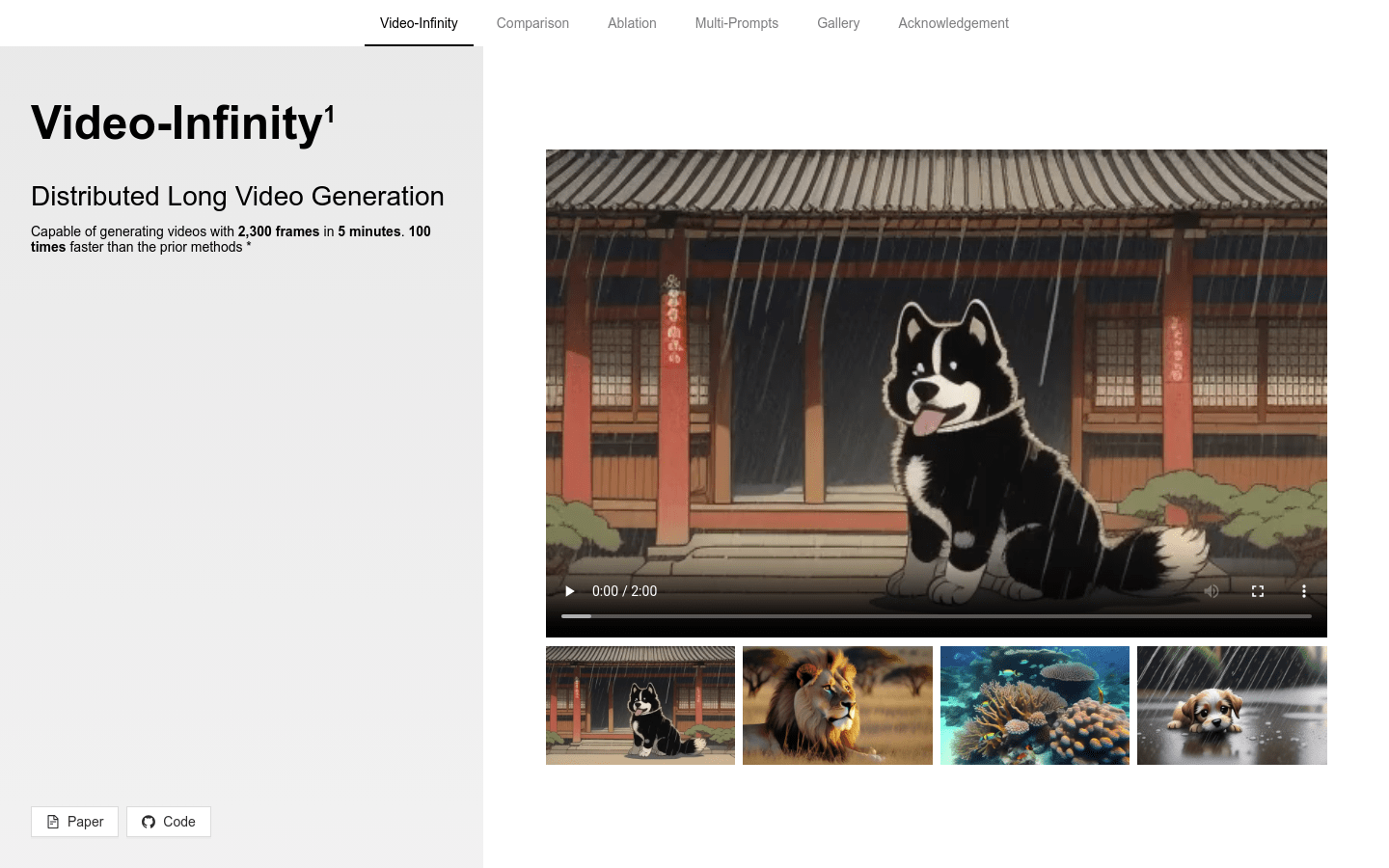
Video-Infinity 是一种分布式长视频生成技术,能够在5分钟内生成2300帧的视频,速度是先前方法的100倍。该技术基于VideoCrafter2模型,采用了Clip Parallelism和Dual-scope Attention等创新技术,显著提高了视频生成的效率和质量。
需求人群:
"Video-Infinity 适合需要快速生成高质量视频内容的专业人士和企业,如电影制作、广告制作、虚拟现实等领域。它的高效率和高质量输出能够满足这些领域对视频内容的严苛要求。"
使用场景示例:
电影制作中快速生成特效场景。
广告行业中创建吸引人的视频广告。
虚拟现实应用中生成沉浸式视频体验。
产品特色:
能够生成长达2300帧的视频,帧率高达7.6 fps。
采用分布式计算,极大缩短了视频生成时间。
支持Clip Parallelism和Dual-scope Attention技术,提升视频质量和细节。
进行了消融实验,评估不同技术对视频生成效果的影响。
支持多提示(Multi-Prompts)技术,能够根据多个提示生成多样化的视频内容。
提供了丰富的画廊(Gallery),展示不同场景下的视频生成效果。
使用教程:
1. 访问Video-Infinity的官方网站。
2. 注册并登录账户,以获取免费试用权限。
3. 根据需求选择合适的视频生成参数,如帧数、帧率等。
4. 使用Multi-Prompts技术输入多个视频生成提示。
5. 启动视频生成过程,等待系统完成视频制作。
6. 下载或分享生成的视频内容。
浏览量:223
分布式长视频生成技术
Video-Infinity 是一种分布式长视频生成技术,能够在5分钟内生成2300帧的视频,速度是先前方法的100倍。该技术基于VideoCrafter2模型,采用了Clip Parallelism和Dual-scope Attention等创新技术,显著提高了视频生成的效率和质量。
创新的AI视频生成器,快速实现创意视频。
Luma AI的Dream Machine是一款AI视频生成器,它利用先进的AI技术,将用户的想法转化为高质量、逼真的视频。它支持从文字描述或图片开始生成视频,具有高度的可扩展性、快速生成能力和实时访问功能。产品界面用户友好,适合专业人士和创意爱好者使用。Luma AI的Dream Machine不断更新,以保持技术领先,为用户提供持续改进的视频生成体验。
高效全球分布式AI模型训练框架
PrimeIntellect-ai/prime是一个用于在互联网上高效、全球分布式训练AI模型的框架。它通过技术创新,实现了跨地域的AI模型训练,提高了计算资源的利用率,降低了训练成本,对于需要大规模计算资源的AI研究和应用开发具有重要意义。
一种单步视频生成模型,实现高质量视频合成。
SF-V是一种基于扩散的视频生成模型,通过对抗训练优化预训练模型,实现了单步生成高质量视频的能力。这种模型在保持视频数据的时间和空间依赖性的同时,显著降低了去噪过程的计算成本,为实时视频合成和编辑铺平了道路。
通过文本生成高质量AI视频
Sora视频生成器是一个可以通过文本生成高质量AI视频的在线网站。用户只需要输入想要生成视频的文本描述,它就可以使用OpenAI的Sora AI模型,转换成逼真的视频。网站还提供了丰富的视频样例,详细的使用指南和定价方案等。
高效的分布式数据并行框架,专为大型语言模型设计。
YaFSDP是一个分布式数据并行框架,专为与transformer类神经网络结构良好协作而设计。它在预训练大型语言模型(Large Language Models, LLMs)时比传统的FSDP快20%,并且在高内存压力条件下表现更佳。YaFSDP旨在减少通信和内存操作的开销。
开源分布式深度学习工具
The Microsoft Cognitive Toolkit(CNTK)是一个开源的商业级分布式深度学习工具。它通过有向图描述神经网络的计算步骤,支持常见的模型类型,并实现了自动微分和并行计算。CNTK支持64位Linux和Windows操作系统,可以作为Python、C或C++程序的库使用,也可以通过其自身的模型描述语言BrainScript作为独立的机器学习工具使用。
开源实现分布式低通信AI模型训练
OpenDiLoCo是一个开源框架,用于实现和扩展DeepMind的分布式低通信(DiLoCo)方法,支持全球分布式AI模型训练。它通过提供可扩展的、去中心化的框架,使得在资源分散的地区也能高效地进行AI模型的训练,这对于推动AI技术的普及和创新具有重要意义。
开源的MuZero实现,分布式AI框架
MuKoe是一个完全开源的MuZero实现,使用Ray作为分布式编排器在GKE上运行。它提供了Atari游戏的示例,并通过Google Next 2024的演讲提供了代码库的概览。MuKoe支持在CPU和TPU上运行,具有特定的硬件要求,适合需要大规模分布式计算资源的AI研究和开发。
Lumalabs AI从文本和图像快速生成高质量、逼真视频的AI模型
Lumalabs AI的Dream Machine是一个AI模型,能够直接从文本和图像快速生成高质量的逼真视频。它是一个高度可扩展且高效的transformer模型,专门针对视频进行训练,能够生成物理上准确、一致且充满事件的镜头。Dream Machine是构建通用想象力引擎的第一步,现已对所有人开放。
视频扩散模型加速工具,无需训练即可生成高质量视频内容。
FasterCache是一种创新的无需训练的策略,旨在加速视频扩散模型的推理过程,并生成高质量的视频内容。这一技术的重要性在于它能够显著提高视频生成的效率,同时保持或提升内容的质量,这对于需要快速生成视频内容的行业来说是非常有价值的。FasterCache由来自香港大学、南洋理工大学和上海人工智能实验室的研究人员共同开发,项目页面提供了更多的视觉结果和详细信息。产品目前免费提供,主要面向视频内容生成、AI研究和开发等领域。
Freepik AI 视频生成器,基于人工智能技术快速生成高质量视频内容。
Freepik AI 视频生成器是一款基于人工智能技术的在线工具,能够根据用户输入的初始图像或描述快速生成视频。该技术利用先进的 AI 算法,实现视频内容的自动化生成,极大地提高了视频创作的效率。产品定位为创意设计人员和视频制作者提供快速、高效的视频生成解决方案,帮助用户节省时间和精力。目前该工具处于 Beta 测试阶段,用户可以免费试用其功能。
一键生成高质量视频,支持从图像到视频的AI转换,满足您的创意需求。
AI视频生成器采用领先行业的图像到视频AI技术,智能选择最佳模型,生成1080p视频,支持多镜头拍摄,样式多样,运动流畅。主要优点包括快速生成高质量视频,支持复杂场景和镜头运动控制,适用于设计师、内容创作者等用户。
基于AI的分布式自动支付处理器
Mobile Credits是一个基于AI的分布式自动支付处理器,确保安全快速地在全球范围内进行实时的资金转移,全天候提供服务。它提供了实时的、无需人工干预的交易处理能力,可以通过任何移动设备或已拥有的手机轻松进行全球范围的无接触即时支付。
AI驱动,快速安全去除AI生成视频水印,无损高质量
RemoveWatermark是一款基于AI技术的视频水印去除工具,旨在帮助用户轻松去除AI生成视频中的水印。其重要性在于为创作者提供了一个高效、安全且高质量的水印去除解决方案,使他们能够专注于内容创作,而不必担心水印的困扰。产品的主要优点包括快速处理、无损质量、无需上传视频、免费试用以及隐私保护等。该产品提供免费、专业和专业无限三种不同的价格方案,以满足不同用户的需求。其定位是为广大视频创作者提供便捷、高效的水印去除服务。免费计划每天可进行3次水印去除;专业计划每月10美元(优惠后6美元),每月可进行1200次去除,具有优先处理速度等优势;专业无限计划每月70美元(优惠后35美元),可进行无限次去除。
基于WAN 2.2/2.5模型的免费AI视频生成器,可将图片转化为高质量视频。
该产品是由阿里巴巴达摩院开发的基于WAN 2.2和WAN 2.5模型的AI视频生成器,在Freewanvideo.com网站上使用。其重要性在于为用户提供了便捷的视频创作方式,能将静态图片转化为动态视频。主要优点包括速度快、画质高、支持精准控制和高级提示理解。新用户可免费生成17个视频并获得100个积分,还有每日60积分的首周福利。价格方面,有不同等级的付费套餐,如3.99美元的PRO Lite、8.99美元的PRO Standard和18.99美元的PRO Premium,适合不同需求和预算的用户。定位是为内容创作者提供专业的视频生成解决方案。
将文字和图片转化为高质量视频的AI平台。
Dream Machine AI是一个利用尖端技术将文字和图片转化为高质量视频的AI平台。它由Luma AI驱动,使用先进的变换模型快速生成具有复杂时空运动的物理准确和一致的视频内容。主要优点包括生成速度快、运动逼真连贯、角色一致性高、相机运动自然。产品定位为视频创作者和内容制作者提供快速高效的视频生成解决方案。
将想法转化为高质量图像的AI工具。
Flux AI Image Generator(FAIG)是由Black Forest Labs开发的尖端人工智能技术,能够根据文本提示快速生成高质量、逼真而艺术的视觉效果。它具备混合架构,结合了多模态和并行扩散变压器块,使得在图像质量、速度和遵循用户提示方面表现卓越。
轻松生成高质量论文
智能论文生成器是一款通过人工智能技术,帮助用户快速生成高质量论文的工具。它能够根据用户提供的关键词和要求,自动生成符合要求的论文,节省用户大量的时间和精力。智能论文生成器提供多种论文类型的模板,如叙述性、描述性、定义性、分析性、因果性等,用户只需填写相关信息,即可获得完整的论文。此外,智能论文生成器还提供编辑、排版和参考文献功能,确保论文的准确性和规范性。定价灵活合理,适用于学生、研究人员和写作爱好者等不同用户群体。
先进的文本到图像AI模型,实现高质量图像生成。
Stable Diffusion 3 Medium是Stability AI迄今为止发布的最先进文本到图像生成模型。它具有2亿参数,提供出色的细节、色彩和光照效果,支持多种风格。模型对长文本和复杂提示的理解能力强,能够生成具有空间推理、构图元素、动作和风格的图像。此外,它还实现了前所未有的文本质量,减少了拼写、字距、字母形成和间距的错误。模型资源效率高,适合在标准消费级GPU上运行,且具备微调能力,可以吸收小数据集中的细微细节,非常适合定制化。
AI驱动的视频生成工具,一键生成高质量营销视频
小视频宝(ClipTurbo)是一个AI驱动的视频生成工具,旨在帮助用户轻松创建高质量的营销视频。该工具利用AI技术处理文案、翻译、图标匹配和TTS语音合成,最终使用manim渲染视频,避免了纯生成式AI被平台限流的问题。小视频宝支持多种模板,用户可以根据需要选择分辨率、帧率、宽高比或屏幕方向,模板将自动适配。此外,它还支持多种语音服务,包括内置的EdgeTTS语音。目前,小视频宝仍处于早期开发阶段,仅提供给三花AI的注册用户。
SkyReels V1 是一个开源的人类中心视频基础模型,专注于高质量影视级视频生成。
SkyReels V1 是一个基于 HunyuanVideo 微调的人类中心视频生成模型。它通过高质量影视片段训练,能够生成具有电影级质感的视频内容。该模型在开源领域达到了行业领先水平,尤其在面部表情捕捉和场景理解方面表现出色。其主要优点包括开源领先性、先进的面部动画技术和电影级光影美学。该模型适用于需要高质量视频生成的场景,如影视制作、广告创作等,具有广泛的应用前景。
AI生成高质量专业照片
Proface是一款基于人工智能的产品,通过先进的算法生成高质量的专业照片。它可以帮助用户快速生成逼真的人像照片,用于各种职业场景和社交媒体。Proface提供多种功能和优势,包括快速生成照片、高质量的细节处理、丰富的风格选择和定制化选项。该产品的定价根据用户需求和使用频率而定,具体定价详情请访问官方网站。Proface定位于提供便捷、高效、高质量的人像照片生成服务。
3FS是一个高性能分布式文件系统,专为AI训练和推理工作负载设计。
3FS是一个专为AI训练和推理工作负载设计的高性能分布式文件系统。它利用现代SSD和RDMA网络,提供共享存储层,简化分布式应用开发。其核心优势在于高性能、强一致性和对多种工作负载的支持,能够显著提升AI开发和部署的效率。该系统适用于大规模AI项目,尤其在数据准备、训练和推理阶段表现出色。
AI声音合成,高质量,逼真
SteosVoice(以前称为CyberVoice)是人工智能的声带,具有超高质量的逼真语音合成。它适用于创作者、视频制作、游戏开发、模组制作、播客、有声读物等领域。它提供超过150种不同的声音,每天生成超过25小时的音频。用户可以使用SteosVoice创造独特的内容,为视频配音、向赞助者发送语音消息、制作播客、为模组和游戏添加声音等。SteosVoice还提供付费计划,于2023年1月9日重新开放。
开源视频生成模型
Mochi 1 是 Genmo 公司推出的一款研究预览版本的开源视频生成模型,它致力于解决当前AI视频领域的基本问题。该模型以其无与伦比的运动质量、卓越的提示遵循能力和跨越恐怖谷的能力而著称,能够生成连贯、流畅的人类动作和表情。Mochi 1 的开发背景是响应对高质量视频内容生成的需求,特别是在游戏、电影和娱乐行业中。产品目前提供免费试用,具体定价信息未在页面中提供。
智能AI工具,快速生成高质量唯一内容。
SmartlyQ是一款强大的AI工具,能够在几次点击内生成高质量的独特内容。它能够帮助用户节省时间,创造内容,促进业务增长。产品定位于提供智能内容生成解决方案。

© 2026 AIbase 备案号:闽ICP备08105208号-14