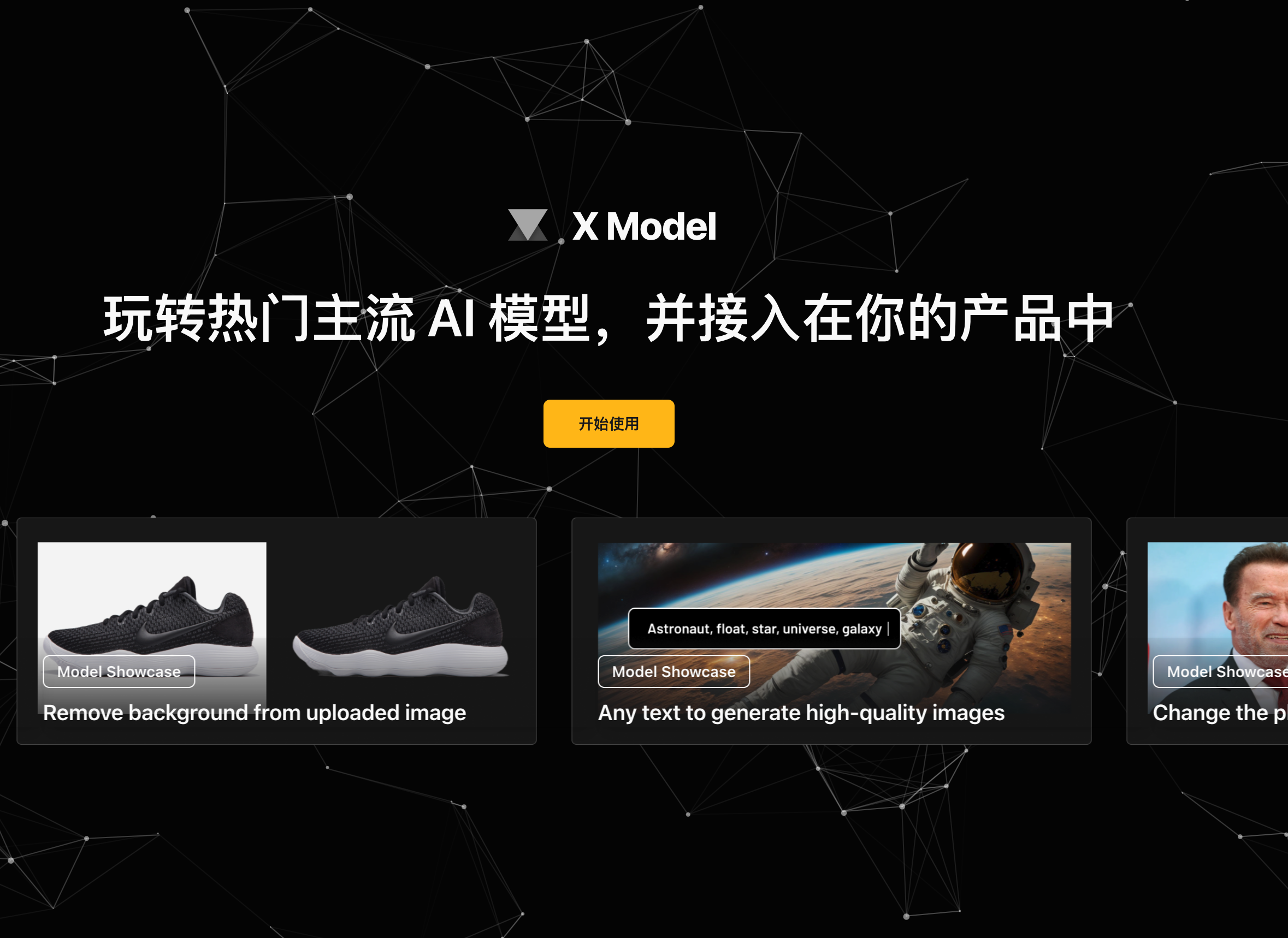
X Model 是一个集成热门主流 AI 模型的平台,用户可以在其产品中轻松接入这些模型。它的主要优点包括多样的模型选择、高质量的输出结果以及简单易用的接入流程。X Model 价格灵活,适用于各种规模的业务。
需求人群:
"X Model 适合那些希望在其产品中加入 AI 模型处理功能的开发者和企业。无论是图像处理、文本生成还是其他 AI 技术应用,X Model 都能满足用户的需求,并为他们节省大量的研发时间和成本。"
使用场景示例:
一家电商企业可以使用 X Model 的图像处理模型对商品图片进行智能美化,提升产品展示效果。
一家社交应用开发者可以利用 X Model 的文本生成模型为用户提供智能对话机器人功能,增强用户体验。
一家新闻媒体平台可以通过 X Model 的语义分析模型快速筛选并生成高质量的新闻摘要,提高工作效率。
产品特色:
灵活的模型选择:X Model 提供多种主流 AI 模型,包括图像处理、文本生成等。
高质量的输出结果:用户可以获得高质量、准确的模型处理结果。
简单易用的接入流程:用户可以轻松将 X Model 的模型集成到自己的产品中。
多样的定制选项:用户可以根据自己的需求定制模型的参数和输出。
强大的技术支持:X Model 提供专业的技术支持和定制化服务,帮助用户解决技术问题。
使用教程:
注册 X Model 账户并登录。
浏览可用的 AI 模型并选择适合的模型。
根据文档指引,将所选模型接入自己的产品中。
调试和优化模型参数和输出效果。
查看模型处理结果并进行后续应用和调整。
浏览量:57
小型多模态模型,支持图像和文本生成
Fuyu-8B是由Adept AI训练的多模态文本和图像转换模型。它具有简化的架构和训练过程,易于理解、扩展和部署。它专为数字代理设计,可以支持任意图像分辨率,回答关于图表和图形的问题,回答基于UI的问题,并对屏幕图像进行细粒度定位。它的响应速度很快,可以在100毫秒内处理大型图像。尽管针对我们的用例进行了优化,但它在标准图像理解基准测试中表现良好,如视觉问答和自然图像字幕。请注意,我们发布的模型是一个基础模型,我们希望您根据具体的用例进行微调,例如冗长的字幕或多模态聊天。在我们的经验中,该模型对于少样本学习和各种用例的微调都表现良好。
先进的文本生成模型,支持多样化任务处理。
OLMo-2-1124-7B-DPO是由Allen人工智能研究所开发的一个大型语言模型,经过特定的数据集进行监督式微调,并进一步进行了DPO训练。该模型旨在提供在多种任务上,包括聊天、数学问题解答、文本生成等的高性能表现。它是基于Transformers库构建的,支持PyTorch,并以Apache 2.0许可发布。
基于文本生成图像的AI模型
fofr/flux-condensation是一个基于文本生成图像的AI模型,使用Diffusers库和LoRAs技术,能够根据用户提供的文本提示生成相应的图像。该模型在Replicate上训练,具有非商业性质的flux-1-dev许可证。它代表了文本到图像生成技术的最新进展,能够为设计师、艺术家和内容创作者提供强大的视觉表现工具。
轻量级、先进的文本生成模型
Gemma 2是Google开发的一系列轻量级、先进的开放模型,基于与Gemini模型相同的研究和技术构建。它们是文本到文本的解码器仅大型语言模型,仅提供英文版本,具有开放的权重,适用于预训练变体和指令调整变体。Gemma模型非常适合各种文本生成任务,包括问答、摘要和推理。其相对较小的体积使其能够部署在资源有限的环境中,如笔记本电脑、桌面或您自己的云基础设施,使先进的AI模型的访问民主化,并帮助为每个人促进创新。
更高效、先进的文本和图像生成模型
CM3leon是一款集文本到图像和图像到文本生成于一身的先进模型。它采用了适应自文本模型的训练配方,包括大规模检索增强预训练阶段和多任务监督微调阶段。CM3leon具有与自回归模型相似的多样性和有效性,同时训练成本低、推理效率高。它是一种因果屏蔽的混合模态(CM3)模型,可以根据任意图像和文本内容生成文本和图像序列。相比以往只能进行文本到图像或图像到文本生成的模型,CM3leon在多模态生成方面具有更高的功能拓展。
先进文本生成图像模型
Stable Diffusion 3是由Stability AI开发的最新文本生成图像模型,具有显著进步的图像保真度、多主体处理和文本匹配能力。利用多模态扩散变换器(MMDiT)架构,提供单独的图像和语言表示,支持API、下载和在线平台访问,适用于各种应用场景。
轻量级、先进的开放文本生成模型
Gemma-2-27b是由Google开发的一系列轻量级、先进的开放文本生成模型,基于与Gemini模型相同的研究和技术构建。这些模型专为文本生成任务设计,如问答、摘要和推理。它们相对较小的体积使得即使在资源有限的环境中,如笔记本电脑、桌面或个人云基础设施上也能部署,使先进的AI模型更易于访问,并促进创新。
全球大模型聚合平台,支持文本、图像、视频全覆盖。
灵客 Ai 是一个全球大模型聚合平台,聚合了 100 + 主流 AI 模型,支持文本、图像和视频等多种类型的调用,用户可以通过简单的操作轻松使用各种 AI 工具。该产品的主要优点在于提升了用户的工作效率,减少了在多个工具间切换的麻烦,适合各类用户从事不同的创作和工作需求。
轻量级、先进的文本生成模型
Gemma-2-9b-it是由Google开发的一系列轻量级、最先进的开放模型,基于与Gemini模型相同的研究和技术构建而成。这些模型是文本到文本的解码器仅大型语言模型,以英文提供,适用于问答、摘要和推理等多样化文本生成任务。由于其相对较小的尺寸,可以在资源有限的环境中部署,如笔记本电脑、桌面或个人云基础设施,使先进的AI模型更加普及,促进创新。
SDXL Turbo是一款在线的文本生成图像模型
SDXL Turbo是一款基于Adversarial Diffusion Distillation(ADD)技术的文本生成图像模型,能够快速生成高质量的图像。它是SDXL 1.0的改进版本,只需一次网络评估即可合成高质量逼真的图像。
轻量级大语言模型,专注于文本生成。
Index-1.9B-Pure是Index系列模型中的轻量版本,专为文本生成而设计。它在2.8T的中英文语料上进行了预训练,与同等级模型相比,在多个评测基准上表现领先。该模型特别过滤了所有指令相关数据,以验证指令对benchmark的影响,适用于需要高质量文本生成的领域。
使用文本生成图像
DALL・E 是一个使用文本描述生成图像的神经网络模型。它能够根据自然语言描述生成逼真的图像,并具有多种功能,如创建动物和物体的拟人化版本,将不相关的概念合理地组合在一起,渲染文本并对现有图像应用变换。DALL・E 能够应用于多个领域,具有广泛的应用前景。
LG AI Research开发的双语文本生成模型
EXAONE-3.5-2.4B-Instruct-GGUF是由LG AI Research开发的一系列双语(英语和韩语)指令调优的生成型模型,参数范围从2.4B到32B。这些模型支持长达32K令牌的长上下文处理,并在真实世界用例和长上下文理解方面展现出最先进的性能,同时在与近期发布的类似大小模型相比,在通用领域保持竞争力。该模型的重要性在于其优化了在小型或资源受限设备上的部署,同时提供了强大的性能。
多功能文本生成工具
文心大模型包含文本生成、文生图、智能对话等技能,可用于文化传媒、艺术创作、教育科研、金融保险、医疗健康等多个应用场景。该产品具有高效、智能、多样化等优势,定价灵活,适用于个人用户和企业用户。
LG AI Research开发的双语文本生成模型
EXAONE-3.5-2.4B-Instruct-AWQ是由LG AI Research开发的一系列双语(英语和韩语)指令调优生成模型,参数范围从2.4B到32B。这些模型支持长达32K令牌的长上下文处理,并且在真实世界用例和长上下文理解方面展现出最先进的性能,同时在与近期发布的类似大小模型相比,在通用领域保持竞争力。该模型在部署到小型或资源受限设备上进行了优化,并且采用了AWQ量化技术,实现了4位群组权重量化(W4A16g128)。
大型语言模型,高效文本生成。
InternLM2.5-7B-Chat GGUF是一个大型语言模型,专为文本生成而设计。它基于开源框架llama.cpp,支持多种硬件平台的本地和云推理。该模型具有7.74亿参数,采用先进的架构设计,能够提供高质量的文本生成服务。
朱雀大模型检测,精准识别AI生成图像,助力内容真实性鉴别。
朱雀大模型检测是腾讯推出的一款AI检测工具,主要功能是检测图片是否由AI模型生成。它经过大量自然图片和生成图片的训练,涵盖摄影、艺术、绘画等内容,可检测多类主流文生图模型生成图片。该产品具有高精度检测、快速响应等优点,对于维护内容真实性、打击虚假信息传播具有重要意义。目前暂未明确其具体价格,但从功能来看,主要面向需要进行内容审核、鉴别真伪的机构和个人,如媒体、艺术机构等。
基于文本生成图像的多模态扩散变换器模型
Stable Diffusion 3.5 Medium是一个基于文本到图像的生成模型,由Stability AI开发,具有改进的图像质量、排版、复杂提示理解和资源效率。该模型使用了三个固定的预训练文本编码器,通过QK-规范化提高训练稳定性,并在前12个变换层中引入双注意力块。它在多分辨率图像生成、一致性和各种文本到图像任务的适应性方面表现出色。
AI社交媒体文本生成器
QuickWit是一款由AI驱动的社交媒体文本生成器,让您在网上表现得更机智。即时获取文本消息回复、社交媒体标题、表情包等的灵感。只需扫描一张照片,滑动选择有趣的角色滤镜,让您的声音变得随心所欲。
基于大型语言模型的文本生成工具
TextSynth是一个基于大型语言模型的文本生成工具。它使用Falcon 7B和Llama2 7B等先进的语言模型,可以帮助用户完成文本的自动补全和生成。无论是写作、聊天还是翻译,TextSynth都能提供准确、流畅的文本输出。它支持多种语言和领域,具有强大的功能和灵活的参数设置。TextSynth是提高生产力和创造力的理想工具。
先进的文本生成模型
OLMo-2-1124-13B-SFT是由Allen AI研究所开发的一个大型语言模型,经过在特定数据集上的监督微调,旨在提高在多种任务上的表现,包括聊天、数学问题解答、文本生成等。该模型基于Transformers库和PyTorch框架,支持英文,拥有Apache 2.0的开源许可证,适用于研究和教育用途。
轻量级、先进的文本生成模型
Gemma是由Google开发的一系列轻量级、先进的开放模型,基于与Gemini模型相同的研究和技术构建。它们是文本到文本的解码器仅大型语言模型,适用于多种文本生成任务,如问答、摘要和推理。Gemma模型的相对较小的尺寸使其能够在资源有限的环境中部署,如笔记本电脑、桌面或您自己的云基础设施,使每个人都能接触到最先进的AI模型,并促进创新。
高性能英文文本生成模型
OLMo-2-1124-7B-SFT是由艾伦人工智能研究所(AI2)发布的一个英文文本生成模型,它是OLMo 2 7B模型的监督微调版本,专门针对Tülu 3数据集进行了优化。Tülu 3数据集旨在提供多样化任务的顶尖性能,包括聊天、数学问题解答、GSM8K、IFEval等。该模型的主要优点包括强大的文本生成能力、多样性任务处理能力以及开源的代码和训练细节,使其成为研究和教育领域的有力工具。
稳定代码3B - 用于文本生成的预训练语言模型
Stable Code 3B是一个拥有27亿参数的仅解码器语言模型,预训练于1300亿个多样的文本和代码数据标记。Stable Code 3B在18种编程语言上进行了训练,并在使用BigCode的评估工具进行测试时,在多种编程语言上展现出与同等规模模型相比的最先进性能。它支持长上下文,使用了长度达16384的序列进行训练,并具有填充中间功能(FIM)。用户可以通过Hugging Face网站上的代码片段开始使用Stable Code 3B生成文本。该模型由Stability AI开发,基于GPT-NeoX库,可用于英文和编程语言。
70亿参数的量化文本生成模型
Llama-Lynx-70b-4bit-Quantized是由PatronusAI开发的一个大型文本生成模型,具有70亿参数,并且经过4位量化处理,以优化模型大小和推理速度。该模型基于Hugging Face的Transformers库构建,支持多种语言,特别是在对话生成和文本生成领域表现出色。它的重要性在于能够在保持较高性能的同时减少模型的存储和计算需求,使得在资源受限的环境中也能部署强大的AI模型。
基于文本生成高质量图像的AI模型
SD3.5-LoRA-Linear-Red-Light是一个基于文本到图像生成的AI模型,通过使用LoRA(Low-Rank Adaptation)技术,该模型能够根据用户提供的文本提示生成高质量的图像。这种技术的重要性在于它能够以较低的计算成本实现模型的微调,同时保持生成图像的多样性和质量。该模型基于Stable Diffusion 3.5 Large模型,并在此基础上进行了优化和调整,以适应特定的图像生成需求。
交互式对话AI模型,提供问答和文本生成服务
ChatGPT是由OpenAI训练的对话生成模型,能够以对话形式与人互动,回答后续问题,承认错误,挑战错误的前提,并拒绝不适当的请求。OpenAI日前买下了http://chat.com域名,该域名已经指向了ChatGPT。ChatGPT它是InstructGPT的姊妹模型,后者被训练以遵循提示中的指令并提供详细的回答。ChatGPT代表了自然语言处理技术的最新进展,其重要性在于能够提供更加自然和人性化的交互体验。产品背景信息包括其在2022年11月30日的发布,以及在研究预览期间免费提供给用户使用。
AI生成的图片、文本生成器
AltText.ai是一款利用人工智能自动生成图片Alt文本的工具。它可以集成到WordPress、Shopify、WooCommerce、Chrome和Contentful等平台中,为您的网站提供自动生成的Alt文本。AltText.ai支持超过130种语言,提供WordPress插件、CMS集成、开发者API和网页界面等多种方式使用。

© 2026 AIbase 备案号:闽ICP备08105208号-14