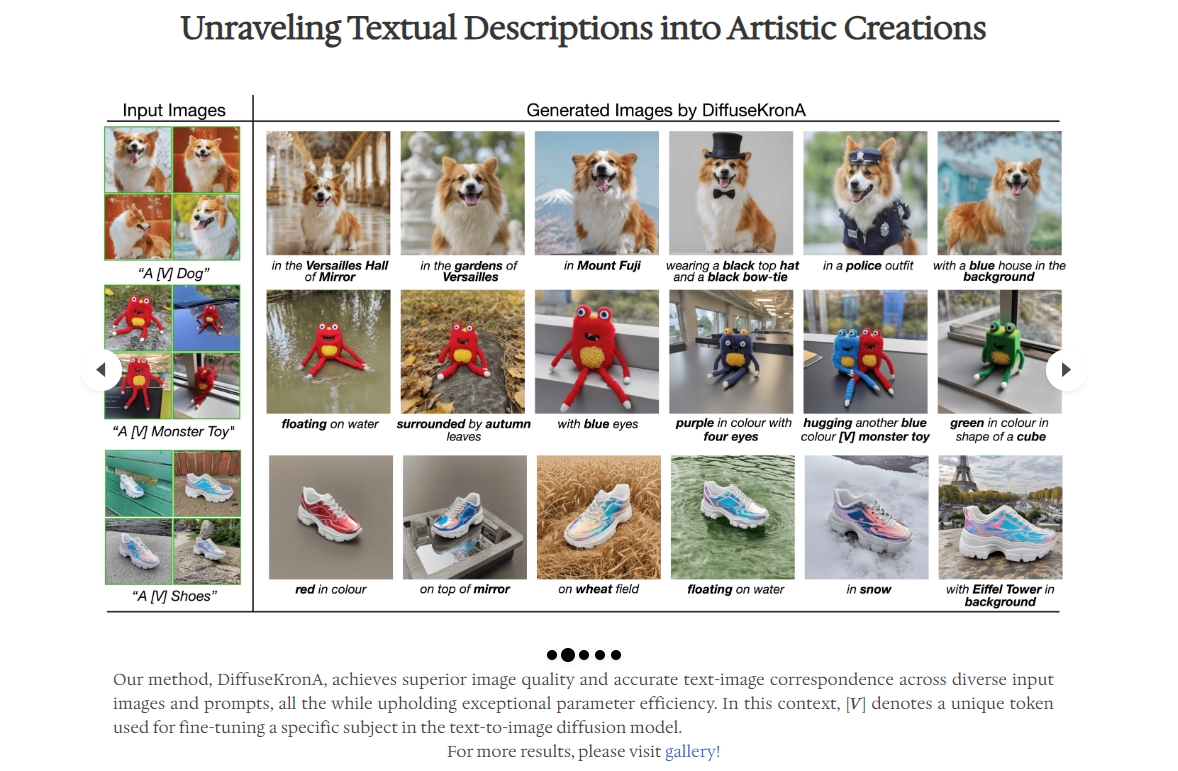
DiffuseKronA 是一种参数高效的微调方法,用于个性化扩散模型。它通过引入基于 Kronecker 乘积的适配模块,显著降低参数数量,提升图像合成质量。该方法减少了对超参数的敏感性,在不同超参数下生成高质量图像,为文本到图像生成模型领域带来重大进展。
需求人群:
"适用于文本到图像生成领域,希望减少参数数量、提高生成图像质量的用户。"
使用场景示例:
{ "title": "高保真图像生成", "description": "使用 DiffuseKronA 生成与文本描述高度符合的图像。" }
{ "title": "参数优化实验", "description": "对比 DiffuseKronA 与其他模型,在参数效率和生成质量上进行评估。" }
{ "title": "文本到图像生成研究", "description": "研究 DiffuseKronA 在不同文本提示下生成图像的能力与稳定性。" }
产品特色:
Kronecker 乘积权重矩阵分解
优化参数数量,提高图像质量
减少对超参数的依赖
产生高质量、高保真度的图像
浏览量:267
参数高效微调个性化扩散模型
DiffuseKronA 是一种参数高效的微调方法,用于个性化扩散模型。它通过引入基于 Kronecker 乘积的适配模块,显著降低参数数量,提升图像合成质量。该方法减少了对超参数的敏感性,在不同超参数下生成高质量图像,为文本到图像生成模型领域带来重大进展。
利用尖端AI技术,将创意转化为高质量图像。
Flux AI 图像生成器是由Black Forest Labs开发的,基于革命性的Flux系列模型,提供尖端的文本到图像技术。该产品通过其120亿参数的模型,能够精确解读复杂的文本提示,创造出多样化、高保真的图像。Flux AI 图像生成器不仅适用于个人艺术创作,也可用于商业应用,如品牌视觉、社交媒体内容等。它提供三种不同的版本以满足不同用户的需求:Flux Pro、Flux Dev和Flux Schnell。
12亿参数的图像生成模型
FLUX.1 [schnell] 是一个具有12亿参数的修正流变换器,能够从文本描述生成图像。它以其尖端的输出质量和竞争性的提示跟随能力而著称,与闭源替代品的性能相匹配。该模型使用潜在对抗性扩散蒸馏进行训练,能够在1到4步内生成高质量的图像。FLUX.1 [schnell] 在apache-2.0许可证下发布,可以用于个人、科学和商业目的。
最新的图像上色算法
DDColor 是最新的图像上色算法,输入一张黑白图像,返回上色处理后的彩色图像,并能够实现自然生动的上色效果。 该模型为黑白图像上色模型,输入一张黑白图像,实现端到端的全图上色,返回上色处理后的彩色图像。 模型期望使用方式和适用范围: 该模型适用于多种格式的图像输入,给定黑白图像,生成上色后的彩色图像;给定彩色图像,将自动提取灰度通道作为输入,生成重上色的图像。
12亿参数的文本到图像生成模型
FLUX.1-dev是一个拥有12亿参数的修正流变换器,能够根据文本描述生成图像。它代表了文本到图像生成技术的最新发展,具有先进的输出质量,仅次于其专业版模型FLUX.1 [pro]。该模型通过指导蒸馏训练,提高了效率,并且开放权重以推动新的科学研究,并赋予艺术家开发创新工作流程的能力。生成的输出可以用于个人、科学和商业目的,具体如flux-1-dev-non-commercial-license所述。
朱雀大模型检测,精准识别AI生成图像,助力内容真实性鉴别。
朱雀大模型检测是腾讯推出的一款AI检测工具,主要功能是检测图片是否由AI模型生成。它经过大量自然图片和生成图片的训练,涵盖摄影、艺术、绘画等内容,可检测多类主流文生图模型生成图片。该产品具有高精度检测、快速响应等优点,对于维护内容真实性、打击虚假信息传播具有重要意义。目前暂未明确其具体价格,但从功能来看,主要面向需要进行内容审核、鉴别真伪的机构和个人,如媒体、艺术机构等。
AI 图像生成进入 “毫秒级” 时代,速度快、质量高。
腾讯混元图像 2.0 是腾讯最新发布的 AI 图像生成模型,显著提升了生成速度和画质。通过超高压缩倍率的编解码器和全新扩散架构,使得图像生成速度可达到毫秒级,避免了传统生成的等待时间。同时,模型通过强化学习算法与人类美学知识的结合,提升了图像的真实感和细节表现,适合设计师、创作者等专业用户使用。
AI生成图像鉴别挑战网站
AI判官是一个AI生成图像鉴别挑战的网站。它提供了普通模式、无尽模式和竞速模式三种游戏玩法。用户可以通过不同难度的游戏来提高自己分辨真实图片和AI生成图片的能力。该网站提供大量高质量的真实图片和AI生成图片作为判别素材。它的出现是对近期AI生成图片技术的一个回应,旨在提高公众的媒体识读能力。
轻量级、先进的2B参数文本生成模型。
Gemma 2 2B是谷歌开发的轻量级、先进的文本生成模型,属于Gemma模型家族。该模型基于与Gemini模型相同的研究和技术构建,是一个文本到文本的解码器仅大型语言模型,提供英文版本。Gemma 2 2B模型适用于问答、摘要和推理等多种文本生成任务,其较小的模型尺寸使其能够部署在资源受限的环境中,如笔记本电脑或桌面电脑,促进了对最先进AI模型的访问,并推动了创新。
基于低秩参数优化的模型控制技术
Control-LoRA 是通过在 ControlNet 上添加低秩参数优化来实现的,为消费级 GPU 提供了更高效、更紧凑的模型控制方法。该产品包含多个 Control-LoRA 模型,包括 MiDaS 和 ClipDrop 深度估计、Canny 边缘检测、照片和素描上色、Revision 等功能。Control-LoRA 模型经过训练,可以在不同的图像概念和纵横比上生成高质量的图像。
实时图像转换与优化,高效的图像管理平台
PixelBin是一个实时图像转换与优化平台,提供数字资产管理和图像处理功能,为用户提供独特的视觉体验和更好的网络互动。通过PixelBin,用户可以批量上传和存储图像,并实时进行图像转换和优化。平台还提供自动压缩图像、响应式图像交付、自定义工作流程和AI支持等功能。PixelBin集中存储和管理图像,提供强大的CDN,以快速交付全球优化的图像。
Banana Pro提供AI图像与视频生成,无水印,含提示优化器
Banana Pro是一个融合了图像与视频生成功能的AI创作平台。它基于Nano Banana、Nano Banana Pro和Sora2等精英AI模型构建,具有强大的AI技术,能够提供高质量的创作成果。该平台的重要性在于它极大地简化了创意过程,通过统一的创作中心,让用户可以在一个平台上完成图像和视频的生成。其主要优点包括智能提示功能,能将基本想法转化为详细提示;精确编辑功能,可在保持原始构图和光线的同时进行精确修改;无水印限制,适合个人和商业项目使用;能生成高分辨率的图像和4K视频,适用于各种媒体。价格方面,提供多种灵活的套餐,包括月度、年度和一次性套餐,且有不同程度的优惠。该平台定位广泛,适合个人用户、专业创作者、团队以及大型企业和专业工作室等不同层次的用户。
强悍的实时图像生成
StreamDiffusion 是一种用于实时交互式生成的创新扩散管道。它为当前基于扩散的图像生成技术引入了显著的性能增强。StreamDiffusion 通过高效的批处理操作简化数据处理流程。它提供了改进的引导机制,最小化计算冗余。通过先进的过滤技术提高 GPU 利用率。它还有效地管理输入和输出操作,以实现更顺畅的执行。StreamDiffusion 优化了缓存策略,提供了多种模型优化和性能增强工具。
AI图像生成与优化工具
Amuse 2.0 Beta是一款由AMD推出的桌面客户端软件,专为AMD Ryzen™ AI 300系列处理器和Radeon™ RX 7000系列显卡用户设计,提供AI图像生成和优化体验。它结合了Stable Diffusion模型和AMD XDNA™超级分辨率技术,无需复杂安装和配置,即可实现高质量的AI图像生成。
10亿参数的英文文本和代码语言模型
INTELLECT-1-Instruct是一个由Prime Intellect训练的10亿参数语言模型,从零开始在1万亿个英文文本和代码token上进行训练。该模型支持文本生成,并且具有分布式训练的能力,能够在不可靠的、全球分布的工作者上进行高性能训练。它使用了DiLoCo算法进行训练,并利用自定义的int8 all-reduce内核来减少通信负载,显著降低了通信开销。这个模型的背景信息显示,它是由30个独立的社区贡献者提供计算支持,并在3个大洲的14个并发节点上进行训练。
1460亿参数的高性能混合专家模型
Skywork-MoE-Base是一个具有1460亿参数的高性能混合专家(MoE)模型,由16个专家组成,并激活了220亿参数。该模型从Skywork-13B模型的密集型检查点初始化而来,并引入了两种创新技术:门控逻辑归一化增强专家多样化,以及自适应辅助损失系数,允许针对层特定调整辅助损失系数。Skywork-MoE在各种流行基准测试中表现出与参数更多或激活参数更多的模型相当的或更优越的性能。
AI优化AI,智能生成优化AI文案
Repromptify是一款AI优化工具,通过智能生成优化AI文案,帮助用户创建端到端优化的AI文案。它支持各类AI模型,包括GPT-4、DALLE•2和Midjourney,并为每个模型生成适配的优化提示。用户可以在其中编写产品描述、问题和指令,Repromptify会根据给定的信息,自动生成最佳的AI提示。同时,Repromptify还提供ChatGPT响应测试,以及DALLE•2和Midjourney生成图像,让用户更直观地了解优化的效果。无需担心语句表达的准确性和繁琐的细节,Repromptify会为您完成。快来体验免费试用吧!
大规模参数扩散变换器模型
DiT-MoE是一个使用PyTorch实现的扩散变换器模型,能够扩展到160亿参数,与密集网络竞争的同时展现出高度优化的推理能力。它代表了深度学习领域在处理大规模数据集时的前沿技术,具有重要的研究和应用价值。
AI 搜索引擎优化系统,提升网站排名。
GEO 排名优化系统源码是一款基于 AI 的搜索引擎优化工具,旨在提升网站在搜索引擎中的排名。该系统具备强大的问答推荐功能,并支持无限 OEM 贴牌,为企业提供灵活的营销服务。适合希望通过优化提高在线曝光度的商家和网站运营者。
一款具有 17 亿参数的开源图像生成基础模型。
HiDream-I1 是一款新型的开源图像生成基础模型,拥有 170 亿个参数,能够在几秒内生成高质量图像。该模型适用于研究和开发,并在多个评测中表现优异,具有高效性和灵活性,适合用于各种创意设计和生成任务。
一键式 AI 文章助手
5118 SEO优化精灵是一款基于海量数据算法的文章生成工具。它可以帮助网站主快速生成高质量、符合 SEO 要求的文章,提高网站在搜索引擎中的排名,从而获得更多的流量。使用该工具,只需输入需要写作的主题关键词,它就可以自动为你生成一篇文章,并且该文章将符合搜索引擎的优化规则。一键式 AI 写作助手的优点在于,它可以快速为网站生成符合 SEO 要求的高质量文章,提高网站在搜索引擎中的排名,减少写作的时间和精力成本,同时提高了文章的质量和可读性。
优化的小型语言模型,适用于移动设备
MobileLLM是一种针对移动设备优化的小型语言模型,专注于设计少于十亿参数的高质量LLMs,以适应移动部署的实用性。与传统观念不同,该研究强调了模型架构在小型LLMs中的重要性。通过深度和薄型架构,结合嵌入共享和分组查询注意力机制,MobileLLM在准确性上取得了显著提升,并提出了一种不增加模型大小且延迟开销小的块级权重共享方法。此外,MobileLLM模型家族在聊天基准测试中显示出与之前小型模型相比的显著改进,并在API调用任务中接近LLaMA-v2 7B的正确性,突出了小型模型在普通设备用例中的能力。
AI驱动的高转化图像生成器
StockDreams.ai是一个使用人工智能技术为各种业务生成高转化图像的在线平台。它可以在60秒内为您的商业、广告、网站或社交媒体帖子生成引人注目的图像,以吸引更多潜在客户的眼球。
优化AI生成的完美回答
Palaxy是一个AI驱动的智能助手,为您的AI生成过程提供丰富的灵感和优化。节省时间,提升技能。通过Palaxy,您可以轻松优化您的AI提示,以获得完美的回答。我们支持各种主流的前沿AI模型,包括ChatGPT、GPT-3.5、GPT-4、Midjourney、Stable Diffusion和Dall-E。通过简单的操作,您可以快速优化您的提示,并在不到10秒的时间内获得最佳结果。Palaxy提供定制化的多目标提示生成,并提供无限次数的优化服务,价格实惠。立即体验Palaxy内置的AI驱动工作流程,提升您的创作效率。
利用先进的提示生成器和优化工具,将想法转化为令人惊叹的AI艺术。
AI图像提示生成器是一款强大的工具,可帮助用户生成和优化图像提示,用于Flux、Midjourney和Stable Diffusion模型。其主要优点包括自动生成详细的艺术提示、提供专业质量输出、简化提示工程等。
由中国电信推出的千亿参数大模型
星辰语义大模型是中国电信推出的千亿参数大模型,具备强大的生成和理解能力。通过缓解多轮幻觉、增强关键信息注意力、强化知识图谱和知识溯源能力,提升模型在推理和回答准确性方面的表现。支持长文本生成和理解、知识问答、逻辑推理、数学能力和代码能力等多项功能,适用于办公、生产协同、客服等场景。
代码生成优化工具
AlphaCodium是一种基于测试的、多阶段、面向代码的迭代流方法,旨在提高LLMs在代码问题上的性能。它通过优化模型在代码生成任务上的表现,特别适用于竞赛性编程问题。用户可以根据配置选择相应的模型(如“gpt-4”、“gpt-3.5-turbo-16k”等),并使用AlphaCodium解决特定问题或整个数据集。该工具还提供了一系列最佳实践,如YAML结构化输出、语义推理、模块化代码生成等,可广泛适用于其他代码生成任务。
8B参数变分自编码器模型,用于高效的文本到图像生成。
Flux.1 Lite是一个由Freepik发布的8B参数的文本到图像生成模型,它是从FLUX.1-dev模型中提取出来的。这个版本相较于原始模型减少了7GB的RAM使用,并提高了23%的运行速度,同时保持了与原始模型相同的精度(bfloat16)。该模型的发布旨在使高质量的AI模型更加易于获取,特别是对于消费级GPU用户。
一个基于文本生成图像的预训练模型,具有80亿参数和Apache 2.0开源许可。
Flex.1-alpha 是一个强大的文本到图像生成模型,基于80亿参数的修正流变换器架构。它继承了FLUX.1-schnell的特性,并通过训练指导嵌入器,使其无需CFG即可生成图像。该模型支持微调,并且具有开放源代码许可(Apache 2.0),适合在多种推理引擎中使用,如Diffusers和ComfyUI。其主要优点包括高效生成高质量图像、灵活的微调能力和开源社区支持。开发背景是为了解决图像生成模型的压缩和优化问题,并通过持续训练提升模型性能。
70B参数量的大型语言模型,专为工具使用优化
Llama-3-70B-Tool-Use是一种70B参数量的大型语言模型,专为高级工具使用和功能调用任务设计。该模型在Berkeley功能调用排行榜(BFCL)上的总体准确率达到90.76%,表现优于所有开源的70B语言模型。该模型优化了变换器架构,并通过完整的微调和直接偏好优化(DPO)在Llama 3 70B基础模型上进行了训练。输入为文本,输出为文本,增强了工具使用和功能调用的能力。尽管其主要用途是工具使用和功能调用,但在一般知识或开放式任务中,可能更适用通用语言模型。该模型可能在某些情况下产生不准确或有偏见的内容,用户应注意实现适合其特定用例的适当安全措施。该模型对温度和top_p采样配置非常敏感。

© 2026 AIbase 备案号:闽ICP备08105208号-14