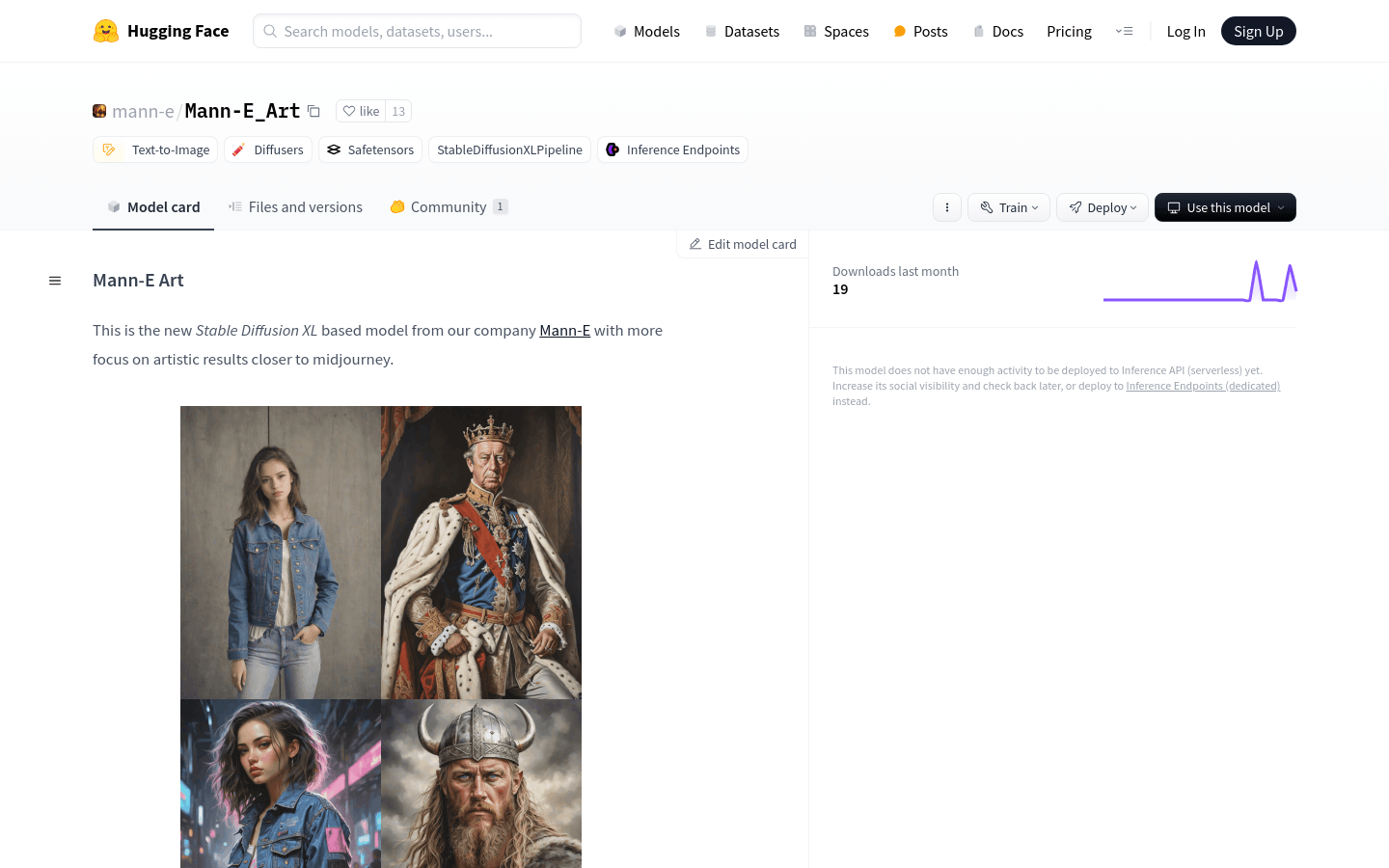
Mann-E Art是由Mann-E公司开发的一款基于Stable Diffusion XL的图像生成模型,专注于生成接近midjourney艺术风格的图像。该模型在训练过程中使用了约1000个midjourney输出以及团队收集的照片,擅长生成照片、艺术作品和数字绘画,但在像素艺术或矢量插画方面可能表现一般。
需求人群:
"Mann-E Art模型适合需要生成高质量艺术图像的设计师和艺术家,以及对图像生成技术感兴趣的研究者和开发者。它可以帮助用户快速生成具有艺术感的图像,提高创作效率。"
使用场景示例:
设计师使用Mann-E Art生成具有中东风格的猫咪插画
艺术家利用该模型创作数字绘画作品
研究人员使用Mann-E Art进行AI艺术生成技术的研究
产品特色:
生成逼真的中东城市中的猫咪图像
支持使用DiffusionPipeline进行图像生成
支持DPMSolverSinglestepScheduler进行单步调度
可自定义图像生成的推理步骤数
可调节引导比例以控制生成图像的细节
支持生成768x768分辨率的图像
支持更大分辨率如1024x1024的图像生成
对矩形图像如832x1216和608x1080也有很好的支持
使用教程:
导入DiffusionPipeline和DPMSolverSinglestepScheduler
从预训练模型中加载Mann-E Art模型
设置模型到CUDA设备以利用GPU加速
配置DPMSolverSinglestepScheduler以使用Karras的σ值
使用prompt参数定义生成图像的主题
设置num_inference_steps和guidance_scale参数
指定图像的宽度和高度
调用模型生成图像并保存到本地文件
浏览量:85
最新流量情况
月访问量
25633.38k
平均访问时长
00:04:53
每次访问页数
5.77
跳出率
44.05%
流量来源
直接访问
49.07%
自然搜索
35.64%
邮件
0.03%
外链引荐
12.38%
社交媒体
2.75%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
中国
14.36%
印度
8.76%
韩国
3.61%
俄罗斯
5.25%
美国
16.65%
基于Stable Diffusion XL的图像生成模型
Mann-E Art是由Mann-E公司开发的一款基于Stable Diffusion XL的图像生成模型,专注于生成接近midjourney艺术风格的图像。该模型在训练过程中使用了约1000个midjourney输出以及团队收集的照片,擅长生成照片、艺术作品和数字绘画,但在像素艺术或矢量插画方面可能表现一般。
Stable Diffusion WebUI Forge是基于Stable Diffusion WebUI的图像生成平台
Stable Diffusion WebUI Forge基于Stable Diffusion WebUI和Gradio开发,旨在优化资源管理、加速推理。相比原版WebUI在1024px分辨率下的SDXL推理,Forge可提升30-75%的速度,最大分辨率提升2-3倍,最大batch size提升4-6倍。Forge保持了原版WebUI的所有功能,同时新增了DDPM、DPM++、LCM等采样器,实现了Free U、SVD、Zero123等算法。使用Forge的UNet Patcher,开发者可以用极少的代码实现算法。Forge还优化了控制网络的使用,实现真正的零内存占用调用。
AI文本转GIF模型,与Stable Diffusion XL配套使用
Hotshot-XL是一个AI文本转GIF模型,训练用于与Stable Diffusion XL配套使用。Hotshot-XL可以使用任何经过微调的SDXL模型生成GIF。这意味着您可以使用任何现有或新经过微调的SDXL模型制作GIF。如果您想制作个性化主题的GIF,您可以加载自己的基于SDXL的LORAs,而无需担心对Hotshot-XL进行微调。这非常棒,因为通常很容易找到适合训练数据的图像,而找到视频则更困难。它还希望适用于每个人现有的LORA使用/工作流程。Hotshot-XL与SDXL ControlNet兼容,可以按照您想要的组合/布局制作GIF。Hotshot-XL经过训练,可以以8FPS生成1秒的GIF。Hotshot-XL经过训练,适用于各种宽高比。对于基本的Hotshot-XL模型,我们建议您使用与512x512图像进行微调的SDXL模型以获得最佳效果。您可以在此处找到我们为512x512分辨率进行微调的SDXL模型。
Animagine XL 4.0 是一款专注于动漫风格的Stable Diffusion XL模型,专为生成高质量动漫图像而设计。
Animagine XL 4.0 是一款基于Stable Diffusion XL 1.0微调的动漫主题生成模型。它使用了840万张多样化的动漫风格图像进行训练,训练时长达到2650小时。该模型专注于通过文本提示生成和修改动漫主题图像,支持多种特殊标签,可控制图像生成的不同方面。其主要优点包括高质量的图像生成、丰富的动漫风格细节以及对特定角色和风格的精准还原。该模型由Cagliostro Research Lab开发,采用CreativeML Open RAIL++-M许可证,允许商业使用和修改。
TensorRT加速的Stable Diffusion扩展
Stable-Diffusion-WebUI-TensorRT是一个用于Stable Diffusion的TensorRT加速扩展,可在NVIDIA RTX GPU上实现最佳性能。该扩展需要安装并生成优化的引擎才能使用。支持Stable Diffusion 1.5和2.1版本。安装步骤请参考官方网址。使用时,可以生成默认引擎,选择TRT模型,加速生成图像。可以根据需要生成多个优化引擎。详细的使用说明和常见问题请参考官方文档。
免费Stable Diffusion AI图像生成器
Stable Diffusion 是一个深度学习模型,可从文本描述生成图像。通过输入描述性文本,可以生成高质量的逼真图像。用户可以免费在线使用 Stable Diffusion,生成各种类型的艺术图像。
基于Stable Diffusion的LoRA模型,生成逼真动漫风格图像
RealAnime - Detailed V1 是一个基于Stable Diffusion的LoRA模型,专门用于生成逼真的动漫风格图像。该模型通过深度学习技术,能够理解并生成高质量的动漫人物图像,满足动漫爱好者和专业插画师的需求。它的重要性在于能够大幅度提高动漫风格图像的生成效率和质量,为动漫产业提供强大的技术支持。目前,该模型在Tensor.Art平台上提供,用户可以通过在线方式使用,无需下载安装,方便快捷。价格方面,用户可以通过购买Buffet计划来解锁下载权益,享受更灵活的使用方式。
TPUv5e 上稳定扩散 XL 模型的应用
Stable Diffusion XL是在 TPUv5e 上运行的一个 Hugging Face Space,它提供了稳定扩散 XL 模型的应用。Stable Diffusion XL是一个强大的自然语言处理模型,它在文本生成、问答、语义理解等多个领域有广泛的应用。该模型在 TPUv5e 上运行,具有高效、稳定的特性,能够处理大规模数据和复杂任务。
一个强大的安卓Stable Diffusion客户端
diffusion-client是一个用于安卓的Stable Diffusion客户端。它提供了强大的图像生成能力,包括文本到图像、图像到图像、图像修复等功能。该APP支持多种模型,内置控制网调节生成效果。另外,该APP具有历史记录管理、标签提取等高级功能,同时支持扩展插件,可链接到Civitai等模型。
基于Stable Diffusion的图像生成Web界面
Stable Diffusion web UI是一个基于Stable Diffusion模型的Web界面,使用Gradio库实现,提供了多种图像生成功能,包括txt2img和img2img模式,一键安装和运行脚本,以及高级的图像处理选项,如Outpainting、Inpainting、Color Sketch等。它支持多种硬件平台,包括NVidia、AMD、Intel和Ascend NPUs,并提供了详细的安装和运行指南。
AI 艺术风格库
KALOS.art 是世界上最大的 AI 艺术风格库,提供超过 1300 位艺术家和 292 种风格 / 媒介。用户可以浏览不同艺术家和风格,创建收藏并探索 AI 艺术创作。价格取决于会员级别。
Stable Diffusion推理优化java实现
sd4j是一个使用ONNX Runtime的Stable Diffusion推理Java实现,以C#实现进行了优化移植,带有重复生成图像的图形界面,并支持负面文本输入。 旨在演示如何在Java中使用ONNX Runtime,以及获得良好性能的ONNX Runtime的最佳实践。 我们将使其与ONNX Runtime的最新版本保持同步,并随着通过ONNX Runtime Java API提供的性能相关ONNX Runtime功能的出现进行适当更新。 所有代码都可能会发生变化,因为这是一个代码示例,任何API都不应该被视为稳定的。
用于Stable Diffusion 1.5的图像组合适配器
该适配器为Stable Diffusion 1.5设计,用于将一般图像组合注入到模型中,同时大部分忽略风格和内容。例如一个人摆手的肖像会生成一个完全不同的人在摆手的图像。该适配器的优势是允许控制更加灵活,不像Control Nets那样会严格匹配控制图像。产品由POM with BANODOCO构思,ostris训练并发布。
托管在 NVIDIA NGC(NVIDIA GPU Cloud 针对深度学习和科学计算优化的基于GPU加速的云平台)上的一个免费实例
Stable Diffusion XL(SDXL)是一个生成对抗网络模型,能够用更短的提示生成富有表现力的图像,并在图像中插入文字。它基于 Stability AI 开发的 Stable Diffusion 模型进行了改进,使图像生成更加高质量和可控,支持用自然语言进行本地化图像编辑。该模型可用于各种创意设计工作,如概念艺术、平面设计、视频特效等领域。
AI艺术风格生成器,无需技能即可将图片转换为任何风格。
Style Art AI是一款结合了最新的ChatGPT 4o模型和各种艺术风格的工具,可以通过简单描述或上传图片,在任何风格下创建令人惊叹的艺术作品。它能够实现多种艺术风格的深度理解,为用户提供创造性无限可能,从而轻松地将想象转化为现实。价格灵活,适合广泛用户。
一款基于 Stable Diffusion 的免费在线 AI 绘画工具。
视觉族是一款基于开源 AI 绘画模型 Stable Diffusion 的工具,允许用户通过文本提示生成高质量艺术图像。该工具免费使用,定位于帮助用户快速实现艺术创作,适合所有想要发挥创造力的人士。
Civitai是一个AI艺术搜索引擎, 帮助你发现最佳的Stable Diffusion模型和图像
Civitai是一个专门为Stable Diffusion用户打造的AI艺术搜索引擎。它拥有海量标签化的模型和图像,支持按模型、艺术家、类别等进行搜索和浏览。Civitai会根据流行度和相关度对结果进行智能排序,帮你快速找到所需的模型和图片资源。它是使用Stable Diffusion的最佳搜索工具。
多平台Stable Diffusion的一键安装包 支持Mac
Stability Matrix 是一个用户友好的桌面客户端,旨在简化 Stable Diffusion 的图像生成过程。它通过一键安装和无缝的模型集成,帮助用户轻松管理和生成图像,无需深入的技术知识。该工具支持多种操作系统,并能有效管理模型资源,降低用户的学习曲线。Stability Matrix 提供稳定性和灵活性,特别适合图像创作者、设计师及数字艺术家使用。
开源双语文生图生成模型
Taiyi-Diffusion-XL是一个开源的基于Stable Diffusion训练的双语文生图生成模型,支持英文和中文的文本到图像生成,相比之前的中文文生图模型有了显著提升。它可以根据文本描述生成照片般逼真的图像,支持多种图像风格,具有较高的生成质量和多样性。该模型采用创新的训练方式,扩展了词表、位置编码以支持长文本和中文,并在大规模双语数据集上进行训练,确保了其强大的中英文生成能力。
基于Stable Diffusion 3.5 Large模型的IP适配器
SD3.5-Large-IP-Adapter是一个基于Stable Diffusion 3.5 Large模型的IP适配器,由InstantX Team研发。该模型能够将图像处理工作类比于文本处理,具有强大的图像生成能力,并且可以通过适配器技术进一步提升图像生成的质量和效果。该技术的重要性在于其能够推动图像生成技术的发展,特别是在创意工作和艺术创作领域。产品背景信息显示,该模型是由Hugging Face和fal.ai赞助的项目,并且遵循stabilityai-ai-community的许可协议。
Stable Diffusion 3.5 Large的三款ControlNets模型
ControlNets for Stable Diffusion 3.5 Large是Stability AI推出的三款图像控制模型,包括Blur、Canny和Depth。这些模型能够提供精确和便捷的图像生成控制,适用于从室内设计到角色创建等多种应用场景。它们在用户偏好的ELO比较研究中排名第一,显示出其在同类模型中的优越性。这些模型在Stability AI社区许可下免费提供给商业和非商业用途,对于年收入不超过100万美元的组织和个人,使用完全免费,并且产出的媒体所有权归用户所有。
将任何图像即时转换为AI提示,支持Midjourney、DALL - E 3和Stable Diffusion,免费
ImaginPrompt Image to Prompt Generator是一款在线工具,可将图像逆向工程为AI提示。它支持多种AI图像生成模型,如Midjourney、DALL - E 3和Stable Diffusion。该工具的主要优点在于免费使用且无需注册,能够快速将图像转换为精确的提示,为用户节省时间和精力。它采用先进的计算机视觉技术,即使对于AI生成图像和真实照片都能有效处理。价格方面,免费版每天提供5次转换机会,满足个人项目和测试需求;付费版则解锁无限批量处理和API访问,适合专业工作流程。
新一代文本到图像生成AI模型
Stable Diffusion 3是stability公司推出的新一代文本到图像生成AI模型,相比早期版本在多主体提示、图像质量和拼写能力等方面都有了极大提升。该模型采用了diffusion transformer架构和flow matching技术,参数量范围从800M到8B不等,提供了从个人用户到企业客户多种部署方案。主要功能包括:高质量图片生成、支持多主体、拼写错误纠正等。典型应用场景有:数字艺术创作、图片编辑、游戏和电影制作等。相比早期版本,该AI助手具有更强大的理解和创作能力,是新一代安全、开放、普惠的生成式AI典范。
Midjourney AI的最先进的艺术风格库
Midlibrary是Midjourney AI的最新版本V6的艺术风格库,包含各种风格、艺术运动、技术、标题和艺术家风格。用户可以通过Midlibrary浏览并应用这些艺术风格,以丰富和美化其作品。Midlibrary的V6版本拥有更多功能和优势,可通过Patreon支持。定价根据使用情况而定,定位于为用户提供最先进的艺术风格应用。
利用AI生成印度风格的图像
BharatDiffusion是一个基于AI的图像生成模型,专门针对印度的多样化景观、文化和遗产进行微调,能够生成反映印度丰富文化和特色的高质量图像。该模型使用Stable Diffusion技术处理所有图像生成,确保内容与印度的多样性和活力相呼应。
基于Diffusion的文本到图像生成模型,专注于时尚模特摄影风格图像生成
Fashion-Hut-Modeling-LoRA是一个基于Diffusion技术的文本到图像生成模型,主要用于生成时尚模特的高质量图像。该模型通过特定的训练参数和数据集,能够根据文本提示生成具有特定风格和细节的时尚摄影图像。它在时尚设计、广告制作等领域具有重要应用价值,能够帮助设计师和广告商快速生成创意概念图。模型目前仍在训练阶段,可能存在一些生成效果不佳的情况,但已经展示了强大的潜力。该模型的训练数据集包含14张高分辨率图像,使用了AdamW优化器和constant学习率调度器等参数,训练过程注重图像的细节和质量。
动漫风格图像生成模型
Momo XL是一个基于SDXL的动漫风格模型,经过微调,能够生成高质量、细节丰富、色彩鲜艳的动漫风格图像。它特别适合艺术家和动漫爱好者使用,并且支持基于标签的提示,确保输出结果的准确性和相关性。此外,Momo XL还兼容大多数LoRA模型,允许用户进行多样化的定制和风格转换。

© 2026 AIbase 备案号:闽ICP备08105208号-14