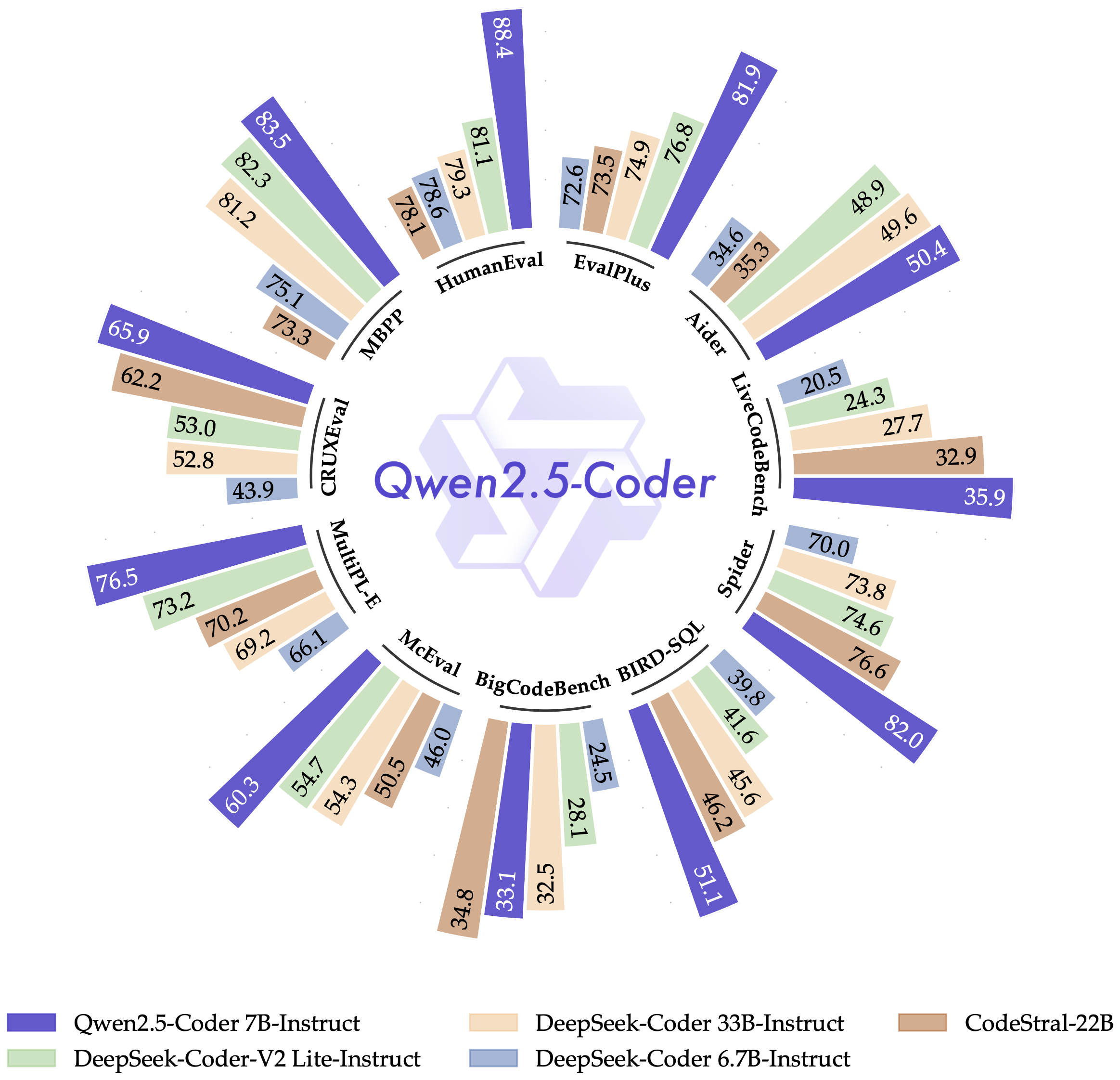
Qwen2.5-Coder是Qwen2.5开源家族的一员,专注于代码生成、推理、修复等任务。它通过扩增大规模代码训练数据,提升了代码能力,同时保持了数学和通用能力。该模型支持92种编程语言,并在代码相关任务中取得了显著提升。Qwen2.5-Coder采用Apache 2.0许可,旨在加速代码智能的应用。
需求人群:
"Qwen2.5-Coder适合软件开发者、编程教育者和研究人员。它能够帮助开发者提高编程效率,减少代码错误,同时为教育者提供丰富的编程教学资源,为研究人员提供强大的代码分析工具。"
使用场景示例:
开发者利用Qwen2.5-Coder自动生成代码,提高开发速度。
编程教育者使用模型进行代码教学,帮助学生理解编程概念。
研究人员使用Qwen2.5-Coder进行代码分析,探索编程语言的新特性。
产品特色:
支持92种编程语言的代码生成、推理和修复。
通过指令微调,提升了多任务性能和泛化性。
在多种编程语言任务上表现出色,包括小众语言。
在代码推理任务上表现卓越,提升了复杂指令遵循能力。
在代码和数学任务上都表现出色,强化了理科生形象。
保持了Qwen2.5的通用能力优势。
使用教程:
访问Qwen2.5-Coder的官方网站或GitHub页面。
阅读模型的文档,了解其功能和使用限制。
下载并安装必要的软件依赖和环境。
根据文档指导,设置模型参数和配置文件。
输入代码或指令,开始使用Qwen2.5-Coder进行代码生成、推理或修复。
评估模型输出的结果,根据需要进行调整和优化。
参与社区讨论,反馈使用体验,共同推动模型的发展。
浏览量:94
最新流量情况
月访问量
897.45k
平均访问时长
00:00:34
每次访问页数
1.40
跳出率
61.70%
流量来源
直接访问
39.23%
自然搜索
43.24%
邮件
0.07%
外链引荐
14.05%
社交媒体
2.92%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
中国
27.17%
德国
2.40%
印度
3.91%
俄罗斯
3.02%
美国
14.54%
商汤自研代码大模型赋能
代码小浣熊(Raccoon)是商汤自研的代码大模型赋能工具,提供多种编程语言支持,包括 Python、C#、C/C++、Java、Go、JavaScript 等。它以 IDE 插件的形式为用户提供智能编程服务,帮助用户在日常编程中随时随地开启 AI 编程。代码小浣熊能够快速定位代码中的问题,提供自动补全、代码纠错、语法优化等功能,大大提升编程效率。
腾讯云 AI 代码助手是一款基于混元代码大模型的开发编程提效辅助工具,提供自动补全、代码生成、技术对话等功能。
腾讯云 AI 代码助手是由腾讯云自研的一款开发编程提效辅助工具,提供基于混元代码大模型的技术对话、代码补全、代码诊断和优化等能力,帮助开发者生成优质代码、解决技术难题,提升编码效率。
代码演示平台,提供智能问答体验
通义千问2.5-代码-demo是一个在线平台,旨在通过代码演示为用户提供智能问答体验。该平台结合了最新的人工智能技术,能够理解用户的查询意图,并提供准确的回答。它的重要性在于能够辅助开发者和技术人员快速解决问题,提高工作效率。产品背景信息显示,该平台在2024年11月11日更新,已经提供了1581次访问,显示了其受欢迎程度。
结合全功能代码编辑器和AI能力,提供100+大厂真题,助力高效掌握算法知识。
豆包 MarsCode 是一款面向编程学习者的在线代码练习平台。它通过整合先进的AI技术和全功能代码编辑器,为用户提供了一个高效、实用的学习环境。该平台拥有100+道大厂真题,能够帮助用户精准掌握编程知识点,提升算法能力,顺利获得心仪的工作机会。其主要优点在于AI陪练功能,能够随时为用户解答编程疑惑,提供详细的解题思路和方法。此外,原生IDE体验让用户能够更加得心应手地进行代码练习。产品由北京引力弹弓科技有限公司开发,定位为编程学习领域的辅助工具,价格策略暂未明确,但提供了免费试用的机会。
开源代码生成与推理的大型语言模型
Qwen2.5-Coder是一系列特定于代码的大型语言模型,覆盖了从0.5亿到32亿参数的不同模型大小,以满足不同开发者的需求。该模型在代码生成、代码推理和代码修复方面有显著提升,基于强大的Qwen2.5,训练令牌扩展到5.5万亿,包括源代码、文本代码基础、合成数据等。Qwen2.5-Coder-32B是目前最先进的开源代码生成大型语言模型,其编码能力与GPT-4o相匹配。此外,该模型还支持长达128K令牌的长上下文,并采用AWQ 4-bit量化技术,以提高模型的效率和性能。
一个提供代码Artifacts的在线平台
通义千问2.5-代码-Artifacts是一个专注于代码Artifacts的平台,旨在为用户提供代码相关的资源和服务。该平台可能包含代码示例、开发工具、代码管理等功能,以提高开发者的工作效率和代码质量。它可能依托于人工智能技术,提供智能代码辅助和自动化测试等功能,具有提高开发效率、降低错误率等优点。
开源代码生成大型语言模型
Qwen2.5-Coder是一系列专为代码生成设计的Qwen大型语言模型,包含0.5、1.5、3、7、14、32亿参数的六种主流模型尺寸,以满足不同开发者的需求。该模型在代码生成、代码推理和代码修复方面有显著提升,基于强大的Qwen2.5,训练令牌扩展到5.5万亿,包括源代码、文本代码基础、合成数据等。Qwen2.5-Coder-32B是目前最先进的开源代码生成大型语言模型,其编码能力与GPT-4o相匹配。它不仅增强了编码能力,还保持了在数学和通用能力方面的优势,并支持长达128K令牌的长上下文。
代码生成与理解的大型语言模型
Qwen2.5-Coder-14B是Qwen系列中专注于代码的大型语言模型,覆盖了0.5到32亿参数的不同模型尺寸,以满足不同开发者的需求。该模型在代码生成、代码推理和代码修复方面有显著提升,基于强大的Qwen2.5,训练令牌扩展到5.5万亿,包括源代码、文本代码接地、合成数据等。Qwen2.5-Coder-32B已成为当前最先进的开源代码LLM,其编码能力与GPT-4o相匹配。此外,它还为现实世界应用如代码代理提供了更全面的基础,不仅增强了编码能力,还保持了在数学和通用能力方面的优势。支持长达128K令牌的长上下文。
Qwen2.5-Coder系列中的1.5B参数代码生成模型
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专为代码生成、推理和修复而设计。基于强大的Qwen2.5,该模型在训练时包含了5.5万亿的源代码、文本代码基础、合成数据等,使其在代码能力上达到了开源代码LLM的最新水平。它不仅增强了编码能力,还保持了在数学和通用能力方面的优势。
Qwen2.5-Coder系列中的1.5B参数代码生成模型
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于Qwen2.5的强大能力,该模型在训练时使用了5.5万亿的源代码、文本代码基础、合成数据等,是目前开源代码生成语言模型中的佼佼者,编码能力与GPT-4o相媲美。它不仅增强了编码能力,还保持了在数学和通用能力方面的优势,为实际应用如代码代理提供了更全面的基础。
智能代码错误修复助手
ANDRES GPT是一款智能代码错误修复助手,能够帮助开发者快速定位和修复代码中的bug,提高开发效率。该产品定位于为开发者提供便捷的代码错误修复服务,定价灵活多样,适合个人开发者和企业用户使用。
开源代码生成大型语言模型
Qwen2.5-Coder是一系列针对代码生成优化的大型语言模型,覆盖了0.5、1.5、3、7、14、32亿参数的六种主流模型尺寸,以满足不同开发者的需求。Qwen2.5-Coder在代码生成、代码推理和代码修复方面有显著提升,基于强大的Qwen2.5,训练令牌扩展到5.5万亿,包括源代码、文本代码接地、合成数据等,成为当前最先进的开源代码LLM,其编码能力与GPT-4o相匹配。此外,Qwen2.5-Coder还提供了更全面的基础,适用于现实世界中的代码代理等应用场景。
Codiga: 静态代码分析,随时修复代码!
Codiga是一个可定制的实时静态代码分析引擎,适用于在任何你编写代码的地方。它提供了自动化的代码质量分析、安全扫描和技术债务检测等功能。Codiga支持VS Code、JetBrains、Visual Studio、GitHub、GitLab和Bitbucket等平台,帮助开发人员提高代码质量,降低技术债务。
Qwen2.5-Coder系列中的1.5B参数代码生成模型
Qwen2.5-Coder-1.5B是Qwen2.5-Coder系列中的一款大型语言模型,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该模型通过扩展训练令牌至5.5万亿,包括源代码、文本代码基础、合成数据等,成为当前开源代码LLM中的佼佼者,编码能力媲美GPT-4o。此外,Qwen2.5-Coder-1.5B还强化了数学和通用能力,为实际应用如代码代理提供了更全面的基础。
7B参数的代码生成语言模型
Qwen2.5-Coder-7B-Instruct是Qwen2.5-Coder系列中的一款代码特定大型语言模型,覆盖了0.5、1.5、3、7、14、32亿参数的六种主流模型尺寸,以满足不同开发者的需求。该模型在代码生成、代码推理和代码修复方面有显著提升,基于强大的Qwen2.5,训练令牌扩展到5.5万亿,包括源代码、文本代码基础、合成数据等。Qwen2.5-Coder-32B已成为当前最先进的开源代码LLM,其编码能力与GPT-4o相匹配。此外,该模型还支持长达128K令牌的长上下文,并为实际应用如代码代理提供了更全面的基础。
Qwen2.5-Coder系列的1.5B参数代码生成模型
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该模型在训练中使用了5.5万亿的源代码、文本代码关联、合成数据等,使其成为当前开源代码语言模型中的佼佼者。该模型不仅在编程能力上有所增强,还保持了在数学和通用能力方面的优势。
Qwen2.5-Coder系列中的1.5B参数量级代码生成模型
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该模型在训练中包含了5.5万亿的源代码、文本代码关联、合成数据等,是目前开源代码语言模型中的佼佼者,其编码能力可与GPT-4相媲美。此外,Qwen2.5-Coder还具备更全面的现实世界应用基础,如代码代理等,不仅增强了编码能力,还保持了在数学和通用能力方面的优势。
Qwen2.5-Coder系列的0.5B参数代码生成模型
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该模型在训练中涵盖了5.5万亿的源代码、文本代码基础、合成数据等,成为当前开源代码语言模型的最新技术。该模型不仅在编程能力上与GPT-4o相匹配,还在数学和一般能力上保持了优势。Qwen2.5-Coder-0.5B-Instruct-GPTQ-Int4模型是经过GPTQ量化的4位指令调整模型,具有因果语言模型、预训练和后训练、transformers架构等特点。
Qwen2.5-Coder系列的0.5B参数代码生成模型
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于Qwen2.5的强大能力,通过扩展训练令牌至5.5万亿,包括源代码、文本代码基础、合成数据等,Qwen2.5-Coder-32B已成为当前最先进的开源代码LLM,其编码能力与GPT-4o相匹配。此模型为AWQ量化的4位指令调整0.5B参数版本,具有因果语言模型、预训练和后训练、transformers架构等特点。
Qwen2.5-Coder系列中的14B参数代码生成模型
Qwen2.5-Coder-14B-Instruct是Qwen2.5-Coder系列中的一个大型语言模型,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该模型通过扩展训练令牌到5.5万亿,包括源代码、文本代码接地、合成数据等,成为当前开源代码LLM的最新技术。它不仅增强了编码能力,还保持了在数学和通用能力方面的优势,并支持长达128K令牌的长上下文。
Qwen2.5-Coder系列中的7B参数代码生成模型
Qwen2.5-Coder-7B是基于Qwen2.5的大型语言模型,专注于代码生成、代码推理和代码修复。它在5.5万亿的训练令牌上进行了扩展,包括源代码、文本代码接地、合成数据等,是目前开源代码语言模型的最新进展。该模型不仅在编程能力上与GPT-4o相匹配,还保持了在数学和一般能力上的优势,并支持长达128K令牌的长上下文。
自动查找并修复代码中的错误,无需查看代码。
Latta是一个AI驱动的自动化错误修复工具,旨在帮助开发者节省查找和修复bug的时间。它通过记录用户会话并重放,让开发者能够快速定位问题并修复。Latta的主要优点包括提高开发效率、减少维护成本、提升产品质量,并确保代码安全。Latta适用于软件公司、代码自由职业者和初创企业,帮助他们快速迭代和适应市场变化。
AI代码助手,自动编写和修复代码。
Micro Agent是一个AI代码助手,它能够根据测试用例或设计截图自动编写代码,直到测试通过或设计匹配。它主要针对那些需要重复迭代以修复代码的问题,通过AI技术减少手动迭代的过程。Micro Agent专注于编写测试并生成通过测试的代码,而不是尝试成为一个全栈开发者。它与Visual Copilot集成,可以直接连接Figma,确保设计到代码的高保真转换。
Qwen2.5-Coder系列中的3B参数模型,专注于代码生成与理解。
Qwen2.5-Coder-3B是Qwen2.5-Coder系列中的一个大型语言模型,专注于代码生成、推理和修复。基于强大的Qwen2.5,该模型通过增加训练令牌至5.5万亿,包括源代码、文本代码基础、合成数据等,实现了在代码生成、推理和修复方面的显著改进。Qwen2.5-Coder-32B已成为当前最先进的开源代码大型语言模型,其编码能力与GPT-4o相匹配。此外,Qwen2.5-Coder-3B还为现实世界的应用提供了更全面的基础,如代码代理,不仅增强了编码能力,还保持了在数学和通用能力方面的优势。
Qwen2.5-Coder系列中的指令调优0.5B参数代码生成模型
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,通过扩展训练令牌到5.5万亿,包括源代码、文本代码基础、合成数据等,Qwen2.5-Coder-32B已成为当前最先进的开源代码LLM,其编码能力与GPT-4o相匹配。该模型不仅增强了编码能力,还保持了在数学和通用能力方面的优势,为实际应用如代码代理提供了更全面的基础。
Qwen2.5-Coder系列中的0.5B参数代码生成模型
Qwen2.5-Coder是Qwen大型语言模型的最新系列,专注于代码生成、代码推理和代码修复。基于强大的Qwen2.5,该系列模型通过增加训练令牌至5.5万亿,包括源代码、文本代码基础、合成数据等,显著提升了编码能力。Qwen2.5-Coder-32B已成为当前最先进的开源代码大型语言模型,编码能力与GPT-4o相当。此外,Qwen2.5-Coder还为实际应用如代码代理提供了更全面的基础,不仅增强了编码能力,还保持了在数学和通用能力方面的优势。
专业的在线颜色代码转换配色工具网站
颜色代码表是一个为设计师和开发者提供一站式色彩解决方案的专业网站。运用机器学习技术,为您推荐最适合的配色方案AI辅助配色。它基于色彩理论,提供多种颜色工具,包括颜色代码转换、配色方案生成、渐变色生成等,帮助用户快速高效地完成设计工作。该网站支持多种颜色格式,并提供代码导出功能,方便用户将颜色方案直接应用到项目中。此外,它还符合WCAG 2.1标准,确保配色方案的无障碍设计。

© 2026 AIbase 备案号:闽ICP备08105208号-14