3分钟即可完成;支持多种输出格式,如GLB、3D Gaussians和网格,具有很强的通用性。产品背景是依托微软的技术研发。价格方面,提供免费试用额度,也有灵活的信用套餐和无限转换的高级计划。定位是服务于游戏开发、产品设计和创意项目等领域,为用户提供专业的图像到3D转换服务。
Y2K风格的文本/字体生成模型
FLUX Y2K TYPEFACE是一个基于LoRA技术的文本/字体生成模型,能够以高精度生成Y2K风格的文本、字体、标志和徽章。该模型由Black Forest Labs, Inc.授权,代表了文本和字体生成技术的新进展,具有高度的创造性和实用性。
超越2D,用AI从文本生成视频
Genmokey是一个能够使用AI从文本生成视频的创意工具。它能够将您输入的文字转化为独特的视频作品,超越传统的2D效果。无论您是想创建个人视频、营销广告还是其他创意项目,Genmokey都能够帮助您实现想象力的极限。Genmokey是一个全面的视频生成工具,提供丰富的功能和定制选项。定价方案灵活,适合个人和企业使用。无论您是设计师、营销人员、创意从业者还是视频爱好者,Genmokey都将成为您的得力助手。

© 2026 AIbase 备案号:闽ICP备08105208号-14