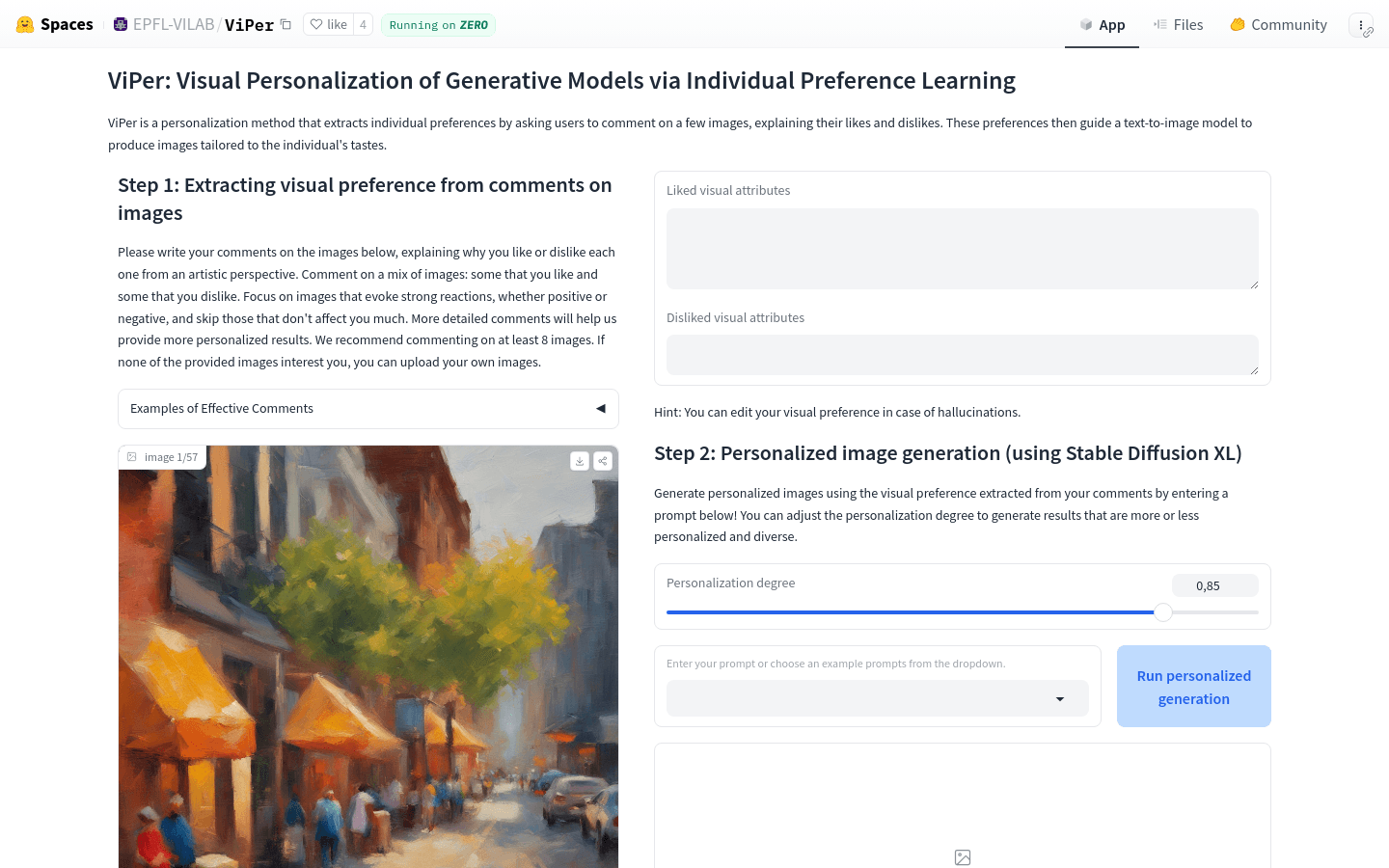
ViPer是一种个性化生成模型,可以根据用户的视觉偏好生成符合个人口味的图像。该模型使用了稳定扩散XL技术,可以在保持图像质量的同时实现个性化生成。ViPer的主要优点是可以为用户提供个性化的图像生成服务,满足用户的个性化需求。
需求人群:
"ViPer适合那些需要个性化图像生成服务的用户,例如艺术家、设计师、摄影师等。该模型可以根据用户的视觉偏好生成符合个人口味的图像,满足用户的个性化需求。"
使用场景示例:
艺术家使用ViPer生成符合自己风格的艺术作品
设计师使用ViPer生成符合自己设计风格的图片
摄影师使用ViPer生成符合自己摄影风格的图片
产品特色:
从用户的评论中提取视觉偏好
使用稳定扩散XL技术生成个性化图像
可以根据用户的偏好程度生成更或少个性化的图像
可以为用户提供个性化的图像生成服务
可以满足用户的个性化需求
使用教程:
打开ViPer网站
在Step 1中,对提供的图片进行评论,至少评论8张图片
在Step 2中,输入提示并选择个性化程度
点击'Run personalized generation'按钮,生成个性化图像
浏览量:85
最新流量情况
月访问量
25633.38k
平均访问时长
00:04:53
每次访问页数
5.77
跳出率
44.05%
流量来源
直接访问
49.07%
自然搜索
35.64%
邮件
0.03%
外链引荐
12.38%
社交媒体
2.75%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
中国
14.36%
印度
8.76%
韩国
3.61%
俄罗斯
5.25%
美国
16.65%
ViPer是一种个性化方法,通过要求用户对几张图片发表评论,解释他们的喜好和不喜好,提取个人偏好。这些偏好指导文本到图像模型生成符合个人口味的图像。
ViPer是一种个性化生成模型,可以根据用户的视觉偏好生成符合个人口味的图像。该模型使用了稳定扩散XL技术,可以在保持图像质量的同时实现个性化生成。ViPer的主要优点是可以为用户提供个性化的图像生成服务,满足用户的个性化需求。
个性化视觉编辑中任意对象交换
SwapAnything是一个新颖的框架,可以根据参考给出的个性化概念,交换图像中的任意对象,同时保持上下文不变。相较于现有的个性化主题交换方法,SwapAnything有三个独特优势:(1)精确控制任意对象和部分而非主题,(2)更忠实地保留上下文像素,(3)更好地将个性化概念适应到图像中。它通过有针对性的变量交换来在潜在特征图上实现区域控制,交换被遮罩的变量以保持忠实的上下文和初始的语义概念交换。然后,通过外观调整,无缝地将语义概念调整到原始图像中,包括目标位置、形状、风格和内容。在人工和自动评估上的广泛结果表明,我们的方法在个性化交换方面比基准方法有显著改进。此外,SwapAnything展示了在单个对象、多个对象、部分对象和跨领域交换任务上的精确和忠实交换能力。SwapAnything还在基于文本的交换和超出交换的任务上取得了出色表现,如对象插入。
AI辅助,快速生成个性化回复。
AI回复生成器是一款革命性的沟通工具,旨在帮助用户创建个性化、符合上下文的回复。无论是撰写电子邮件、回应客户咨询还是生成内容,我们的AI系统确保您的信息清晰、简洁且针对您的受众量身定制。
基于大语言模型的个性化图像生成工具
MoMA Personalization 是一款基于开源 Multimodal Large Language Model (MLLM) 的个性化图像生成工具。它专注于主题驱动的个性化图像生成,可以根据参考图像和文本提示生成高质量、保留目标物体特征的图像。MoMA 不需要任何 fine-tuning,是一个插件式的模型,可以直接应用于现有的 diffusion 模型中,并在保留原模型性能的同时提高生成图像的细节和 prompt 忠实度。
AI设计,一键生成个性化Logo。
AI Logo Designs Gallery是一个在线平台,利用人工智能技术为用户提供个性化的Logo设计服务。用户只需输入品牌名称和一些基本的设计要求,AI即可生成多种风格的Logo供选择。该平台支持多种行业和风格,包括极简、中等复杂度等,满足不同用户的需求。
个性化图像生成工具
Midjourney是一个独立的研究实验室,专注于探索新的思想媒介和扩展人类想象力。它是一个自筹资金的小团队,专注于设计、人类基础设施和人工智能。Midjourney Personalization通过用户对图像对的评分来学习用户的偏好,并根据这些偏好生成个性化的图像。
一键生成个性化动漫艺术作品
AI动漫生成器是一款利用人工智能和机器学习技术,帮助用户将文字描述、照片或简单绘画转化为动漫风格的艺术作品的在线工具。它无需用户具备绘画技巧,即可快速生成高质量的动漫艺术图像,支持从静态图像到动画视频的转换,为用户提供了无限的创意表达和个性化定制的可能性。
使用AI技术创作个性化音乐
免费AI歌曲生成器是一个在线工具,使用人工智能技术根据用户输入创作个性化歌曲。它结合旋律、和声和节奏,创造完整的歌曲。产品背景信息显示,该工具受到全球超过25,000名音乐家、内容创作者和音乐爱好者的信任。它提供免费、无需订阅的音乐创作服务,支持多种音乐风格,并允许用户商业使用生成的歌曲。
免费生成个性化的明信片
AI明信片生成器是一款能够根据用户提供的信息生成个性化明信片的工具。用户只需要输入自己的姓名、收件人姓名、关系、明信片的语气、语言、发送地点以及三个描述假期的关键词,AI会自动生成一张独特的明信片,用于分享假期的快乐。
视觉配音中个性化人物形象的呈现
PersonaTalk是一个基于注意力机制的两阶段框架,用于实现高保真度和个性化的视觉配音。该技术通过风格感知的音频编码模块和双注意力面部渲染器,能够在合成准确的唇形同步的同时,保持和突出说话者的“个性”。它不仅能够捕捉说话者独特的说话风格,还能保留面部细节,这对于音频驱动的视觉配音来说是一个相当大的挑战。PersonaTalk的主要优点包括视觉质量高、唇形同步准确以及个性保持,它作为一个通用框架,能够达到与特定人物方法相媲美的性能。
文本到图像模型的个性化定制
内容创作者经常希望使用个人主题创建个性化图片,超越传统的文本到图像模型的能力。此外,他们可能希望生成的图片包含特定的位置、风格、氛围等。现有的个性化方法可能会在个性化能力和与复杂文本提示的对齐之间做出妥协。这种权衡可能会阻碍用户提示和主题的忠实性。我们提出了一种新的方法,专注于单个提示的个性化方法,以解决这个问题。我们将这种方法称为提示对齐个性化。尽管这种方法可能看起来有限,但我们的方法在改进文本对齐方面表现出色,可以创建具有复杂和复杂提示的图像,这对于当前技术来说可能是一个挑战。具体而言,我们的方法使用额外的得分蒸馏采样项,使个性化模型与目标提示保持对齐。我们在多次拍摄和单次拍摄设置中展示了我们方法的多功能性,并进一步展示了它可以组合多个主题或从艺术作品等参考图像中获取灵感。我们定量和定性地与现有基线和最先进的技术进行比较。
快速个性化文本到图像模型
HyperDreamBooth是由Google Research开发的一种超网络,用于快速个性化文本到图像模型。它通过从单张人脸图像生成一组小型的个性化权重,结合快速微调,能够在多种上下文和风格中生成具有高主题细节的人脸图像,同时保持模型对多样化风格和语义修改的关键知识。
AI图像生成器,支持个性化定制和多模型管理
MidJourney是一个流行的AI图像生成器,拥有超过1900万用户。它最近推出了类似Pinterest的“Moodboards”功能和对多个自定义AI图像模型的支持,使用户能够创建和切换多个定制版本的MidJourney最新图像生成器AI模型,以适应他们独特的审美。这些更新旨在简化个人和团队的创作流程,使个性化风格更容易融入各种项目。MidJourney的个性化基础设施不断改进,公司正在通过其“想法和功能”频道征求用户反馈,以赋予创作者直观而强大的工具,推动AI辅助创作的进一步发展。
AI模型微调,个性化定制。
prompteasy.ai是一个在线平台,允许用户通过简单的聊天方式对GPT模型进行微调,无需具备任何技术技能。平台的目标是让AI更加智能,易于任何人访问和使用。目前,该服务在v1版本发布期间对所有用户免费。
一键生成个性化社交媒体标题
Capit是一款自动从图片或视频中直接生成独特个性化社交媒体标题的应用。目前可在iPhone、iPad和Mac上使用。用户可以根据不同的心情和场景选择幽默、激励、诗意或随意等不同的语调,快速生成符合个性的社交媒体标题。Capit的定位是提高社交媒体发布效率,帮助用户更快速地产生有趣的内容,增加互动和关注。
快速创建个性化AI贴纸,让沟通更生动有趣。
Magickimg AI贴纸生成器是一个利用人工智能技术,根据用户输入的提示词快速生成个性化贴纸的在线工具。它主要面向需要为社交媒体、聊天应用等增添个性化元素的用户。产品背景基于深度学习技术,通过用户友好的界面,提供简单快捷的操作体验。产品的主要优点包括快速生成、易于操作、高质量输出以及安全可靠的服务。
让您的模型定制更加个性化
FABRIC 是一个通过迭代反馈来个性化定制扩散模型的工具。它提供了一种简单的方法来根据用户的反馈来改进模型的性能。用户可以通过迭代的方式与模型进行交互,并通过反馈来调整模型的预测结果。FABRIC 还提供了丰富的功能,包括模型训练、参数调整和性能评估。它的定价根据用户的使用情况而定,可满足不同用户的需求。
无需训练的扩散模型个性化定制
RB-Modulation是谷歌发布的一种基于随机最优控制的新型训练免费个性化扩散模型解决方案。它通过终端成本编码所需属性,实现风格和内容的精确提取与控制,无需额外训练,即可生成与参考图像风格一致且遵循给定文本提示的图像。该技术在无需训练的情况下,通过新颖的注意力特征聚合(AFA)模块,保持对参考图像的高保真度,并遵循给定的提示,具有重要的研究和应用价值。
生成个性化发型AI
TuNuevoLook是一个使用人工智能生成个性化发型的在线服务。用户可以上传一张自拍照片,30分钟内就会收到由人工智能生成的个性化发型照片。我们提供男性和女性的发型选择,并保证用户满意度。用户只需支付相应费用,即可获得个性化的发型建议。
Stability AI 生成模型是一个开源的生成模型库。
Stability AI 生成模型是一个开源的生成模型库,提供了各种生成模型的训练、推理和应用功能。该库支持各种生成模型的训练,包括基于 PyTorch Lightning 的训练,提供了丰富的配置选项和模块化的设计。用户可以使用该库进行生成模型的训练,并通过提供的模型进行推理和应用。该库还提供了示例训练配置和数据处理的功能,方便用户进行快速上手和定制。
使用 AI 技术快速生成个性化纹身设计。
Inker.AI 是一个在线的 AI 纹身生成器,允许用户通过上传照片或输入文字来创建个性化的纹身设计。该平台无需设计技能,用户只需简单操作即可生成专业纹身。适合各类人群,特别是艺术爱好者和纹身爱好者。产品免费使用,易于上手,具有极高的灵活性和创造力。
个性化图像复原,保留面部特征
本文提出了一种简单有效的个性化图像复原方法,名为双枢纽调谐。该方法包含两个步骤:1) 通过微调条件性生成模型来利用编码器中的条件信息进行个性化;2) 固定生成模型,调节编码器的参数以适应强化的个性化先验。这可以生成保留个性化面部特征以及图像退化属性的自然图像。实验证明,与非个性化方法相比,该方法可以生成更高保真度的面部图像。
上传照片生成100+个个性化AI头像
Posed AI是一款个性化AI头像生成工具,用户可以上传照片,通过AI技术生成逼真的高质量头像,支持多种风格选择。生成的头像可以用于个人资料图片、社交媒体等各种用途。价格合理,功能强大,让你的头像与众不同。
AI生成个性化贺卡,表达真挚情感
Greetings & eCards是一款AI生成个性化贺卡的产品。它可以帮助用户轻松创建和发送完美的贺卡,包括生日贺卡、圣诞贺卡、母亲节贺卡和感谢卡等。用户可以选择不同的卡片设计和编辑个性化的文字描述,同时利用先进的自然语言处理技术,生成更富有意义的祝福语。通过这款产品,用户可以更加深入地与他们生活中重要的人建立有意义的联系。Greetings & eCards提供免费的eCard服务,并提供付费的高级功能。
AI生成个性化视频
FoxAcid AI是一款基于人工智能技术的个性化视频生成工具。通过上传一段个人录像和一个包含目标客户数据的电子表格,FoxAcid AI可以智能地根据电子表格中的数据为每个目标客户生成一段个性化视频。视频内容会根据电子表格中的姓名、地理位置、业务详情等信息进行定制,让每个目标客户都感觉到自己受到直接的关注。使用FoxAcid AI可以大大提升您的市场推广效果,提高客户转化率。
个性化报告与关系分析
KnowU是一个个性化报告生成工具,通过分析用户的社交媒体数据,生成个性化报告和关系分析。用户可以了解自己的性格特点、人际关系以及与朋友的相处情况。KnowU的优势在于提供个性化的报告,帮助用户了解自己并改善人际关系。

© 2026 AIbase 备案号:闽ICP备08105208号-14