浏览量:404
语音转文字,支持实时语音识别、录音文件识别等
腾讯云语音识别(ASR)为开发者提供语音转文字服务的最佳体验。语音识别服务具备识别准确率高、接入便捷、性能稳定等特点。腾讯云语音识别服务开放实时语音识别、一句话识别和录音文件识别三种服务形式,满足不同类型开发者需求。技术先进,性价比高,多语种支持,适用于客服、会议、法庭等多场景。
快速、准确、免费的音频转文字服务
AIbase音频提取文字工具利用人工智能技术,通过机器学习模型快速生成高质量的音频文本描述,优化文本排版,提升可读性,同时完全免费使用,无需安装、下载或付款,为创意人员提供便捷的基础服务。
强大的语音转文字API
SpeechFlow是一个强大的语音转文字API,提供高准确率的语音转文字功能。它支持14种语言,可将语音、音频转换为文字,适用于各种场景和行业。SpeechFlow的优势在于准确率高、部署简单、可扩展性强,支持云端和本地部署。
强大的语音转文字API
SpeechFlow是一款强大的语音转文字API,可在13种语言中以极高的准确率进行转录。它是将声音转为文字、语音转为文字和音频转为文字的强大工具。SpeechFlow支持云端和本地部署,提供可靠且易于部署和扩展的解决方案。它还具有快速处理速度,可以在短短几分钟内处理长达1小时的音频文件。
智能语音转文字工具
WisprNote 是一款智能语音转文字工具,支持将语音备忘录、音频和视频文件转录为纯文本。它拥有极高的准确性和转录速度,同时保证了隐私安全。适用于会议记录、访谈转录、学习笔记等场景。
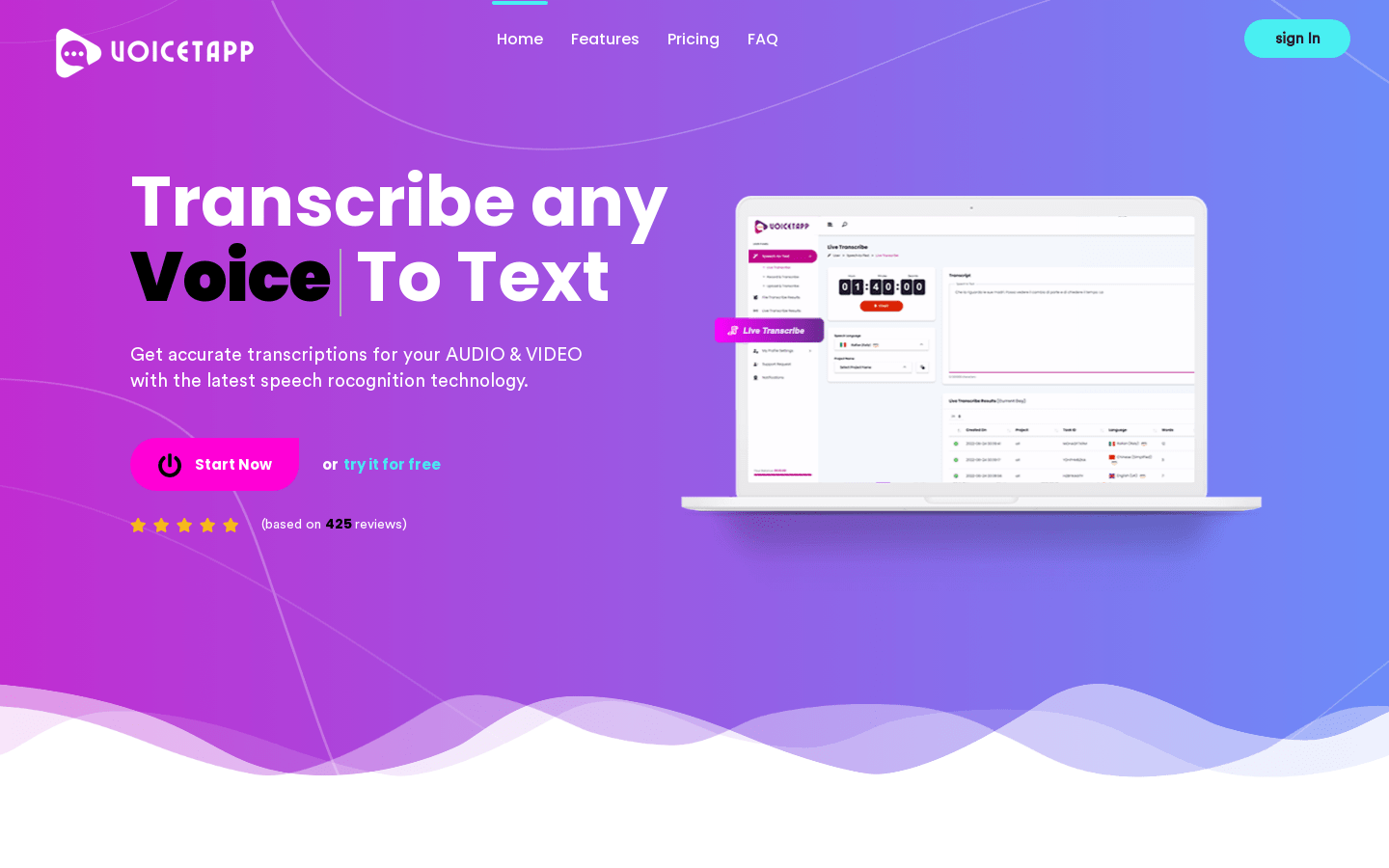
转录任何语音、音频、视频到文字
Voicetapp是一个强大的基于云端的人工智能软件,通过最新的语音识别技术,帮助您将任何语音、音频和视频自动转换为文字。具备高达99%的准确度。支持170种语言和方言。具备演讲者识别、实时转录、多种音频输入格式等功能。提供不同的定价计划。
一款语音转文字的应用程序
Transcribe ~ Speech to Text是一个语音转文字的iOS应用程序。它利用OpenAI的Whisper技术和Apple的神经引擎,实现语音文件的高精度识别,可将音频和视频文件直接转录成可阅读的文本。支持离线识别和云端识别两种模式。适用于各类语音转文字的需求,使用简单方便。
AI语音转文字
Scribewave是一款AI语音转文字工具,可以轻松将音频和视频文件转录、加字幕和字幕,具有99%的准确率。支持90多种语言,包括英语、荷兰语、法语、德语、西班牙语等。可以无限导出到Word、SRT、VTT、TXT等常用格式。免费试用,付费用户可以使用更多功能。适用于学术研究、媒体制作、法律文书等多个行业。
音频转文字,快速高效
Rythmex是一款在线音频转文字工具,支持超过140种语言,用户只需上传音频或视频文件,选择对应的语言,即可在60秒内开始编辑并下载转换后的文本。该产品功能强大,优势在于快速、准确地将音频转换为文字,定价灵活,定位于商业用户和教育用户。
免费的语音转文字工具
Speechnotes是一个可靠和安全的基于网络的语音转文字工具,可以快速准确地转录音频和视频录音,以及代替键入进行口述笔记,节省您的时间和精力。Speechnotes具有声音指令用于标点和格式设置、自动大写和易于导入和导出选项等功能,为您提供高效和用户友好的口述和转录体验。Speechnotes自2015年以来为数百万用户提供服务。
实时语音转文字,实现快速沟通
Actual Chat是一款结合了实时语音、即时转录和人工智能辅助的应用,让您能够更快速地沟通,详细回复,不浪费时间等待。它重新构想了电话、文字和语音消息,将语音和文字融合成一个单一的媒介。通过Actual Chat,您可以实时观看语音转录,选择听或读,随时加入对话,匿名参与聊天,保持对话记录,提高清晰度,完善口语,提升对话质量,包括在家庭、工作、网络研讨会、在线课程和客户支持等场景中的应用。
Origlio - 音频转文字和更多服务
Origlio是一款音频转文字的服务,还提供更多功能。它可以将您的音频消息转录成文字,帮助您管理和整理语音消息。您可以将音频转发给Origlio,几秒钟后即可获得转录结果。除了音频转录,Origlio还提供丰富的响应功能,帮助您更好地完成日常工作。
快速准确提取视频中的文字
AIbase视频提取文字工具是一个利用人工智能和机器学习技术,为用户提供快速、准确的视频文字转录服务。它优化了文字排版,使得转录内容易于理解且忠实于原视频。作为一项基础服务,该工具完全免费,无需安装、下载或付费订阅,极大地方便了创意人员的视频内容处理工作。
macOS智能语音转文字
WhisperWizard是一款智能语音转文字的桌面客户端,通过ChatGPT的帮助,将您的口头语言转化为更加准确的书面文字,加快在macOS上的写作流程。您可以通过WhisperWizard跳过打字,避免错误,节省时间。随时捕捉想法,访问旧录音,创建自定义模板,以及获取智能转录,让您的口头语言转化为优质文字。此外,WhisperWizard提供不同的定价计划,包括Essential、Advanced和Ultimate,满足不同用户的需求。
音频转文本
Transcriptmate是一个在线音频转文本的服务。它可以将长达3小时的录音文件转换成文本文件,并在2小时内通过电子邮件发送给您。转换结果可以以csv、srt、txt等多种格式保存。Transcriptmate支持多种语言,无需订阅或承诺,安全支付。推荐的价格为6美元/文件。
语音转文字,轻松高效
Letterly是一款语音转文字的应用,能够将任何语音转换为清晰结构的文字,支持录音转文字、提取会议纪要、生成社交媒体内容、快速发送电子邮件等功能,让您的文字随心所欲。通过AI增强技术,文字更加精准。用户还可以选择界面风格、翻译语音等功能。Letterly让您的文字更加流畅,让语音成为您的最佳助手。
语音转文字 AI 机器人
instaSpeak AI bot 是一款强大的语音转文字 AI 机器人。它可以将用户输入的语音实时转换为文字,并且支持多种语言识别。用户可以在网站上直接录制语音,并立即获得文字转录。instaSpeak AI bot 的优势在于高准确率和快速响应速度。该产品定价灵活,用户可以根据自己的需求选择适合的套餐。定位于提供高质量的语音转文字服务。
一键视频转文字
Video2Text 是一个使用 OpenAI Whisper 技术的视频转文字工具。它使用先进的算法,提供准确的视频转文字功能。该工具可免费下载使用,可以将视频快速转换为文字。适用于研究人员、教育工作者、记者和内容创作者等各类用户。如有任何问题,请通过 contact@jhayer.tech 联系我们。
语音备忘录转文字
使用先进的人工智能技术,将语音备忘录转录为文字。该应用能够轻松处理大型音频录音并生成准确的转录。支持离线转录,所有数据在设备上进行处理。免费功能包括:轻松录制和转录音频文件、无需互联网进行转录、所有数据在设备上处理、即时获取转录结果、自动检测语言、支持 5 个转录结果,界面简单易用,支持后台录制和分享转录结果至邮件和其他应用。Pro 功能包括无限次转录结果生成。立即下载!
准确的语音转文字工具
Whisper Notes 是一款准确的语音转文字工具,使用 OpenAI 的 Whisper 模型。无需网络连接,用户数据不会上传,支持 80 多种语言。可以用于记笔记、快速发送消息等。
AI 助力 macOS 语音转文字
superwhisper 是一款基于人工智能的语音转文字软件,能够将您的语音准确转录为文字,并集成于 macOS 系统剪贴板。它可以帮助您更快速地书写邮件、撰写报告等文字内容,释放大量的思维空间。superwhisper 采用客户端本地化运行,保证您的数据安全。定价为 $7,定位于提升办公效率的工具。
图片转文字、文字转图片、自定义对话,一切尽在SnapGPT
SnapGPT不仅仅是一个文字识别工具,它还是一个友好的聊天机器人助手!您可以通过SnapGPT提取摘要、获取建议,甚至提取关键信息和购物清单。通过SnapGPT的图片转文字和语音转文字功能,您的工作效率将更上一层楼,就像有一个随时待命的个人助理!
AI语音转文字工具
VoicePen是一款AI语音转文字工具,可将音频、视频、语音备忘录和网站转换为博客文章。它使用人工智能技术,在几分钟内生成转录文本,并提供博客文章的编辑和重新生成功能。支持多种语言和96+种语言的转录。VoicePen有多种定价计划可供选择,包括一次性付款和月度/年度订阅。适用于个人用户和商业用户。
AI语音转文字在线工具
Revoicer是一款基于人工智能的语音转文字在线工具,通过使用最先进的AI技术,可以快速、准确地将语音转换为文字。它提供80多种逼真的人声AI语音,支持多种语言,用户可以自定义语音类型、音调和速度,并添加不同情绪,如友好、愉快、悲伤、愤怒等。Revoicer是一个完全在线的应用程序,无需下载任何内容。

© 2026 AIbase 备案号:闽ICP备08105208号-14