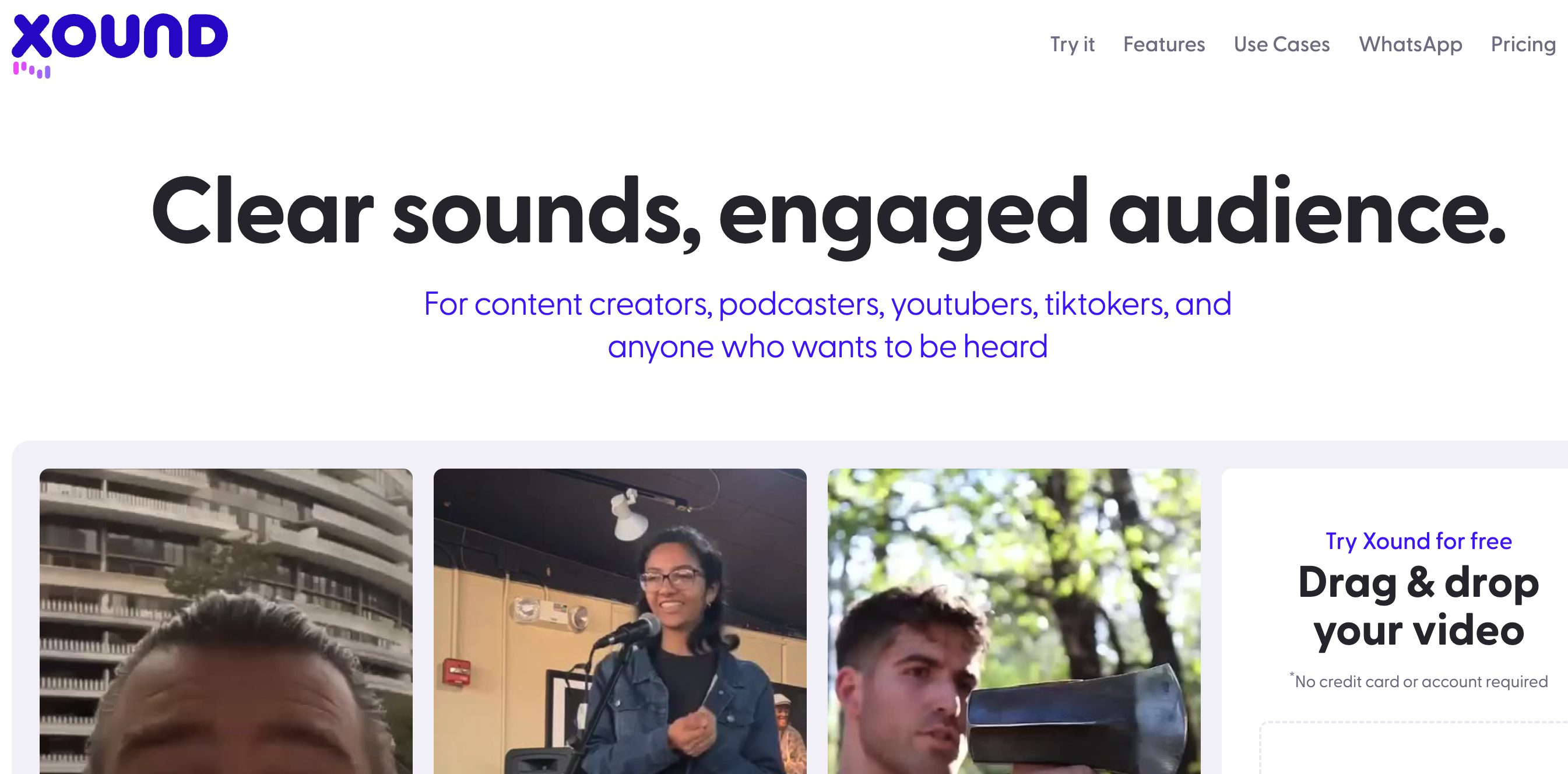
Xound是一个人工智能驱动的声音增强系统。它可以自动清理背景噪音,校正音高,提高音频质量,为YouTube和TikTok创作者提供专业水准的音频。该系统使用先进的机器学习算法,可以本地处理音频文件,确保数据隐私安全。主要功能包括降噪、音高校正、音频增强等。适用于创作者、播客主持人、YouTuber等提升内容声音质量,以吸引更多观众。
需求人群:
["YouTuber","TikToker","播客主持人","内容创作者"]
使用场景示例:
Jake H称赞该系统音频增强效果惊人、必备工具
YouTuber Alex R表示不再担心拍摄时的房间噪音
播客主持人Jessica M表示该APP保证每期节目都有出众体验
产品特色:
背景噪音去除
音高校正
音频质量提升
浏览量:61
最新流量情况
月访问量
41.61k
平均访问时长
00:00:23
每次访问页数
2.06
跳出率
38.66%
流量来源
直接访问
39.48%
自然搜索
39.84%
邮件
1.03%
外链引荐
12.57%
社交媒体
5.90%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
德国
3.42%
印度
25.37%
意大利
10.11%
美国
20.38%
越南
5.55%
AI声音增强系统,提升YouTuber内容创作者视频声音质量
Xound是一个人工智能驱动的声音增强系统。它可以自动清理背景噪音,校正音高,提高音频质量,为YouTube和TikTok创作者提供专业水准的音频。该系统使用先进的机器学习算法,可以本地处理音频文件,确保数据隐私安全。主要功能包括降噪、音高校正、音频增强等。适用于创作者、播客主持人、YouTuber等提升内容声音质量,以吸引更多观众。
AI增强语音降噪与增强
resemble-enhance是一个支持语音降噪与增强的AI模型,可以高效去除背景噪声,还原语音细节,提升语音质量。该模型包含降噪模块和增强模块,通过深度学习算法实现语音信号与噪声分离,以及语音品质改善。模型针对高保真44.1kHz语音进行训练,可以输出高品质增强语音。用户可以通过pip安装使用,也可以基于提供的代码定制训练自己的模型。该模型功能强大,使用简单,是提升语音质量的首选方案。
声音优化,让您的声音更出色!
欢迎来到语音技术的未来!通过生成式语音AI,以前所未有的高质量音频体验,提升您的声音至专业级质量。无论您是在录制播客、使用低质量耳机还是处理讨厌的背景噪音,我们的技术都能将您的音频提升至专业级质量。我们的AI语音增强技术使用先进的算法,提高口语的清晰度和质量。我们不仅可以抑制背景噪音,还可以消除房间共振、补偿低质量耳机和修复数字伪影。我们甚至可以恢复音频信号中丢失的组成部分和频率!即使在嘈杂的办公室里使用廉价耳机,您的声音也可以听起来像是在音乐工作室录制的。我们的AI语音增强技术非常适用于任何以音频为重点的应用。无论您是构建视频会议应用程序、播客平台、音频录制或传输硬件,还是任何其他类型的语音产品,我们的技术都将提高语音的可懂性,减少误解,并增加用户的关注度,使沟通更加有效和引人入胜。
Levelr提供AI音频修复、母带处理、语音隔离与增强等功能。
Levelr是一款专注于AI音频处理与分析的产品。其核心技术为利用人工智能算法对音频进行处理,涵盖音频修复、母带处理、语音隔离与增强等功能。该产品的重要性在于极大地简化了音频后期制作流程,提升了音频质量。主要优点包括能够高效去除背景噪音、清晰分离语音、提升语音清晰度,适用于多种音频处理场景。产品定位为满足不同行业对高质量音频处理的需求,无论是专业音频制作人员还是普通用户,都能借助其强大功能提升音频内容质量。价格方面,提供免费试用,用户可先体验产品功能。
AI驱动的视频音频增强解决方案,提供视频超分辨率、降噪、音频上混等功能。
UniFab 是一款强大的 AI 助力的视频音频增强工具。它利用先进的超分辨率技术,能够将视频分辨率提升至 8K/16K,同时将 SDR 转换为 HDR,为用户提供影院级的视觉体验。其 AI 驱动的深度学习能够智能分析并优化每一帧画面,呈现出鲜艳的色彩、逼真的细节和清晰的视觉效果。此外,UniFab 还支持音频上混功能,可将音频轨道升级为 EAC3 5.1/DTS 7.1 环绕声,让用户沉浸在电影般的听觉享受中。该产品主要面向摄影师、影视爱好者、视频创作者等群体,帮助他们优化视频内容,提升创作质量。
改变你的声音,享受声音的魔力
Voices AI是一款专为iOS设计的语音转换应用程序,可生成声音、克隆自定义声音并通过AI音频增强提高声音质量。它提供了广泛的声音库,从标志性的政治人物到好莱坞名人,让你的文本变得更加生动。对于内容创作者,它可以为视频、电视片段、商业广告等项目提供行业标准的配音。它还可以为你的朋友制作特别的生日祝福,或者让你享受听到著名声音回响你的情感的快感。它具有高质量的音频,直观的界面和隐私保护。你可以使用它克隆自己的声音,利用它的AI音频增强功能提高音频质量。
去除音频中的废话声音
Cleanvoice AI是一种人工智能,可以从您的播客或音频录音中去除填充声音(如“嗯”、“呃”)、嘴部声音(如唇舌音)和口吃声。它可以自动检测和删除这些声音,帮助您节省大量编辑时间。您可以免费试用30分钟,无需信用卡。
免费AI音频过滤器,清理口语音频
Enhance Speech from Adobe是一款免费的AI音频过滤器,可以将口语音频处理得像在声音隔音工作室中录制的一样。它可以自动清除背景噪音,调整音量平衡,提升音频质量。用户可以将录音文件上传到该平台,通过AI算法进行音频优化处理。Enhance Speech from Adobe适用于广播、播客、音频制作等领域。该产品完全免费使用。
开源音频样本和声音设计模型
Stable Audio Open是一个开源的文本到音频模型,专为生成短音频样本、音效和制作元素而优化。它允许用户通过简单的文本提示生成高达47秒的高质量音频数据,特别适用于创造鼓点、乐器即兴演奏、环境声音、拟音录音等音乐制作和声音设计。开源发布的关键好处是用户可以根据自己的自定义音频数据微调模型。
AI 声音生成与训练工具包
Kits AI 是一个 AI 声音生成和免费 AI 声音训练平台,让音乐人使用和创建 AI 声音。您可以使用 Kits.AI 来改变您的声音,使用我们的官方授权或免费声音库中的 AI 艺术家声音,也可以从头开始创建、训练和分享您自己的 AI 声音。主要功能包括 AI 声音转换、AI 声音克隆、文字转语音、声音分离等。Kits AI 与艺术家和创作者直接合作,以正式授权他们的 AI 声音模型。定价请访问官网获取详细信息。
通过时间变化信号和声音模仿生成可控音频的模型
Sketch2Sound是一个生成音频的模型,能够从一组可解释的时间变化控制信号(响度、亮度、音高)以及文本提示中创建高质量的声音。该模型能够在任何文本到音频的潜在扩散变换器(DiT)上实现,并且只需要40k步的微调和每个控制一个单独的线性层,使其比现有的方法如ControlNet更加轻量级。Sketch2Sound的主要优点包括从声音模仿中合成任意声音的能力,以及在保持输入文本提示和音频质量的同时,遵循输入控制的大致意图。这使得声音艺术家能够结合文本提示的语义灵活性和声音手势或声音模仿的表现力和精确度来创造声音。
为您的声音增加颜色
Cosonify是一个音乐增强工具,能够为您的声音增加颜色。通过使用高级的音频处理技术和效果,Cosonify能够改善音频质量,提升音乐体验。我们提供多种音频处理选项,包括均衡器、压缩器、混响和其他音效效果。Cosonify适用于任何需要提升音频质量的场景,包括音乐制作、音乐播放、视频制作等。我们的定价灵活,并提供免费试用。无论您是专业音乐人还是音乐爱好者,Cosonify都能满足您的需求。
音频变声技术,转换声音同时保留原始表达和情感
Voice Changer是Cartesia推出的一款音频变声模型,它能够在转换音频声音的同时,保持原始音频的表达方式和情感。这项技术基于Cartesia在状态空间模型(SSM)架构上的开创性工作,能够以惊人的质量处理和生成高分辨率的声音。Voice Changer的主要优点包括自然语音保留、精确控制交付、多样化的使用场景以及与Sonic声音生成技术的结合使用。
AI音频母带处理
Mastermallow AI Audio Mastering是一个智能音频母带处理服务,旨在为内容创作者、音乐家和播客人士提供专业的音频处理。通过AI技术,将您的歌曲、播客等转化为行业级音频轨道。无需预约,快速完成。相较于传统的专业音频工程师,成本降低了20倍,速度提高了100倍。不满意不付款。
SimpleClean免费去除音视频背景噪音,是播客、视频和旁白的最佳AI音频清洁器。
SimpleClean是一款在线音频清洁工具,其核心功能是利用先进的AI技术去除音频和视频中的背景噪音。该产品的重要性在于满足了创作者对于高质量音频的需求,解决了传统噪音去除软件复杂且昂贵的问题。其主要优点包括:操作简单,无需安装软件,通过浏览器即可完成操作;采用AI降噪技术,能自动消除背景声音;支持批量上传文件,处理完成后会通过邮件通知用户;定价透明,仅按使用量付费,无锁定功能和复杂的积分系统;支持所有音频和视频文件格式。产品定位为面向广大创作者,提供专业、便捷、低成本的音频清洁服务。
智能视频到音频生成,简化声音设计。
Resona V2A是一款AI驱动的视频到音频生成技术产品,它能够仅通过视频数据自动生成与场景、动画或电影完美匹配的声音设计、效果、拟音和环境音。该技术通过自动化音频创作过程,节省了大约90%的时间和努力,使得音频制作更加高效和智能。Resona V2A技术正在被电影制作、动画、教育和多媒体项目等行业专家和团队测试,他们对音频生产流程的效率和卓越性有严格要求。
ComfyUI节点,用于MMAudio模型的音频处理
ComfyUI-MMAudio是一个基于ComfyUI的插件,它允许用户利用MMAudio模型进行音频处理。该插件的主要优点在于能够提供高质量的音频生成和处理能力,支持多种音频模型,并且易于集成到现有的音频处理流程中。产品背景信息显示,它是由kijai开发的,并且是开源的,可以在GitHub上找到。目前,该插件主要面向技术爱好者和音频处理专业人士,可以免费使用。
在线音频母带处理
eMastered是由葛莱美奖得主工程师打造的在线音频母带处理工具。它使用人工智能技术,快速、简单地提升音频质量。用户可以上传音轨并自动应用专业的EQ、压缩等处理,获得高质量的音频母带。eMastered提供免费试用和付费订阅两种方式,适用于音乐制作人、制作公司等各类用户。
专业AI音频处理工具,可检测水印、去除杂音、增强空间音频等。
SpectraHertz是由Music Machines LLC开发的一款专业AI音频处理工具,为现代音乐制作人提供了强大的音频修复和处理能力。它具有高精度的AI音乐检测、高效的杂音去除、灵活的水印嵌入和卓越的空间音频增强等功能。该工具采用按使用付费的定价模式,无订阅费用和隐藏费用,有Starter、Pro、Studio三种套餐可供选择,价格分别为10美元、25美元和50美元,适合不同需求和规模的用户。其最大的优点在于利用先进的AI技术,能够在保证音频质量的前提下,快速、精准地完成各种音频处理任务,同时采用零知识加密保障用户音频数据安全。
Stable Audio 3在线工作台,可用于AI音乐、声音设计、音频修补等
Stable Audio 3是Stability AI推出的新音频模型家族,有Small、Medium和Large版本,Small与Medium提供开放权重,Large面向更高阶生产部署。其主要优点在于支持最长约六分钟的可变长度生成,适合完整音乐弧线等;强调音频修补与续写,工作流更接近音频制作。价格方面,方案与定价随积分与用量扩展,兼顾轻度与重度使用,有入门性价比、创作者用量、团队弹性等不同方案。定位是面向艺术实验、长音频创作、声音设计以及可编辑生成的需求。
全球领先的降噪应用
Krisp是全球领先的降噪应用,通过AI技术实现通话时的背景噪音消除和回声抑制,提供高效的在线会议体验。Krisp能够消除其他人说话时的背景声音,同时保留你的声音。它还能消除麦克风和扬声器中的背景噪音,确保无干扰的通话。Krisp还提供实时的口音转换,帮助客户更好地理解坐席,使坐席的口音与客户的母语口音相匹配。Krisp免费使用,同时提供付费版用于商业用户。
Online AI音频母带处理工具与聊天
DIKTATORIAL Suite是一款在线AI音频母带处理工具,通过聊天交互方式与虚拟声音工程师对话。它可以提供清晰的音频效果,支持wav和mp3等多种音频格式。用户可以描述他们希望达到的音频效果,调整音频参数以满足个人喜好。DIKTATORIAL Suite的优势包括即时优化,适用于流媒体平台,安全可靠等。定价根据不同的套餐选项而定。DIKTATORIAL Suite适用于音频专业人员、音乐家、母带工程师以及初学者。
音频处理和生成的深度学习库
AudioCraft 是一个用于音频处理和生成的 PyTorch 库。它包含了两个最先进的人工智能生成模型:AudioGen 和 MusicGen,可以生成高质量的音频。AudioCraft 还提供了 EnCodec 音频压缩 / 分词器和 Multi Band Diffusion 解码器等功能。该库适用于音频生成的深度学习研究。
训练自定义 AI 声音模型,生成逼真而美妙的声音,保护声音版权
Revocalize AI 是一款音乐制作与处理工具,能够作为声音美化器、合成器、和均衡器,为声音带来全新的革命性体验。它就像是 Photoshop 一样,但专注于声音。 Revocalize AI 可以训练自定义的 AI 声音模型,也可以使用其他模型来生成逼真而美妙的声音轨。用户可以通过这款工具在声音处理领域迈向未来。 主要功能: - 声音合成,不受限制 - 无尽的声音可能性 - 终极的情感表达 - 语言多样性 - 实时自动调音 - 自动生成声音变化 - 专业声音调制 Revocalize AI 已被 10,000 多名艺术家、品牌和开发者所信任,共同构建未来的声音世界。
快速、准确、免费的音频转文字服务
AIbase音频提取文字工具利用人工智能技术,通过机器学习模型快速生成高质量的音频文本描述,优化文本排版,提升可读性,同时完全免费使用,无需安装、下载或付款,为创意人员提供便捷的基础服务。

© 2026 AIbase 备案号:闽ICP备08105208号-14