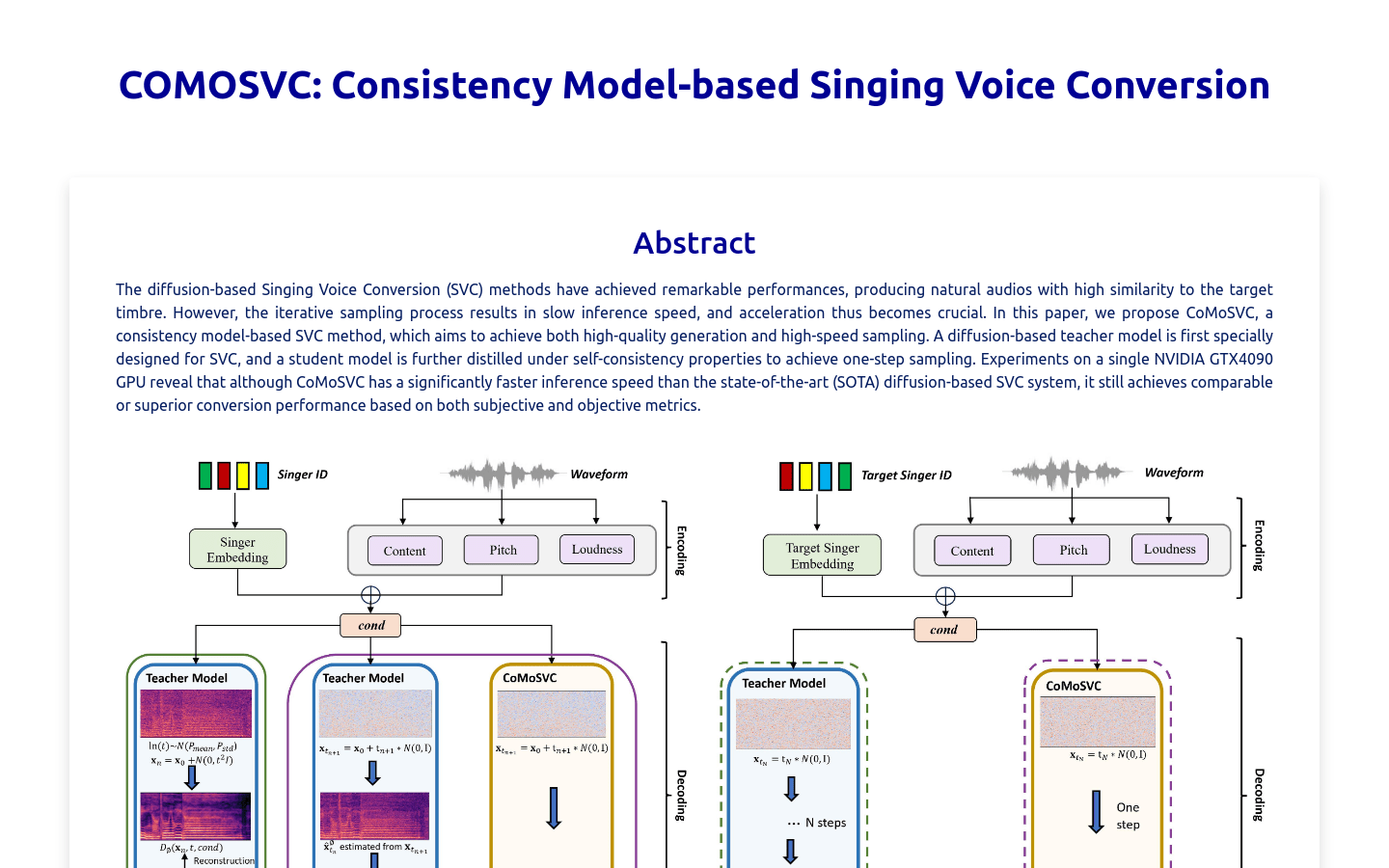
COMOSVC是一种基于一致性模型的歌唱音高转换技术,它可以实现高质量的转换效果和快速的采样速度。该技术首先设计了一个基于弥散的教师模型,用于歌唱音高转换任务,然后通过自我一致性属性进行知识蒸馏,以实现一步采样。相比当前最先进的基于弥散的歌唱音高转换系统,COMOSVC在保持可比甚至优越的转换性能的同时,也实现了显著更快的推理速度。
需求人群:
["将歌手A的歌声转换为歌手B的风格","调整歌曲人声部分的音高和音色","为歌手提供个性化的音高转换效果"]
使用场景示例:
用COMOSVC 把李玉刚的歌声转换成张学友的风格
用COMOSVC 调整歌曲人声部分的音高,使其更适合女声
用COMOSVC 为流行歌手提供个性化的音高转换效果,增强他的音乐特色
产品特色:
快速的一步采样推理
维持高质量的转换效果
自定义的教师模型设计
自我一致性知识蒸馏
浏览量:177
一种基于一致性模型的歌唱音高转换技术
COMOSVC是一种基于一致性模型的歌唱音高转换技术,它可以实现高质量的转换效果和快速的采样速度。该技术首先设计了一个基于弥散的教师模型,用于歌唱音高转换任务,然后通过自我一致性属性进行知识蒸馏,以实现一步采样。相比当前最先进的基于弥散的歌唱音高转换系统,COMOSVC在保持可比甚至优越的转换性能的同时,也实现了显著更快的推理速度。
快速将 PDF 文件转换为 Markdown 格式,保留原始样式。
PDF 转 Markdown 转换器是一款快速、简洁的在线工具,能够将 PDF 文档转换为高质量的 Markdown 格式。其重要性在于可以帮助用户在处理文档时,轻松提取和编辑内容。该工具支持多语言,并使用高精度 OCR 技术,确保格式的完美保留。提供免费和付费两种版本,付费版允许更大的文件上传和更多转换次数。
一站式URL转换工具,可将网页内容转换为Markdown、PDF、图片等多种格式。
URL to Any是一款功能强大的一站式URL转换工具,其重要性在于为用户提供了便捷、高效的网页内容转换解决方案。主要优点包括:支持多种格式转换,界面简单直观,处理速度快,安全私密,全球可访问,云处理无需安装软件,输出格式干净规范。该产品定位为满足日常URL转换需求的工具,价格完全免费,旨在降低用户获取有用工具的门槛。
零样本声音转换技术,实现音质与音色的高保真转换。
seed-vc 是一个基于 SEED-TTS 架构的声音转换模型,能够实现零样本的声音转换,即无需特定人的声音样本即可转换声音。该技术在音频质量和音色相似性方面表现出色,具有很高的研究和应用价值。
实时低延迟语音转换技术
StreamVC是由Google研发的实时低延迟语音转换解决方案,能够在保持源语音内容和韵律的同时,匹配目标语音的音色。该技术特别适合实时通信场景,如电话和视频会议,并且可用于语音匿名化等用例。StreamVC利用SoundStream神经音频编解码器的架构和训练策略,实现轻量级高质量的语音合成。它还展示了学习软语音单元的因果性以及提供白化基频信息以提高音高稳定性而不泄露源音色信息的有效性。
将PNG文件转换为AI格式
PNG to AI Converter是一款能够将PNG文件转换为AI格式的插件。用户只需点击插件图标,选择PNG文件并点击转换按钮,即可通过电子邮件收到AI文件的下载链接。
在线批量将AVIF转换为JPG、PNG、WebP,无需上传,100%浏览器离线处理
Avif2JPG是一款基于浏览器的在线工具,可将AVIF图像批量转换为JPG、PNG和WebP格式。其重要性在于解决了AVIF格式在一些设备和软件上兼容性不佳的问题。主要优点包括:无需上传文件到服务器,保障了用户数据的隐私和安全;支持批量处理,提高了工作效率;采用本地浏览器处理,转换速度更快。该产品免费使用,定位为方便用户进行图像格式转换的工具,适用于需要处理大量AVIF图像的个人和企业。
AI图像转换
Destocker是一款基于AI技术的图像转换工具,通过先进的扩散技术,可以将您的照片重新想象和转换,为您的图像创造出独特的效果。它提供了简单易用的界面,支持任意尺寸和比例的图像上传,并提供了多种功能来控制图像的结构和颜色。Destocker适用于广告、网站设计、内部沟通等多种场景,并提供灵活的定价模式。
视频DensePose转换工具
Vid2DensePose是一个强大的工具,旨在将DensePose模型应用于视频,为每一帧生成详细的“部位索引”可视化。该工具在增强动画方面非常有用,特别是与MagicAnimate结合使用时,能够实现时间上连贯的人体图像动画。
将文本转换为逼真语音的在线工具
该产品是一个先进的在线文字转语音工具,使用人工智能技术将文本转换为自然逼真的语音。它支持多种语言和语音风格,适用于广告、视频旁白、有声书制作等场景,增强了内容的可访问性和吸引力。产品背景信息显示,它为数字营销人员、内容创作者、有声书作者和教育工作者提供了极大的便利。
代码转换工具,简化编程语言转换流程。
AI Code Converter是一个基于人工智能的代码转换平台,它能够将代码从一个编程语言自动转换到另一个编程语言,极大地节省了开发者在不同语言间转换代码时所花费的时间。该平台使用了先进的AI模型来确保代码转换的精确性和卓越性,无需安装或下载,用户只需粘贴代码并点击按钮即可实现一键转换。同时,AI Code Converter强调对用户隐私的保护,不存储或保留用户的输入代码或输出结果。
将图像转换为文本
Imagen A Texto是一个在线工具,可以将图像转换为可编辑的文本。它使用先进的OCR技术,确保准确提取图像中的文本。用户只需上传图像,工具会自动识别并提取文本。适用于转换文件、书籍、引用等。它支持多种图像格式,界面简单易用。
极致AI语音转换
UberTTS是一款采用先进的AI文本到语音技术,将文本转换为逼真的人类声音的产品。它适用于YouTube叙述、营销内容、教程内容、新闻叙述、有声书等各种用途。它提供了900多种标准和神经网络声音,支持超过144种语言和方言。用户可以自定义音量、速度、音调和暂停等参数。UberTTS还提供强大的声音工作室,可合并和增强音频效果,并支持多种格式的音频下载和分享。
实时AI语音转换器
Dubbing AI是一款实时AI语音转换器,能将任何声音转换为高质量的克隆声音,支持超过1000个来自您最喜爱的动漫、游戏等角色。它具有低延迟、低资源占用,支持几乎所有平台,并提供了丰富的声音滤镜。Dubbing AI是游戏玩家和直播者的理想工具,能够提升游戏体验和内容质量。
将PSD文件转换为AI格式
PSD to AI Converter是一个在线工具,可将PSD文件转换为AI格式。它具有简单易用的界面,只需点击扩展图标即可打开转换网站。用户只需选择PSD文件并点击转换按钮,即可在电子邮件中收到AI文件的下载链接。
免费图像文件转换工具
ConvertFiles.ai是一个智能图像转换工具,让您根据需要将图像文件转换为不同的文件格式。加入成千上万的用户使用ConvertFiles.ai以节省存储空间并获得更好的性能!我们支持多种图像格式,如PNG、JPEG、WEBP等。您可以轻松地将图像文件转换为所需格式,无任何质量损失。我们的产品以超快的速度转换文件格式,用户界面友好,操作简单,支持移动设备。ConvertFiles.ai也提供其他实用工具,如图片放大增强、去除水印、图像压缩和智能抠图。无需安装任何软件,免费使用,适用于个人和商业用途。
将任何设计转换为代码
Design 2 Code是一款可以将任何设计转换为代码的工具。用户只需上传设计图,即可快速生成对应的代码,节省开发时间。优势在于高效、精准、节省成本。定价根据使用量计费,定位于设计师、开发者、产品经理等需要快速实现设计到代码的转换的用户群体。
语音转换为Notion页面
Voxio是一款语音转换为Notion页面的应用。它提供了多种布局和文本块,用户可以自由选择。用户可以在Voxio应用程序中或后台捕捉他们的语音,并通过单个滑动将其发送到Notion。此外,用户可以随时保存录音并在稍后发送。Voxio支持多语言,适用于全球用户。
将SVG文件转换为AI格式
SVG to AI Converter是一个方便快捷的插件,可以将SVG文件转换为AI格式。用户只需点击插件图标,选择SVG文件并点击转换按钮,即可获得AI文件的下载链接。
将任何内容转换为其他任何内容
Socialite AI是一款能够将任何内容转换为其他任何内容的工具。它提供了强大的转换功能,用户可以将文本、图片、视频等转换成不同的格式和类型。Socialite AI的优势在于其高效、准确的转换算法,以及友好的用户界面。该产品定价灵活,用户可以根据自己的需求选择不同的套餐。Socialite AI定位于提供便捷、高质量的内容转换服务。
利用AI实现语音转换
Respeecher是一个基于AI的语音转换工具,能够实现不同人声音之间的转换。它采用深度神经网络技术,只需要提供少量样本音频,就可以训练出目标人声音的克隆版本。Respeecher的语音转换效果非常逼真,可用于游戏、影视配音等多种创作领域。它提供免费试用,支持上传自己录制的音频进行语音转换。主要功能包括语音转换、语音塑造、语音配音等。
智能提取网页核心内容,一键转换为文本。
Url to Text Converter是一个利用人工智能技术,从网页中提取主要相关内容并转换为文本的在线工具。它通过AI技术识别并提取网页上的核心信息,支持JavaScript渲染,使用住宅IP地址以帮助绕过某些限制,从而提供更准确和全面的内容提取服务。
将Twitter Spaces转换为MP3和文本
XspaceGPT是您将Twitter Spaces转换为MP3和文本的首选平台。它利用先进的GPT技术,快速可靠地将Twitter Spaces转换为MP3和文本,并生成具有洞察力的摘要和思维导图。此外,我们还提供Twitter视频下载器,将视频转换为MP4格式。快速、可靠、免费。
透过AI文字转换成出色影片
文字转影片是CapCut推出的AI影片产生器,它可以将用户输入的文字提示无缝转换成优秀的短视频。用户只需输入想法,AI模型即可根据文字描述产生对应的影片镜头。该工具适用于视频创作者、商业用户等,大大提高了视频制作的效率。
AI代码转换、生成与优化工具
AICodeConvert整合了AI代码转换与生成能力,可高效地在不同编程语言间转换代码,并自动生成优质代码。这个强大的组合为开发者提供了方便智能的编码体验。所有服务完全免费,是你最好的AI编程助手。
将文本转换成Skibidi。
Brainrot Translator是一个将文本转换成Skibidi的网站。它的主要优点是可以将普通文本转换成具有特殊效果的Skibidi文本,增加了文本的趣味性和创意性。
AI音频转换工具
Voice-Swap是一款使用人工智能技术的音频转换工具,可以将您的声音转换成顶尖歌手的风格,适用于制作演示或找到最适合您曲目的完美声音。我们提供免费试用和订阅计划,支持远程协作和演示制作。
视频转PDF文件的应用程序,将mp4、mov、avi、flv转换为PDF文档
视频转PDF文件的应用程序可以免费在线将视频转换为可读的PDF文档。将视频转换为文档具有以下好处:1. 可访问性:视频对于所有人并不总是易于访问,如具有视觉或听觉障碍的人。将其转换为文档可让更多人访问。2. 可搜索性:文档比视频更易搜索,便于查找特定信息。3. 可共享性:文档比视频更易共享,使他人可以在不必观看整个视频的情况下访问信息。4. 归档:文档比视频更易存档,使信息可以被保存以备将来参考。5. 翻译:文档比视频更易翻译,使信息可供更多人访问。6. 更容易做笔记:有些人可能发现从文档而不是视频中做笔记更容易。7. 节约成本:创建和分发文档通常比创建和分发视频成本更低。如果你正在寻找一个好的mp4视频转PDF的在线转换器,那么你可以试试这个应用程序,它会超出你的期望。我们提供5种不同的转换方法,包括自动转换、基于时间转换、基于页面转换、手动转换和基于字幕转换。

© 2026 AIbase 备案号:闽ICP备08105208号-14