浏览量:103
最新流量情况
月访问量
825.06k
平均访问时长
00:08:28
每次访问页数
16.09
跳出率
26.47%
流量来源
直接访问
63.05%
自然搜索
33.33%
邮件
0.03%
外链引荐
2.26%
社交媒体
1.17%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
西班牙
4.59%
法国
8.54%
英国
4.92%
俄罗斯
5.28%
美国
23.64%
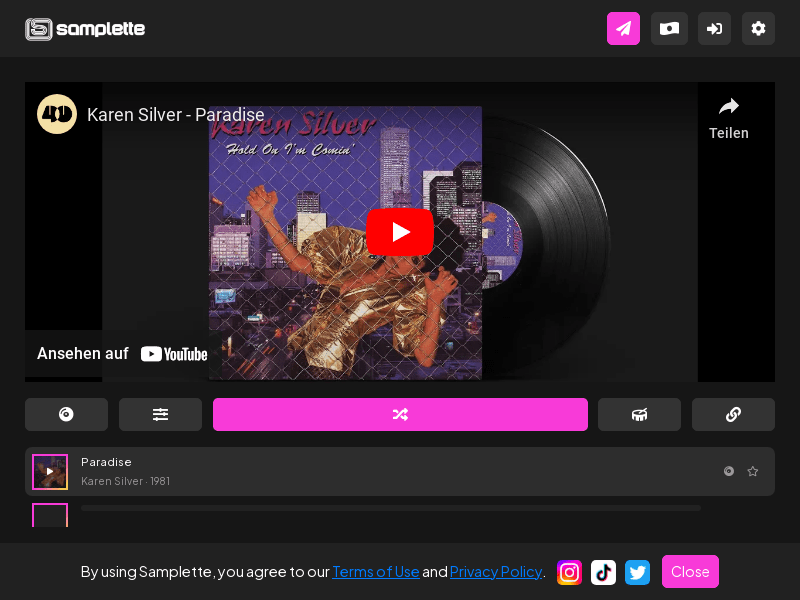
数码时代的挖掘音乐宝藏
Samplette是一个由制作人为制作人精心策划的数千个采样集合。它允许用户在YouTube上生成随机歌曲、音乐和节拍,帮助用户无缝浏览随机音乐。用户可以使用各种过滤器来浏览符合自己风格和需求的音乐,并获得灵感用于创作自己的音乐。Samplette还提供每分钟节拍计数器和有关音乐的元数据。请注意,在使用Samplette上的任何内容之前,必须完全与音乐的所有者进行合法授权。
Youtube播放列表随机播放器,可以随机播放和循环任何Youtube播放列表。
Youtube Playlist Randomizer是一个允许用户随机播放和循环Youtube和Youtube音乐播放列表的免费网站。它解决了Youtube播放列表随机播放不完全随机、存在广告干扰的问题。用户可以免费享受无广告、背景播放的播放列表体验。
创作灵感提供者
LyricStudio 是一个基于你选择的主题和风格为你提供独特歌词创意的工具。它类似于一个合作创作者,为你提供开始创作的思路,并在你遇到困难时帮助你。此外,LyricStudio 还可帮助你摆脱创作障碍,通过个性化的建议和灵感激发你的创造力。你可以完全保留你创作的歌词版权,LyricStudio 也不收取任何版税。
ChatGPT for YouTube,为YouTube提供定制的提示
ChatGPT for YouTube让YouTube的ChatGPT使用更加简单。您可以为每个新视频设置自定义提示。看了一个烹饪视频想要一个食谱?在回顾2009年的纪录片时感到困惑?GPT Prompts For YouTube应有尽有。欢迎使用这个插件,我们正在积极开发中,请在GitHub上留下您的反馈。如果遇到任何问题,请与我联系。
在YouTube上快速增长的移动应用
RankU是一个移动应用,可以帮助您在YouTube上快速增长。它提供了量身定制和个性化的推荐,让您的频道和视频得到优化。通过我们的应用程序,您可以轻松获得有关竞争对手、市场排名和调整计划的洞察力。无论是创建新频道还是拍摄新视频,我们的个性化推荐将指导您快速、轻松地增长。
AI生成小说创作灵感
PlotPrompts是一款AI生成小说创作灵感的工具,可以生成主角、反派、配角、生物、剧情等创作灵感,帮助你构建完整的故事大纲和章节梗概,提高写作效率和创作质量。PlotPrompts的创作灵感是可选的,旨在激发你的创造力,而不是束缚它。你只需要提供故事类型,PlotPrompts就会为你提供足够的创作灵感,帮助你完成故事。
一站式智能创作平台
创作王是一个全能型智能创作平台,可以智能回答、智能创作、智能编写、智能翻译、智能写代码等,帮助您解决各种创作难题。我们提供小红书创作、今日头条创作、知乎问答创作、微博创作、公众号创作等多种场景下不同风格的文章创作,以及视频口播稿、SWOT 分析法、英文写作、节日祝福、夸夸神器、塔罗牌预测、解梦神器等多种创作工具。
获取YouTube视频的摘要和转录
YouTube Scribe是一个在线工具,用于获取YouTube视频的摘要和转录。它可以自动分析视频的内容,并生成视频的关键信息,包括标题、描述、标签等。用户可以通过输入视频的URL,获取视频的摘要和转录,并可以选择将其导出为文本文件。YouTube Scribe的主要优势是快速、准确地提取视频信息,节省用户的时间和精力。该工具免费使用,无需注册和登录。欢迎使用YouTube Scribe来获取YouTube视频的关键信息!
AI YouTube Description Generator - 免费,无需登录
AI YouTube Description Generator是一个为您的YouTube视频生成优化描述的小工具,无论是否提供视频剧本。只需提供视频标题和剧本或总体主题,即可生成专为您的视频定制的描述。生成的描述符合YouTube SEO的要求,并充分利用了5000个字符的限制。您可以指定关键字,以便在生成的描述中包含这些关键字。您还可以选择包含表情符号以提高用户参与度,以及选择整体语调以与您的品牌相匹配。
ChatGPT与Youtube的互动AI对话
Chat With Youtube是一个能够与YouTube视频进行互动AI对话的平台。用户只需粘贴YouTube视频链接即可开始与AI驱动的对话。该产品具有以下功能:1.与任何YouTube视频进行对话;2.智能分析视频内容;3.保存聊天记录;4.多种产品使用示例。Chat With Youtube适用于各种使用场景,包括学习、娱乐等。产品定价和定位请参考官方网站。
解放创作者的灵感笔记工具
ThinkerNotes是一款旨在帮助创作者摆脱创作困境,提供无限灵感的笔记工具。通过捕捉阅读中的想法和提取见解,帮助用户生成原创内容。它还提供了组织笔记、标签管理、2向链接、知识库扩展等功能。ThinkerNotes帮助用户创建独特的内容,提升思维和创造力,并成为内容创作的思想领袖。
生成创作灵感的AI助手
Fusion是一款AI助手,通过生成创作灵感的方式帮助用户提升创造力和创作效率。它可以生成各种创作提示和随机组合,包括文字、图像、视频等。用户可以根据生成的提示来进行写作、设计、编程等创作活动,提供了丰富的创作灵感和思路。Fusion还提供定制化的功能,用户可以根据自己的需求来定制生成的内容。Fusion还支持多种使用场景,包括写作、设计、教育等领域。
专为YouTube创作者打造的AI YouTube内容工厂。
VideoIdeas.ai是一个强大的AI工具,旨在帮助YouTube创作者生成病毒级脚本、新鲜的视频创意和 engaging内容,提供全面的YouTube内容创建解决方案。产品背景信息丰富,价格合理,定位于提高YouTube创作者的内容创作效率和吸引力。
存储、分享和查找创作灵感的终极工具
PromptMaster是一个存储、分享和查找创作灵感的终极工具。它让你可以安全地存储所有的创作灵感,与世界分享你的创作,并从其他用户共享的灵感中获取灵感。PromptMaster拥有简洁的界面和强大的功能,帮助你更好地组织和管理你的创作灵感。
轮盘随机选择器
Spin the Wheel - Random Picker是一个免费的轮盘随机选择器,可用于游戏、抽奖或决策。用户可以自定义轮盘并随机选择选项。该产品易于使用,提供了丰富的功能和定制选项。
下载使用ChatGPT扩展名的YouTube摘要来汇总视频
YouTube™ Summarizer Chrome扩展允许用户访问他们正在观看的视频的摘要。用户只需点击一下即可轻松查看和访问视频的关键要点。对于那些想要快速了解视频关键要点而不必观看整个视频的人来说,这个扩展可以是一个有用的工具。 主要功能: - 视频摘要:自动对冗长的YouTube™视频进行摘要,不丢失重要信息。 - 时间戳:提供时间戳摘要,允许观众快速导航到他们想观看的具体部分。 - 用户友好界面:简单直观的界面,极易使用。 - 准确可靠:准确提供视频的关键要点,不漏掉任何重要信息。 使用方法: - 点击“添加到Chrome”按钮安装扩展 - 播放带有字幕的任意视频 - 在右上角会看到两个选项 - Transcript(文本稿)和Summarizer(摘要生成器) - 根据需求点击其中一个选项 常见问题解答: 1. 什么是视频摘要生成器? 这个工具可以自动生成YouTube™视频的简要摘要,突出主要要点和关键信息。这可以帮助观众快速了解视频内容,而无需观看整个视频。 2. 它是如何工作的? 它使用OpenAI的技术学习来分析视频的字幕。
AI智能提示包,助您创作、激发灵感
Prompt.Cafe是一个AI智能提示包,包括Starter Pack、Midjourney Prompt Generator和Notion Pack等工具。用户可以通过AI提示激发灵感、使用Prompt Generator生成新提示,并利用Notion模板组织自己的提示库。该产品定位于帮助用户创建一致的AI图像,提供超过400个标签供用户组合使用。
无需注册或付费,轻松生成准确的YouTube视频转录和字幕
Editby.AI YouTube转录工具是一个免费、高效的工具,可将您的YouTube视频转录为文本。无论您是内容创作者还是学生,我们的工具提供快速准确的YouTube视频转录,无需注册或付费。通过一键操作,您可以复制和下载转录文本,并轻松跳转到视频的特定位置。此外,您还可以搜索转录文本中的关键词,并以绿色高亮显示。利用我们的工具,节省宝贵的时间,提高工作效率!
用AI给你的创作带来灵感与艺术
ArtHeart.ai是一个基于人工智能技术的创作平台,通过生成器和算法,为用户提供创意灵感和艺术设计。它具有以下特点: 1. 自动生成艺术创作:通过AI算法,自动生成独特的艺术作品,为创作者提供无限灵感。 2. 定制化设计:用户可以根据自己的需求和喜好,定制生成器生成的艺术作品。 3. 创作协同:用户可以与其他创作者进行交流和合作,共同创作出更加优秀的作品。 4. 定价灵活:平台提供不同定价方案,满足用户不同的需求和预算。 ArtHeart.ai定位于为创作者提供艺术创作的灵感和工具,帮助他们在创作过程中获得更多的想象力和创造力。
节省时间,轻松获取YouTube视频摘要
SayDub - YouTube Summary with ChatGPT是一款免费的Chrome插件,利用ChatGPT技术为YouTube视频提供摘要。它可以快速提供准确的视频要点摘要,节省时间和精力。用户可以轻松复制和下载基于时间戳的免费YouTube转录。无论是学生、专业人士还是好奇的学习者,这款插件都是你的终极伴侣,可以快速概览视频内容,提高学习、研究和获取信息的效率。通过优化SEO,它还可以帮助用户轻松高效地访问YouTube内容。
免费AI驱动的YouTube标题生成器,快速创建高点击量标题
YT标题生成器是一款由AI驱动的免费在线工具,旨在帮助YouTube创作者快速生成吸引人且符合SEO优化的标题。该工具的重要性在于,在竞争激烈的YouTube平台上,一个好的标题能够显著提高视频的点击率和观看量。其主要优点包括:能够瞬间生成标题,节省创作者的时间和精力;生成的标题经过优化,有助于提高视频在搜索结果中的排名;支持添加表情符号,使标题更加生动有趣。产品背景是为了满足YouTube创作者对于高效标题创作的需求而开发。价格方面,目前可免费使用。该产品定位于为YouTube创作者提供便捷、高效的标题创作解决方案。
通过AI提取YouTube视频的时间戳和字幕,高效便捷。
YouTube Transcripts Machine 是一款基于AI的在线工具,旨在快速提取YouTube视频的字幕和时间戳。它利用先进的AI技术自动处理视频内容,无需人工手动操作,极大地提高了工作效率。该工具适用于需要快速获取视频文本信息的用户,如研究人员、内容创作者和学习者。它支持任何有字幕的公开YouTube视频,具有高效、准确和易于使用的特点。目前该工具为用户免费提供服务,旨在帮助用户更高效地处理和利用YouTube视频内容。
让ChatGPT观看YouTube视频并提供摘要
VidSummize - AI YouTube Summary with Chat GPT是一款使用人工智能技术的Chrome插件,可以让ChatGPT观看YouTube视频并生成高质量、易读的摘要。它可以摘要任何长度的YouTube视频,提供详细但简洁的章节和要点,帮助用户更高效地获取视频内容,并适用于各种场景。
AI 助力 YouTube 创作者
Morise.ai 是一个 AI 助力工具箱,帮助 YouTube 创作者更高效地创建内容。它提供智能创意、标题生成、视频描述生成、标签生成等功能,可帮助创作者节省时间、提高视频质量,并帮助视频更好地排名和吸引观众。Morise.ai 已被许多知名创作者使用,广受好评。
随机播放你喜欢的播客
Podsee是一个网站,提供随机播放你喜欢的播客的功能。它基于Elixir语言开发,使用Phoenix LiveView框架构建。Podsee的优势在于可以帮助用户发现新的播客内容,并提供便捷的随机播放功能。Podsee是免费使用的。
这是一个能在Youtube上使用AI魔法进行营销推广的OpenAI ChatGPT强大工具。
OpenAI Chat GPT For Youtube™是一个强大的工具,可在Youtube上使用AI魔法进行营销推广。它能够让您更快速地回复评论和互动,并提供高质量的答案。它简单易用,帮助您节省时间和精力。
节省时间,即时获取YouTube视频的关键观点。
Eightify是一个AI YouTube摘要插件,能够在几秒钟内为您提供任何YouTube视频的要点。它能够为您提供视频的要点和关键观点,还可以对评论进行摘要,快速了解观众的想法。支持40多种语言的摘要翻译,无论您观看的是商业研讨会、新闻报道还是健康和健身播客,我们的AI摘要工具都会为您提供简洁明了的摘要和关键观点。通过摘要带有时间戳的段落,您可以轻松地浏览视频。只需点击一下即可与朋友、同事或社交媒体分享摘要和见解。平均处理时间仅为7秒,即使是4-6小时的视频也可以轻松摘要。Eightify由OpenAI ChatGPT API提供支持,是一个可靠的AI YouTube视频摘要工具。
在线随机生成宝可梦,AI创造独特宝可梦角色
Free Online Random Pokemon Generator是一个在线工具,它允许用户随机生成宝可梦角色,并且支持AI宝可梦创作。这个工具覆盖了从第一代到最新发布的所有1400多个宝可梦角色,为用户提供了全面的宝可梦生成体验。AI宝可梦生成器允许用户通过输入文本描述来创造独特的宝可梦,将用户的想象力变为现实。此外,该工具还提供了自定义生成选项,用户可以根据自己的喜好设置宝可梦的类型、世代、稀有度等,以创建个性化的宝可梦团队。支持批量生成,最多一次生成6个宝可梦,大大提高了团队建设和收集效率。所有功能完全免费,无需注册,无需信用卡,只需打开网页即可开始使用。

© 2026 AIbase 备案号:闽ICP备08105208号-14