浏览量:8023
最新流量情况
月访问量
8798.43k
平均访问时长
00:03:27
每次访问页数
2.86
跳出率
53.18%
流量来源
直接访问
49.61%
自然搜索
48.31%
邮件
0.01%
外链引荐
1.54%
社交媒体
0.47%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
法国
3.58%
英国
3.11%
印度
5.52%
俄罗斯
10.00%
美国
15.17%
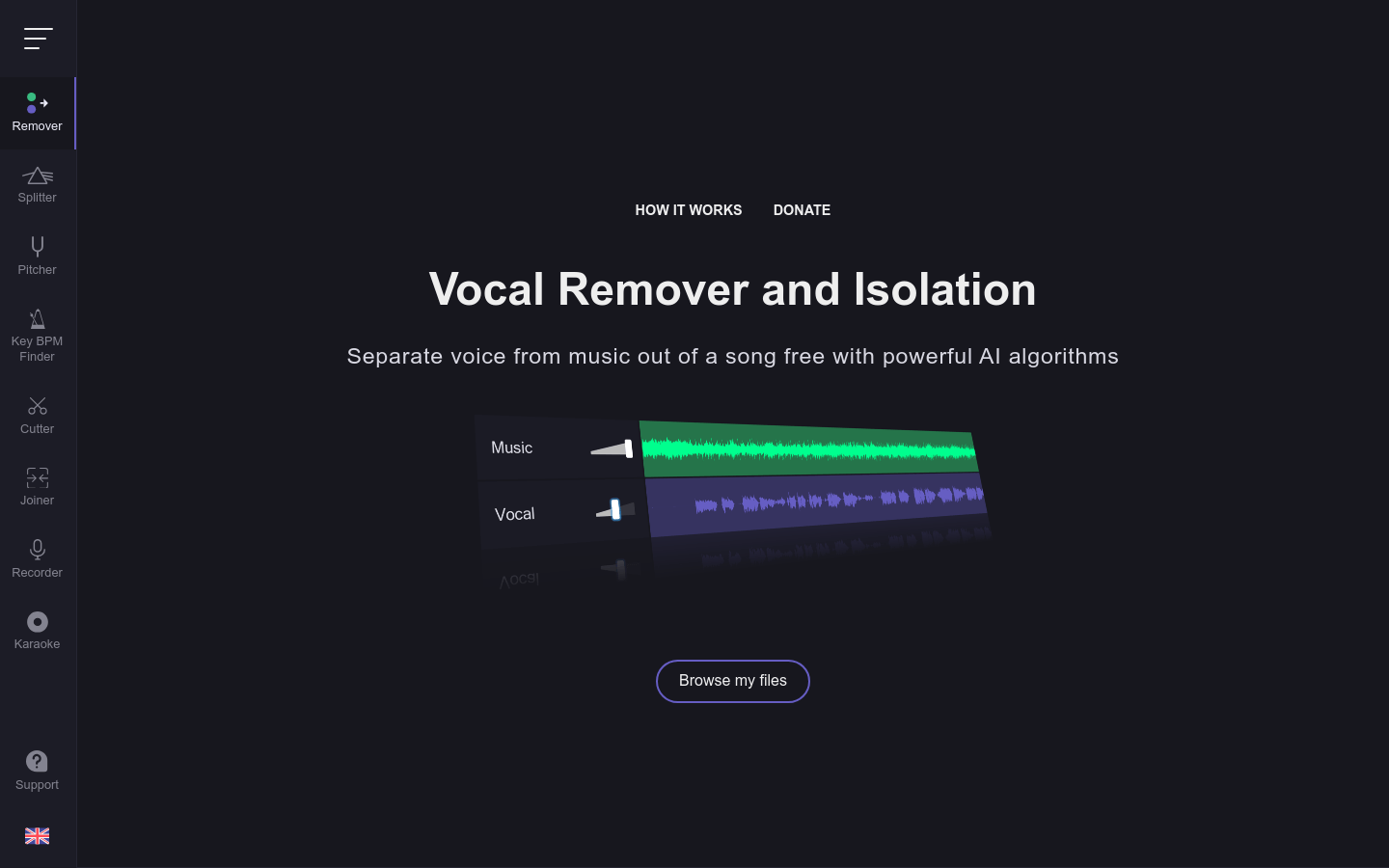
在线音轨分离工具
vocalremover org是一个在线音轨分离工具,可以将音乐中的人声和伴奏分离出来。它具有简单易用的界面,能够快速高效地分离音轨,并且可以导出分离后的音频文件。vocalremover org支持多种音频格式,并且完全免费使用。
使用Voicss - AI音轨去除器,轻松制作卡拉OK音轨,分离音轨中的人声与乐器。
Voicss是一款AI音轨去除器,能够智能分离音乐中的人声和背景音乐,适用于音乐编辑、卡拉OK制作等领域,无需下载软件。
SpleeterGUI 是一款音乐源分离桌面应用程序。
SpleeterGUI 是一个音乐源分离的桌面应用程序,用户无需安装 Python 或 Spleeter,该应用程序内含预装 Python 版本和 Spleeter。通过分离音轨,用户可以从音乐中提取出不同的声音源,提供了更灵活的音频处理能力。
最佳在线工具,用于从音频文件中分离人声和伴奏。
AudioStrip是音乐人用来从音频文件中分离人声和伴奏的最佳在线工具。用户可以免费使用AudioStrip,也可以付费升级到高级版,以获得批量上传、10倍更快的分离速度等更多功能。该服务使用最高质量的算法,操作简单,快速获得分离效果,可以同时分离多个音频文件。用户可以免费使用,也可以选择付费高级版,价格为每月5.99英镑。
免费人声分离工具 分离伴奏背景音乐提取
终极人声去除GUI是一款使用深度神经网络技术的人声去除工具。其核心开发者训练了所有提供的模型,除了Demucs v3和v4 4声道模型。该应用使用先进的源分离模型从音频文件中去除人声。无需额外的先决条件即可有效运行。适用于Windows 10及以上版本。
快速、准确、免费的音频转文字服务
AIbase音频提取文字工具利用人工智能技术,通过机器学习模型快速生成高质量的音频文本描述,优化文本排版,提升可读性,同时完全免费使用,无需安装、下载或付款,为创意人员提供便捷的基础服务。
集AI音乐创作、语音转换等多功能于一体的音频工具平台
Lalals是一款基于领先AI技术的音频工具平台。其重要性在于为音乐创作者、音频处理人员等提供了一站式的音频处理解决方案。主要优点包括功能丰富多样,拥有1000多种AI语音,支持多种音频处理操作,处理速度快,能极大提高工作效率。产品背景是为满足音乐创作和音频处理领域不断增长的需求而开发。关于价格,文中提到可以免费开始使用,具体是否有付费模式未明确提及,定位是面向广大音乐创作者、音频爱好者等群体。
MVSEP能够将音频中的语音和音乐部分分离。
MVSEP是一款在线音频处理工具,利用先进的音频分离技术可将音乐和语音从音频文件中分离出来,适用于音乐制作、音频编辑、广播、电影后期制作等领域。优点包括高质量的音频输出、快速的处理速度和用户友好的操作界面。提供不同模型选择。
利用AI技术分离音乐/视频中的人声和伴奏
易我人声分离是一款在线工具,它使用人工智能算法将音频或视频中的人声和伴奏分离,支持多种音频和视频格式,如MP3、WAV、M4A、FLAC等。这款工具对于音乐制作人、歌曲创作者、K歌爱好者以及需要音频编辑的专业人士来说非常有用。它提供了不同版本的订阅服务,包括年版、月版、推荐包和基础包,用户可以根据自己的需求选择合适的版本。
基于自然语言查询的开放领域音频源分离模型
AudioSep是一种基于自然语言查询的开放领域音频源分离模型。它由文本编码器和分离模型两个关键组件组成。我们在大规模多模态数据集上训练AudioSep,并在许多任务上广泛评估其能力,包括音频事件分离、乐器分离和语音增强。AudioSep表现出强大的分离性能和令人印象深刻的零样本泛化能力,使用音频标题或文本标签作为查询,大大优于以前的音频查询和语言查询声音分离模型。为了保证本工作的可重复性,我们将发布源代码、评估基准和预训练模型。
使用Gradio UI的Ultimate Vocal Remover 5,分离音频文件。
UVR5-UI是一个基于python-audio-separator的开源项目,它提供了一个用户友好的界面来分离音频文件中的不同音轨,使用了多种模型来实现高质量的音频分离。该项目特别适合音乐制作者、音频编辑者和任何需要从音频中移除或分离特定声音的人。UVR5-UI支持从多个网站批量分离音频,并且可以在Colab和Kaggle上运行,为使用者提供了极大的便利。
RipX DAW AI 分轨编辑工具
RipX DAW 是一款获奖的 AI 分轨编辑工具,可以将音乐混音文件分离成 6 个以上的音轨,支持逐音符编辑和替换音轨,拥有无与伦比的混音能力和乐器替换功能。RipX DAW PRO 还提供强大的音轨清理、音频修复和音效处理工具。定价请参考官网。
音乐人的AI音频分离工具
Moises是一款专为音乐人设计的应用程序,利用人工智能技术分离音乐中的人声和乐器声音,帮助音乐爱好者、学生、教师和社交媒体内容创作者等目标用户群体学习和创作音乐。产品背景信息显示,Moises以其先进的AI音频分离技术,为用户提供了一种全新的音乐学习与创作方式,其主要优点包括操作简便、功能全面以及对多种音频格式的支持。Moises提供免费版本,并提供月度和年度的高级订阅服务。
Online AI音频母带处理工具与聊天
DIKTATORIAL Suite是一款在线AI音频母带处理工具,通过聊天交互方式与虚拟声音工程师对话。它可以提供清晰的音频效果,支持wav和mp3等多种音频格式。用户可以描述他们希望达到的音频效果,调整音频参数以满足个人喜好。DIKTATORIAL Suite的优势包括即时优化,适用于流媒体平台,安全可靠等。定价根据不同的套餐选项而定。DIKTATORIAL Suite适用于音频专业人员、音乐家、母带工程师以及初学者。
用强大的人工智能算法将声音从音乐中分离出来
这个免费的在线应用程序通过创建卡拉 OK 来帮助去除歌曲中的人声。当你选择了一首歌曲,人工智能将把人声从器乐中分离出来。你将得到两条音轨 - 你的歌曲的卡拉 OK 版本(没有人声)和阿卡贝拉版本(无伴奏纯人声)。尽管此服务复杂且成本高,但你仍然可以完全免费使用它。处理通常需要 10 秒左右。
通过音频扩散模型实现源分离和合成的创新方法。
Audio-SDS 是一个将 Score Distillation Sampling(SDS)概念应用于音频扩散模型的框架。该技术能够在不需要专门数据集的情况下,利用大型预训练模型进行多种音频任务,如物理引导的冲击声合成和基于提示的源分离。其主要优点在于通过一系列迭代优化,使得复杂的音频生成任务变得更为高效。此技术具有广泛的应用前景,能够为未来的音频生成和处理研究提供坚实基础。
在线音频母带处理
eMastered是由葛莱美奖得主工程师打造的在线音频母带处理工具。它使用人工智能技术,快速、简单地提升音频质量。用户可以上传音轨并自动应用专业的EQ、压缩等处理,获得高质量的音频母带。eMastered提供免费试用和付费订阅两种方式,适用于音乐制作人、制作公司等各类用户。
强大的 AI 音乐工具,轻松去除人声和分离乐器。
Coolo.ai 是一款功能强大的在线音频工具,利用 AI 技术帮助用户快速去除音乐中的人声、分离乐器轨道、检测 BPM 和音调。该产品适用于音乐制作、卡拉 OK 创作和教育等场景,且完全免费,无使用限制,适合所有音乐爱好者和专业人士。用户可以在网页上直接处理音频,享受高质量的音频输出。随着音乐制作的普及,该工具填补了用户对快速音频处理和高质量音频分离的需求。
免费在线音频剪辑工具,可无损裁剪MP3、WAV等格式音频,无需安装。
Audio Cut是一款免费的在线音频剪辑工具,用户无需安装软件,通过网页浏览器即可直接使用。其重要性在于为用户提供了便捷、高效且安全的音频剪辑解决方案。主要优点包括支持多种音频格式、处理速度快、能保持音频无损质量以及注重用户数据隐私。该工具定位为面向广大音频处理需求者,无论是专业人士还是普通用户,都能轻松使用它完成日常音频剪辑任务。价格方面,完全免费使用。
一款基于AI的免版税音乐生成与音频处理工具,可将文本、歌词或创意秒变高品质音乐。
FreeMusicCreator.ai 是一款尖端的 AI 音乐生成平台,旨在打破传统音乐创作的高门槛与高成本。该产品背景基于当前创作者经济对版权音乐的巨大需求,通过先进的人工智能技术,让用户无需懂乐理或编曲,即可在数秒内创作出专业级歌曲。产品主要优点在于高效、免版税以及功能全面,不仅能生成音乐,还集成了人声分离和音轨拆分等实用工具。其产品定位为创作者的 AI 音乐助手,价格采取免费+订阅制(Freemium)模式,既提供免费的基础额度,也为有商业变现需求的用户提供超值的付费方案。
AI驱动的图像分割工具,实现精准的背景与前景分离。
Matting by Generation是一个利用人工智能技术进行图像分割的在线工具。它能够识别图像中的前景和背景,实现精准分离,广泛应用于设计、视频制作和图像编辑等领域。产品的主要优点包括高效率、易操作和高质量的分割效果。
快速分离音乐中的人声和乐器,制作高质量卡拉OK、伴奏、清唱或纯音乐。
Singify Vocal Remover是一款利用先进AI技术提取音乐中人声和乐器的工具。它能够准确提取歌曲的人声,并隔离单独的鼓、贝斯、钢琴、电吉他、原声吉他和合成器等部分。该工具免费易用,保留原始音频细节,支持多种音频输出格式。
视听源分离系统
PixelPlayer是一个能够通过观看大量无标注视频学会定位产生声音的图像区域并分离输入声音成一组表示每个像素声音的组件的系统。我们的方法利用视觉和听觉双模态的自然同步特点,在不需要额外人工标注的情况下学习联合解析声音和图像的模型。该系统使用大量包含不同乐器组合独奏和二重奏演奏的训练视频进行训练。对每个视频没有提供出现了哪些乐器、它们在哪里以及它们是什么声音的监督。在测试阶段,系统的输入是一个展示不同乐器演奏的视频和单声道听觉输入。系统执行音频视觉源分离和定位,将输入声音信号分离成N个声音通道,每个通道对应不同的乐器类别。此外,系统可以定位声音并为输入视频中的每个像素分配不同的音频波形。
音频转文字,快速高效
Rythmex是一款在线音频转文字工具,支持超过140种语言,用户只需上传音频或视频文件,选择对应的语言,即可在60秒内开始编辑并下载转换后的文本。该产品功能强大,优势在于快速、准确地将音频转换为文字,定价灵活,定位于商业用户和教育用户。
强大的AI人声移除器,可免费快速分离歌曲人声,制作高质量音轨。
该产品是基于先进AI技术的在线人声移除工具。其重要性在于为音乐创作、娱乐等领域提供了便捷的人声与乐器分离解决方案。主要优点包括无需下载和注册、无广告、处理速度快、输出音频质量高。产品背景是满足用户对于免费、高效分离歌曲人声的需求。价格方面完全免费,定位面向创作者、专业人士、音乐爱好者等广泛人群。
AI音频母带处理
Mastermallow AI Audio Mastering是一个智能音频母带处理服务,旨在为内容创作者、音乐家和播客人士提供专业的音频处理。通过AI技术,将您的歌曲、播客等转化为行业级音频轨道。无需预约,快速完成。相较于传统的专业音频工程师,成本降低了20倍,速度提高了100倍。不满意不付款。

© 2026 AIbase 备案号:闽ICP备08105208号-14