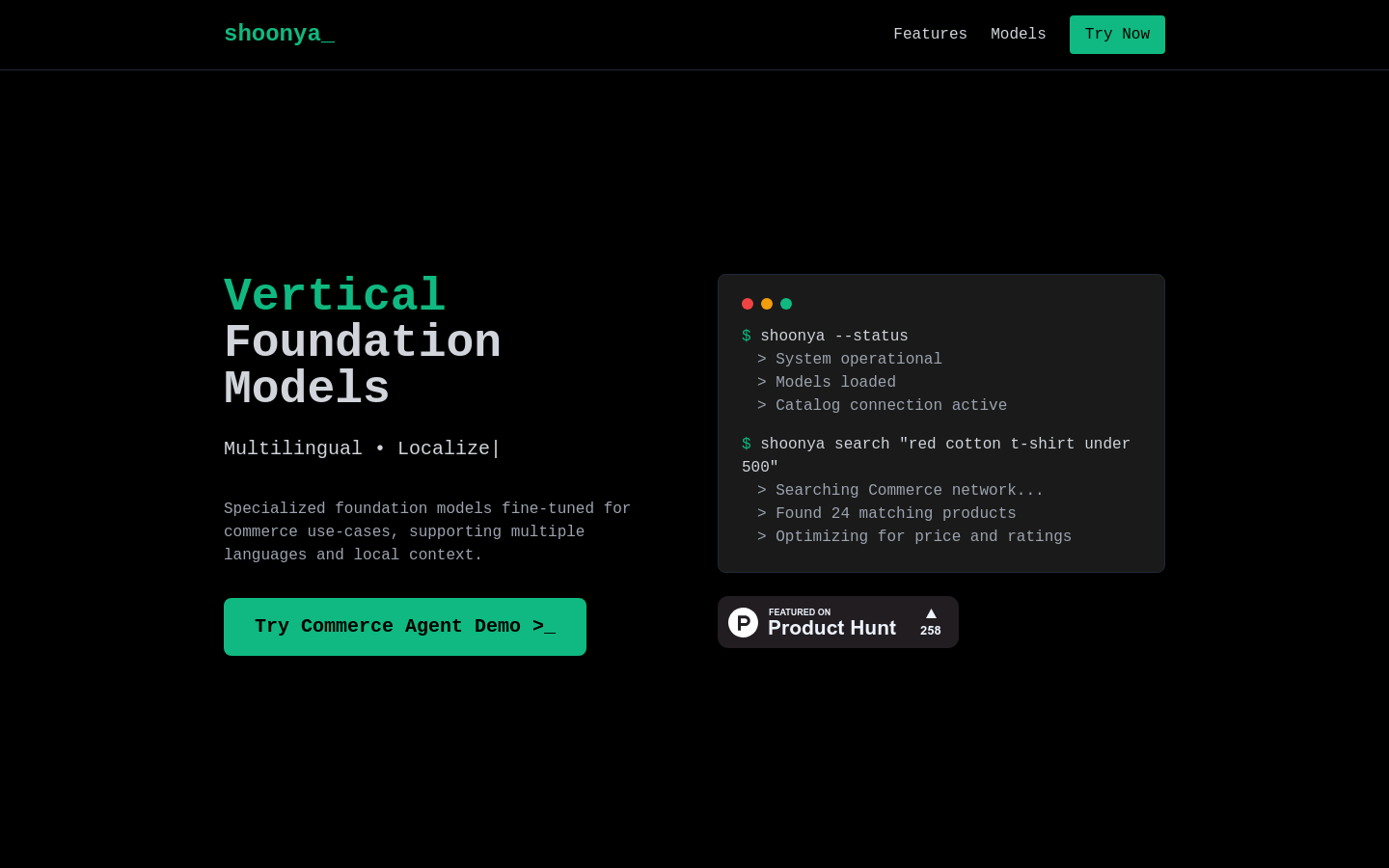
shoonya是一个专注于现代商业领域的基础模型与代理,提供多语言支持、本地化服务和针对特定商业垂直领域的优化。它通过为电子商务用例特别调整的基础模型,支持多种语言和本地上下文,以推动下一代零售业务的发展。shoonya的技术背景是基于人工智能和机器学习,旨在理解和优化区域商业模式、术语和偏好,为用户提供更加个性化和高效的购物体验。
需求人群:
"目标受众为电子商务平台、零售商和本地卖家,特别是那些寻求通过人工智能技术提升用户体验和销售效率的企业。shoonya通过理解用户的自然语言查询,帮助他们快速找到所需商品,同时支持多种语言,使其能够服务于更广泛的用户群体。"
使用场景示例:
用户通过自然语言搜索‘500元以下的红色棉质T恤’,shoonya能够快速找到匹配的商品。
本地卖家利用shoonya的ONDC语音购物演示,通过印度各种语言搜索本地产品。
零售商使用shoonya的目录搜索代理功能,为顾客提供更加个性化的购物体验。
产品特色:
多语言支持:从基础构建起支持多种语言和混合语言查询。
领域专业化:为特定商业垂直领域和用例优化的精细调整模型。
本地化上下文:深入理解区域商业模式、术语和偏好。
目录搜索代理:支持ONDC搜索演示,为用户提供商品搜索服务。
产品分类:即将推出,针对商品进行分类的功能。
语义产品匹配:即将推出,通过语义分析匹配产品的功能。
使用教程:
1. 访问shoonya官网并了解产品特性。
2. 注册并获取API访问权限。
3. 根据需要选择合适的模型进行集成。
4. 使用shoonya提供的API进行商品搜索和产品匹配。
5. 利用多语言和本地化功能,为用户提供个性化服务。
6. 监控系统状态,确保模型加载和目录连接处于活跃状态。
7. 通过shoonya的接口,实现语音购物和产品搜索功能。
8. 分析搜索结果,优化产品展示和用户体验。
浏览量:50
最新流量情况
月访问量
578
平均访问时长
00:01:14
每次访问页数
3.20
跳出率
31.14%
流量来源
直接访问
28.27%
自然搜索
15.20%
邮件
0.05%
外链引荐
51.79%
社交媒体
3.00%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
印度
100.00%
人工智能入门教程网站,提供全面的机器学习与深度学习知识。
该网站由作者从 2015 年开始学习机器学习和深度学习,整理并编写的一系列实战教程。涵盖监督学习、无监督学习、深度学习等多个领域,既有理论推导,又有代码实现,旨在帮助初学者全面掌握人工智能的基础知识和实践技能。网站拥有独立域名,内容持续更新,欢迎大家关注和学习。
提供AI和机器学习课程
Udacity人工智能学院提供包括深度学习、计算机视觉、自然语言处理和AI产品管理在内的AI培训和机器学习课程。这些课程旨在帮助学生掌握人工智能领域的最新技术,为未来的职业生涯打下坚实的基础。
多语言大型语言模型
Llama 3.2是由Meta公司推出的多语言大型语言模型(LLMs),包含1B和3B两种规模的预训练和指令调优生成模型。这些模型在多种语言对话用例中进行了优化,包括代理检索和总结任务。Llama 3.2在许多行业基准测试中的表现优于许多现有的开源和封闭聊天模型。
多语言大型语言模型,支持23种语言
Aya Expanse 32B是由Cohere For AI开发的多语言大型语言模型,拥有32亿参数,专注于提供高性能的多语言支持。它结合了先进的数据仲裁、多语言偏好训练、安全调整和模型合并技术,以支持23种语言,包括阿拉伯语、中文(简体和繁体)、捷克语、荷兰语、英语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、韩语、波斯语、波兰语、葡萄牙语、罗马尼亚语、俄语、西班牙语、土耳其语、乌克兰语和越南语。该模型的发布旨在使社区基础的研究工作更加易于获取,通过发布高性能的多语言模型权重,供全球研究人员使用。
多语言聊天机器人
Giti多语言聊天机器人是一款智能聊天机器人,支持100多种语言,具备自然流畅的对话能力。它可以理解您的母语并与您进行智能对话。无论您想聊天、咨询问题还是寻求娱乐,Giti都能为您提供准确、有趣的回答。
Phind是一款先进的人工智能搜索工具,支持多语言和多搜索功能。
Phind是一款基于人工智能的先进搜索工具,能够通过多轮对话和多语言支持帮助用户快速获取信息。它支持多种搜索方式,包括文本、语音和图像搜索,能够提供更精准的搜索结果。Phind的主要优点是其强大的自然语言处理能力和多语言支持,能够满足不同用户的需求。该产品定位为高端智能搜索工具,适合需要高效获取信息的用户。
多语言指令微调的大型语言模型
Aya-23-8B是由Cohere For AI开发的指令微调模型,具有23种语言的强大多语言能力,专注于将高性能预训练模型与Aya Collection结合,为研究人员提供高性能的多语言模型。
多语言AI模型,支持101种语言。
Aya是由Cohere For AI领导的全球性倡议,涉及119个国家的3000多名独立研究人员。Aya是一个尖端模型和数据集,通过开放科学推进101种语言的多语言AI。Aya模型能够理解并按照101种语言的指令执行任务,是迄今为止最大的开放科学机器学习项目之一,重新定义了研究领域,通过与全球独立研究人员合作,实现了完全开源的数据集和模型。
智能漫画翻译工具,快速准确多语言翻译。
AI Comic Translate是一款利用先进人工智能技术,为漫画爱好者和创作者提供快速准确的多语言翻译服务的智能工具。它具有成本效益高、易于使用、支持多种语言翻译等主要特点。该产品通过自动化翻译流程,大幅节省了翻译时间和成本,同时提供了用户友好的界面设计,使得无论是专业翻译者还是漫画爱好者都能轻松使用。
多语言生成语言模型
Aya模型是一个大规模的多语言生成性语言模型,能够在101种语言中遵循指令。该模型在多种自动和人类评估中优于mT0和BLOOMZ,尽管它覆盖的语言数量是后者的两倍。Aya模型使用包括xP3x、Aya数据集、Aya集合、DataProvenance集合的一个子集和ShareGPT-Command等多个数据集进行训练,并在Apache-2.0许可下发布,以推动多语言技术的发展。
智能AI聊天助手,提供多语言对话和个性化服务。
Ai Chat机器人Plus是一款基于人工智能技术的聊天机器人,它能够理解并流畅地与用户进行交流,提供信息查询、日常咨询、技术支持等服务。这款产品通过模仿人类的对话方式,为用户提供了一个直观、便捷的交互体验。它主要的优点包括快速响应、高准确率的语义理解以及个性化的服务体验。Ai Chat机器人Plus适用于需要快速、智能对话解决方案的个人和企业用户。
推动人工智能安全治理,促进技术健康发展
《人工智能安全治理框架》1.0版是由全国网络安全标准化技术委员会发布的技术指南,旨在鼓励人工智能创新发展的同时,有效防范和化解人工智能安全风险。该框架提出了包容审慎、确保安全,风险导向、敏捷治理,技管结合、协同应对,开放合作、共治共享等原则。它结合人工智能技术特性,分析风险来源和表现形式,针对模型算法安全、数据安全和系统安全等内生安全风险,以及网络域、现实域、认知域、伦理域等应用安全风险,提出了相应的技术应对和综合防治措施。
多语言聊天机器人,支持100多种语言
Giti多语言聊天机器人是一款先进的多语言AI聊天机器人,采用最新的GPT-3模型。支持100多种语言,可以自然流畅地进行对话。Giti.ai可以让您与能够理解您母语的智能聊天机器人对话。
开源的多语言代码生成模型
CodeGeeX4-ALL-9B是CodeGeeX4系列模型的最新开源版本,基于GLM-4-9B持续训练,显著提升了代码生成能力。它支持代码补全、生成、代码解释、网页搜索、函数调用、代码问答等功能,覆盖软件开发的多个场景。在公共基准测试如BigCodeBench和NaturalCodeBench上表现优异,是参数少于10亿的最强代码生成模型,实现了推理速度与模型性能的最佳平衡。
快速、多语言支持的OCR工具包
RapidOCR是一个基于ONNXRuntime、OpenVINO和PaddlePaddle的OCR多语言工具包。它将PaddleOCR模型转换为ONNX格式,支持Python/C++/Java/C#等多平台部署,具有快速、轻量级、智能的特点,并解决了PaddleOCR内存泄露的问题。
MuLan:为110多种语言适配多语言扩散模型
MuLan是一个开源的多语言扩散模型,旨在为超过110种语言提供无需额外训练即可使用的扩散模型支持。该模型通过适配技术,使得原本需要大量训练数据和计算资源的扩散模型能够快速适应新的语言环境,极大地扩展了扩散模型的应用范围和语言多样性。MuLan的主要优点包括对多种语言的支持、优化的内存使用、以及通过技术报告和代码模型的发布,为研究人员和开发者提供了丰富的资源。
口袋里的人工智能语言辅导员
Univerbal是一个提供多语言教学服务的平台,通过人工智能技术,用户可以在线学习并练习多种语言。该平台汇集了来自世界各地的语言讲师,提供个性化的语言学习体验。Univerbal以其便捷性、高效性和互动性为主要优点,适合忙碌的现代生活节奏,让用户随时随地都能学习新语言。目前产品提供免费试用,具体价格和定位信息需进一步了解。
智能助手,提供多语言对话和文件处理服务。
Claude是一个多功能的智能助手,它能够以自然语言处理技术为基础,提供流畅的中英文对话体验。它支持长文本输入和输出,能够处理多种文件格式,包括TXT、PDF、Word文档、PPT幻灯片和Excel电子表格。它是由Anthropic开发的,旨在通过人工智能技术提升用户的工作效率和生活质量。
真实对话的人工智能语言学习助手
Lingostar是一款可以用英语、西班牙语或法语与之对话的人工智能语言学习助手。通过与Lingostar进行真实对话,提高发音、词汇和理解能力,达到流利的口语表达。无需导师,随时随地与Lingostar聊天,它会根据你的错误构建个性化学习计划。免费试用。
提供关于人工智能的最佳资源,学习机器学习、数据科学、自然语言处理等。
AI Online Course是一个互动学习平台,提供清晰简明的人工智能介绍,使复杂的概念易于理解。它涵盖机器学习、深度学习、计算机视觉、自动驾驶、聊天机器人等方面的知识,并强调实际应用和技术优势。
多语言视觉文本渲染的强有力美学基线
Glyph-ByT5-v2 是微软亚洲研究院推出的一个用于准确多语言视觉文本渲染的模型。它不仅支持10种不同语言的准确视觉文本渲染,而且在美学质量上也有显著提升。该模型通过创建高质量的多语言字形文本和平面设计数据集,构建多语言视觉段落基准,并利用最新的步态感知偏好学习方法来提高视觉美学质量。
Qwen1.5系列首个千亿参数开源模型,多语言支持,高效Transformer解码器架构。
Qwen1.5-110B是Qwen1.5系列中规模最大的模型,拥有1100亿参数,支持多语言,采用高效的Transformer解码器架构,并包含分组查询注意力(GQA),在模型推理时更加高效。它在基础能力评估中与Meta-Llama3-70B相媲美,在Chat评估中表现出色,包括MT-Bench和AlpacaEval 2.0。该模型的发布展示了在模型规模扩展方面的巨大潜力,并且预示着未来通过扩展数据和模型规模,可以获得更大的性能提升。
轻松实现多语言翻译
Plane是一款基于人工智能技术的多语言翻译工具。它可以快速准确地将文本翻译成多种语言,帮助用户在跨语言交流中解决语言障碍。该助手具有高度的准确性和实时性,同时支持多种语言的互译功能。用户可以通过输入文本或上传文件进行翻译,还可以保存翻译记录和设置常用语言,提高翻译效率。
大规模多语言文本数据集
allenai/tulu-3-sft-olmo-2-mixture是一个大规模的多语言数据集,包含了用于训练和微调语言模型的多样化文本样本。该数据集的重要性在于它为研究人员和开发者提供了丰富的语言资源,以改进和优化多语言AI模型的性能。产品背景信息包括其由多个来源的数据混合而成,适用于教育和研究领域,且遵循特定的许可协议。
多语言模型问答助手
Snack AI是一款多语言模型问答助手,可以同时向多个语言模型提问并获取答案。它能够帮助用户快速获取准确的信息,并提供丰富的功能和使用场景。Snack AI的定价灵活多样,适合个人用户和企业用户的不同需求。

© 2026 AIbase 备案号:闽ICP备08105208号-14