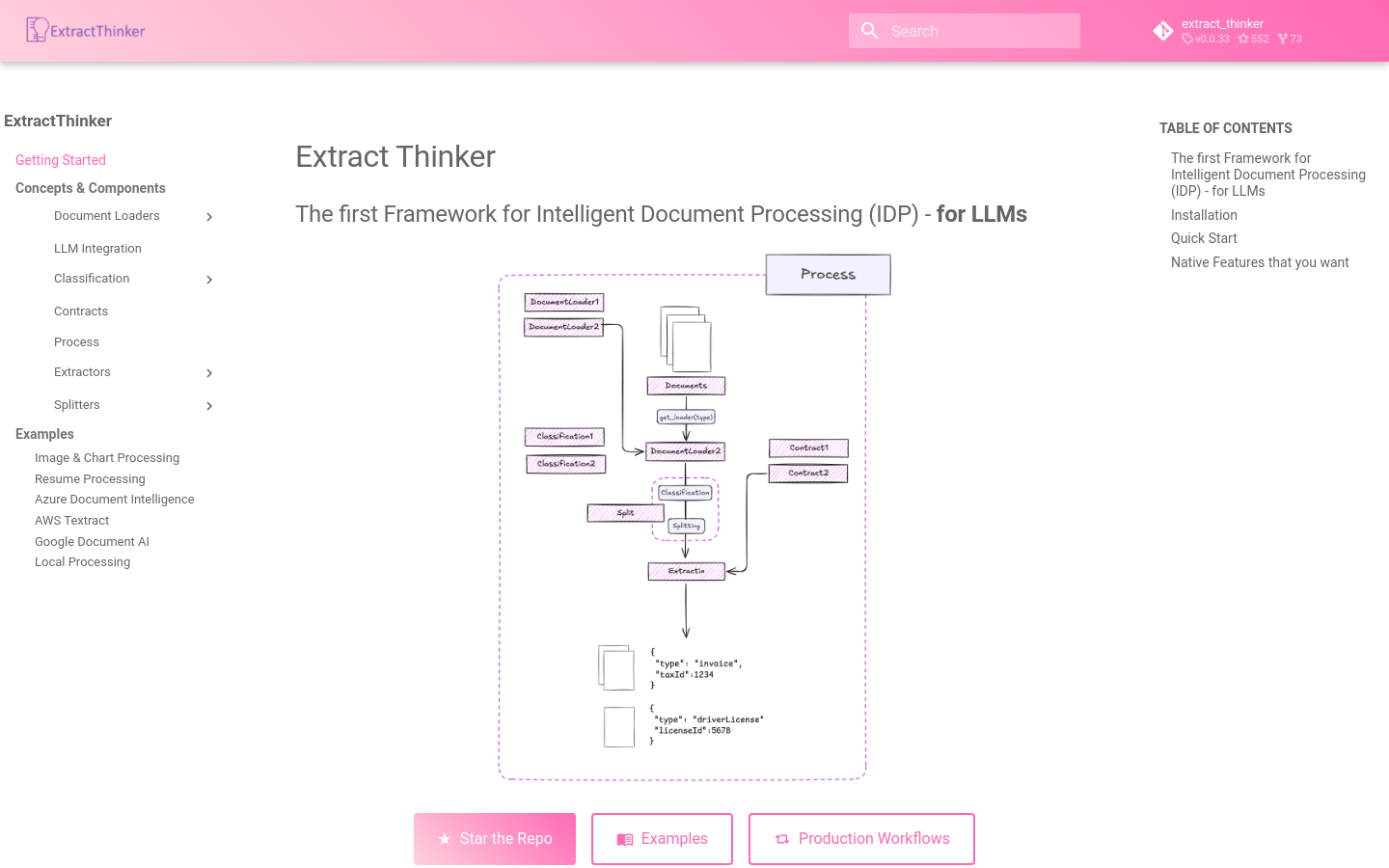
ExtractThinker是一个灵活的文档智能框架,帮助用户从各种文档中提取和分类结构化数据,类似于文档处理工作流的ORM。它被称为“LLMs的文档智能”或“智能文档处理的LangChain”。该框架的动机是为文档处理创建所需的特定功能,如分割大型文档和高级分类。
需求人群:
"目标受众为需要处理大量文档并从中提取结构化数据的企业或个人,如财务分析师、数据科学家和法律专业人士。ExtractThinker适合他们,因为它提供了一个灵活且强大的工具来自动化文档处理任务,提高效率并减少手动错误。"
使用场景示例:
从PDF中提取发票数据:使用ExtractThinker从PDF文件中提取发票编号、日期和总金额。
智能文档分类:对大量文档进行分类,识别不同类型的文档并进行相应的处理。
PII检测和处理:在处理敏感文档时,自动识别并处理个人身份信息,确保数据隐私。
产品特色:
使用Pydantic进行数据提取:从任何文档类型中提取结构化数据,并使用Pydantic模型进行验证、自定义功能和提示工程能力。
智能文档分类和分割:支持共识策略、急切/惰性分割和置信度阈值的智能文档分类和分割。
PII检测:自动检测和处理文档中的敏感个人信息,采用隐私优先的方法和高级验证。
LLM和OCR中立:根据需求和成本要求,自由选择和切换不同的LLM提供商和OCR引擎。
使用教程:
1. 安装ExtractThinker:使用pip安装extract_thinker。
2. 定义要提取的数据:创建一个继承自Contract的类,定义需要提取的数据字段。
3. 初始化提取器:创建Extractor实例,并加载文档加载器和LLM模型。
4. 从文档中提取数据:使用Extractor的extract方法从指定文档中提取数据,并传入Contract类。
5. 打印结果:打印提取的数据,如发票编号、日期和总金额。
浏览量:96
最新流量情况
月访问量
1644
平均访问时长
00:00:00
每次访问页数
1.01
跳出率
42.42%
流量来源
直接访问
33.68%
自然搜索
46.42%
邮件
0.51%
外链引荐
13.78%
社交媒体
4.12%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
巴西
9.40%
马来西亚
2.56%
俄罗斯
66.80%
泰国
9.61%
美国
11.64%
智能文档处理框架,专为LLMs设计
ExtractThinker是一个灵活的文档智能框架,帮助用户从各种文档中提取和分类结构化数据,类似于文档处理工作流的ORM。它被称为“LLMs的文档智能”或“智能文档处理的LangChain”。该框架的动机是为文档处理创建所需的特定功能,如分割大型文档和高级分类。
OCR解决方案API | 文档OCR文本识别
Pixl OCR Solution API是一款高效的OCR解决方案API,可以简化文档OCR文本识别流程。轻松从图像和文档中提取文本,实现快速信息检索。通过集成我们强大的API,不仅可以降低劳动成本,还能实现更快速和更明智的决策。
利用OpenAI的GPT-4 Turbo模型进行高效OCR处理
这是一个开源的OCR API,利用OpenAI强大的语言模型和优化的性能技术(如并行处理和批处理)来实现从复杂PDF文档中提取高质量文本。非常适合寻求高效文档数字化和数据提取解决方案的企业。
利用大型语言模型增强扫描PDF的OCR输出。
llm_aided_ocr是一个高级系统,旨在显著提高光学字符识别(OCR)输出的质量。通过利用尖端的自然语言处理技术和大型语言模型(LLMs),该项目将原始OCR文本转化为高度准确、格式良好、易读的文档。
智能文档处理平台,自动化数据提取
DOConvert是一个智能文档处理平台,可自动化提取各类文档的复杂数据,优化文档处理和集成流程,节省高达75%的数据录入成本。它支持主流的ERP系统,包括SAP、Salesforce等,也可自定义API集成到任何ERP或CMS系统。DOConvert最多可在10天内完全实施,从首次演示到定制解决方案、ERP连接、模板定制以及全自动化运行。
全球首个由深度学习驱动的在线 OCR 工具,97% 准确率。
DeepSeek OCR 是基于 3B 参数的视觉 - 语言模型的在线 OCR 工具,具有 97% 的文本提取准确率和超低的令牌消耗(每页 100 个令牌)。该工具支持多语言处理,能快速转换文档为 Markdown 格式,提取图像中的文本,并解析图表。它采用了革命性的视觉压缩技术,极大地提升了 OCR 的效率和效果。产品提供免费和付费方案,适合不同需求的用户。
一种简单直观的PDF OCR工具,使用gpt-4o-mini进行文档转换。
Zerox OCR是一个基于gpt-4o-mini的PDF文档转换工具,它通过将PDF文件转换为图像,然后利用GPT模型将图像内容转换为Markdown格式,从而实现对文档的高效OCR处理。该工具在价格上具有竞争力,并且能够提供比现有产品更有意义的结果。
智能文档处理解决方案
Parseflow是一个数据自动化平台,专注于通过先进的OCR和AI技术实现文档数据的自动提取和结构化。它能够显著降低操作成本,提高工作效率,适用于从发票、合同到电子邮件和简历等多种文档类型。该平台易于集成,支持60多种语言,并提供安全的数据存储。Parseflow的主要优点包括快速的数据提取、广泛的文档类型支持、多语言识别能力以及与6000多个应用的集成能力。它的目标是帮助企业释放数据的潜力,提高运营效率。
智能文档处理AI平台,利用AI、机器学习和OCR技术自动化数据提取、分类和组织各种文档类型。
docsynecx是一款智能文档处理AI平台,通过AI、机器学习和OCR技术,自动化处理各种文档类型,包括发票处理、收据、提单等。该平台能够快速准确地提取、分类和组织结构化、半结构化和非结构化数据。
Mistral OCR 是一款先进的光学字符识别 API,能够精准理解和解析复杂文档。
Mistral OCR 是 Mistral AI 推出的一款光学字符识别(OCR)API,旨在通过高效解析文档内容,推动信息的快速提取与应用。它能够处理多种格式的文档,包括 PDF 和图像,并以极高的准确率提取文本、表格、公式和图像等元素。该技术的核心优势在于其对复杂文档的深度理解能力,支持多语言和多模态输入,适用于全球范围内的企业和机构。其定价为每1000页1美元,适合大规模文档处理场景。
一个强大的OCR(光学字符识别)工具
Ollama-OCR是一个使用最新视觉语言模型的OCR工具,通过Ollama提供技术支持,能够从图像中提取文本。它支持多种输出格式,包括Markdown、纯文本、JSON、结构化数据和键值对,并且支持批量处理功能。这个项目以Python包和Streamlit网络应用的形式提供,方便用户在不同场景下使用。
LLM应用开发平台,提升文档处理能力。
Farspeak是一个LLM应用开发平台,它允许开发者通过API接入,使用自然语言查询(NLQ)和自然语言开发(NLD)技术,与MongoDB Atlas等数据库进行交互,处理结构化和非结构化数据。其主要优点包括实时嵌入更新、单一存储解决方案以及对多种数据库的支持。
腾讯文档智能助手,支持内容生成、数据处理、版式美化等创作需求
腾讯文档智能助手正式开启公测,可与Word、Excel、PPT等多品类文档进行智能互动,支持内容秒级生成,实现数据处理、版式美化等创作辅助功能。主要优势有:可基于标题或描述生成多类型文档内容,支持函数公式应用、数据处理、表格自动化等能力,实现 PPT 一键美化,可快速提取 PDF 文档摘要等,让文档内容实现跨品类畅通流转。
基于先进AI技术的在线OCR工具,可将图片与PDF快速识别并转换为可编辑文本。
HandOCR是一款基于下一代人工智能(Next-Gen AI)技术的在线OCR(光学字符识别)工具,旨在为用户提供快速、准确且安全的图像转文本服务。该产品主打无门槛使用,用户无需注册或登录即可直接在浏览器中处理文件。其核心技术能够精准识别复杂的排版、多样的字体甚至手写笔记,极大地解决了传统OCR工具错误率高、需要二次人工校对的痛点。产品目前提供免费服务,定位为面向全球用户的多语言数字化办公与学习助手,通过本地化与服务器安全处理机制,严格保护用户的隐私数据。
一个针对机器学习优化的多模态 OCR 管道。
该产品是一个专门设计的 OCR 系统,旨在从复杂的教育材料中提取结构化数据,支持多语言文本、数学公式、表格和图表,能够生成适用于机器学习训练的高质量数据集。该系统利用多种技术和 API,能够提供高精度的提取结果,适合学术研究和教育工作者使用。
OCR-free 文档理解的统一结构学习模型
mPLUG-DocOwl 1.5 是一个致力于OCR-free文档理解的统一结构学习模型,它通过深度学习技术实现了对文档的直接理解,无需传统的光学字符识别(OCR)过程。该模型能够处理包括文档、网页、表格和图表在内的多种类型的图像,支持结构感知的文档解析、多粒度的文本识别和定位,以及问答等功能。mPLUG-DocOwl 1.5 的研发背景是基于对文档理解自动化和智能化的需求,旨在提高文档处理的效率和准确性。该模型的开源特性也促进了学术界和工业界的进一步研究和应用。
使用简单、原始的 C/CUDA 进行 LLM 训练
karpathy/llm.c 是一个使用简单的 C/CUDA 实现 LLM 训练的项目。它旨在提供一个干净、简单的参考实现,同时也包含了更优化的版本,可以接近 PyTorch 的性能,但代码和依赖大大减少。目前正在开发直接的 CUDA 实现、使用 SIMD 指令优化 CPU 版本以及支持更多现代架构如 Llama2、Gemma 等。
免费 npm 库,用 Llama 3.2 Vision 进行 OCR,输出 markdown 文本
开源 npm 库,免费使用 Llama 3.2 Vision 进行 OCR,支持本地和远程图像,计划支持 PDF,受 Zerox 启发,有免费和付费接口
免费OCR工具,将图像和PDF转换为可编辑的Markdown文本。
OCR Markdown是一款强大的OCR工具,可以将扫描文档、图像文件和非可选PDF转换为可编辑的Markdown。其AI增强识别功能能够以90-99%的准确率识别文本、数学公式、表格和图片,极大提高了内容处理的效率。
利用复合AI技术,将文档内联处理,跨越模态差距。
Document Inlining是Fireworks AI推出的一款复合AI系统,它能够将任何大型语言模型(LLM)转化为视觉模型,以处理图像或PDF文档。这项技术通过构建自动化流程,将任何数字资产格式转换为LLM兼容的格式,实现逻辑推理。Document Inlining通过解析图像和PDFs,直接将它们输入到用户选择的LLM中,提供更高的质量、输入灵活性和超简单的使用方式。它解决了传统LLM在处理非文本数据时的局限性,通过专业化的组件分解任务,提高了文本模型推理的质量,并且简化了开发者的使用体验。
提供文档解析功能,将图片或 PDF 文件转换成 Markdown 格式,实现智能转换
OCR 体验是一个文档解析工具,利用 OCR 技术将图片或 PDF 文件转换成 Markdown 格式文件。其主要优点在于高效转换并智能排版,背景信息源于对文档处理的需求。目前免费使用。
LLM辅助的文稿处理工具
Rambler是一款基于LLM技术的桌面客户端,支持通过图形用户界面进行口述文本的要点提取和宏观修订。它包括要点提取和宏观修订两大功能,能够生成关键词和摘要,支持口述文本的审阅和交互,并通过LLM辅助的宏观修订功能,让用户在不指定具体编辑位置的情况下进行重述、拆分、合并和转换文稿。Rambler在口述文本处理方面表现优异,能够帮助用户更好地进行口述和修订,弥合口语和结构化写作之间的差距。在与12名参与者进行口头作文任务的比较研究中,Rambler表现优于基于语音转文本编辑器+ChatGPT的基准,因为它更好地促进了用户对内容的迭代修订,同时支持多样化的用户策略。
高效的 Intel GPU 上的 LLM 推理解决方案
这是一种在 Intel GPU 上实现的高效的 LLM 推理解决方案。通过简化 LLM 解码器层、使用分段 KV 缓存策略和自定义的 Scaled-Dot-Product-Attention 内核,该解决方案在 Intel GPU 上相比标准的 HuggingFace 实现可实现高达 7 倍的令牌延迟降低和 27 倍的吞吐量提升。详细功能、优势、定价和定位等信息请参考官方网站。
比较各种大型语言模型(LLM)的定价信息
LLM Pricing是一个聚合并比较各种大型语言模型(LLMs)定价信息的网站,这些模型由官方AI提供商和云服务供应商提供。用户可以在这里找到最适合其项目的语言模型定价。
将GitHub链接转换为适合LLM的格式
GitHub to LLM Converter是一个在线工具,旨在帮助用户将GitHub上的项目、文件或文件夹链接转换成适合大型语言模型(LLM)处理的格式。这一工具对于需要处理大量代码或文档数据的开发者和研究人员来说至关重要,因为它简化了数据准备过程,使得这些数据可以被更高效地用于机器学习或自然语言处理任务。该工具由Skirano开发,提供了一个简洁的用户界面,用户只需输入GitHub链接,即可一键转换,极大地提高了工作效率。
智能文档处理
Bewai是一种智能文档处理解决方案,通过强大的人工智能驱动的RAD-LAD(快速自适应学习文档分析)技术,自动化识别、提取、分类和验证客户档案中的数据。无需预设模板,可自动识别各类文件,包括银行文件、保险文件、政府文件等。提供自动分类和验证文件、自动提取和验证数据等功能。Bewai可以帮助您实现文档处理的自动化、可靠化和加速化。
通过统一的端到端模型实现OCR-2.0
GOT-OCR2.0是一个开源的OCR模型,旨在通过一个统一的端到端模型推动光学字符识别技术向OCR-2.0迈进。该模型支持多种OCR任务,包括但不限于普通文本识别、格式化文本识别、细粒度OCR、多裁剪OCR和多页OCR。它基于最新的深度学习技术,能够处理复杂的文本识别场景,并且具有较高的准确率和效率。
Mistral OCR 是一款强大的文档理解 OCR 产品,能够以极高的准确性从 PDF 和图像中提取文本、图像、表格和方程式。
Mistral OCR 是由 Mistral AI 开发的先进光学字符识别 API,旨在以无与伦比的准确性提取和结构化文档内容。它能够处理包含文本、图像、表格和方程式的复杂文档,输出 Markdown 格式的结果,便于与 AI 系统和检索增强生成(RAG)系统集成。其高精度、高速度和多模态处理能力使其在大规模文档处理场景中表现出色,尤其适用于科研、法律、客服和历史文献保护等领域。Mistral OCR 的定价为每美元 1000 页标准使用量,批量处理可达每美元 2000 页,还提供企业自托管选项,满足特定隐私需求。

© 2026 AIbase 备案号:闽ICP备08105208号-14