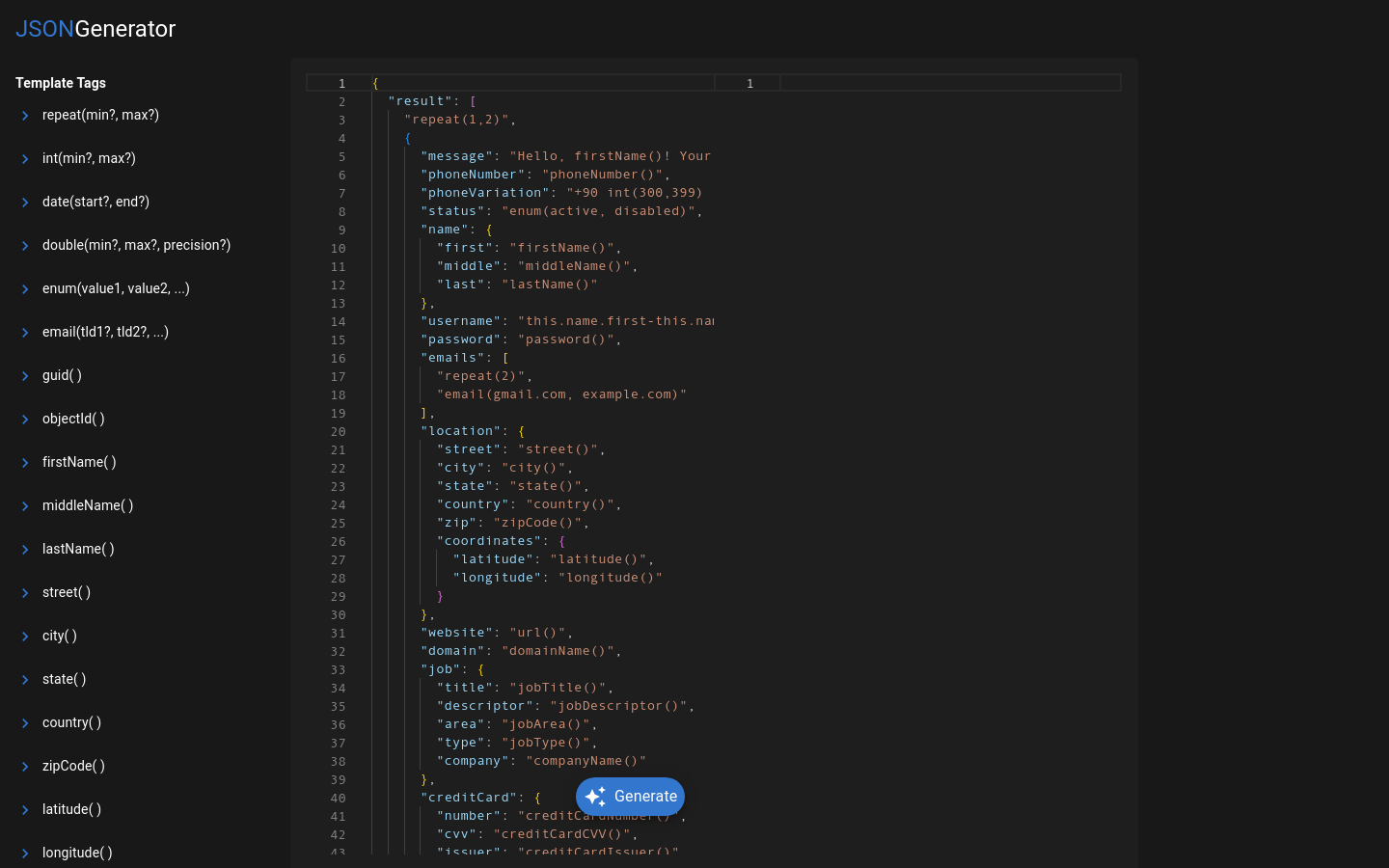
JSONGenerator是一个为开发者、测试人员和教育工作者设计的终极数据生成工具,它通过使用模板来定义和生成精确及随机的JSON数据。该工具简化了手动构建JSON数据的过程,提供了一致性和大量数据的快速生成,同时支持数据结构的灵活修改。它遵循RFC 8259和ECMA-404标准,确保生成的JSON数据是经过验证和优化的。
需求人群:
"目标受众包括开发者、测试人员和教育工作者。开发者可以使用它来模拟API响应和创建一致的测试数据,测试人员可以生成多样化的测试数据以确保应用程序的可靠性,教育工作者可以轻松创建示例和教学材料,帮助学生理解复杂的数据结构。"
使用场景示例:
John D. - 'JSON Generator使我的开发过程更加顺畅。模板功能对于创建一致的模拟数据来说是一个真正的变革。'
Sarah K. - '现在用逼真的数据进行测试变得如此简单。JSON Generator的随机数据生成既强大又灵活。'
Michael L. - '作为一名教育工作者,这个工具太棒了。现在为我的学生们创建示例变得快速而简单。'
产品特色:
模板驱动:一次性定义数据结构,可在多个项目中重复使用,确保一致性。
随机数据生成:为全面测试和开发创建逼真的随机数据。
用户友好界面:直观的用户界面使得创建和管理JSON模板变得简单。
API集成:通过强大的API将JSONGenerator集成到您的工作流程中。
导出选项:将数据导出为JSON、CSV和XML格式,以满足不同需求。
使用教程:
1. 注册:在平台上创建账户以访问所有功能。
2. 创建模板:使用直观的模板系统定义您的数据结构。
3. 生成数据:使用我们的工具根据模板生成随机或特定数据。
4. 导出和集成:将数据导出为所需格式,并将其集成到您的项目中。
浏览量:54
最新流量情况
月访问量
5822
平均访问时长
00:00:08
每次访问页数
1.43
跳出率
48.32%
流量来源
直接访问
39.25%
自然搜索
46.50%
邮件
0.14%
外链引荐
7.25%
社交媒体
6.01%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
印度
15.63%
波兰
3.98%
俄罗斯
17.18%
土耳其
18.19%
美国
42.98%
JSON数据生成工具,帮助创建和管理JSON数据结构
JSONGenerator是一个为开发者、测试人员和教育工作者设计的终极数据生成工具,它通过使用模板来定义和生成精确及随机的JSON数据。该工具简化了手动构建JSON数据的过程,提供了一致性和大量数据的快速生成,同时支持数据结构的灵活修改。它遵循RFC 8259和ECMA-404标准,确保生成的JSON数据是经过验证和优化的。
高精度将图片或PDF转换为Markdown文本或JSON结构化文档的API
pdf-extract-api是一个使用现代OCR技术和Ollama支持的模型将任何文档或图片转换为结构化的JSON或Markdown文本的API。它使用FastAPI构建,并使用Celery进行异步任务处理,Redis用于缓存OCR结果。该API无需云或外部依赖,所有处理都在本地开发或服务器环境中完成,确保数据安全。它支持PDF到Markdown的高精度转换,包括表格数据、数字或数学公式,并且可以使用Ollama支持的模型进行PDF到JSON的转换。此外,该API还支持LLM改进OCR结果,去除PDF中的个人身份信息(PII),以及分布式队列处理和缓存。
模拟 API 生成器是一个帮助您生成模拟数据和 API 的工具。
AI-Powered Mock API Generator是一个帮助您生成模拟数据和 API 的工具。您可以使用自然语言描述所需生成的数据,并生成相应的 API。它可以用于快速原型开发、测试环境搭建、数据模拟等场景。AI-Powered Mock API Generator已生成 5341 个数据集和 2350 个 API。
控制您的LinkedIn帐户并通过单个API实时检索数据,适用于复杂的自动化、高级推广和数据收集。
Linked API是一个安全的LinkedIn API,可用于控制LinkedIn帐户并通过单个API实时检索数据。该产品的主要优点包括灵活的自动化功能、高级推广工具和便捷的数据收集能力。它背后是LinkedIn平台的稳定和安全性,定位于为用户提供高效的LinkedIn数据管理和使用体验。
通过API获取谷歌等搜索引擎实时SERP数据,支持地理定位,按需付费。
Talordata SERP API是一款强大的工具,可通过API接口获取谷歌和其他主要搜索引擎的实时搜索结果页面(SERP)数据。其重要性在于为企业和开发者提供了便捷、高效的数据获取途径。主要优点包括支持地理定位,能根据不同地区获取精准数据;仅对成功请求收费,降低成本;提供JSON或HTML格式的结构化数据,方便处理;无需担心代理和验证码问题,使用更省心。该产品面向有搜索数据需求的企业和开发者,定位为提供专业、可靠的搜索数据解决方案。价格方面提供免费试用,之后仅对成功请求付费。
用API生成和优化Dreambooth稳定扩散,节省成本、时间、金钱,并获得50倍更快的图像生成
Stable Diffusion And Dreambooth API是一个API,让您可以专注于构建下一代人工智能产品,而不是维护GPU。使用Stable Diffusion API,您无需拥有昂贵的GPU和大内存,即可节省成本、时间和金钱,并以50倍更快的速度生成图像。Dreambooth API可让您使用自己的数据集对稳定扩散进行优化,生成所需的图像。您可以通过单击一个按钮从100多个模型中生成图像,无需训练自己的模型。
快速实惠的搜索API,跨多搜索引擎,处理阻塞,提供JSON数据。
Serpex是一款专为AI与数据项目打造的快速且经济实惠的搜索API。其核心功能是统一的实时网络搜索API,能够将查询路由到多个搜索引擎,如Google、Bing、DuckDuckGo、Brave等。它的重要性在于解决了数据提取过程中的常见难题,如阻塞、验证码等问题,为开发者提供了稳定可靠的数据获取途径。产品具有诸多优点,包括优化的基础设施、全球化的IP池、低延迟、高吞吐量、准确的搜索结果等。其价格十分亲民,起价仅为每请求0.0008美元,还提供200个免费积分供用户试用。产品定位明确,旨在为开发者提供便捷、高效、低成本的搜索数据解决方案。
将任何网页转换为实时JSON API,无需编写爬虫代码,仅需输入URL和所需的JSON格式。
PulpMiner是一个可以将任何网页数据转换为结构化实时JSON API的工具,它消除了数据提取和API构建的繁琐工作,提供AI驱动的实时API,价格灵活,即时设置。
MidAPI.ai提供免费MidJourney API,支持V7等模型生成图像与视频。
MidJourney API是MidAPI.ai平台提供的一项服务,可访问MidJourney各版本模型,用于图像和视频生成。产品重要性在于为创作者提供便捷、高效的AI创作工具。主要优点包括支持多版本模型、功能丰富、生成效果好、速度快等。背景信息是随着AI绘画和视频生成技术的发展,满足用户多样化创作需求。价格方面提供免费的API密钥,可在免费模式下使用,也有付费的快速模式。产品定位是为各类创作者、开发者和企业提供高质量的AI图像和视频生成服务。
使用Dream Machine API生成视频的Python脚本。
Dream Machine API是一个Python脚本,使用Dream Machine API来生成视频,并异步检查视频生成状态,输出最新生成的视频链接。它需要Python 3.7+环境和requests、aiohttp库支持。用户需要登录LumaAI的Dream Machine网站获取access_token以使用该脚本。
基于 Python 和 FastAPI 的非官方 Suno API。
SunoAPI 是一个基于 Python 和 FastAPI 的非官方 Suno API。它支持生成歌曲、歌词等功能,并带有内置的令牌维护和保持活跃功能,让您无需担心令牌过期。SunoAPI 采用全异步设计,运行速度快,适合后续扩展。用户可以轻松使用 API 生成各种音乐内容。
AI音乐API
WarpSound是一款灵活的生成式AI音乐API,能够为无限的动态音乐内容、应用和体验提供动力。它采用行业领先的工作室级创作技术,使您能够通过API轻松创建高质量的音乐体验。WarpSound还提供多种定价方案,适用于不同的用户需求。
将文档转换成AI就绪的Markdown或结构化JSON
Monkt是一个文档转换平台,能够将PDF、Word、PowerPoint、Excel、CSV、网页和原始HTML等格式的文档即时转换成为优化过的Markdown格式,专为AI/LLM系统设计。它支持多种文件格式,提供清晰的Markdown导出,自定义JSON模式,图像理解能力,并针对流行的LLM系统进行优化。Monkt通过其直观的仪表板或REST API直接集成,为用户提供强大的功能,简化AI和LLM工作流程。
Sora2Api提供统一API,实现无水印Sora风格视频生成
Sora2Api是一款为开发者提供Sora风格视频生成服务的统一API。其重要性在于简化了视频生成的流程,让开发者能够更便捷地将视频生成功能集成到自己的项目中。该产品的主要优点包括:支持无水印视频生成,生成的视频物理上更一致、运动和交互更真实,可控制多镜头场景,还能同步生成音频。产品背景方面,它为满足市场对高效视频生成的需求而推出。价格方面,提供免费试用,具体付费情况未提及。其定位是为各类需要视频生成功能的开发者和企业服务,帮助他们快速实现视频生成的功能,提升工作效率和产品竞争力。
开源数据摄取API服务
Chunkr是一个开源的数据摄取API服务,专注于文档布局分析、OCR和分块处理,将文档转换成适合RAG和LLM的数据格式。支持PDF、DOC、PPT和XLS文件。该服务能够将文本、表格、图像和手写内容进行结构化处理,为人工智能和机器学习应用提供数据支持。它由Lumina AI Inc.维护,并且提供免费试用和定价方案。
智能图像识别API
Monster API是一个智能图像识别API,可以帮助开发者快速实现图像识别功能。它提供了多种功能,包括物体识别、人脸识别、文字识别等。优势是准确率高、响应速度快、易于集成。价格根据使用情况计费,具体请查看官方网站。Monster API的定位是为开发者提供强大的图像识别能力,帮助他们构建智能应用。
自动化消息和构建自定义工作流程的通信接口
OpenPhone API 是一个为企业提供的电话系统和通信接口,它允许用户将电话、短信和联系人更深入地集成到他们的技术栈中。这个API支持自动化消息发送,保持联系人同步,记录CRM中的活动,并构建自定义集成。它使用API密钥进行身份验证,确保对账户数据和功能的安全性访问。OpenPhone API 的主要优点包括简化系统操作,通过单一工具替代多个平台,以及提供以前通过Webhook无法访问的关键信息。
超快速的网络爬虫与数据抓取API
UseScraper是一个超快速的网络爬虫与数据抓取API,可以快速抓取网页内容并提供多种输出格式,包括HTML、纯文本和Markdown。它支持浏览器渲染,可以爬取复杂的网站,并提供多种功能和定价选项。无需信用卡即可注册,还可以获得25美元的免费使用额度。
开源项目,实现AI音乐服务的API接口
Suno API是一个开源项目,允许用户设置自己的Suno AI音乐服务API。它实现了app.suno.ai的创建API,兼容OpenAI的API格式,支持自定义模式,一键部署到Vercel,并且拥有开放源代码许可证,允许自由集成和修改。
使用Runway API,随时随地创造视频内容。
Runway API是一个强大的视频模型平台,提供先进的生成视频模型,允许用户在安全、可靠的环境中嵌入Gen-3 Alpha Turbo到他们的产品中。它支持广泛的应用场景,包括创意广告、音乐视频、电影制作等,是全球顶尖创意人士的首选。
提供OpenAI和Claude模型支持的API服务。
API易是一个提供OpenAI和Claude模型支持的API服务平台,用户可以通过API接口调用这些模型进行各种AI任务。该平台具有稳定性高、价格优惠、无需代理即可使用等特点,适合需要AI模型支持的开发者和企业。
Gemini API的指南和示例集合
Gemini API Cookbook是一个包含Gemini API使用指南和示例的集合,旨在帮助开发者快速上手并使用Gemini API。这些示例大多数是用Python编写的Colab Notebooks,可以直接在Google Colab中打开或下载到本地环境中运行。
AI平台准确检测和分类API隐私数据,强制执行隐私标准,确保API的安全和合规
API隐私是一个AI平台,能够准确检测和分类API隐私数据,通过执行隐私标准,确保API的安全和合规。它简化了合规要求,减少了手动工作和错误风险,同时为开发人员提供了执行隐私标准的能力。
强大的 API 市场,便捷集成多种 AI 接口。
本产品是一个综合性的 AI API 市场,提供大量的 AI 模型与服务,方便开发者快速集成和管理 API。该平台支持多种功能,如图像生成、视频制作和文本处理,具有高效、可靠的性能,价格合理,适合各类开发者使用。用户可通过简单的接口调用,获得高质量的图像和视频生成,满足多样化的创意需求。
AI图像生成API,提供高质量的4K图像生成和编辑功能。
Picogen AI Image API是一个领先的AI图像生成平台,提供与Midjourney, Stable Diffusion和DALL-E相媲美的高质量图像生成服务。它支持生成高达4K分辨率的图像,并且具备图像合并、背景移除和8K分辨率的图像放大等高级功能。Picogen旨在为数字营销人员、平面设计师、内容创作者等专业人士提供强大的视觉内容创作工具。
提供经济实惠的 Veo 3 API,轻松部署 AI 视频生成。
Veo3API.ai 提供性价比最高的 Veo 3 API,支持从文本和图像生成同步音频的4K视频。具有高扩展性和稳定性,价格实惠,适合各种视频生成需求。
为ComfyUI提供Luma AI API的自定义节点。
ComfyUI-LumaAI-API是一个为ComfyUI设计的插件,它允许用户直接在ComfyUI中使用Luma AI API。Luma AI API基于Dream Machine视频生成模型,由Luma开发。该插件通过提供多种节点,如文本到视频、图像到视频、视频预览等,极大地丰富了视频生成的可能性,为视频创作者和开发者提供了便捷的工具。

© 2026 AIbase 备案号:闽ICP备08105208号-14