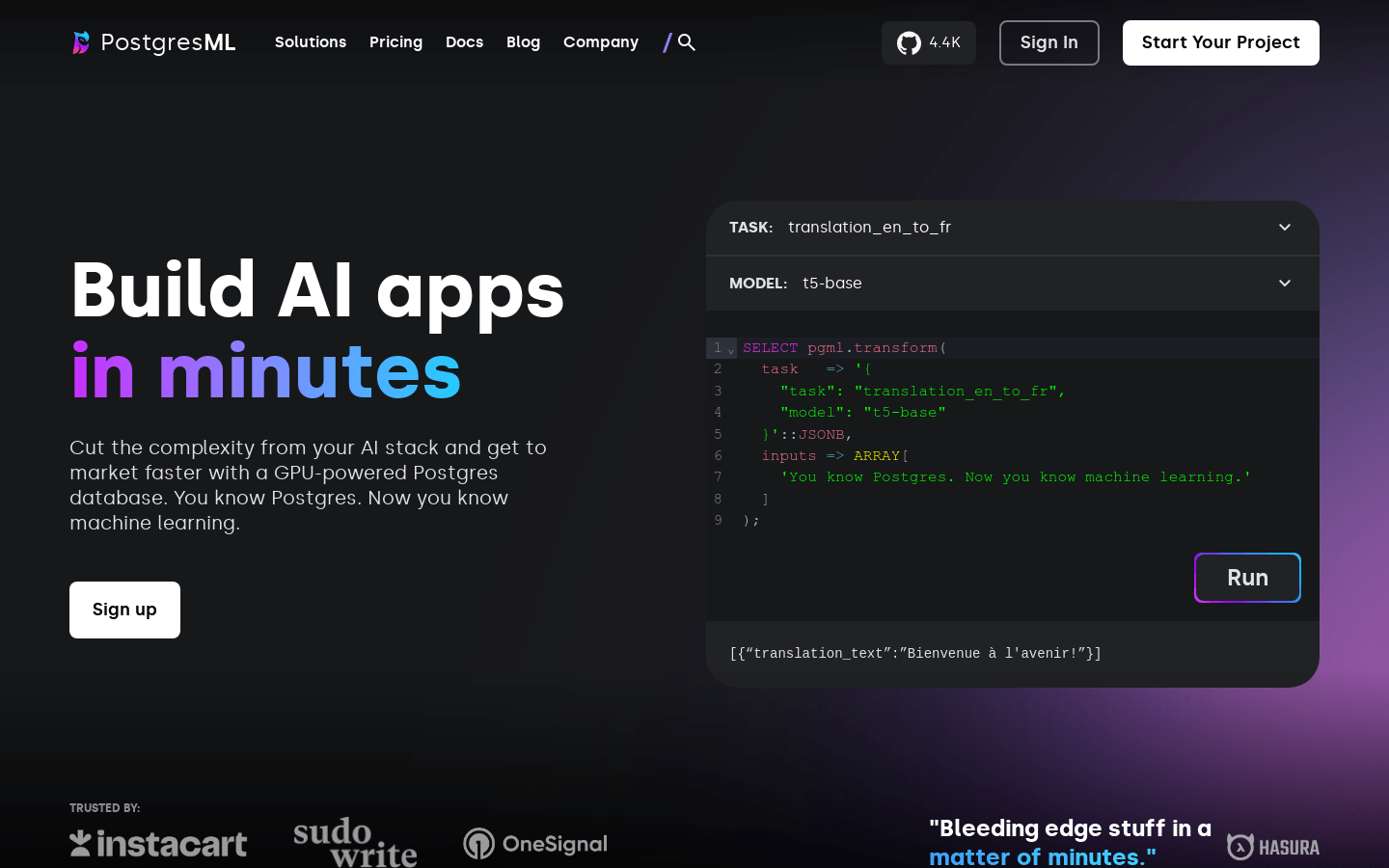
PostgresML是一个GPU加速的Postgres数据库,可帮助您快速构建AI应用程序。它简化了AI堆栈的复杂性,让您更快地进入市场。通过PostgresML,您可以使用各种机器学习模型,如文本分类、机器翻译、问题回答等。它还提供了可扩展性、高效性和安全性。了解更多信息,请访问官方网站。
需求人群:
PostgresML适用于构建聊天机器人、智能玩具、搜索引擎管理等AI应用程序。
使用场景示例:
使用PostgresML构建智能玩具的聊天功能
利用PostgresML实现欺诈检测系统
使用PostgresML进行文本分类任务
产品特色:
文本分类
机器翻译
问题回答
时间序列预测
欺诈检测
聊天机器人
智能玩具
搜索引擎管理
浏览量:90
最新流量情况
月访问量
1373
平均访问时长
00:01:02
每次访问页数
2.25
跳出率
37.66%
流量来源
直接访问
45.45%
自然搜索
37.31%
邮件
0.09%
外链引荐
8.05%
社交媒体
7.84%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
德国
21.38%
印度尼西亚
1.62%
印度
5.96%
美国
71.04%
高性能AI应用的向量数据库
Pinecone是一个全面管理、开发人员友好且可轻松扩展的向量数据库,可通过API调用以毫秒级时间搜索数十亿个项目的相似匹配。它是下一代搜索技术,只需一个API调用即可使用。
数据库GUI工具与OLAP数据库的完美结合
DB Pilot是一个数据库GUI工具,支持PostgreSQL、MySQL、SQLite等多种数据库。它还集成了OLAP数据库,可以连接各种数据源。内置的AI助手使得编写SQL查询变得简单易懂。定价分为免费版、Plus版和Pro版。
将AI引入您最喜爱的数据库!
SuperDuperDB是一个可以将AI直接集成和训练到您喜欢的数据库的工具。只需使用Python,无需复杂的MLOps流程和专门的向量数据库。它允许您在数据库中进行实时推断和模型训练,将现有数据库转化为完全功能的向量数据库,并能与各种机器学习框架和AI API无缝集成。请访问官方网站了解更多信息。
AI驱动的数据库跨平台工具,让数据查询和分析更简单。
Chat2DB是一个AI驱动的数据库跨平台工具,它允许用户通过自然语言与数据库进行交互,生成高性能的SQL语句,优化查询性能,并提供数据导入导出、数据库迁移等功能。产品背景信息显示,Chat2DB旨在帮助技术型和非技术型用户节省数据处理时间,提供一站式数据库管理,深入洞察数据,并轻松驾驭复杂分析。产品定位为开源工具,采用Apache 2.0许可证,支持多种数据库类型,注重数据安全和隐私保护。
高性能、成本效益的向量数据库,为GenAI应用打造。
Zilliz Cloud Serverless是一个为GenAI应用设计的高性能向量数据库服务,它提供了自动扩展的数据库能力,成本随着业务增长而增加。该产品使用分层存储系统,结合DRAM、SSD和对象存储自动优化数据放置,确保活跃数据快速访问的同时降低不常用信息的成本,无需手动管理。Zilliz Cloud Serverless以其成本效益、数据可移植性和自动扩展能力,为需要处理大规模向量数据的企业提供了一个强大的解决方案。
AI风险数据库与分类系统
AI Risk Repository是一个全面的生活数据库,收录了700多个AI风险,并根据其原因和风险领域进行了分类。它提供了一个易于访问的AI风险概览,是研究人员、开发者、企业、评估者、审计师、政策制定者和监管者共同参考的框架,有助于发展研究、课程、审计和政策。
NeoBase 是一款开源的 AI 数据库助手,让你用自然语言与数据库交互。
NeoBase 是一款创新的 AI 数据库助手,通过自然语言处理技术让用户能够以对话的方式与数据库进行交互。它支持多种主流数据库,如 PostgreSQL、MySQL、MongoDB 等,并且可以与 OpenAI、Google Gemini 等 LLM 客户端集成。其主要优点是简化了数据库管理流程,降低了技术门槛,使非技术用户也能轻松管理和查询数据。NeoBase 采用开源模式,用户可以根据自身需求进行定制和部署,确保数据安全性和隐私性。它主要面向需要高效管理和分析数据的企业和开发者,旨在提高数据库操作的效率和便捷性。
与数据库交互的更好方式
TableTalk是一种更好的与数据库交互的方式。我们利用人工智能来更好地映射您的数据库,以一种类似与人对话的方式进行交互。我们构建了一个自然语言界面,让您可以向数据库提问并以熟悉的方式得到答案。我们目前处于测试阶段,正在寻找更多用户帮助我们打造最好的产品。准备好您的数据库,并敬请关注更多更新。
数据库设计助手,简化数据库设计、管理和演化。
Nabubit是一个旨在帮助用户优化数据库设计、管理和演化的在线工具。它提供了上传数据库架构图、可视化数据库结构、以及使用自然语言提问的功能。用户可以从头开始设计数据库,无需担心命名或记住语法。完成设计后,可以将其导出到自己喜爱的数据库或框架中。
使用AI查询数据库,无需SQL知识
PlasticDB是一款使用人工智能技术查询数据库的工具,无需SQL知识。用户只需输入数据库连接信息,使用自然语言查询数据即可。PlasticDB能够快速准确地返回用户所需的数据,大大提高了数据查询的效率和便捷性。支持PostgreSQL、MySQL、MariaDB、SQL Server等多种数据库类型。PlasticDB的免费版功能丰富,适合个人和小型团队使用。
SAP HANA Cloud是一种基于内存的数据库即服务(DBaaS)
SAP HANA Cloud是一种用于现代应用和分析的单一数据库即服务(DBaaS)基础。它提供了高性能、可扩展的内存数据库解决方案,可帮助企业实现实时分析、数据驱动的决策和创新。SAP HANA Cloud具有灵活的定价模型,可根据用户的需求进行灵活调整。
AI数据库调优工具,优化PostgreSQL和MySQL性能
OtterTune是一款AI工具,自动化数据库调优和解决配置问题,优化PostgreSQL和MySQL性能,降低成本。它可以找到95%的数据库优化机会,提高P99性能2倍以上,吞吐量增加25%以上,成本减半。
连接数据库,训练GPT,实时对话
DataLang是一款连接数据库并利用GPT进行实时对话的工具。用户可以通过设置数据视图(如SQL脚本),配置GPT助手,发布定制的GPT到ChatGPT商店,并与用户、员工或客户分享。用户还可以利用DataLang将SQL视图自动转换为API,以及创建定制的GPT助手与数据库进行对话。该产品简化了数据分析流程,用户只需进行简单的数据库配置、数据视图添加、GPT助手选择和定制GPT创建即可实现实时数据交互。
与数据库对话,用自然语言查询数据。
Chat with your Database 是一个创新的数据库交互工具,它允许用户通过自然语言与Postgres数据库进行交互。利用AI技术,用户可以轻松地查询、分析和操作数据库,而无需编写复杂的SQL代码。该产品支持开源,鼓励社区参与开发和贡献,代码在GitHub上公开,用户可以自由探索、贡献或定制以满足特定需求。
AI驱动的数据库平台,简化AI开发流程。
JamAI Base是一个为AI设计的数据库即服务(BaaS)平台,它允许用户通过定义数据模式并将数据发送到平台,直接在应用程序中获得精确的AI响应。该平台通过生成表格和内置的RAG(Retrieval-Augmented Generation)以及chunk reranking功能,增强数据库能力,提供高级的AI集成功能,以确保顶级的准确性。用户无需构建复杂的AI堆栈,即可轻松创建革命性的AI驱动体验。
用户友好的Web数据库客户端,简化数据库访问,保障数据安全。
hoop.dev是一个现代的、基于Web的数据库客户端,旨在简化数据库访问流程,同时不牺牲安全性。它通过AI数据掩码技术保护个人可识别信息,支持从浏览器即时登录访问数据库,无需安装等待。此外,它还提供实时更新和Slack集成,确保团队成员间的信息同步和安全。hoop.dev支持将脚本转化为无代码应用,通过链接Git仓库、嵌入变量来实现。它还提供了多种快速启动选项,如Kubernetes、Docker、Unix等,适用于金融科技、健康科技等高度监管的行业。
AI驱动的数据库查询分析工具
Prisma Optimize是一个利用人工智能技术来分析和优化数据库查询的工具。它通过提供深入的洞察和可操作的建议来提高数据库查询效率,从而加速应用程序的运行。Prisma Optimize支持多种数据库,包括PostgreSQL、MySQL、SQLite、SQL Server、CockroachDB、PlanetScale和Supabase等,能够无缝集成到现有的技术栈中,无需进行大规模的修改或迁移。产品的主要优点包括提高数据库性能、减少查询延迟、优化查询模式等,对于开发者和数据库管理员来说,这是一个强大的工具,可以帮助他们更有效地管理和优化数据库。
超快速、实时、专业友好、无代码数据库
Teable是一个结合了SQL能力与电子表格协作的顶级解决方案,直接连接到Postgres,提供协作体验,超越Airtable,满足运营数据需求,显著加速快节奏的创业团队。集成了AI能力,可以快速创建应用程序、分析数据、创建视图、执行操作等。
Streamlit是一个开源Python库,用于快速构建数据应用和机器学习产品原型。
Streamlit是一个开源Python库,让数据科学家和机器学习工程师可以快速地在Web浏览器中创建Beautiful,自定义的机器学习应用程序和数据应用程序。无需学习前端Web开发,Streamlit应用可以在几分钟内从简单的脚本构建。Streamlit提供了简单的API来创建各种交互式小部件,如文本、图像、表格、图表、视频等,从而使数据探索和展示变得轻松。它具有内置支持的数据框架,如Pandas、Numpy、Matplotlib等。它兼容大多数Python机器学习库,如Scikit-learn、TensorFlow等。
在几分钟内构建AI应用程序
PostgresML是一个GPU加速的Postgres数据库,可帮助您快速构建AI应用程序。它简化了AI堆栈的复杂性,让您更快地进入市场。通过PostgresML,您可以使用各种机器学习模型,如文本分类、机器翻译、问题回答等。它还提供了可扩展性、高效性和安全性。了解更多信息,请访问官方网站。
数据库界面化工具,简化数据探索与协作
Outerbase是一个简化数据探索和协作的数据库界面化工具。它允许用户在不需要数据库专家的情况下,通过可视化界面来查看、更新和可视化数据。用户可以创建查询、列、行、表和模式,而无需编写SQL语句。用户还可以直接在界面上编辑数据,类似于编辑电子表格。同时,用户可以保存和共享查询,方便团队合作。Outerbase支持多种常见数据库的连接,如Postgres、MySQL、Redshift、Snowflake等。它还提供了EZQL功能,让用户能够轻松查询数据,无需编写SQL语句。用户还可以使用Outerbase创建漂亮的仪表盘和图表,方便数据可视化。Outerbase的目标是让数据探索和协作变得简单易用,无需繁琐的数据仓库。
数据库架构可视化工具
ChartDB 是一个免费且开源的数据库设计编辑器,它允许用户通过单一查询快速生成数据库架构图。这个工具支持多种流行的数据库管理系统,如MySQL、MariaDB、PostgreSQL、Microsoft SQL Server和SQLite。它提供了一个直观的编辑器,用户可以轻松导入、编辑和导出数据库架构,同时支持AI生成DDL脚本,以便于数据库的管理和文档化。
通过对话访问数据库的强大工具
Basejump AI是一个通过自然语言处理技术使数据库查询变得简单的平台。它允许用户通过日常语言与数据库进行交互,从而快速获取所需数据,无需编写复杂的SQL查询。这种技术对于提高工作效率、减少数据分析师的工作负担以及使决策更加数据驱动具有重要意义。Basejump AI提供了多种功能,包括实时数据访问、数据点的可视化、数据集合的创建和数据准确性的比较等。它适用于需要快速数据访问的各种行业,如医疗保健、人力资源、软件开发等。产品提供多种定价计划,包括免费试用和不同规模的企业方案。
免费的人工智能工具数据库
AIFINDY是一个每日更新的免费人工智能工具数据库,为用户提供广泛的AI应用,涵盖社交媒体、艺术创作、文本处理、音乐制作、视频编辑等多个领域。它为个人和企业提供了寻找适合自己需求的AI工具的平台,帮助用户提高效率,激发创造力。
通过自然语言查询数据库,快速获取数据洞察。
Sequel是一个自然语言数据库接口,它允许用户使用自然语言查询数据库,无需编写SQL查询。它通过自然语言处理技术将问题转换为SQL查询,并执行这些查询以返回结果。Sequel支持多种数据库,如PostgreSQL、MySQL和SQLite,并确保与现有数据库的安全连接。它旨在帮助开发者、数据分析师和商业用户更快速、更高效地查询数据库。
CapybaraDB 是一个 AI 原生数据库,让构建智能应用变得简单。
CapybaraDB 是一个 AI 原生数据库,旨在通过内置的 AI 能力简化数据处理和存储。它将 NoSQL、向量数据库和对象存储等多种存储类型统一到一个接口中,使开发者无需管理多个数据库或复杂的管道。CapybaraDB 提供了自动化的数据处理功能,如媒体转文本、文本分块、嵌入生成和向量索引等,大大提高了开发效率。其 MongoDB 兼容性使其能够受益于丰富的生态系统和社区支持。CapybaraDB 定位为高效、低成本的数据库解决方案,适用于需要快速构建 AI 应用的开发者和企业。
无需编写SQL,轻松查看、更新和可视化数据的数据库接口
Outerbase是一个数据库接口,让您能够轻松地协作查看、更新和可视化数据,无需成为数据库专家。您可以创建查询、列、行、表和模式,而无需编写SQL语句。还可以直接在界面上进行数据编辑,并像编辑电子表格一样进行协作。通过组织SQL查询块,您可以轻松保存和共享查询。Outerbase支持多种流行数据库,如Postgres、MySQL、Redshift、Snowflake等。它还提供了直观的用户界面和强大的可视化功能,让您能够轻松创建漂亮的仪表盘和图表。Outerbase适用于任何需要使用数据进行决策的团队。
连接数据库,用简单的英语提问,获得答案
Channel是一个连接数据库的工具,通过使用简单的英语提问,可以获得数据库的答案。它提供了自助数据分析的功能,无需了解SQL语言。Channel能够分析复杂的数据仓库,用简单的英语查询出您所需的答案。它还可以自动生成美观的数据可视化图表,根据您的偏好选择适当的图表类型。不再需要等待所需的数据,任何人,无论是分析师还是产品经理,都可以使用Channel。Channel还提供了共享定义功能,方便您跟踪组织中重要术语的定义。

© 2026 AIbase 备案号:闽ICP备08105208号-14