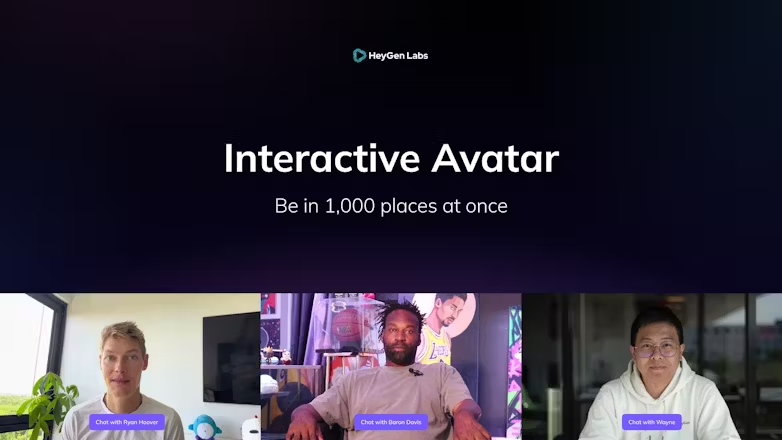
HeyGen Interactive Avatar是一个在线AI视频生成器,专注于创建和优化虚拟形象视频,支持实时互动。它允许用户创建一个为连续流媒体优化的虚拟形象,同时提醒用户保持头部和手部的最小动作。HeyGen的背景信息包括与Baron David和Ryan Hoover等知名人士的合作,产品目前处于Beta测试阶段,提供免费试用。
需求人群:
"目标受众包括视频内容创作者、社交媒体影响者、教育工作者和企业培训者。HeyGen适合他们,因为它提供了一种创新的方式来吸引观众,提高互动性,同时节省了实际拍摄视频的时间和成本。"
使用场景示例:
社交媒体影响者使用HeyGen创建教育视频,提高观众参与度。
企业使用HeyGen进行产品演示,增强客户体验。
教育工作者利用HeyGen创建互动教学视频,提高学习效果。
产品特色:
创建AI虚拟形象视频
实时与虚拟形象互动
选择不同虚拟形象进行对话
知识库共享
将虚拟形象嵌入其他平台
API使用,进行自定义开发
购买信用点以使用更多功能
使用教程:
1. 访问HeyGen网站并注册账号。
2. 选择或创建一个虚拟形象。
3. 根据需要定制虚拟形象的外观和动作。
4. 使用API或现有功能与虚拟形象进行互动。
5. 录制视频或进行实时直播。
6. 将视频分享到社交平台或嵌入到网站中。
7. 根据需要购买信用点以解锁更多功能。
浏览量:176
最新流量情况
月访问量
274.38k
平均访问时长
00:03:03
每次访问页数
3.18
跳出率
38.46%
流量来源
直接访问
52.03%
自然搜索
32.04%
邮件
0.08%
外链引荐
11.43%
社交媒体
3.72%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
巴西
11.33%
英国
3.75%
印度
6.90%
巴基斯坦
3.83%
美国
18.90%
在线创建AI虚拟形象视频,实时互动。
HeyGen Interactive Avatar是一个在线AI视频生成器,专注于创建和优化虚拟形象视频,支持实时互动。它允许用户创建一个为连续流媒体优化的虚拟形象,同时提醒用户保持头部和手部的最小动作。HeyGen的背景信息包括与Baron David和Ryan Hoover等知名人士的合作,产品目前处于Beta测试阶段,提供免费试用。
创新的AI视频生成器,快速实现创意视频。
Luma AI的Dream Machine是一款AI视频生成器,它利用先进的AI技术,将用户的想法转化为高质量、逼真的视频。它支持从文字描述或图片开始生成视频,具有高度的可扩展性、快速生成能力和实时访问功能。产品界面用户友好,适合专业人士和创意爱好者使用。Luma AI的Dream Machine不断更新,以保持技术领先,为用户提供持续改进的视频生成体验。
通过AI技术创建虚拟形象,快速生成视频内容。
Gan.AI Avatar利用先进的AI技术,允许用户通过简单的脚本输入快速生成个性化的视频内容。其核心功能是将文本转换为具有逼真表情和语音的虚拟形象视频,极大地提高了内容创作的效率和灵活性。该产品适用于多种商业场景,如房地产、医疗保健、消费品牌等,能够帮助企业提高客户参与度和转化率。Gan.AI提供免费试用,同时也有不同级别的付费计划以满足不同用户的需求。
Freepik AI 视频生成器,基于人工智能技术快速生成高质量视频内容。
Freepik AI 视频生成器是一款基于人工智能技术的在线工具,能够根据用户输入的初始图像或描述快速生成视频。该技术利用先进的 AI 算法,实现视频内容的自动化生成,极大地提高了视频创作的效率。产品定位为创意设计人员和视频制作者提供快速、高效的视频生成解决方案,帮助用户节省时间和精力。目前该工具处于 Beta 测试阶段,用户可以免费试用其功能。
通过文本生成高质量AI视频
Sora视频生成器是一个可以通过文本生成高质量AI视频的在线网站。用户只需要输入想要生成视频的文本描述,它就可以使用OpenAI的Sora AI模型,转换成逼真的视频。网站还提供了丰富的视频样例,详细的使用指南和定价方案等。
基于 AI 技术生成视频内容的智能服务。
清影 AI 视频生成服务是一个创新的人工智能平台,旨在通过智能算法生成高质量的视频内容。该服务适合各种行业用户,能够快速便捷地生成富有创意的视觉内容。无论是商业广告、教育课程还是娱乐视频,清影 AI 都能提供优质的解决方案。该产品依托于先进的 GLM 大模型,确保生成内容的准确性与丰富性,同时满足用户个性化需求。提供免费试用,鼓励用户探索 AI 视频创作的无限可能。
利用AI技术快速生成视频内容
AI视频生成神器是一款利用人工智能技术,将图片或文字转换成视频内容的在线工具。它通过深度学习算法,能够理解图片和文字的含义,自动生成具有吸引力的视频内容。这种技术的应用,极大地降低了视频制作的成本和门槛,使得普通用户也能轻松制作出专业级别的视频。产品背景信息显示,随着社交媒体和视频平台的兴起,用户对视频内容的需求日益增长,而传统的视频制作方式成本高、耗时长,难以满足快速变化的市场需求。AI视频生成神器的出现,正好填补了这一市场空白,为用户提供了一种快速、低成本的视频制作解决方案。目前,该产品提供免费试用,具体价格需要在网站上查询。
基于扩散模型的2D虚拟形象生成框架
Make-Your-Anchor是一个基于扩散模型的2D虚拟形象生成框架。它只需一段1分钟左右的视频素材就可以自动生成具有精确上身和手部动作的主播风格视频。该系统采用了一种结构引导的扩散模型来将3D网格状态渲染成人物外观。通过两阶段训练策略,有效地将运动与特定外观相绑定。为了生成任意长度的时序视频,将frame-wise扩散模型的2D U-Net扩展到3D形式,并提出简单有效的批重叠时序去噪模块,从而突破推理时的视频长度限制。最后,引入了一种基于特定身份的面部增强模块,提高输出视频中面部区域的视觉质量。实验表明,该系统在视觉质量、时序一致性和身份保真度方面均优于现有技术。
利用AI技术,将文字和图像转化为创意视频。
通义万相AI创意作画是一款利用人工智能技术,将用户的文字描述或图像转化为视频内容的产品。它通过先进的AI算法,能够理解用户的创意意图,自动生成具有艺术感的视频。该产品不仅能够提升内容创作的效率,还能激发用户的创造力,适用于广告、教育、娱乐等多个领域。
AI人物形象视频生成
Spiritme是一款能够根据输入的文本生成具有真实外貌、声音和情感的视频的工具。它具有更高的逼真度和用户体验,比其他竞争产品更出色。Spiritme帮助您以AI人物形象与客户进行互动,使您能够更便捷地创建个人化视频内容,节省时间并提高效率。它是数字明星或博主的完美助手,能够为他们的在线形象提供更多内容,并解决人类因素所带来的问题。它还可用于提升沟通效果,吸引观众的注意力,并用于个性化视频广告、邮件列表和聊天机器人等场景。Spiritme的优势在于简单、透明的定价,您始终清楚自己要支付的费用。它可以在任何时间、任何场合为您快速、廉价地生成视频内容。
在线视频制作平台,提供AI虚拟形象和视频制作服务。
Yepic Studio是一个在线视频制作平台,它通过使用人工智能技术,允许用户创建和编辑视频内容,包括制作会说话的照片视频、专业视频以及AI虚拟形象。该平台的主要优点在于能够快速生成高质量的视频内容,同时提供个性化的AI虚拟形象,满足不同商业需求。产品背景信息显示,Yepic Studio旨在为内容创作者和企业提供一个简单易用的在线视频制作工具,以提高内容生产的效率和质量。关于价格,页面显示用户为'Guest'且'Credits'为0,暗示可能有免费试用或基础免费服务,具体定价需进一步查看。
HappyHorse 1.0可将文本或图像转化为高清AI视频,有免费额度,免信用卡试用。
HappyHorse 1.0是一个基于先进人工智能技术的视频生成平台,其重要性在于为创作者提供了便捷、高效的视频创作途径。该平台的主要优点包括:支持文本和图像转视频,输出高清视频,具备商业使用许可,提供免费额度,无需信用卡即可试用。产品定位为满足创作者和团队对于高质量视频制作的需求,适用于社交媒体内容创作、营销广告等领域。价格方面,有不同质量和时长的套餐可供选择,例如标准质量5秒180积分,10秒360积分;Pro质量5秒240积分,10秒480积分。
免费在线AI视频生成器,可秒将文本或图像转为高清视频
A2E AI是一款免费的在线AI视频生成器,为全球创作者和品牌提供服务。它通过先进的人工智能技术,能将文本或图像快速转化为高质量的视频。主要优点在于无需拍摄和编辑,操作全部在线完成,节省了大量时间和精力。其免费计划可满足基本的视频生成和导出需求,对于有更高要求的用户,可升级至A2E Pro获取更长时长、更高分辨率和更多高级功能。产品定位为让每个人都能轻松成为视频导演,降低视频创作门槛。
AI驱动的视频生成工具,一键生成高质量营销视频
小视频宝(ClipTurbo)是一个AI驱动的视频生成工具,旨在帮助用户轻松创建高质量的营销视频。该工具利用AI技术处理文案、翻译、图标匹配和TTS语音合成,最终使用manim渲染视频,避免了纯生成式AI被平台限流的问题。小视频宝支持多种模板,用户可以根据需要选择分辨率、帧率、宽高比或屏幕方向,模板将自动适配。此外,它还支持多种语音服务,包括内置的EdgeTTS语音。目前,小视频宝仍处于早期开发阶段,仅提供给三花AI的注册用户。
改变客户服务体验的AI虚拟形象
Avtaar.ai是一款革命性的客户服务解决方案,通过逼真的AI虚拟形象提升用户体验、推动业务增长和提高效率。该产品具有可定制、模块化和多平台的特点。通过Avtaar.ai,您可以为您的业务提供全新的客户服务体验,提高效率,实现业务增长。
视频生成模型,支持无限长度高保真虚拟人视频生成
MuseV是一个基于扩散模型的虚拟人视频生成框架,支持无限长度视频生成,采用了新颖的视觉条件并行去噪方案。它提供了预训练的虚拟人视频生成模型,支持Image2Video、Text2Image2Video、Video2Video等功能,兼容Stable Diffusion生态系统,包括基础模型、LoRA、ControlNet等。它支持多参考图像技术,如IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID等。MuseV的优势在于可生成高保真无限长度视频,定位于视频生成领域。
高效的音频驱动 Avatar 视频生成与自适应身体动画。
OmniAvatar 是一种先进的音频驱动视频生成模型,能够生成高质量的虚拟形象动画。其重要性在于结合了音频和视觉内容,实现高效的身体动画,适用于各种应用场景。该技术利用深度学习算法,实现高保真的动画生成,支持多种输入形式,定位于影视、游戏和社交领域。该模型是开源的,促进了技术的共享与应用。
使用简单的提示和图像生成视频片段。
Adobe Firefly 是一款基于人工智能技术的视频生成工具。它能够根据用户提供的简单提示或图像快速生成高质量的视频片段。该技术利用先进的 AI 算法,通过对大量视频数据的学习和分析,实现自动化的视频创作。其主要优点包括操作简单、生成速度快、视频质量高。Adobe Firefly 面向创意工作者、视频制作者以及需要快速生成视频内容的用户,提供高效、便捷的视频创作解决方案。目前该产品处于 Beta 测试阶段,用户可以免费使用,未来可能会根据市场需求和产品发展进行定价和定位。
AI视频创作工具,将老照片转化为动态视频。
京亦智能AI视频生成神器是一款利用人工智能技术,将静态的老照片转化为动态视频的产品。它结合了深度学习和图像处理技术,使得用户能够轻松地将珍贵的老照片复活,创造出具有纪念意义的视频内容。该产品的主要优点包括操作简便、效果逼真、个性化定制等。它不仅能够满足个人用户对于家庭影像资料的整理和创新需求,也能为商业用户提供一种新颖的营销和宣传方式。目前,该产品提供免费试用,具体价格和定位信息需进一步了解。
通过网络摄像头将VTuber虚拟形象变为现实,提升直播体验。
VTuber Maker是一款面向虚拟主播(VTuber)的桌面软件,能够通过摄像头捕捉用户表情和动作,实时驱动虚拟形象进行直播或视频创作。它利用先进的面部追踪和动作捕捉技术,为用户提供稳定、高精度的虚拟形象驱动体验。该产品支持多种虚拟形象格式,包括VRM模型,并提供丰富的背景和道具资源,帮助用户快速创建个性化内容。VTuber Maker不仅适合个人创作者,也适用于商业直播场景,其订阅模式提供了免费和付费版本,满足不同用户需求。
AI语音和视频生成
Listnr AI是一款由AI驱动的语音和视频生成工具。它提供900多种语音和142种语言选择,可以生成逼真的语音和视频内容。用户可以免费开始使用,并在需要时选择付费计划。Listnr AI适用于各种场景,包括生成视频、创建语音广告、制作音频文章、播客制作等。它提供透明的定价,用户可以根据自己的需求选择合适的付费计划。
AI 角色生成器,助您打造独特形象和视频故事。
Artflow AI 是一款 AI 角色生成器,可帮助用户创建一致的角色形象,并制作图像和视频故事。用户可以设计角色外观,创建各种场景图像,以及为角色添加动画,让角色栩栩如生。产品定位于为用户提供创意设计和视频制作的工具。
基于AI技术的数字人虚拟形象,面向多场景应用
百度智能云曦灵是一款基于领先的数字人和人工智能技术的产品,可面向视频、直播、交互等全场景应用。它利用AI算法赋予数字人逼真的动作表情,能生成高质量视频内容,提供自然的对话交互体验。主要功能包括一键直播、一句话生成视频、配置数字人智能体等。产品优势在于开播效率高、投资回报率高、无需专业团队即可使用。定位为面向企业客户提供数字人和AI内容智能化升级服务。
上传产品图片,即时创建展示产品的 AI 视频形象。
Topview 2.0 - Product Avatar 是一款利用 AI 技术帮助用户快速生成产品展示视频的在线工具。它通过智能算法将用户上传的产品图片与精心设计的虚拟形象模板相结合,自动生成高质量、可定制的视频内容,无需昂贵的拍摄成本和专业的技术知识。该产品适用于各种规模的企业,尤其适合那些希望以更具吸引力和个性化的方式展示产品,同时节省时间和成本的商家。Topview 提供免费版本以及更高级的付费计划,以满足不同用户的需求。
在线AI局部更换,生成职业艺术写真照
AI在线生成最美形象照是一个利用人工智能技术,通过用户上传正面头像照,实现快速局部更换并生成具有专业相馆效果的职业艺术写真照的在线服务。它结合了先进的图像处理技术和用户友好的界面,为用户提供了一种便捷、高效的方式来改善和提升个人形象照的质量。
AI视频生成工具
Sora AI Video Generator是一款用于生成AI视频的工具。它可以根据提供的文本内容,自动合成出高质量的视频。该工具具有智能视频编辑、自动配乐、特效添加等功能,可以满足用户在影视制作、广告制作、社交媒体营销等领域的需求。定价方面,请访问官方网站了解详情。
AI生成个人形象照片
DreamPic.AI是一个革命性的平台,利用先进的人工智能技术,在各种风格中生成令人惊叹的个人形象照片。无论您想将自己变成名人、艺术品,甚至是动物,我们都可以满足您的需求。只需几个简单的点击,您就可以创建一张独一无二的照片,令人印象深刻。
全栈式虚拟人多场景应用服务
讯飞虚拟人利用最新的AI虚拟形象技术,结合语音识别、语义理解、语音合成、NLP、星火大模型等AI核心技术,提供虚拟人形象资产构建、AI驱动、多模态交互的多场景虚拟人产品服务。一站式虚拟人音视频内容生产,AIGC助力创作灵活高效;在虚拟'AI演播室'中输入文本或录音,一键完成音、视频作品的输出,3分钟内渲染出稿。

© 2026 AIbase 备案号:闽ICP备08105208号-14