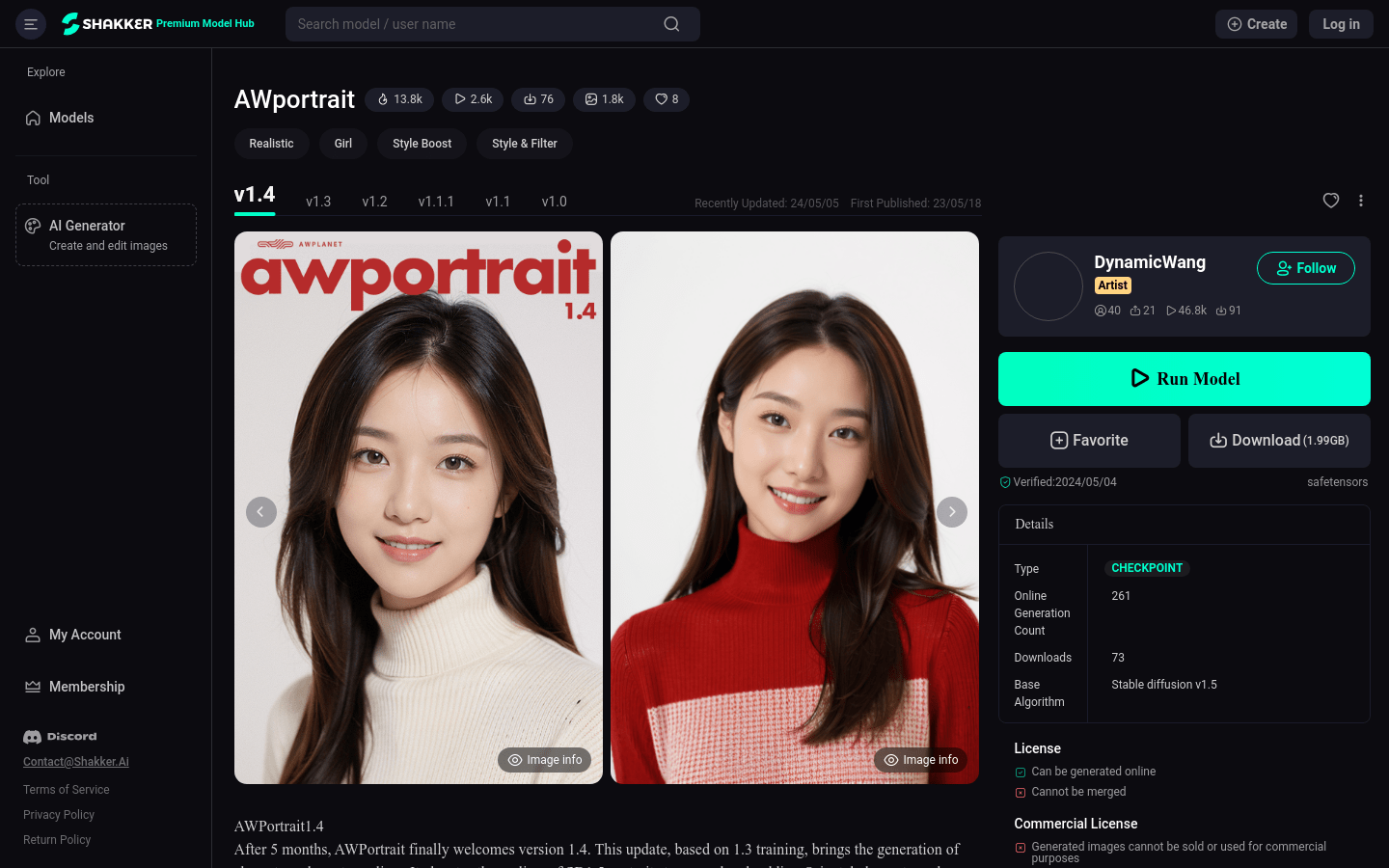
AWPortrait是一款专注于AI生成肖像照片的模型,致力于通过技术提升照片的真实感。它通过不断优化训练,使得生成的人物肖像更加逼真,加入了东方元素,如旗袍和汉服,增强了室内外效果,优化了面部特写的变形问题,并允许调整人物年龄。AWPortrait适用于个人和商业用途,但需遵守相应的使用协议。
需求人群:
["适合个人用户进行肖像照片的生成,包括商业用途","适合研究和学习,可以用于集成模型","适合企业用户,但需购买商业许可"]
使用场景示例:
用于生成具有东方特色的人物肖像
商业广告中使用,创造逼真的人物形象
在艺术创作中,模拟真实摄影效果
产品特色:
提升SD1.5肖像的逼真度到新水平
加入东方元素,如旗袍和汉服
增强室内外拍摄效果
优化面部特写可能出现的变形问题
可调节人物年龄,稳定输出10-80岁之间的肖像
使用'1girl'参数简化生成一致性平均面孔
提供多种模型效果,通过示例提示引导用户
使用教程:
选择推荐的采样方法DPM++ 2M Karras或Restart, Step 30
设置分辨率为512768或576864
选择上采样算法Lanczos,调整Redraw magnitude在0.35-0.45之间
根据需要,使用负面提示排除不希望出现的元素
使用Adetailer插件优化面部模型
根据拍摄情况调整Redraw magnitude的值
遵守模型使用协议,合法合规地使用模型
浏览量:205
最新流量情况
月访问量
867.56k
平均访问时长
00:04:12
每次访问页数
7.93
跳出率
38.78%
流量来源
直接访问
48.60%
自然搜索
37.84%
邮件
0.05%
外链引荐
5.15%
社交媒体
6.95%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
巴西
5.51%
印度尼西亚
3.52%
美国
5.34%
越南
51.84%
一款专注于提升AI生成肖像照片真实感的模型。
AWPortrait是一款专注于AI生成肖像照片的模型,致力于通过技术提升照片的真实感。它通过不断优化训练,使得生成的人物肖像更加逼真,加入了东方元素,如旗袍和汉服,增强了室内外效果,优化了面部特写的变形问题,并允许调整人物年龄。AWPortrait适用于个人和商业用途,但需遵守相应的使用协议。
生成逼真的AI肖像
PhotoStudio是一款利用人工智能生成逼真肖像的应用。用户可以使用PhotoStudio来生成逼真的AI肖像。该应用提供了30个AI肖像的内购选项,定价为26.99美元。PhotoStudio支持多种语言,适用于iOS 14.0及更高版本的iPhone和iPod touch。
定制AI宠物摄影,独一无二的宠物肖像
Pawfect Snapshots是一款使用先进的AI技术定制个性化宠物摄影和肖像的产品。通过各种艺术风格、场景和时间,将您可爱的毛茸茸朋友独特的魅力展现出来。立即注册并开始创造您的宠物独特肖像!免费试用。
免费 AI 生成精美肖像照片
A2E Photo 是一款免费的 AI 肖像生成工具。只需上传两张自拍照,即可获得 50 张令人惊叹的 AI 肖像照片。无法辨别与现实的差异,质量堪比专业摄影作品。适用于简历头像、社交网络照片等各种场景。
Luminar Neo是一款先进的图像处理程序,借助AI轻松完善创意摄影作品。
Luminar Neo是由Skylum开发的一款图像处理程序,适用于MacOS和Windows系统。它拥有强大的AI算法,可自动提升图像质量,让用户以最小的工作量获得最佳效果。该软件提供丰富的高级处理功能,涵盖从基本的裁剪、调整大小到复杂的AI增强、背景去除等操作。其优势在于操作简单直观,即使是初学者也能轻松上手,同时也能满足专业摄影师对图像质量和细节的高要求。它既可以作为独立应用程序运行,也能作为插件集成到Adobe Photoshop、Adobe Lightroom等现有软件中,不改变用户的工作流程。价格方面,文中虽未明确提及具体金额,但提到有不同的计划可供查看,说明是付费软件,并且提供30天退款保证。此外,购买该产品还能支持乌克兰。
专注人像摄影的AI创意生成工具,助力个人图像创意
超能画布是百度网盘荣誉出品的AI创意生成工具,可以根据您上传的人像图片自动生成各种风格的创意图像,如写实、唯美、奇幻等,帮助摄影师提高工作效率,为每个人实现图像创意. 该工具提供免费试用,并有灵活的付费模式满足不同需求.
图像处理和编辑工具
Wisemorph 是一款强大的图像处理和编辑工具。它提供了丰富的功能和优势,包括智能修复、滤镜效果、调整图像色彩和对比度、裁剪和旋转、添加文字和贴纸等。Wisemorph 的定价灵活合理,适用于个人和专业用户。无论您是摄影师、设计师还是普通用户,Wisemorph 都能满足您的图像处理需求。
AI Shots | 生成专业肖像照片
AI Shots是一种现代化服务,利用先进的人工智能技术轻松创建令人惊叹的专业肖像照片。通过上传自拍照片并使用AI Shots的神奇功能,您可以在短短60分钟内获得100张4K分辨率的专业肖像照片。AI Shots提供多种风格、拍摄地点和服装供您选择,让您的肖像照片个性化定制。
AI 生成专业肖像照片
PicStudio.AI 是一个基于人工智能技术的在线肖像照片生成工具。用户只需上传自拍照片,选择相应的照片包,即可获得 120 多张精美的肖像照片,非常适合用于社交媒体。PicStudio.AI 采用最先进的人工智能技术,可自动为用户生成专业的照片,省去了拍摄和后期处理的繁琐过程,大大提高了用户的效率和使用体验。
打破摄影和照片编辑行业的世界首款 AI 自拍应用
木目 AI 是即将颠覆摄影和照片编辑行业的革命性 AI 自拍应用。我们的 AI 技术可以生成用户在任何场景、姿势、服装、发型或面部表情下的无限超逼真照片。使用木目 AI,任何人都可以在几秒钟内创建出令人惊叹的照片,无需专业知识、时间和成本。专为主流青年设计,木目 AI 为个人和专业用途提供了改变游戏规则的解决方案。与木目 AI 一同探索自拍的未来。
2 步解锁 AI 宠物肖像,21 个不同角色,惊人质量
AI 宠物照片是一款通过 AI 生成宠物肖像的服务。只需上传宠物的 25 张照片,即可获得 42 张展示全部 21 个宠物肖像的图片。我们提供高质量、高分辨率的图片,可以用于打印或在线分享。通过几次点击,将您的宠物变身超级英雄、潜水员、牛仔或维京人。无需设计技能,轻松操作。定价为 $9.99 每只宠物。这是一个实验性的服务,我们正在改进流程,但生成式 AI 是一个新兴领域,希望您的反馈和耐心。
利用尖端AI技术,将创意转化为高质量图像。
Flux AI 图像生成器是由Black Forest Labs开发的,基于革命性的Flux系列模型,提供尖端的文本到图像技术。该产品通过其120亿参数的模型,能够精确解读复杂的文本提示,创造出多样化、高保真的图像。Flux AI 图像生成器不仅适用于个人艺术创作,也可用于商业应用,如品牌视觉、社交媒体内容等。它提供三种不同的版本以满足不同用户的需求:Flux Pro、Flux Dev和Flux Schnell。
定制化AI生成的专业肖像库
StockPhotoAI.net是一个使用AI生成专业肖像照片的库,可用于幻灯片、网站或印刷媒体。通过描述照片需求,使用最新的OpenAI Dall E模型生成独特的、个性化的肖像照片。免费试用。
AI生成的摄影作品
Nyx.gallery是一个利用人工智能生成摄影作品的网站。它使用先进的算法和深度学习技术,能够生成逼真且独特的摄影作品。Nyx.gallery提供多种风格和主题的摄影作品供用户选择,让用户能够轻松获取高质量的照片作品。用户可以通过上传自己的照片或选择现有的摄影作品进行编辑和定制,以满足个性化的需求。Nyx.gallery致力于为用户提供美感和创意的摄影作品,让摄影艺术更加普及和便捷。
AI宠物肖像画生成
furryfriends.ai是一款可以生成宠物肖像画的AI产品。用户只需上传宠物照片,选择喜欢的艺术风格,即可生成多张宠物肖像画。该产品提供三种套餐,分别包括不同数量的图片和高分辨率图片下载功能。用户需要上传至少10张宠物照片,建议上传20-30张以获得最佳效果。生成的肖像画通常在30-60分钟内完成,用户可以通过邮件收到通知。该产品支持PNG、JPG、WebP、HEIC、HEIF和JFIF等多种图片格式。生成的肖像画归用户所有,用户可以自由使用。该产品不提供退款服务。
AiGlamorous - 快速生成专业头像和肖像照片
AiGlamorous是一个基于人工智能的图像生成工具,可以快速生成专业头像、商务肖像照片等。它利用先进的人脸识别和图像修饰技术,提供无需摄影师即可生成完美照片的便利。用户只需上传一张照片,AiGlamorous就能自动处理并生成高质量的图像。该工具适用于个人形象展示、社交媒体头像、企业品牌形象等多种场景。
Snappyit是一款AI服装摄影平台,可秒速生成多种类型服装图片和视频。
Snappyit是一款专为服装设计的AI产品摄影平台。该平台利用先进的AI技术,能将单张服装照片快速转化为多种专业电商视觉素材,如模特照片、平铺照片、幽灵模特照片等。它的优势显著,无需摄影棚、摄影师和专业编辑技能,就能在短时间内生成高质量的图片和视频,大大节省了时间和成本。价格方面,单张图片成本低于0.1美元,月费用从8.2美元起,还提供免费试用。其定位是为各类服装相关的电商卖家、品牌和设计团队提供高效、便捷的视觉解决方案,帮助他们提升产品展示效果,增加销售转化率。
AI生成图像鉴别挑战网站
AI判官是一个AI生成图像鉴别挑战的网站。它提供了普通模式、无尽模式和竞速模式三种游戏玩法。用户可以通过不同难度的游戏来提高自己分辨真实图片和AI生成图片的能力。该网站提供大量高质量的真实图片和AI生成图片作为判别素材。它的出现是对近期AI生成图片技术的一个回应,旨在提高公众的媒体识读能力。
朱雀大模型检测,精准识别AI生成图像,助力内容真实性鉴别。
朱雀大模型检测是腾讯推出的一款AI检测工具,主要功能是检测图片是否由AI模型生成。它经过大量自然图片和生成图片的训练,涵盖摄影、艺术、绘画等内容,可检测多类主流文生图模型生成图片。该产品具有高精度检测、快速响应等优点,对于维护内容真实性、打击虚假信息传播具有重要意义。目前暂未明确其具体价格,但从功能来看,主要面向需要进行内容审核、鉴别真伪的机构和个人,如媒体、艺术机构等。
智能绘图与图像处理的AI平台
智启特AI是一个提供卓越算法和顶级算力的智能绘图与图像处理平台,专注于通过AI技术赋能无限可能,共创智能未来。平台具备强大的服务器集群和灵活的负载均衡策略,确保在高并发场景下也能保持出色的性能和稳定性。支持多种图像处理功能,如文生图、图生图、局部重绘等,满足不同用户需求,同时提供安全、高性价比的服务。
一款强大的在线AI图像生成与编辑工具,提供多种图像处理功能。
Picture AI 是一个基于人工智能的在线图像生成和编辑平台,它利用先进的AI技术帮助用户轻松创建和优化图像。该平台的主要优点是操作简单、功能多样且完全在线,无需下载或安装任何软件。它适用于各种用户,包括设计师、摄影师、普通用户等,能够满足从创意设计到日常图像处理的多种需求。目前该平台提供免费试用,用户可以根据自己的需求选择不同的功能和服务。
一种基于扩散变换器网络的高动态、逼真肖像图像动画技术。
Hallo3是一种用于肖像图像动画的技术,它利用预训练的基于变换器的视频生成模型,能够生成高度动态和逼真的视频,有效解决了非正面视角、动态对象渲染和沉浸式背景生成等挑战。该技术由复旦大学和百度公司的研究人员共同开发,具有强大的泛化能力,为肖像动画领域带来了新的突破。
全能的 AI 视频生成与图像处理平台,免费试用!
Funy AI 是一个综合平台,专注于视频创作和图像处理。它允许用户将静态图像转化为动态视频,且不需要注册,提供自由、无限制的体验。该平台利用先进的人工智能技术,提供图像到视频、文本到视频、背景移除等多种功能,是创作者和设计师的理想选择。所有功能均免费使用,无需注册,让用户可以轻松生成高质量的视觉内容。
在线免费将随手拍产品照转为专业摄影棚级别图片,无需注册。
AI Product Photography是一款在线免费工具,利用人工智能技术,能自动移除产品照片背景、生成专业摄影棚场景并添加逼真光照,几秒内产出媲美专业摄影棚的效果。其重要性在于为电商卖家、营销团队等提供了便捷、高效且低成本的产品图片处理方案。产品定位是服务有产品图片处理需求的各类用户,价格方面,可使用初始积分免费试用,每次生成约消耗22积分,可实惠价格购买额外积分。
创建令人惊叹的AI肖像和自拍照
kahma.io是一款使用AI技术创建令人惊叹的肖像和自拍照的产品。无论是为自己还是为所爱之人,这是一份完美的礼物,无论是纪念日还是生日。您可以打印它们的大尺寸照片或以高清质量展示。
使用我们的AI肖像生成器,即可将您的照片立即转换为独特的AI肖像艺术品。探索数百种艺术风格,并创建您完美的艺术肖像。
AIPortrait.Art是一个AI肖像生成器,能够将您的照片在几秒钟内转换为艺术杰作。通过混搭数百种风格,创作出独特的AI艺术肖像。无需艺术技能,只需上传照片即可。数千名用户使用我们的产品来探索、创作和分享完美的艺术肖像。我们提供高分辨率的输出和下载功能。

© 2026 AIbase 备案号:闽ICP备08105208号-14