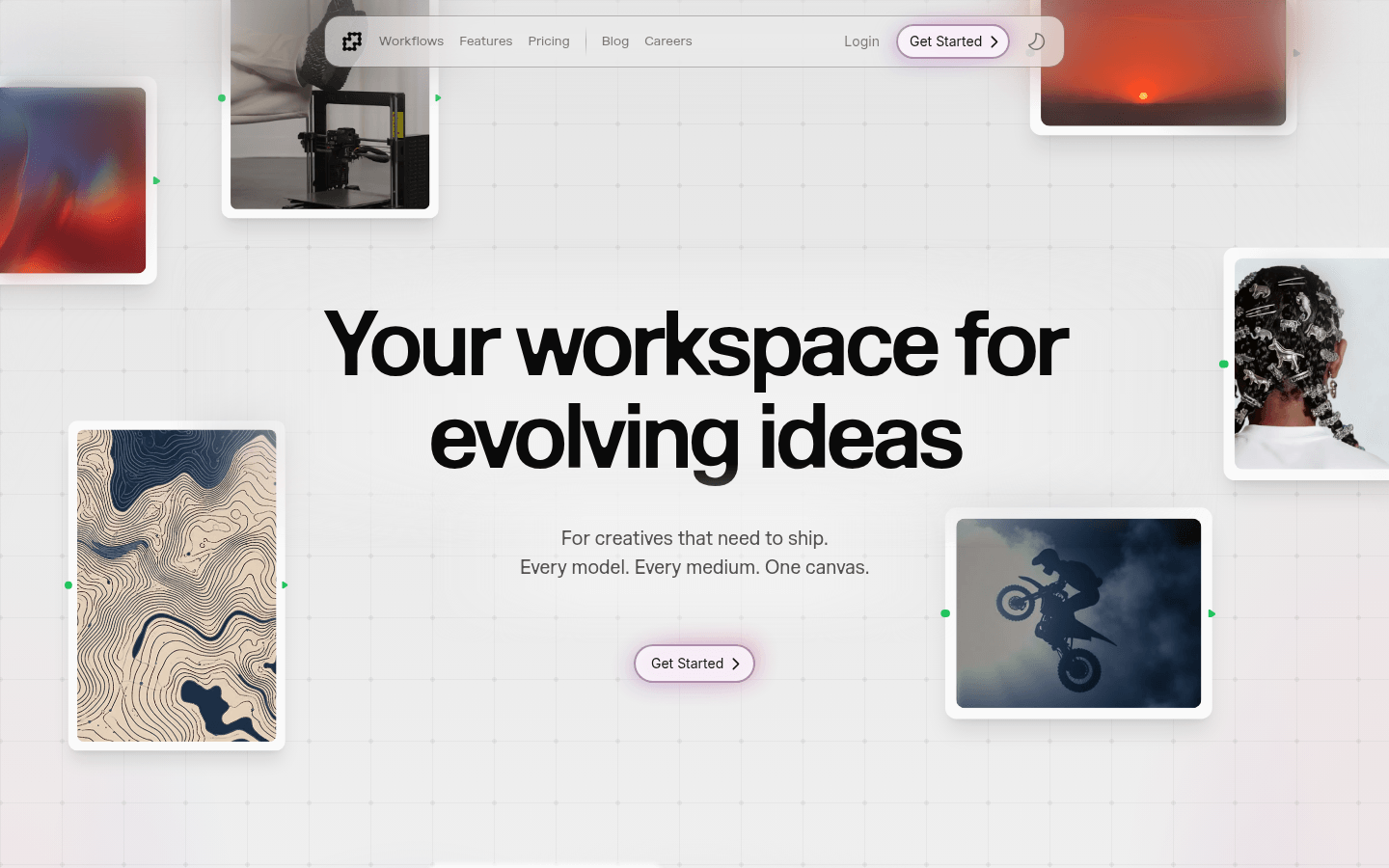
Fuser是一款创意工作空间网站,支持多模型和多媒介创作。它的重要性在于为创作者提供了一站式的创作平台,避免了在不同工具间切换的麻烦。主要优点包括直观的界面、丰富的模型选择、支持多种创作模态、可定制工作流和模板等。产品背景是为满足创作者高效输出的需求而设计。价格方面,采用信用积分制,有多种套餐可供选择,积分不失效且可累积,还有存储套餐可选。定位是为需要输出作品的创意人士提供服务,推动创意工具发展,鼓励创作者探索和引领新的创作方向。
需求人群:
["设计师:Fuser提供丰富的模型和多模态创作支持,设计师可以在一个平台上完成从概念设计到最终呈现的全过程,提高工作效率。例如,在时尚设计中,可快速将草图转化为逼真的渲染图,还能创建品牌形象和设计系统。", "艺术家:对于艺术家而言,平台的多模态创作功能和直观界面有助于他们自由表达创意。可以利用不同的模型进行图像、视频、音频等创作,探索新的艺术形式和表现手法。", "创意机构:机构需要高效协作和输出高质量的作品,Fuser的可定制工作流和团队协作功能满足了这一需求。团队成员可以共同构建工作流程,共享资源,提高项目的执行效率。"]
使用场景示例:
时尚设计师使用Fuser将草图转化为时尚摄影作品,展示品牌的独特风格。
视频制作团队利用平台的多模态创作功能,制作出引人入胜的宣传视频。
艺术家通过Fuser的模型和工具,创作并展示自己的3D艺术作品。
产品特色:
提供丰富模型选择:创意研究团队测试市场上的每一个模型,用户无需自行筛选,可直接使用适合的模型进行创作。
支持多模态创作:涵盖文本、图像、视频、音频和3D等多种创作模态,满足不同类型的创作需求。
可定制工作流:用户能够根据自己的创作习惯和需求,构建量身定制的工作流程,提高创作效率。
提供模板和可复用资源:为各种创作模态提供模板,方便用户快速开始创作,同时可复用资源节省时间和精力。
直观的界面设计:界面设计符合用户的思维方式,始终领先两步,为用户的创意过程提供有力支持。
模型无关的聊天功能:用户可以在平台上进行模型无关的聊天,方便交流创作想法和思路。
支持API连接:允许用户连接自己的API密钥,拓展创作的可能性。
云端存储功能:为用户的项目和创作成果提供云端存储服务,可在任何设备上随时随地访问,且项目和画布数量无限制。
使用教程:
步骤1:访问网站https://fuser.studio,注册并登录账号。
步骤2:根据创作需求,选择合适的模型和创作模态。
步骤3:若需要,连接自己的API密钥以拓展功能。
步骤4:利用平台提供的模板和可复用资源,开始创作。
步骤5:在创作过程中,可根据自己的习惯构建和调整工作流程。
步骤6:完成创作后,将作品保存到云端存储。
步骤7:根据需要,对作品进行分享或进一步的修改和完善。
浏览量:65
创意工作空间,支持多模型、多媒介,一站式助力创作输出。
Fuser是一款创意工作空间网站,支持多模型和多媒介创作。它的重要性在于为创作者提供了一站式的创作平台,避免了在不同工具间切换的麻烦。主要优点包括直观的界面、丰富的模型选择、支持多种创作模态、可定制工作流和模板等。产品背景是为满足创作者高效输出的需求而设计。价格方面,采用信用积分制,有多种套餐可供选择,积分不失效且可累积,还有存储套餐可选。定位是为需要输出作品的创意人士提供服务,推动创意工具发展,鼓励创作者探索和引领新的创作方向。
字节跳动自研大模型,提供多模态能力
豆包大模型是字节跳动推出的自研大模型,通过内部50+业务场景实践验证,每日万亿级tokens大使用量持续打磨,提供多模态能力,以优质模型效果为企业打造丰富的业务体验。产品家族包括多种模型,如通用模型、视频生成、文生图、图生图、同声传译等,满足不同业务需求。
一个支持多种AI艺术生成平台的创意工具,让艺术创作更简单。
多平台AI艺术生成器是一个集成了多个AI艺术生成平台的在线工具,如MidJourney、DALL-E 3、Leonardo等,为用户提供了丰富的艺术创作选项。它通过简单的操作流程,允许用户选择不同的AI平台和模型,设置分辨率,输入提示语,并生成艺术作品。该产品的主要优点在于其便捷性、创意性和多样性,它不仅适用于专业设计师寻找灵感,也适合普通用户进行个性化艺术创作。目前,该产品的具体价格和定位信息未在页面上提供。
集成文本、图像和音频AI模型,多模型协作的AI工作平台
Council Chat是一个基于网页端的AI工作平台,它为用户提供了一个集成多种领先AI模型的工作空间,无需API密钥。其重要性在于解决了用户在使用不同AI模型时的繁琐操作,让多个模型协同工作,提高效率。产品的主要优点包括多模型协作、无需安装、数据安全、欧盟数据存储等。产品背景是为了结束用户在使用多个AI模型时的混乱局面而创建。价格方面提供多种套餐,从免费到69美元/月不等,以满足不同用户的需求。其定位是为企业和个人提供一站式AI工作解决方案。
多模态大型语言模型设计空间探索
EAGLE是一个面向视觉中心的高分辨率多模态大型语言模型(LLM)系列,通过混合视觉编码器和不同输入分辨率来加强多模态LLM的感知能力。该模型包含基于通道连接的'CLIP+X'融合,适用于具有不同架构(ViT/ConvNets)和知识(检测/分割/OCR/SSL)的视觉专家。EAGLE模型家族支持超过1K的输入分辨率,并在多模态LLM基准测试中取得了优异的成绩,特别是在对分辨率敏感的任务上,如光学字符识别和文档理解。
全能AI工作空间,实时语音助手搭配多模态画布,助力高效创作与思考。
Albus AI是一个由人工智能驱动的平台,旨在为知识和创意专业人士提供高效的工作空间。通过实时语音助手和多模态画布,用户可以快速处理大量信息,激发新想法,节省宝贵的时间和注意力。该平台利用大型语言模型和机器学习服务,能够连接不同思想,避免用户在多个标签和应用之间来回切换。Albus AI的出现,为创意工作者、记者、研究人员等专业人士提供了强大的辅助工具,帮助他们更好地发挥人类智慧,为社会创造价值。目前,Albus AI提供有限的早期访问价格,订阅价格为9美元。
更有效的提示大型多模态模型,释放潜能
Multimodal-Maestro为您提供更多对大型多模态模型的控制,以获得您想要的输出。通过更有效的提示策略,您可以让多模态模型执行您以前不知道(或认为不可能)的任务。想知道它是如何工作的吗?试试我们的HF空间! 该项目仍在建设中,API可能会发生变化。
SynBooth连接多AI模型,一站式创作专业内容
SynBooth是一个创作者平台,集成了多个AI模型的API,让用户能够借助多样化的AI能力创建专业内容。其主要优点在于通过统一的API访问各种AI模型,涵盖从文本生成到图像创建等多个领域,为创作者提供了一站式的内容创作解决方案。平台定位为创作者提供便捷、高效的创作工具,帮助他们更自由地进行创作和扩展创作流程。价格方面,部分功能需使用积分,如生成6AI Image Forge图像需6个积分,但未提及整体定价模式,推测存在付费使用的情况。
Tikpal是多智能体创意AI伙伴,无干扰设计,多应用集成,助力创意工作。
Tikpal是一款面向创作者和思考者的创意AI伙伴。其重要性在于提供了一个无数字干扰的创作环境,让用户专注于创意过程。主要优点包括 distraction - free 设计、多应用集成、智能语音交互等。产品背景是为了解决创作者在创意过程中容易受到干扰、信息管理困难等问题。文档中未提及价格信息。产品定位是成为创作者的数字创意助手,帮助他们更高效地将想法转化为实际成果。
情商智商俱佳的多模态大模型
西湖大模型是心辰智能云推出的一款具有高情商和智商的多模态大模型,它能够处理包括文本、图像、声音等多种数据类型,为用户提供智能对话、写作、绘画、语音等AI服务。该模型通过先进的人工智能算法,能够理解和生成自然语言,适用于多种场景,如心理咨询、内容创作、客户服务等,具有高度的定制性和灵活性。西湖大模型的推出,标志着心辰智能云在AI领域的技术实力和创新能力,为用户提供了更加丰富和高效的智能服务体验。
KroniQ AI为营销与增长团队提供一站式AI工作空间,支持多平台内容创作。
KroniQ AI是一款集成多种AI模型的营销与增长工作空间,旨在帮助团队高效创建营销内容。其具有多模型AI能力,可自动根据用户需求选择最佳模型进行内容生成。产品的主要优点包括一站式解决营销内容创作需求,无需在多个工具间切换;支持多种内容形式,如长文、社交媒体创意和视频;提供慷慨的付费计划使用限制,适合开展营销活动。产品背景是满足市场对高效、集成化AI营销工具的需求。价格方面,提供免费试用,付费计划根据不同需求而定,具有较高的性价比。产品定位为面向营销和增长团队的专业AI平台。
由人工智能强力驱动,为职场人打造千人千面创意写作工作流
多墨智能写作是一款由人工智能强力驱动的创意写作工具,帮助职场人提高工作交付效率。它独家支持根据不同岗位通过算法一键生成工作文档,适合各种职业需求,包括产品经理、抖音运营专员、战略咨询专家、老师、医生、公职人员、旅游导游、公关等。多墨智能写作提供一键成文、辅助撰写、命令自定义和私有化部署等功能,可定制解决方案并保护内部数据隐私。
集成多AI模型,可通过对话生成图像、视频和声音,优化创意流程。
Lucent Chat是一个一体化的AI创意工作空间,它将多个领先的AI模型整合到一个平台上,为创作者和营销人员提供了高效的创意解决方案。该平台的重要性在于它简化了创意工作流程,无需用户精通复杂的提示技巧就能轻松进行创作。其主要优点包括支持多种创意形式(图像、视频、声音)的生成和编辑,能够根据用户的想法快速迭代和优化作品。产品背景是在AI技术快速发展的背景下,为满足创意行业对高效工具的需求而开发。价格方面,不同的AI模型和功能使用需要消耗不同数量的积分,例如Sora 2 Fast模式下10积分每秒,Pro模式50积分每秒等。其定位是面向创意行业,帮助用户更快速、高质量地完成创意作品。
多模态语言模型
SpeechGPT是一种多模态语言模型,具有内在的跨模态对话能力。它能够感知并生成多模态内容,遵循多模态人类指令。SpeechGPT-Gen是一种扩展了信息链的语音生成模型。SpeechAgents是一种具有多模态多代理系统的人类沟通模拟。SpeechTokenizer是一种统一的语音标记器,适用于语音语言模型。这些模型和数据集的发布日期和相关信息均可在官方网站上找到。
多模态语言模型预测网络
Honeybee是一个适用于多模态语言模型的局部性增强预测器。它能够提高多模态语言模型在不同下游任务上的性能,如自然语言推理、视觉问答等。Honeybee的优势在于引入了局部性感知机制,可以更好地建模输入样本之间的依赖关系,从而增强多模态语言模型的推理和问答能力。
多模态综合理解与创作
DreamLLM是一个学习框架,首次实现了多模态大型语言模型(LLM)在多模态理解和创作之间的协同效应。它通过直接在原始多模态空间中进行采样,生成语言和图像的后验模型。这种方法避免了像CLIP这样的外部特征提取器所固有的限制和信息损失,从而获得了更全面的多模态理解。DreamLLM还通过建模文本和图像内容以及无结构布局的原始交叉文档,有效地学习了所有条件、边缘和联合多模态分布。因此,DreamLLM是第一个能够生成自由形式交叉内容的MLLM。全面的实验证明了DreamLLM作为零样本多模态通才的卓越性能,充分利用了增强的学习协同效应。
Vidthis AI集成多模型,可免费创作视频与图像,无过滤限制
Vidthis AI是一个综合性的在线AI视频与图像生成平台。该平台集成了多种先进的AI模型,如用于视频生成的Wan 2.5、Wan 2.2、Hailuo 02,以及用于图像生成的Nano Banana、Seedream 4。其重要性在于为用户提供了一站式的创意解决方案,无需在多个工具之间切换。产品的主要优点包括:支持多种AI模型、专业的视频和图像质量、快速的生成速度、无过滤的创意控制等。价格方面,提供多种付费计划,包括按年计费的基础版、专业版和一次性付费的企业版,同时新用户有一定的优惠。定位是面向内容创作者和营销团队,满足他们在视频和图像创作方面的需求。
多模态语音大型语言模型
fixie-ai/ultravox-v0_4_1-llama-3_1-8b是一个基于预训练的Llama3.1-8B-Instruct和whisper-large-v3-turbo的大型语言模型,能够处理语音和文本输入,生成文本输出。该模型通过特殊的<|audio|>伪标记将输入音频转换为嵌入,并生成输出文本。未来版本计划扩展标记词汇以支持生成语义和声学音频标记,进而可以用于声码器产生语音输出。该模型在翻译评估中表现出色,且没有偏好调整,适用于语音代理、语音到语音翻译、语音分析等场景。
AI图像生成器,支持个性化定制和多模型管理
MidJourney是一个流行的AI图像生成器,拥有超过1900万用户。它最近推出了类似Pinterest的“Moodboards”功能和对多个自定义AI图像模型的支持,使用户能够创建和切换多个定制版本的MidJourney最新图像生成器AI模型,以适应他们独特的审美。这些更新旨在简化个人和团队的创作流程,使个性化风格更容易融入各种项目。MidJourney的个性化基础设施不断改进,公司正在通过其“想法和功能”频道征求用户反馈,以赋予创作者直观而强大的工具,推动AI辅助创作的进一步发展。
前沿的多模态大型语言模型
NVLM-D-72B是NVIDIA推出的一款多模态大型语言模型,专注于视觉-语言任务,并且通过多模态训练提升了文本性能。该模型在视觉-语言基准测试中取得了与业界领先模型相媲美的成绩。
全球首个多代理AI视频创作平台
ReelMagic是Higgsfield AI推出的全球首个多代理AI视频创作平台,它能够将故事想法转化为即看即用的长篇内容。该平台不需要复杂的工作流程或多个订阅服务,只需用户的想象力。ReelMagic由AI创意代理驱动,这些代理专门负责从编剧、角色表演、场景设计、摄影到编辑的每个制作步骤,并由AI制作经理指导。它为创作者提供了最佳的创意AI模型,包括Higgsfield AI自己的基础世界模型,所有这些都在一个单一的平台上。ReelMagic将故事想法转化为感觉像是直接来自工作室制作的即看视频,用户只需提供愿景,ReelMagic处理其余部分。Higgsfield AI由硅谷先锋的独特合作创立,并得到技术和媒体领域顶级投资者的支持。
生成多视角视频的模型
Stable Video 4D (SV4D) 是基于 Stable Video Diffusion (SVD) 和 Stable Video 3D (SV3D) 的生成模型,它接受单一视角的视频并生成该对象的多个新视角视频(4D 图像矩阵)。该模型训练生成 40 帧(5 个视频帧 x 8 个摄像机视角)在 576x576 分辨率下,给定 5 个相同大小的参考帧。通过运行 SV3D 生成轨道视频,然后使用轨道视频作为 SV4D 的参考视图,并输入视频作为参考帧,进行 4D 采样。该模型还通过使用生成的第一帧作为锚点,然后密集采样(插值)剩余帧来生成更长的新视角视频。
基于Omni AI Model的多模态AI视频生成器,支持多形式创作编辑。
Omni AI Video是基于强大的Omni AI Model构建的先进多模态视频生成系统。其重要性在于为创作者提供了一站式的AI视频创作解决方案。主要优点包括支持文本、图像、音频和视频输入,实现统一的多模态处理;无需切换工具,提高创作效率;输出高质量视频,适用于多种商业场景。产品背景是满足创作者对高效、多功能AI视频创作工具的需求。价格方面,有每日免费信用额度1 Credit,同时有不同的付费计划可供选择,价格即将上调,现在订阅可锁定低价。定位为面向创作者的一站式AI创意平台,提供7种顶级AI模型用于视频、图像、音乐和语音生成。
一张图生成多视角扩散基础模型
Zero123++是一个单图生成多视角一致性扩散基础模型。它可以从单个输入图像生成多视角图像,具有稳定的扩散VAE。您可以使用它来生成具有灰色背景的不透明图像。您还可以使用它来运行深度ControlNet。模型和源代码均可在官方网站上获得。
一款支持多模态功能的全功能大语言模型安卓应用。
MNN 大模型 Android App 是阿里巴巴开发的一款基于大语言模型(LLM)的安卓应用。它支持多种模态输入和输出,包括文本生成、图像识别、音频转录等。该应用通过优化推理性能,确保在移动设备上高效运行,同时保护用户数据隐私,所有处理均在本地完成。它支持多种领先的模型提供商,如 Qwen、Gemma、Llama 等,适用于多种场景。
多模态原生混合专家模型
Aria是一个多模态原生混合专家模型,具有强大的多模态、语言和编码任务性能。它在视频和文档理解方面表现出色,支持长达64K的多模态输入,能够在10秒内描述一个256帧的视频。Aria模型的参数量为25.3B,能够在单个A100(80GB)GPU上使用bfloat16精度进行加载。Aria的开发背景是满足对多模态数据理解的需求,特别是在视频和文档处理方面。它是一个开源模型,旨在推动多模态人工智能的发展。

© 2026 AIbase 备案号:闽ICP备08105208号-14