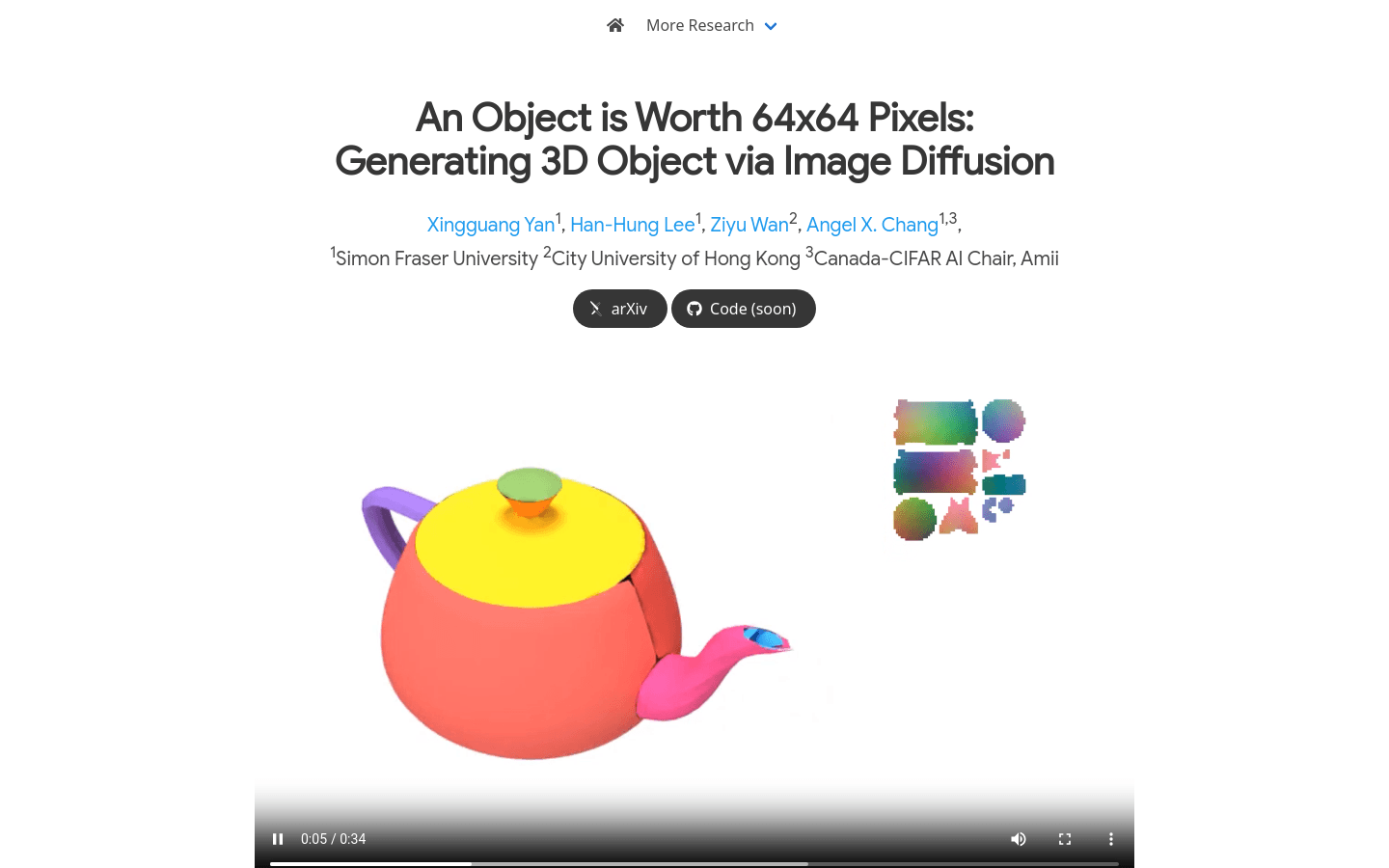
Object Images是一种创新的3D模型生成技术,它通过将复杂的3D形状封装在一个64x64像素的图像中,即所谓的'Object Images'或'omages',来简化3D形状的生成和处理。这项技术通过图像生成模型,如Diffusion Transformers,直接用于3D形状生成,解决了传统多边形网格中几何和语义不规则性的挑战。
需求人群:
"Object Images适合3D设计师、游戏开发者和任何需要高效生成和编辑3D模型的专业人士。这项技术简化了3D模型的创建过程,使得编辑、动画和交互更加容易,同时保持了模型的高质量和细节。"
使用场景示例:
设计师使用Object Images技术快速生成具有复杂几何结构的3D耳机模型。
游戏开发者利用这项技术为游戏角色创建多样化的装备和道具。
教育领域中,学生通过Object Images学习3D建模的基础知识和技巧。
产品特色:
通过64x64像素图像简化3D模型的生成。
支持UV映射,包含表面几何、外观和补丁结构。
使用图像生成模型直接进行3D形状生成。
在ABO数据集上评估,生成的形状具有与最新3D生成模型相当的点云FID。
支持PBR材质生成,如镜子等反射材质。
通过图像扩散模型生成低分辨率omages,展示3D生成的新范式。
在去噪过程中,离散结构从连续图像格式中显现出来。
使用教程:
1. 访问Object Images的官方网站。
2. 了解技术背景和产品介绍。
3. 阅读文档,学习如何将3D形状转换为64x64像素图像。
4. 下载并安装所需的软件或工具。
5. 按照教程,将UV展开的3D模型预处理成omages。
6. 使用Diffusion Transformer学习omages的分布并生成新的3D模型。
7. 根据需要,调整生成的3D模型的材质和细节。
8. 将生成的3D模型应用于设计、游戏开发或其他相关领域。
浏览量:77
最新流量情况
月访问量
1147
平均访问时长
00:00:23
每次访问页数
1.14
跳出率
34.55%
流量来源
直接访问
39.45%
自然搜索
36.76%
邮件
0.21%
外链引荐
12.88%
社交媒体
8.29%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
巴西
20.39%
西班牙
3.71%
印度尼西亚
3.08%
墨西哥
5.37%
美国
67.45%
使用Hunyuan 3D和Seed3D,从文本或图像生成AI 3D模型,免费在线生成。
该产品是一个在线的AI 3D模型生成平台,整合了腾讯的Hunyuan 3D和字节跳动的Seed 3D。其重要性在于打破了传统3D建模的技术门槛,让没有3D技能的用户也能轻松生成3D模型。主要优点包括生成速度快,能在短时间内从文本或图像生成具有完整PBR材质的3D模型;支持多种格式导出,方便在不同的3D软件和平台中使用;用户可以同时运行两个模型并选择最佳输出。价格方面,生成模型需要消耗积分,比如生成一次需要20积分,但也提供免费使用的机会。产品定位是为广大需要3D模型的用户提供便捷、高效的3D模型生成服务。
AI 生成定制 3D 模型
3D AI Studio 是一款基于人工智能技术的在线工具,可以轻松生成定制的 3D 模型。适用于设计师、开发者和创意人士,提供高质量的数字资产。用户可以通过AI生成器快速创建3D模型,并以FBX、GLB或USDZ格式导出。3D AI Studio具有高性能、用户友好的界面、自动生成真实纹理等特点,可大幅缩短建模时间和降低成本。
Tripo AI 3D 模型生成器可将文本和图片几秒内转为可用于生产的3D模型。
Tripo AI 3D 模型生成器是一款在线的AI 3D模型生成工具,集成在一个流畅的工作流程中,能将文字、图片或草图快速转化为可用于生产的3D资产。其主要优点在于速度快,能将数小时的人工3D作业缩短至秒级完成;成本低,借助智能算法提高效率从而降低成本;功能强大,具备文字和图片生成3D模型、智能分割、AI纹理、绑骨与动画等多种功能。产品背景是为了满足创意行业对于高效3D建模的需求。该产品提供免费试用,无需注册,支持导出GLB/STL/OBJ格式,用于游戏和3D打印等领域,定位是为全球创作者提供更智能、更简化的3D建模解决方案。
快速从单张图片生成3D模型。
Stable Fast 3D (SF3D) 是一个基于TripoSR的大型重建模型,能够从单张物体图片生成带有纹理的UV展开3D网格资产。该模型训练有素,能在不到一秒的时间内创建3D模型,具有较低的多边形计数,并且进行了UV展开和纹理处理,使得模型在下游应用如游戏引擎或渲染工作中更易于使用。此外,模型还能预测每个物体的材料参数(粗糙度、金属感),在渲染过程中增强反射行为。SF3D适用于需要快速3D建模的领域,如游戏开发、电影特效制作等。
Formy 3D可将照片、文本快速转化为专业3D模型
Formy 3D是一款先进的AI 3D生成器,于2024年创立。它利用拥有100亿参数的扩散模型技术,能理解自然语言和视觉参考,将文本描述和图像转化为高质量3D模型。与传统3D建模软件不同,它无需专业经验,即可在几分钟内创建出专业的3D资产。该平台提供免费的基础计划,也有每月24.99美元的Plus计划,适用于需要快速创建3D模型的个人和企业。
SAM 3D:AI驱动,秒速将2D图像转化为专业级3D模型
SAM 3D是一款由人工智能驱动的3D重建平台,它基于先进的SAM(Segment Anything Model)技术,实现了将单张2D照片转化为精确、全纹理3D模型的突破。该平台打破了传统3D建模的壁垒,无需昂贵设备和专业技术知识,为全球开发者、设计师、研究人员和内容创作者提供了企业级的3D重建能力。其重要性在于降低了3D建模的门槛,使更多人能够轻松获得高质量的3D模型。价格方面,提供免费使用,无需信用卡信息。产品定位是为各行业提供便捷、高效的3D重建解决方案。
快速将 2D 图像转换为专业 3D 模型的 AI 工具。
Modelfy 3D 是一个先进的 AI 图像转 3D 模型生成器,允许用户在几秒钟内将 2D 图像转换为 3D 模型,支持高达 30 万多边形的精度,非常适合 3D 打印、游戏开发和专业项目。该平台采用自研的 AI 算法和企业级基础设施,提供高效、可靠的 3D 模型生成服务,用户可以按需选择不同的质量级别进行下载,满足多种需求。价格体系灵活,支持免费试用和付费订阅,适合从个人创作者到企业用户的广泛使用。
将3D模型转换为64x64像素图像,简化3D形状生成。
Object Images是一种创新的3D模型生成技术,它通过将复杂的3D形状封装在一个64x64像素的图像中,即所谓的'Object Images'或'omages',来简化3D形状的生成和处理。这项技术通过图像生成模型,如Diffusion Transformers,直接用于3D形状生成,解决了传统多边形网格中几何和语义不规则性的挑战。
先进AI技术,可将文字和图像瞬间转化为3D模型,无需3D建模经验。
To 3D AI是一款先进的AI 3D模型生成器,利用先进的机器学习算法,可将文字描述和图像转化为详细的3D模型。其重要性在于极大地简化了3D模型的创建过程,无需专业的3D建模经验。主要优点包括生成速度快,相比传统3D建模工作流程快10 - 100倍;支持多种格式导出,与主流3D软件和3D打印工作流程兼容;生成的模型质量高,具有优化的拓扑结构和PBR纹理。产品背景信息暂未提及价格相关内容,其定位是为开发者、设计师、艺术家等专业人士提供高效的3D模型创建解决方案。
基于Meta的SAM 3D模型,可秒将单张图像转换成高质量3D模型。
SAM 3D是一款在线工具,基于Meta的SAM 3D研究模型,可将单张图像快速转换为高质量的3D模型。其重要性在于打破了传统摄影测量和仅使用合成数据训练的限制,为3D重建带来了语义理解。主要优点包括在复杂真实场景下的高鲁棒性、快速推理、支持标准3D格式导出等。产品背景是Meta在计算机视觉领域的研究成果,页面未提及价格信息,定位是为用户提供便捷的3D重建服务。
一种通过3D感知递归扩散生成3D模型的框架
Ouroboros3D是一个统一的3D生成框架,它将基于扩散的多视图图像生成和3D重建集成到一个递归扩散过程中。该框架通过自条件机制联合训练这两个模块,使它们能够相互适应,以实现鲁棒的推理。在多视图去噪过程中,多视图扩散模型使用由重建模块在前一时间步渲染的3D感知图作为附加条件。递归扩散框架与3D感知反馈相结合,提高了整个过程的几何一致性。实验表明,Ouroboros3D框架在性能上优于将这两个阶段分开训练的方法,以及在推理阶段将它们结合起来的现有方法。
Kreat3D是AI驱动的3D模型创建平台,可快速将图像和文本转化为3D模型。
Kreat3D是一款由人工智能驱动的3D模型创建平台,其重要性在于降低了3D模型创建的门槛,让更多人能够轻松参与到3D内容的创作中。主要优点包括:能够快速将图像和文本转化为3D模型,无需复杂的建模工具;支持多种输入方式和输出格式,适用于不同的使用场景;集成了多个先进的生成模型,具备灵活和不断进化的能力。产品背景是为了满足设计师、开发者和创作者对于高效创建3D模型的需求。价格方面,提供免费试用,付费计划则解锁更高的生成限制、高级参数、更快的处理优先级和商业使用权。定位是面向广大3D内容创作者,提供便捷、高效、高质量的3D模型创建解决方案。
腾讯推出的3D生成框架,支持文本和图像到3D的生成。
Hunyuan3D-1是腾讯推出的一个统一框架,用于文本到3D和图像到3D的生成。该框架采用两阶段方法,第一阶段使用多视图扩散模型快速生成多视图RGB图像,第二阶段通过前馈重建模型快速重建3D资产。Hunyuan3D-1.0在速度和质量之间取得了令人印象深刻的平衡,显著减少了生成时间,同时保持了生成资产的质量和多样性。
即时生成3D模型的AI平台
Instant 3D AI是一个利用人工智能技术,能够将2D图像快速转换成3D模型的在线平台。该技术的重要性在于它极大地简化了3D模型的创建过程,使得非专业人士也能轻松创建高质量的3D模型。产品背景信息显示,Instant 3D AI已经获得了1400多位创作者的信任,并获得了4.8/5的优秀评分。产品的主要优点包括快速生成3D模型、用户友好的操作界面以及高用户满意度。价格方面,Instant 3D AI提供免费试用,让用户可以先体验产品再决定是否付费。
基于图像学习的高质量3D纹理形状生成模型
GET3D是一种基于图像学习的生成模型,可以直接生成具有复杂拓扑结构、丰富几何细节和高保真纹理的3D模型。通过结合可微分表面建模、可微分渲染和2D生成对抗网络,我们从2D图像集合中训练了该模型。GET3D能够生成高质量的3D纹理模型,涵盖了汽车、椅子、动物、摩托车和人物等各种形态,相比之前的方法有显著改进。
Manex3D AI可将图像秒转高质量3D模型,多格式导出,免费试用
Manex3D是一款基于人工智能技术的在线3D模型生成工具,其核心功能是将二维图像转化为三维模型。该产品的重要性在于为艺术创作、3D打印、游戏开发、产品可视化等领域提供了便捷的3D模型生成解决方案。主要优点包括高精度的模型生成、可定制化的生成选项、多种导出格式、实时预览功能等。背景信息方面,它为用户提供了免费试用的机会,有不同的付费套餐可供选择,如基础套餐、标准套餐和专业套餐,价格根据套餐和订阅周期有所不同。产品定位是满足不同用户在不同场景下对3D模型的需求。
使用AI生成任何3D模型
3D Mesh Generation是Anything World推出的一款在线3D模型生成工具,它利用人工智能技术,允许用户通过简单的文字描述或上传图片来快速生成3D模型。这项技术的重要性在于它极大地简化了3D模型的创建过程,使得没有专业3D建模技能的用户也能轻松创建出高质量的3D内容。产品背景信息显示,Anything World致力于通过其平台提供创新的3D内容创建解决方案,而3D Mesh Generation是其产品线中的重要组成部分。关于价格,用户可以在注册后查看具体的定价方案。
3D模型市场与AI驱动的3D模型创建
Mondial 3D是一个3D模型市场,提供各种类型的3D模型,并且还有AI驱动的3D模型创建工具。您可以在市场上浏览和购买现有的3D模型,或者使用AI技术创建定制的3D模型。无论您是设计师还是爱好者,Mondial 3D都能满足您的需求。
一键生成3D模型
Farm3D是一款能够从单张图片生成可控的3D模型的软件。它通过使用图像生成器Stable Diffusion来产生训练数据,从而学习一个单目重建网络。该网络可以从单张输入图片中生成具有细节的3D模型,包括形状、外观、视角和光照方向等。Farm3D适用于设计师、艺术家和模型制作人员,能够快速生成高质量的3D模型。
Hunyuan 3D AI将文本和图像转化为含PBR纹理的高质量3D模型,无需建模经验。
Hunyuan 3D是腾讯的革命性Hunyuan3D v3平台,采用先进3D AI技术,能快速将文本和图像转化为专业3D模型。其重要性在于降低了3D建模门槛,让非专业人士也能参与创作。主要优点是速度快、精度高、纹理质量好,使用100亿参数模型。产品定位为面向广泛用户的3D建模平台。价格方面,有免费的基础计划和每月24.99美元的Plus计划。
Next3D可在线将图像或文本提示转化为可预览、编辑和下载的3D资产。
Next3D是一个3D生成平台,利用AI技术实现图像到3D以及文本到3D的转换。它的重要性在于大大简化了3D模型的创建流程,普通人也能快速生成3D模型。其主要优点包括操作简单,能在几分钟内将图像或文本转化为3D资产,生成的3D模型可预览、编辑和下载。产品背景方面,随着3D技术在各个领域的广泛应用,对便捷高效的3D模型生成工具的需求日益增长,Next3D应运而生。关于价格,文档未提及。该产品定位是为用户提供一个在线的、便捷的3D模型生成解决方案。
3D模型动画生成
Animate3D是一个创新的框架,用于为任何静态3D模型生成动画。它的核心理念包括两个主要部分:1) 提出一种新的多视图视频扩散模型(MV-VDM),该模型基于静态3D对象的多视图渲染,并在我们提供的大规模多视图视频数据集(MV-Video)上进行训练。2) 基于MV-VDM,引入了一个结合重建和4D得分蒸馏采样(4D-SDS)的框架,利用多视图视频扩散先验来为3D对象生成动画。Animate3D通过设计新的时空注意力模块来增强空间和时间一致性,并通过多视图渲染来保持静态3D模型的身份。此外,Animate3D还提出了一个有效的两阶段流程来为3D模型生成动画:首先从生成的多视图视频中直接重建运动,然后通过引入的4D-SDS来细化外观和运动。
3D模型查看器,支持在线查看和交互
CSM 3D Viewer是一个在线3D模型查看器,允许用户在网页上查看和交互3D模型。它支持多种3D文件格式,提供了旋转、缩放等基本操作,以及更高级的查看功能。CSM 3D Viewer适用于设计师、工程师和3D爱好者,帮助他们更直观地展示和分享3D作品。
从多视角图像创建3D场景
CAT3D是一个利用多视角扩散模型从任意数量的输入图像生成新视角的3D场景的网站。它通过一个强大的3D重建管道,将生成的视图转化为可交互渲染的3D表示。整个处理时间(包括视图生成和3D重建)仅需一分钟。
微软Trellis 2 AI,快速将图像转为含PBR纹理的高质量3D模型
Trellis 2 AI是微软研发的先进3D生成模型,拥有40亿参数。其核心是创新的O - Voxel表示,能处理复杂拓扑结构。该模型可在数秒内将2D图像转换为带有PBR纹理的3D资产,无需额外优化和手动操作,实现端到端工作流程。它在速度和质量上达到了前所未有的平衡,能生成高达1536³分辨率的逼真资产。在trellis3d.net平台上可直接使用,暂未提及价格信息。定位为专业的3D生成解决方案,适合有3D模型创建需求的用户。
3D生成模型的创新突破
VFusion3D是一种基于预训练的视频扩散模型构建的可扩展3D生成模型。它解决了3D数据获取困难和数量有限的问题,通过微调视频扩散模型生成大规模合成多视角数据集,训练出能够从单张图像快速生成3D资产的前馈3D生成模型。该模型在用户研究中表现出色,用户超过90%的时间更倾向于选择VFusion3D生成的结果。
Meta的单图像3D重建模型,融合SAM 3分割与几何纹理布局预测生成3D资产
sam3d是Meta推出的研究级单图像3D重建模型,它将SAM 3的开放词汇分割与几何、纹理和布局预测相融合,能直接从单张RGB图像生成3D资产。该模型具有开源的检查点、推理代码和基准数据集,方便进行可重复的研究和生产试点。其重要性在于降低了3D重建的硬件和设置复杂度,提高了重建效率。主要优点包括单图像输入、开放词汇分割、开放生态系统、适用于XR、高效输入和有明确的评估套件等。产品免费开源,定位于创意工具、电商AR购物、机器人感知和科学可视化等领域。
专为3D艺术家打造,加速3D工作流程,让创作更高效。
Secret Sauce 3D是由3D艺术家为3D艺术家打造的工具,依托受全球工作室和财富500强品牌信赖的专业知识构建。它是唯一专为专业3D艺术家设计的AI工具,可加速3D生产流程,避免生产过程中因重复任务导致的效率低下。产品提供3天免费试用的Creator计划,用户可以随时取消订阅。该工具定位为专业3D艺术家的生产力助手,适合游戏、电影、电商等行业的3D创作。
从单张图片生成高质量3D视图和新颖视角的3D生成技术
Stable Video 3D是Stability AI推出的新模型,它在3D技术领域取得了显著进步,与之前发布的Stable Zero123相比,提供了大幅改进的质量和多视角支持。该模型能够在没有相机条件的情况下,基于单张图片输入生成轨道视频,并且能够沿着指定的相机路径创建3D视频。
Hunyuan3D 2.0 是腾讯推出的高分辨率 3D 资产生成系统,基于大规模扩散模型。
Hunyuan3D 2.0 是腾讯推出的一种先进大规模 3D 合成系统,专注于生成高分辨率纹理化的 3D 资产。该系统包括两个基础组件:大规模形状生成模型 Hunyuan3D-DiT 和大规模纹理合成模型 Hunyuan3D-Paint。它通过解耦形状和纹理生成的难题,为用户提供了灵活的 3D 资产创作平台。该系统在几何细节、条件对齐、纹理质量等方面超越了现有的开源和闭源模型,具有极高的实用性和创新性。目前,该模型的推理代码和预训练模型已开源,用户可以通过官网或 Hugging Face 空间快速体验。

© 2026 AIbase 备案号:闽ICP备08105208号-14