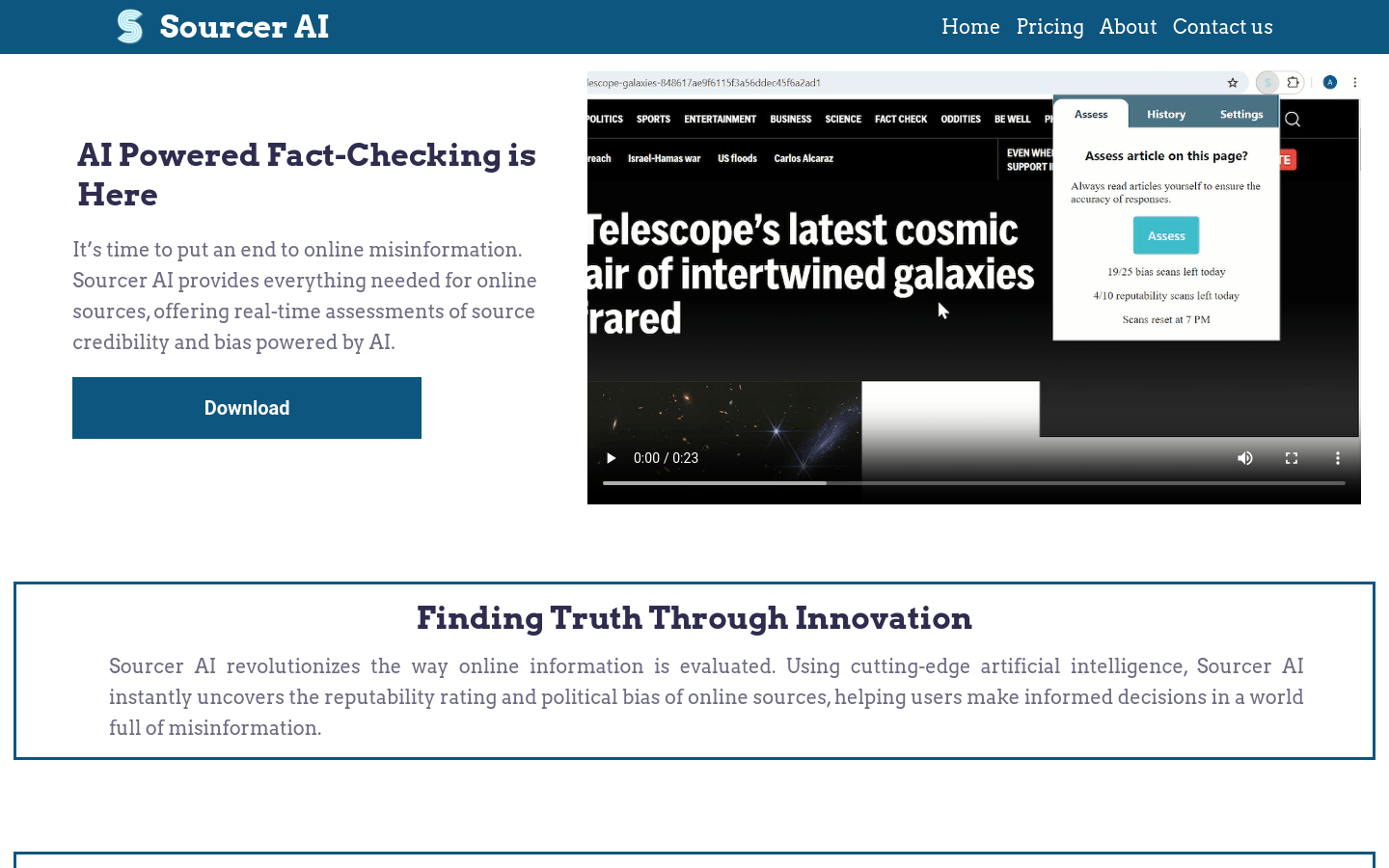
Sourcer AI 是一款利用人工智能技术进行在线信息评估的工具。它通过分析文章的语言,即时揭示在线来源的可信度和政治偏见,帮助用户在充满虚假信息的世界中做出明智的决策。该工具的主要优点包括实时评估、透明度高、易于使用等。
需求人群:
"Sourcer AI 适合所有需要评估在线信息可信度的用户,包括但不限于新闻工作者、研究人员、教育工作者和普通网民。它可以帮助他们识别和避免虚假信息,提高信息获取的质量和可靠性。"
使用场景示例:
新闻记者使用 Sourcer AI 评估新闻来源的可信度
研究人员利用 Sourcer AI 分析学术文章的偏见
教育工作者通过 Sourcer AI 教育学生识别虚假信息
产品特色:
实时评估在线来源的可信度
分析文章语言以识别偏见
提供透明度和可见性
支持多种社交媒体平台
帮助用户做出更明智的决策
通过AI技术提升信息评估的准确性
易于安装和使用
使用教程:
1) 点击扩展图标
2) 点击 Sourcer AI
3) 点击评估
4) 立即获得透明度
浏览量:52
AI驱动的事实核查工具
Sourcer AI 是一款利用人工智能技术进行在线信息评估的工具。它通过分析文章的语言,即时揭示在线来源的可信度和政治偏见,帮助用户在充满虚假信息的世界中做出明智的决策。该工具的主要优点包括实时评估、透明度高、易于使用等。
使用AI进行写作事实核查
Parafact是一个利用人工智能技术进行文本事实核查的平台。它能够实时识别人类或AI撰写文本中的不准确之处,并提供可靠的来源。产品背景信息表明,Parafact旨在提高信息的准确性和可靠性,特别是在信息泛滥的互联网时代。产品价格分为三个档次,满足不同用户的需求,从个人用户到大型组织。
实时事实核查工具,提升信息准确性。
HighlightFactCheck是一个先进的事实核查工具,它通过算法分析和多源验证,为用户提供准确、全面的事实核查服务。该工具特别适合记者、研究人员、内容创作者和任何致力于信息真实性的人。它通过Chrome扩展、网站和API支持90多种语言,帮助用户快速提升内容的准确性和可信度。产品背景信息显示,该工具旨在应对信息过载时代对可靠事实核查的需求,通过自动化和算法化提高事实核查的效率和准确性。价格方面,提供$19.99/月的FactCheckPro计划,包括高级算法分析、多源验证、详细解释、持续学习、重写建议和安全认证等功能。
最强大的AI事实核查工具
Fact Check Anything是一款可靠的浏览器插件,通过AI技术快速核实信息,帮助用户对抗虚假内容传播。功能包括验证信息、过滤误导性帖子、深度解析、提供可靠来源等。适用于学生、专业人士、好奇心强的人等各行各业。
不要盲目相信AI生成的内容,请先用Katteb进行事实核查
Katteb是最佳的AI写作工具,可进行事实核查并生成可靠的AI内容。加入超过200,000位依赖Katteb的作者!Katteb提供多达30种类型、超过110种语言的内容生成,通过引用可信赖来源的内文引文,确保内容的准确性。
Pavis实时分析通话,检测操纵、事实核查并当场提出独特问题
Pavis是一款利用前沿技术打造的实时通话分析工具。主要功能包括实时分析通话内容、检测对方话语中的操纵意图、进行事实核查以及当场生成独特问题。其重要性在于能帮助用户在对话中保持清醒,避免被误导,做出更明智的决策。产品的主要优点是实时性强,能在对话过程中及时提供分析和建议;功能全面,涵盖检测、核查和提问等多个方面。产品背景信息暂未提及,价格也未在页面中体现,从描述来看,定位为帮助用户提升对话质量和决策能力的辅助工具。
用于评估大型语言模型事实性的最新基准
FACTS Grounding是Google DeepMind推出的一个全面基准测试,旨在评估大型语言模型(LLMs)生成的回应是否不仅在给定输入方面事实准确,而且足够详细,能够为用户提供满意的答案。这一基准测试对于提高LLMs在现实世界中应用的信任度和准确性至关重要,有助于推动整个行业在事实性和基础性方面的进步。
Gistilo可在1分钟内将YouTube链接转化为清晰摘要,还能选做事实核查。
Gistilo是一款专注于YouTube视频内容处理的网站,其核心功能是将YouTube视频转化为清晰的摘要。该产品具有速度快、细节把握好的特点,能够在一分钟内为用户提供7个关键见解或详细摘要,且支持事实核查并附带来源。其重要性在于帮助用户节省大量观看视频的时间,尤其是对于那些时间紧张但又想获取知识信息的人来说,是一个高效的工具。产品定位为满足用户快速获取视频核心内容的需求,提供了分钟-based的付费计划,无需管理令牌,避免了用户的猜测成本。此外,它还支持自动翻译多种语言,能处理长达4小时的长视频,甚至可以让用户在几分钟内了解长播客的内容。
辅助人类校验大型语言模型(LLM)输出中的事实错误并提供证据的工具
GenAudit 是一个旨在帮助校验大型语言模型(LLM)在文档支持任务中的响应的工具。它可以建议对LLM响应进行编辑,通过修正或移除未被参考文档支持的声明,并且为看似有支持的事实提供参考证据。GenAudit 通过训练模型执行这些任务,并设计了一个交互式界面向用户展示建议的编辑和证据。
连接大型语言模型与谷歌数据共享平台,减少AI幻觉现象。
DataGemma是世界上首个开放模型,旨在通过谷歌数据共享平台的大量真实世界统计数据,帮助解决AI幻觉问题。这些模型通过两种不同的方法增强了语言模型的事实性和推理能力,从而减少幻觉现象,提升AI的准确性和可靠性。DataGemma模型的推出,是AI技术在提升数据准确性和减少错误信息传播方面的重要进步,对于研究人员、决策者以及普通用户来说,都具有重要的意义。
Nutgrafe用AI将新闻文章总结成短段落,提供事实无偏见内容。
Nutgrafe是一款专注于新闻资讯处理的产品,其核心功能是利用人工智能技术对全球顶级新闻网站、博客和出版物的文章进行处理,提取其中的事实信息,并将每篇文章总结成不超过400字的简短段落。该产品的重要性在于为用户节省大量阅读时间,让用户能够快速了解新闻事件的核心内容。其主要优点包括提供无偏见的事实内容,不包含编辑意见和煽动性言论;采用按时间顺序排列的信息流,用户可以自主控制阅读顺序;不设置成瘾性机制,让用户能够高效获取信息后离开。产品背景是为了满足人们在快节奏生活中对快速、准确获取新闻资讯的需求。价格方面,提供14天免费试用,试用结束后每年收费59美元。产品定位是为追求高效、客观新闻资讯的用户提供服务。
AI辅助的事实检查插件
Filtir是一个事实检查的ChatGPT插件,通过评估文本中的声明是否有公开可查证的证据来提高内容的事实性。它可以帮助作者识别并更正AI生成内容中的虚假声明。Filtir通过检查声明是否有支持的证据来评估其可靠性,并提供相关的源链接和事实检查结果。
基于大规模数据的高质量信息抽取模型
雅意信息抽取大模型(YAYI-UIE)由中科闻歌算法团队研发,是一款在百万级人工构造的高质量信息抽取数据上进行指令微调的模型。它能够统一训练信息抽取任务,包括命名实体识别(NER)、关系抽取(RE)和事件抽取(EE),覆盖了通用、安全、金融、生物、医疗、商业等多个场景的结构化抽取。该模型的开源旨在促进中文预训练大模型开源社区的发展,并通过开源共建雅意大模型生态。
创建、共享和管理金融事实表
FactBox AI是一个可轻松创建、共享和管理综合事实表的平台。它提供丰富的模板库和直观的拖放界面,让您可以自定义布局并展示有效的信息。您可以轻松上传CSV数据,利用自定义和高级小部件增强事实表。通过生成公共URL,您可以方便地分享事实表。同时,您可以一键导出事实表为PDF格式,便于离线访问和打印。
Generative AI 模型评估工具
Deepmark AI 是一款用于评估大型语言模型(LLM)的基准工具,可在自己的数据上对各种任务特定指标进行评估。它与 GPT-4、Anthropic、GPT-3.5 Turbo、Cohere、AI21 等领先的生成式 AI API 进行预集成。
新型AI驱动的编码评估
Ropes AI是一种新型的编码评估工具,利用人工智能技术进行评估。它能够生成总结每个编码评估的详细信息,并给出评分卡。同时,它还提供了定制的编程挑战,让候选人有机会展示自己的技能。Ropes AI还可以根据您的业务需求定制编码挑战,并提供了防作弊功能和候选人友好的体验。
使用我们的AI评估工具,上传照片即可获得免费评估。
SnapAppraise是一个提供珠宝首饰评估的在线平台。通过上传照片,我们的AI评估工具可以快速分析珠宝首饰的价值并生成详细的评估报告。SnapAppraise提供免费的初步评估,方便用户在安排面对面评估之前获得快速的预估价值。
专家评估界面和数据评估脚本
OpenScholar_ExpertEval是一个用于专家评估和数据评估的界面和脚本集合,旨在支持OpenScholar项目。该项目通过检索增强型语言模型合成科学文献,对模型生成的文本进行细致的人工评估。产品背景基于AllenAI的研究项目,具有重要的学术和技术价值,能够帮助研究人员和开发者更好地理解和改进语言模型。
通过 Minecraft 评估 AI 的表现。
MC-Bench 是一个在线平台,旨在通过 Minecraft 游戏环境评估和比较不同 AI 生成的建筑。它允许用户投票并参与到 AI 评估中,促进 AI 技术的发展。该平台的主要优势在于其趣味性和互动性,为用户提供了一个简单而有趣的方式来了解 AI 的能力。
使用可靠数据源和全面事实核实的生成性人工智能,为您的机构或企业创建准确和可靠的内容。
LongShot AI 是一款旨在满足您内容需求的高效可靠的生成性人工智能工具。利用可靠的数据源和全面的事实核实,我们的人工智能驱动平台为您提供最准确可靠的信息,确保您的内容毫无疑虑。不再担心数据的可靠性和过时的信息,LongShot AI 不断更新知识库,确保您的内容始终相关和最新。我们的先进算法对事实进行仔细的交叉核实,消除了任何错误的可能性。LongShot AI 简化了事实核实的过程,为您节省宝贵的时间,让您专注于业务的其他方面。LongShot AI 提供灵活、定制的解决方案,以满足您机构或企业的独特需求。
AI评估症状,帮助理解健康问题
智能症状检测器是一款AI驱动的医疗工具,通过用户描述症状来评估健康问题。它可以提供非经过审核的AI生成回答,但不意味着提供医疗建议。用户可以描述症状的细节,包括症状的起始时间、严重程度、变化情况、影响因素等。此工具仅供参考,不应替代专业医疗建议。
衡量语言模型回答事实性问题能力的基准测试
SimpleQA是OpenAI发布的一个事实性基准测试,旨在衡量语言模型回答简短、寻求事实的问题的能力。它通过提供高正确性、多样性、挑战性和良好的研究者体验的数据集,帮助评估和提升语言模型的准确性和可靠性。这个基准测试对于训练能够产生事实正确响应的模型是一个重要的进步,有助于提高模型的可信度,并拓宽其应用范围。
省时高效的AI绩效评估工具
GeniusReview是一款360° AI绩效评估工具,通过使用GeniusReview,您可以省去大量时间来获取定制化的绩效评估问题的答案。它提供针对不同角色的定制化答案,并包括问题列表、技能排名、反馈生成等功能。您可以免费试用。
AI模型测试评估工具
Openlayer是一个评估工具,适用于您的开发和生产流程,帮助您自信地发布高质量的模型。它提供强大的测试、评估和可观察性,无需猜测您的提示是否足够好。支持LLMs、文本分类、表格分类、表格回归等功能。通过实时通知让您在AI模型失败时获得通知,让您自信地发布。

© 2026 AIbase 备案号:闽ICP备08105208号-14