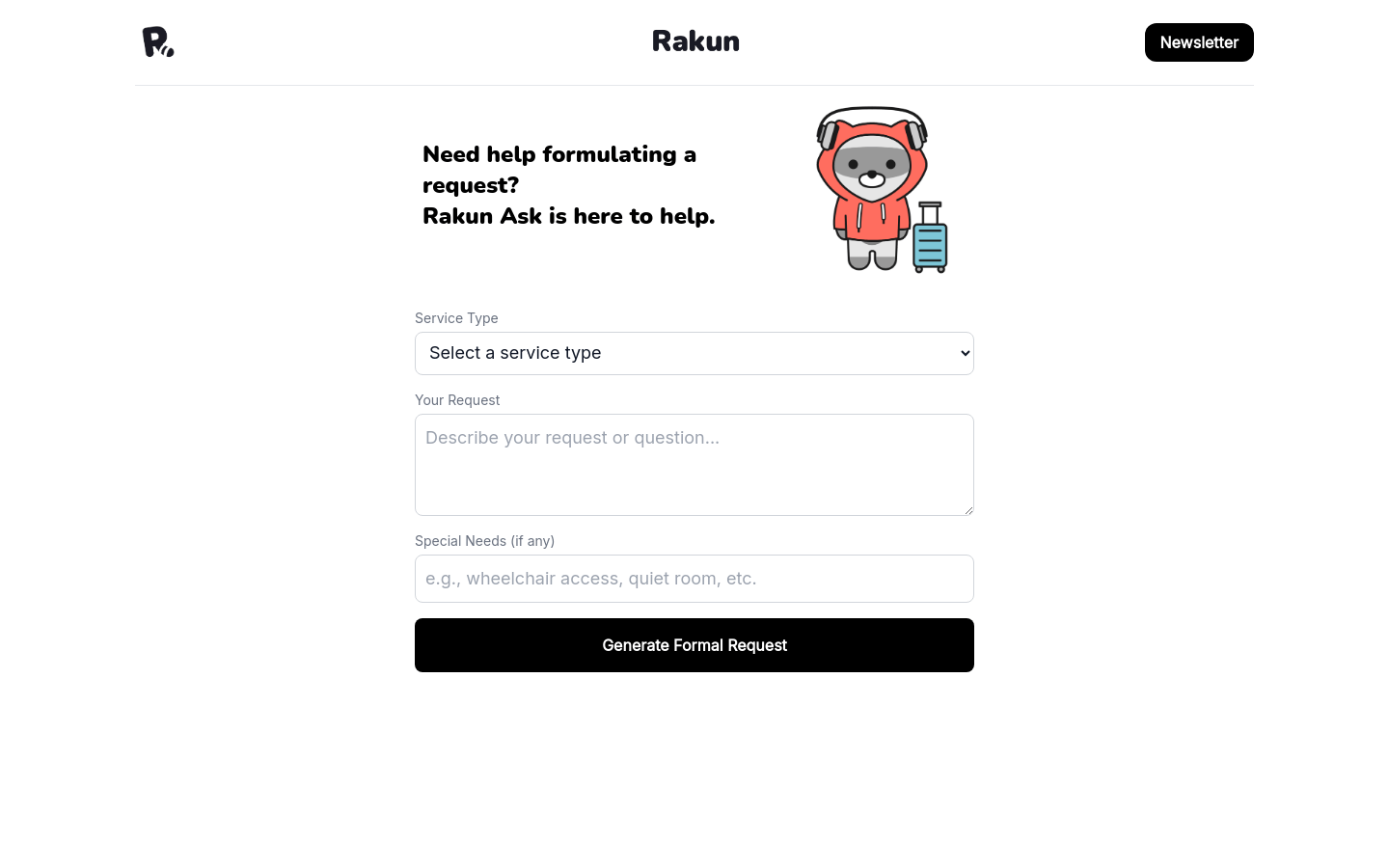
Rakun Ask是一个在线服务,旨在帮助用户快速制定正式请求。它提供了一个简洁的用户界面,让用户能够输入服务类型、请求内容以及特殊需求,从而生成一份正式的请求文档。
需求人群:
"Rakun Ask适合需要快速制定正式请求的用户,无论是个人还是企业,特别是在需要专业文档支持的商业或法律领域。"
使用场景示例:
一位律师需要为客户制定一份正式的法律请求
一个项目经理需要向供应商发出项目需求文档
一个学生需要向学校提交特殊需求的申请
产品特色:
用户可以输入服务类型来定制请求
用户可以详细描述他们的请求内容
用户可以填写特殊需求以获得更个性化的帮助
系统将根据用户输入生成正式的请求文档
用户可以方便地下载或分享生成的请求文档
支持多种语言,使得不同语言背景的用户都能使用
使用教程:
访问Rakun Ask网站
选择服务类型
输入您的请求内容
填写任何特殊需求
点击生成按钮来创建正式请求
下载或分享生成的请求文档
浏览量:35
个性化AI学习平台,为您定制课程,提供互动跟踪和多语言支持。
Breni是一款AI学习应用,通过根据用户兴趣和目标收集相关内容来创建个性化课程。它提供各种主题的课程,如编码、商业和营销,具有交互式进度跟踪、多语言支持和可定制的导师风格。该平台允许用户设定学习目标,接收通知以保持在正确轨道上,提供适应个人需求的定制教育体验。
Speakoala可将网页和本地文档转为自然语音,支持多语言
Speakoala是一款文字转语音(TTS)插件,可将网页、本地文档等内容以自然逼真的语音朗读出来。它支持70多种语言,包括英语、中文、日语等。其主要优点在于提供自然的语音、多语言支持、多种播放方式(如选区域、选文本播放)。产品免费版提供机器人语音,升级到付费版每月4.99美元可获得数十种自然语音。该产品定位于辅助用户在忙碌时或需要减少视觉疲劳时能够轻松获取文字信息,适用于通勤、锻炼等场景。
智能AI翻译,高效文档语言转换助手。
EZ-work AI文档翻译是一款专注于文档翻译的在线服务,支持多种语言的翻译,包括中文、英语、日语、俄语、阿拉伯语和西班牙语等。它使用先进的AI技术,如gpt-4o-mini和deepseek-chat模型,为用户提供快速、准确的翻译服务。该产品适用于需要文档翻译的个人和企业,尤其在国际交流和学术研究领域尤为重要。
多语言对话生成模型
Meta Llama 3.1是一系列预训练和指令调整的多语言大型语言模型(LLMs),支持8种语言,专为对话使用案例优化,并通过监督式微调(SFT)和人类反馈的强化学习(RLHF)来提高安全性和有用性。
现代国际化平台,快速实现产品多语言支持。
Quetzal是一个现代国际化平台,旨在帮助用户快速将产品翻译成多种语言,以获得全球新客户。该平台提供工具,支持20多种语言,与Next.js和React兼容,并且拥有快速设置流程,仅需约10分钟。Quetzal利用人工智能技术,结合应用程序的上下文,在几分钟内实现最佳翻译效果。它还提供了一个仪表板,让用户可以在一个地方查看和管理所有的字符串。产品背景信息显示,Quetzal由Quetzal Labs, Inc.在奥克兰精心打造,并且提供了一个慷慨的免费计划,直到用户添加第二种语言。
大型语言模型,支持多语言和编程语言文本生成。
Nemotron-4-340B-Base是由NVIDIA开发的大型语言模型,拥有3400亿参数,支持4096个token的上下文长度,适用于生成合成数据,帮助研究人员和开发者构建自己的大型语言模型。模型经过9万亿token的预训练,涵盖50多种自然语言和40多种编程语言。NVIDIA开放模型许可允许商业使用和派生模型的创建与分发,不声明对使用模型或派生模型生成的任何输出拥有所有权。
智能AI语音代理,自然对话,多语言支持,用于业务通话自动化。
NexaVoxa是一款智能AI语音代理产品,旨在优化销售流程、自动化排程和提升客户支持体验。其主要优点包括自然对话、多语言支持以及企业级可扩展性。
Qwen1.5系列首个千亿参数开源模型,多语言支持,高效Transformer解码器架构。
Qwen1.5-110B是Qwen1.5系列中规模最大的模型,拥有1100亿参数,支持多语言,采用高效的Transformer解码器架构,并包含分组查询注意力(GQA),在模型推理时更加高效。它在基础能力评估中与Meta-Llama3-70B相媲美,在Chat评估中表现出色,包括MT-Bench和AlpacaEval 2.0。该模型的发布展示了在模型规模扩展方面的巨大潜力,并且预示着未来通过扩展数据和模型规模,可以获得更大的性能提升。
多语言大型语言模型,优化对话场景。
Meta Llama 3.1是一系列多语言的大型预训练和指令调整的生成模型,包含8B、70B和405B大小的版本。这些模型专为多语言对话用例而优化,并在常见行业基准测试中表现优于许多开源和闭源聊天模型。模型使用优化的transformer架构,并通过监督式微调(SFT)和强化学习与人类反馈(RLHF)进行调整,以符合人类对有用性和安全性的偏好。
快速、多语言支持的OCR工具包
RapidOCR是一个基于ONNXRuntime、OpenVINO和PaddlePaddle的OCR多语言工具包。它将PaddleOCR模型转换为ONNX格式,支持Python/C++/Java/C#等多平台部署,具有快速、轻量级、智能的特点,并解决了PaddleOCR内存泄露的问题。
大型语言模型,支持多语言和代码数据
Mistral-Nemo-Instruct-2407是由Mistral AI和NVIDIA联合训练的大型语言模型(LLM),是Mistral-Nemo-Base-2407的指导微调版本。该模型在多语言和代码数据上进行了训练,显著优于大小相似或更小的现有模型。其主要特点包括:支持多语言和代码数据训练、128k上下文窗口、可替代Mistral 7B。模型架构包括40层、5120维、128头维、1436隐藏维、32个头、8个kv头(GQA)、2^17词汇量(约128k)、旋转嵌入(theta=1M)。该模型在多种基准测试中表现出色,如HellaSwag(0-shot)、Winogrande(0-shot)、OpenBookQA(0-shot)等。
AI多语言文档翻译工具
PDF Translator是一款AI工具,可以翻译各种类型的文档,包括原生和扫描的PDF文件,jpeg、png和heif格式的图片,以及Microsoft Word、Excel和PowerPoint文件。附加功能包括PDF编辑、PDF转照片、照片转PDF、扫描转PDF和PDF拆分。拥有136种不同语言的翻译服务,可以在不损害原始文件格式或布局的情况下提供高质量的翻译。该工具使用由Google和Microsoft提供支持的神经机器翻译(NMT)模型,提供高效可靠的翻译服务。通过利用这些AI能力,PDF Translator确保翻译文本准确有效,适用于各种语言。简单易用的界面使得快速轻松的翻译成为可能,对于专业人士、研究人员和学生来说是一种有用的工具,使他们能够轻松地以自己偏好的语言获取信息。总的来说,PDF Translator是一款强大的AI工具,利用NMT模型在各种文档类型和语言之间实现无缝翻译,是企业和个人快速有效翻译文件的理想选择。
AI驱动的多语言翻译平台,支持文档、图片和视频翻译。
Transmonkey是一个AI驱动的在线翻译平台,支持超过130种语言的文档、图片和视频翻译。该平台利用大型语言模型提供高精度的翻译服务,同时保持文件原有格式和布局。Transmonkey以其高效的翻译速度、广泛的文件格式支持和用户友好的操作界面受到用户青睐。产品背景信息显示,Transmonkey致力于打破语言障碍,提升用户的数字体验。价格方面,Transmonkey提供免费试用,并有付费订阅服务。
多语言晚交互检索模型,支持嵌入和重排
Jina ColBERT v2是一个先进的晚交互检索模型,基于ColBERT架构构建,支持89种语言,并提供优越的检索性能、用户可控的输出维度和长达8192个token的文本处理能力。它在信息检索领域具有革命性的意义,通过晚交互评分近似于交叉编码器中的联合查询-文档注意力,同时保持了接近传统密集检索模型的推理效率。
多语言嵌入模型,用于视觉文档检索。
vdr-2b-multi-v1 是一款由 Hugging Face 推出的多语言嵌入模型,专为视觉文档检索设计。该模型能够将文档页面截图编码为密集的单向量表示,无需 OCR 或数据提取流程即可搜索和查询多语言视觉丰富的文档。基于 MrLight/dse-qwen2-2b-mrl-v1 开发,使用自建的多语言查询 - 图像对数据集进行训练,是 mcdse-2b-v1 的升级版,性能更强大。模型支持意大利语、西班牙语、英语、法语和德语,拥有 50 万高质量样本的开源多语言合成训练数据集,具有低 VRAM 和快速推理的特点,在跨语言检索方面表现出色。
多语言文本转语音在线平台
Free Text to Speech Online Converter是一个多语言文本转语音的在线平台。它支持超过20种语言,拥有自然的发音,无需注册即可免费使用,转换速度快。
多语言大型语言模型,优化对话和文本生成。
Meta Llama 3.1是一系列预训练和指令调整的多语言大型语言模型(LLMs),包含8B、70B和405B三种大小的模型,专门针对多语言对话使用案例进行了优化,并在行业基准测试中表现优异。该模型使用优化的transformer架构,并通过监督式微调(SFT)和人类反馈的强化学习(RLHF)进一步与人类偏好对齐,以确保其有用性和安全性。
AI视频编辑工具,支持多语言和轻松分享
Loomos是一个AI视频编辑平台,可以将原始屏幕录像快速转换成高质量的视频。它通过AI技术编辑字幕,去除多余的“嗯”和“啊”,并提供20多种语言的翻译和专业的AI配音。这个平台特别适合需要快速制作专业视频演示、广告和销售视频的用户。Loomos提供了多种定价计划,满足不同用户的需求,从免费计划到企业定制计划,用户可以根据自己的预算和需求选择合适的服务。
免费AI文档翻译工具,保留格式、双语对照,支持多格式多语言。
Doclingo是一款基于AI的专业文档翻译工具,旨在为全球用户提供高效、准确的文档翻译服务。其重要性在于解决了传统翻译工具在处理专业术语、复杂句式以及文档格式保留方面的难题。产品主要优点包括支持90种语言、格式完美还原、集成主流AI引擎、支持多格式文档和批量翻译等。该产品有免费版和PRO版,免费版永久免费,支持基础文档的高质量翻译;PRO版针对科研专业文档,支持复杂格式处理和AI增强功能。产品定位为满足不同用户群体的文档翻译需求,无论是科研工作者、企业员工还是普通学习者都能从中受益。
多语言高质量文本转语音库
MeloTTS是由MyShell.ai开发的多语言文本转语音库,支持英语、西班牙语、法语、中文、日语和韩语。它能够实现实时CPU推理,适用于多种场景,并且对开源社区开放,欢迎贡献。
最先进的12B模型,支持多语言应用
Mistral NeMo 是由 Mistral AI 与 NVIDIA 合作构建的 12B 模型,具有 128k 个令牌的大型上下文窗口。它在推理、世界知识和编码准确性方面处于领先地位。该模型专为全球多语言应用程序设计,支持英语、法语、德语、西班牙语、意大利语、葡萄牙语、中文、日语、韩语、阿拉伯语和印地语等多种语言。Mistral NeMo 还使用了新的分词器 Tekken,提高了文本和源代码的压缩效率。此外,该模型经过指令微调,提升了遵循精确指令、推理、处理多轮对话和生成代码的能力。
在线文本转语音工具,支持多语言和自然发音。
TTSynth.com是一个免费的在线文本转语音(TTS)生成器,它使用先进的AI技术将书面文本转换为自然发音的语音。该服务支持多种语言和口音,适用于全球用户。它提供了高质量的音频输出,并且用户可以轻松下载TTS MP3文件。TTS技术在教育、营销、无障碍解决方案等多个领域都有广泛的应用。
最新的视觉语言模型,支持多语言和多模态理解
Qwen2-VL-72B是Qwen-VL模型的最新迭代,代表了近一年的创新成果。该模型在视觉理解基准测试中取得了最新的性能,包括MathVista、DocVQA、RealWorldQA、MTVQA等。它能够理解超过20分钟的视频,并可以集成到手机、机器人等设备中,进行基于视觉环境和文本指令的自动操作。除了英语和中文,Qwen2-VL现在还支持图像中不同语言文本的理解,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。模型架构更新包括Naive Dynamic Resolution和Multimodal Rotary Position Embedding (M-ROPE),增强了其多模态处理能力。
Voe 4是AI视频生成器,可快速文本转视频、图像转视频,支持多语言。
Voe 4是一款由Voe 4.0 AI Video驱动的AI视频生成器,可在线免费使用。其核心优势在于生成速度极快,仅需约2秒就能创建视频,同时依靠Voe 4.0模型保证视频的高保真度。该产品支持100种语言,能保持原始布局,具备快速且准确的特点。在价格方面,有年度计划,当前有限时优惠,可享受50%的折扣。其定位是为创作者提供专业级的视频生成和图像编辑解决方案,助力他们更高效地完成创作。
高分辨率、多语言支持的文本到图像生成模型
Sana是一个由NVIDIA开发的文本到图像的框架,能够高效生成高达4096×4096分辨率的图像。该模型以惊人的速度合成高分辨率、高质量的图像,并保持强大的文本-图像对齐能力,可部署在笔记本电脑GPU上。Sana模型基于线性扩散变换器,使用预训练的文本编码器和空间压缩的潜在特征编码器,支持Emoji、中文和英文以及混合提示。
Digen AI提供免费AI视频生成器,可将图像轻松转换为专业视频,支持逼真的嘴唇同步、多语言支持和智能动画技术。
Digen AI是一款免费AI视频生成器,使用智能技术将图像转换为高质量视频。产品背景丰富,主打逼真嘴唇同步和多语言支持,为用户提供轻松创建专业视频的功能。
智能漫画翻译工具,快速准确多语言翻译。
AI Comic Translate是一款利用先进人工智能技术,为漫画爱好者和创作者提供快速准确的多语言翻译服务的智能工具。它具有成本效益高、易于使用、支持多种语言翻译等主要特点。该产品通过自动化翻译流程,大幅节省了翻译时间和成本,同时提供了用户友好的界面设计,使得无论是专业翻译者还是漫画爱好者都能轻松使用。

© 2026 AIbase 备案号:闽ICP备08105208号-14