LLM Transparency Tool
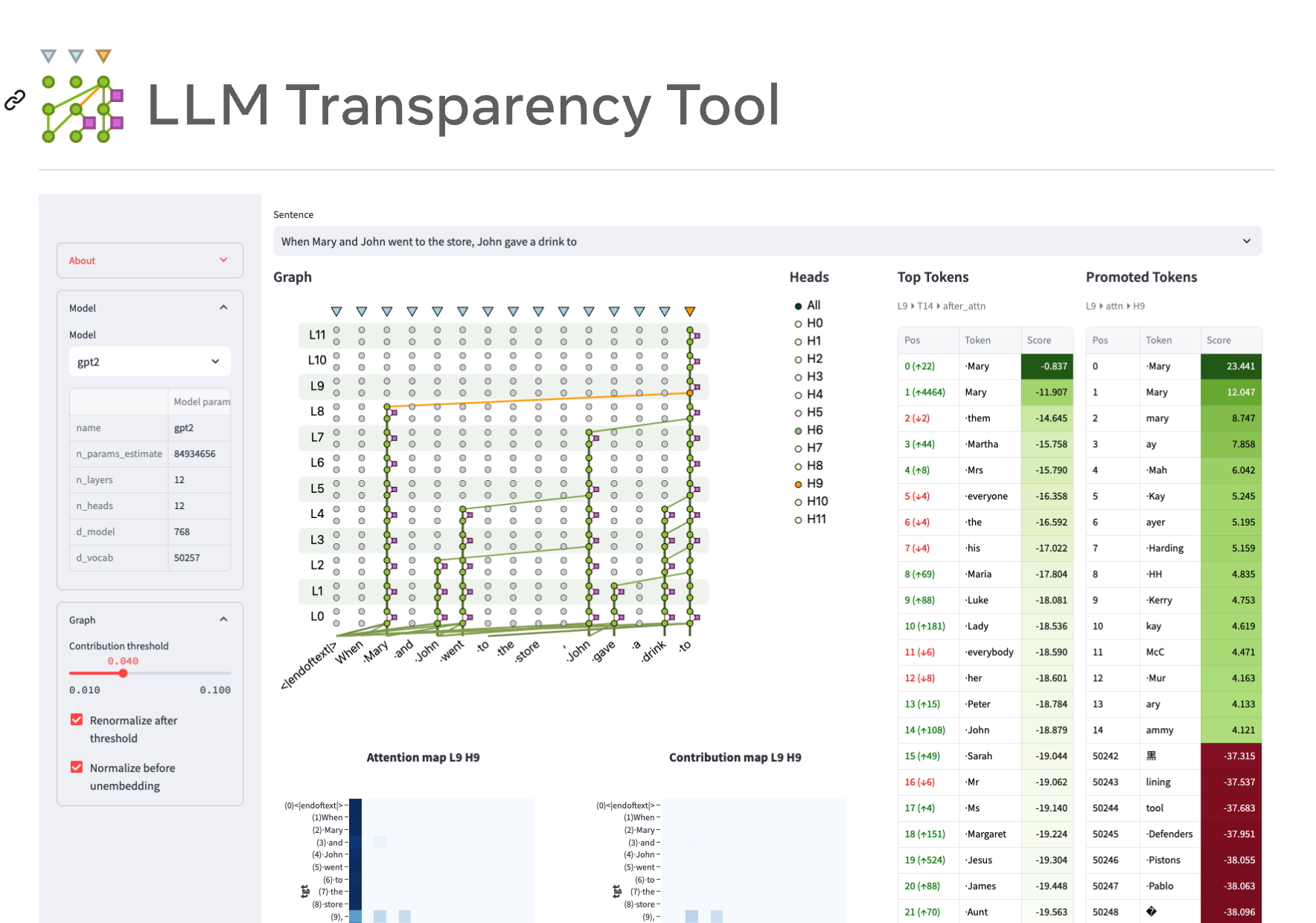
LLM Transparency Tool(LLM-TT)是一个开源的交互式工具包,用于分析基于Transformer的语言模型的内部工作机制。它允许用户选择模型、添加提示并运行推理,通过可视化的方式展示模型的注意力流动和信息传递路径。该工具旨在提高模型的透明度,帮助研究人员和开发者更好地理解和改进语言模型。
需求人群:
"研究人员和开发者分析和理解语言模型"
使用场景示例:
研究人员使用LLM-TT分析特定语言模型的注意力分布
开发者通过LLM-TT调整模型参数以改善性能
教育工作者利用LLM-TT向学生展示语言模型的工作原理
产品特色:
选择模型和提示进行推理
浏览贡献图
选择令牌以构建图表
调整贡献阈值
选择任何令牌在任何块之后的表示
查看输出词汇表中的表示,以及前一个块中哪些令牌被提升/抑制
浏览量:107
最新流量情况
月访问量
4.93m
平均访问时长
00:06:29
每次访问页数
6.10
跳出率
36.08%
流量来源
直接访问
54.82%
自然搜索
31.76%
邮件
0.04%
外链引荐
11.31%
社交媒体
1.86%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
中国
12.56%
德国
3.93%
印度
9.82%
俄罗斯
5.43%
美国
18.51%
快速且内存高效的精确注意力机制
FlashAttention是一个开源的注意力机制库,专为深度学习中的Transformer模型设计,以提高计算效率和内存使用效率。它通过IO感知的方法优化了注意力计算,减少了内存占用,同时保持了精确的计算结果。FlashAttention-2进一步改进了并行性和工作分配,而FlashAttention-3针对Hopper GPU进行了优化,支持FP16和BF16数据类型。
分析Transformer语言模型的内部工作机制
LLM Transparency Tool(LLM-TT)是一个开源的交互式工具包,用于分析基于Transformer的语言模型的内部工作机制。它允许用户选择模型、添加提示并运行推理,通过可视化的方式展示模型的注意力流动和信息传递路径。该工具旨在提高模型的透明度,帮助研究人员和开发者更好地理解和改进语言模型。
高分辨率多视角扩散模型,使用高效行注意力机制。
Era3D是一个开源的高分辨率多视角扩散模型,它通过高效的行注意力机制来生成高质量的图像。该模型能够生成多视角的颜色和法线图像,支持自定义参数以获得最佳结果。Era3D在图像生成领域具有重要性,因为它提供了一种新的方法来生成逼真的三维图像。
MoBA 是一种用于长文本上下文的混合块注意力机制,旨在提升大语言模型的效率。
MoBA(Mixture of Block Attention)是一种创新的注意力机制,专为长文本上下文的大语言模型设计。它通过将上下文划分为块,并让每个查询令牌学习关注最相关的块,从而实现高效的长序列处理。MoBA 的主要优点是能够在全注意力和稀疏注意力之间无缝切换,既保证了性能,又提高了计算效率。该技术适用于需要处理长文本的任务,如文档分析、代码生成等,能够显著降低计算成本,同时保持模型的高性能表现。MoBA 的开源实现为研究人员和开发者提供了强大的工具,推动了大语言模型在长文本处理领域的应用。
快速且内存高效的精确注意力机制
FlexHeadFA 是一个基于 FlashAttention 的改进模型,专注于提供快速且内存高效的精确注意力机制。它支持灵活的头维度配置,能够显著提升大语言模型的性能和效率。该模型的主要优点包括高效利用 GPU 资源、支持多种头维度配置以及与 FlashAttention-2 和 FlashAttention-3 兼容。它适用于需要高效计算和内存优化的深度学习场景,尤其在处理长序列数据时表现出色。
基于注意力机制的运动生成和无训练编辑模型
MotionCLR是一个基于注意力机制的运动扩散模型,专注于人类动作的生成和编辑。它通过自注意力和交叉注意力机制,分别模拟模态内和模态间的交互,实现对动作序列的精细控制和编辑。该模型的主要优点包括无需训练即可进行编辑,具有较好的解释性,能够通过操作注意力图来实现多种运动编辑方法,如动作的强调或减弱、就地替换动作、基于示例的动作生成等。MotionCLR的研究背景是解决以往运动扩散模型在细粒度编辑能力上的不足,通过清晰的文本-动作对应关系,提高动作编辑的灵活性和精确性。
首个无需注意力机制的7B大规模模型
Falcon Mamba是由阿布扎比技术创新研究所(TII)发布的首个无需注意力机制的7B大规模模型。该模型在处理大型序列时,不受序列长度增加导致的计算和存储成本增加的限制,同时保持了与现有最先进模型相当的性能。
个性化图像生成的注意力混合架构
Mixture-of-Attention (MoA) 是一种用于个性化文本到图像扩散模型的新架构,它通过两个注意力路径——个性化分支和非个性化先验分支——来分配生成工作负载。MoA 设计用于保留原始模型的先验,同时通过个性化分支最小干预生成过程,该分支学习将主题嵌入到先验分支生成的布局和上下文中。MoA 通过一种新颖的路由机制管理每层像素在这些分支之间的分布,以优化个性化和通用内容创建的混合。训练完成后,MoA 能够创建高质量、个性化的图像,展示多个主题的组成和互动,与原始模型生成的一样多样化。MoA 增强了模型的先有能力与新增强的个性化干预之间的区别,从而提供了以前无法实现的更解耦的主题上下文控制。
个人AI助手,帮助管理注意力和专注
Monkai是您的个人AI助手,帮助您管理注意力、避免分心,并提供正念引导。它能帮助您远离Facebook、Instagram等分散注意力和不健康的网站,帮助您保持专注。它通过时间逐渐减少您在这些网站上的使用。Monkai采用人工智能(AI)技术,能够理解和引导您的数字习惯。您的隐私是我们的首要任务!我们使用先进的设备上联合学习技术,确保您的原始信息永远不会被存储或共享。
高效能混合专家注意力路由语言模型
Yuan2.0-M32是一个具有32个专家的混合专家(MoE)语言模型,其中2个是活跃的。提出了一种新的路由网络——注意力路由,用于更高效的专家选择,提高了3.8%的准确性。该模型从零开始训练,使用了2000B个token,其训练计算量仅为同等参数规模的密集模型所需计算量的9.25%。在编码、数学和各种专业领域表现出竞争力,仅使用3.7B个活跃参数,每个token的前向计算量仅为7.4 GFLOPS,仅为Llama3-70B需求的1/19。在MATH和ARC-Challenge基准测试中超越了Llama3-70B,准确率分别达到了55.9%和95.8%。
高效长序列大型语言模型推理技术
Star-Attention是NVIDIA提出的一种新型块稀疏注意力机制,旨在提高基于Transformer的大型语言模型(LLM)在长序列上的推理效率。该技术通过两个阶段的操作显著提高了推理速度,同时保持了95-100%的准确率。它与大多数基于Transformer的LLM兼容,无需额外训练或微调即可直接使用,并且可以与其他优化方法如Flash Attention和KV缓存压缩技术结合使用,进一步提升性能。
通过 AI 冥想提高注意力和减轻压力
Bliss Brain 是一款利用人工智能技术创建定制冥想的应用。它可以根据你的需求生成个性化的冥想内容,帮助你提高注意力、减轻压力,并改善睡眠质量。你可以选择不同的目标,包括减压、缓解焦虑、增强注意力或改善睡眠质量。此外,你还可以选择不同的声音和背景音乐,以获得更丰富的冥想体验。Bliss Brain 为你提供 5、10 或 15 分钟的冥想时长,让冥想融入你的日常生活。
优化的小型语言模型,适用于移动设备
MobileLLM是一种针对移动设备优化的小型语言模型,专注于设计少于十亿参数的高质量LLMs,以适应移动部署的实用性。与传统观念不同,该研究强调了模型架构在小型LLMs中的重要性。通过深度和薄型架构,结合嵌入共享和分组查询注意力机制,MobileLLM在准确性上取得了显著提升,并提出了一种不增加模型大小且延迟开销小的块级权重共享方法。此外,MobileLLM模型家族在聊天基准测试中显示出与之前小型模型相比的显著改进,并在API调用任务中接近LLaMA-v2 7B的正确性,突出了小型模型在普通设备用例中的能力。
具有注意力下沉的高效流媒体语言模型
StreamingLLM是一种高效的语言模型,能够处理无限长度的输入,而不会牺牲效率和性能。它通过保留最近的令牌和注意力池,丢弃中间令牌,从而使模型能够从最近的令牌生成连贯的文本,而无需缓存重置。StreamingLLM的优势在于能够在不需要刷新缓存的情况下,从最近的对话中生成响应,而不需要依赖过去的数据。
深入理解Transformer模型的可视化工具
Transformer Explainer是一个致力于帮助用户深入理解Transformer模型的在线可视化工具。它通过图形化的方式展示了Transformer模型的各个组件,包括自注意力机制、前馈网络等,让用户能够直观地看到数据在模型中的流动和处理过程。该工具对于教育和研究领域具有重要意义,可以帮助学生和研究人员更好地理解自然语言处理领域的先进技术。
高效序列模型的新进展
Mamba-2是Goomba AI Lab开发的一种新型序列模型,旨在提高机器学习社区中序列模型的效率和性能。它通过结构化状态空间对偶(SSD)模型,结合了状态空间模型(SSM)和注意力机制的优点,提供了更高效的训练过程和更大的状态维度。Mamba-2的设计允许模型在训练时利用矩阵乘法,从而提高了硬件效率。此外,Mamba-2在多查询关联记忆(MQAR)等任务中表现出色,显示出其在复杂序列处理任务中的潜力。
Gemma 2B模型,支持10M序列长度,优化内存使用,适用于大规模语言模型应用。
Gemma 2B - 10M Context是一个大规模的语言模型,它通过创新的注意力机制优化,能够在内存使用低于32GB的情况下处理长达10M的序列。该模型采用了循环局部注意力技术,灵感来源于Transformer-XL论文,是处理大规模语言任务的强大工具。
FlashInfer是一个用于大型语言模型服务的高性能GPU内核库。
FlashInfer是一个专为大型语言模型(LLM)服务而设计的高性能GPU内核库。它通过提供高效的稀疏/密集注意力机制、负载平衡调度、内存效率优化等功能,显著提升了LLM在推理和部署时的性能。FlashInfer支持PyTorch、TVM和C++ API,易于集成到现有项目中。其主要优点包括高效的内核实现、灵活的自定义能力和广泛的兼容性。FlashInfer的开发背景是为了满足日益增长的LLM应用需求,提供更高效、更可靠的推理支持。
基于 Transformer 的图像识别模型
Google Vision Transformer 是一款基于 Transformer 编码器的图像识别模型,使用大规模图像数据进行预训练,可用于图像分类等任务。该模型在 ImageNet-21k 数据集上进行了预训练,并在 ImageNet 数据集上进行了微调,具备良好的图像特征提取能力。该模型通过将图像切分为固定大小的图像块,并线性嵌入这些图像块来处理图像数据。同时,模型在输入序列前添加了位置编码,以便在 Transformer 编码器中处理序列数据。用户可以通过在预训练的编码器之上添加线性层进行图像分类等任务。Google Vision Transformer 的优势在于其强大的图像特征学习能力和广泛的适用性。该模型免费提供使用。
基于 Transformer 的预训练语言模型系列
Qwen1.5 是基于 Transformer 架构的解码器语言模型系列,包括不同规模的模型。具有 SwiGLU 激活、注意力 QKV 偏置、组查询注意力等特性。支持多种自然语言和代码。推荐进行后续训练,如 SFT、RLHF 等。定价免费。
腾讯QQ多媒体研究团队开发的轻量级灵活视频多语言模型
Video-CCAM 是腾讯QQ多媒体研究团队开发的一系列灵活的视频多语言模型(Video-MLLM),致力于提升视频-语言理解能力,特别适用于短视频和长视频的分析。它通过因果交叉注意力掩码(Causal Cross-Attention Masks)来实现这一目标。Video-CCAM 在多个基准测试中表现优异,特别是在 MVBench、VideoVista 和 MLVU 上。模型的源代码已经重写,以简化部署过程。
Flash-Decoding for long-context inference
Flash-Decoding是一种针对长上下文推理的技术,可以显著加速推理中的注意力机制,从而使生成速度提高8倍。该技术通过并行加载键和值,然后分别重新缩放和组合结果来维护正确的注意力输出,从而实现了更快的推理速度。Flash-Decoding适用于大型语言模型,可以处理长文档、长对话或整个代码库等长上下文。Flash-Decoding已经在FlashAttention包和xFormers中提供,可以自动选择Flash-Decoding或FlashAttention方法,也可以使用高效的Triton内核。
大规模训练 Transformer 模型的持续研究
Megatron-LM 是由 NVIDIA 应用深度学习研究团队开发的一种强大的大规模 Transformer 模型。该产品用于大规模训练 Transformer 语言模型的持续研究。我们使用混合精度,高效的模型并行和数据并行,以及多节点的 Transformer 模型(如 GPT、BERT 和 T5)的预训练。
高效能混合专家语言模型
Yuan2.0-M32-hf-int8是一个具有32个专家的混合专家(MoE)语言模型,其中2个是活跃的。该模型通过采用新的路由网络——注意力路由器,提高了专家选择的效率,使得准确率比使用传统路由网络的模型提高了3.8%。Yuan2.0-M32从头开始训练,使用了2000亿个token,其训练计算量仅为同等参数规模的密集模型所需计算量的9.25%。该模型在编程、数学和各种专业领域展现出竞争力,并且只使用37亿个活跃参数,占总参数40亿的一小部分,每个token的前向计算仅为7.4 GFLOPS,仅为Llama3-70B需求的1/19。Yuan2.0-M32在MATH和ARC-Challenge基准测试中超越了Llama3-70B,分别达到了55.9%和95.8%的准确率。
集成空间编织注意力,提升扩散模型的高保真条件
HelloMeme是一个集成了空间编织注意力的扩散模型,旨在将高保真和丰富的条件嵌入到图像生成过程中。该技术通过提取驱动视频中的每一帧特征,并将其作为输入到HMControlModule,从而生成视频。通过进一步优化Animatediff模块,提高了生成视频的连续性和保真度。此外,HelloMeme还支持通过ARKit面部混合形状控制生成的面部表情,以及基于SD1.5的Lora或Checkpoint,实现了框架的热插拔适配器,不会影响T2I模型的泛化能力。
加速长上下文大型语言模型的预填充处理
MInference 1.0 是一种稀疏计算方法,旨在加速长序列处理的预填充阶段。它通过识别长上下文注意力矩阵中的三种独特模式,实现了对长上下文大型语言模型(LLMs)的动态稀疏注意力方法,加速了1M token提示的预填充阶段,同时保持了LLMs的能力,尤其是检索能力。
捕捉用户注意力,将访问转化为潜在客户和销售
Superteam是一个捕捉用户注意力并将访问转化为潜在客户和销售的系统。它包括优化的订阅页面、价值为导向的电子邮件营销、持续的客户培养和建立关系等功能。Superteam可以帮助您提高转化率、增加销售和构建客户关系。我们每个月与4个客户合作,欢迎联系我们咨询可用性。
扩展Transformer模型处理无限长输入
Google开发的“Infini-attention”技术旨在扩展基于Transformer的大语言模型以处理无限长的输入,通过压缩记忆机制实现无限长输入处理,并在多个长序列任务上取得优异表现。技术方法包括压缩记忆机制、局部与长期注意力的结合和流式处理能力等。实验结果显示在长上下文语言建模、密钥上下文块检索和书籍摘要任务上的性能优势。

© 2026 AIbase 备案号:闽ICP备08105208号-14