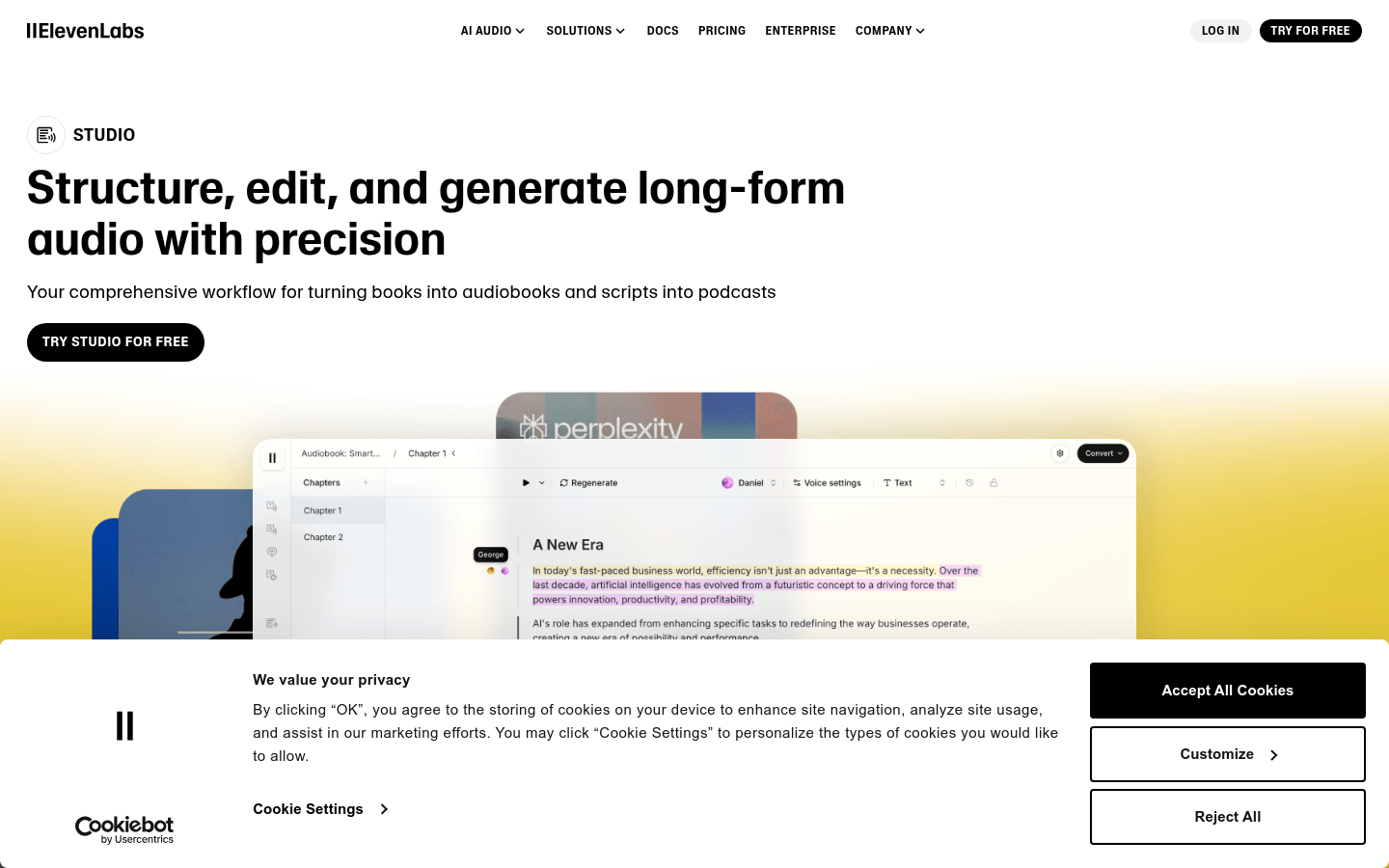
ElevenLabs Studio 是一个专注于音频内容创作的平台,利用先进的人工智能技术,能够将文本内容转化为高质量的音频。其主要优点包括支持多种文件格式、提供丰富的语音库、能够根据情感和上下文调整语音表达等。该平台适用于有声读物制作、播客创作等场景,能够帮助创作者高效地生成音频内容,提升创作效率和质量。其定价策略可能因用户需求和使用场景而异,具体价格可参考官网的定价页面。
需求人群:
"该产品适合有声读物创作者、播客制作人、音频内容开发者以及需要高效音频生成解决方案的企业和团队。它能够帮助他们快速将文本内容转化为高质量的音频,节省时间和成本,同时提供丰富的语音选择和高质量的音频输出,满足不同场景下的音频创作需求。"
使用场景示例:
Storytel 与 ElevenLabs 合作,推出新的 VoiceSwitcher 功能,提升用户体验。
HarperCollins 出版社利用 ElevenLabs 将更多故事通过音频形式呈现给读者。
USA Today 畅销书作者 Leeanna Morgan 使用 ElevenLabs 提高有声书销量。
产品特色:
支持多种文件格式(EPUB、TXT、PDF、HTML)和从URL导入项目。
提供数千种语音选择,并可通过语音设计工具创建新语音,调整年龄、口音、语速等。
通过文本编辑器添加多章节,为不同部分分配独特语音,重新生成和下载选定短语。
根据情感线索和上下文调整语音表达,避免逻辑错误。
自动生成音频质量检查,自动修复发音错误和音频瑕疵。
支持多语言语音生成,覆盖32种语言。
为特定文本片段分配特定语音,增强角色沉浸感。
编辑、优化和重新生成项目中的小片段,直到达到理想效果。
使用教程:
访问 https://elevenlabs.io/studio 并注册或登录账户。
选择 'Try Studio for free' 开始免费试用。
上传支持的文件格式(如 EPUB、TXT、PDF、HTML)或从 URL 导入项目。
选择合适的语音或创建自定义语音,调整相关参数(如年龄、口音、语速等)。
在文本编辑器中添加章节,为不同部分分配语音,编辑和优化内容。
生成音频后,系统会自动进行质量检查,如有问题将自动重新生成。
下载生成的音频文件,用于有声读物、播客或其他音频项目。
浏览量:210
最新流量情况
月访问量
23600.98k
平均访问时长
00:05:29
每次访问页数
6.18
跳出率
40.17%
流量来源
直接访问
59.01%
自然搜索
36.59%
邮件
0.03%
外链引荐
2.54%
社交媒体
1.63%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
巴西
4.72%
英国
3.13%
印度
11.36%
巴基斯坦
5.19%
美国
15.95%
AI 生成有声读物
Speechki 是一款使用人工智能生成自然真实的有声读物的产品。它提供 341 种自然音色的声音,支持 77 种语言。用户可以根据需要自定义声音,并在 15 分钟内获得完整的有声读物。Speechki 的定价相比传统录制要便宜 10 倍,并且只需要 15 分钟即可生成一本书籍。它简化了合同协议,让用户可以快速、简单地享受人工智能语音合成技术带来的便利。
一个用于将书籍转为有声读物、剧本转为播客的音频生成平台。
ElevenLabs Studio 是一个专注于音频内容创作的平台,利用先进的人工智能技术,能够将文本内容转化为高质量的音频。其主要优点包括支持多种文件格式、提供丰富的语音库、能够根据情感和上下文调整语音表达等。该平台适用于有声读物制作、播客创作等场景,能够帮助创作者高效地生成音频内容,提升创作效率和质量。其定价策略可能因用户需求和使用场景而异,具体价格可参考官网的定价页面。
定制智能儿童有声读物
BabyStoryAI是一款基于最新人工智能技术创建的个性化儿童有声读物。它根据道德价值观和您的目标生成故事。产品定价灵活,并提供多种语言选择。BabyStoryAI旨在为孩子们打造一个栩栩如生的梦境,让他们在有声读物中获得乐趣和教育。
一键生成有声读物的软件
AudioBook Bot是一款使用生成式人工智能将文本转换为语音的工具。它可以为您的书籍提供多个角色的声音,并且可以使用您自己的声音来叙述书籍。它能以极少的样本生成具有整个角色阵容的有声读物。
智能语音转换,自动制作有声读物
Audie.AI 是一款智能语音转换工具,可以自动将书籍转化为有声读物。它使用先进的 AI 技术,提供清晰自然的叙述,包括不同的语速和语调。您可以选择不同的演讲者声音,甚至可以克隆自己的声音。Audie.AI 的优势在于快速、廉价且高质量的转换,帮助您开拓庞大的有声读物市场。您无需支付版税,完全保留所有权利。我们提供不同的套餐,适应不同的需求。
Freepik AI 视频生成器,基于人工智能技术快速生成高质量视频内容。
Freepik AI 视频生成器是一款基于人工智能技术的在线工具,能够根据用户输入的初始图像或描述快速生成视频。该技术利用先进的 AI 算法,实现视频内容的自动化生成,极大地提高了视频创作的效率。产品定位为创意设计人员和视频制作者提供快速、高效的视频生成解决方案,帮助用户节省时间和精力。目前该工具处于 Beta 测试阶段,用户可以免费试用其功能。
人工智能入门教程网站,提供全面的机器学习与深度学习知识。
该网站由作者从 2015 年开始学习机器学习和深度学习,整理并编写的一系列实战教程。涵盖监督学习、无监督学习、深度学习等多个领域,既有理论推导,又有代码实现,旨在帮助初学者全面掌握人工智能的基础知识和实践技能。网站拥有独立域名,内容持续更新,欢迎大家关注和学习。
推动人工智能安全治理,促进技术健康发展
《人工智能安全治理框架》1.0版是由全国网络安全标准化技术委员会发布的技术指南,旨在鼓励人工智能创新发展的同时,有效防范和化解人工智能安全风险。该框架提出了包容审慎、确保安全,风险导向、敏捷治理,技管结合、协同应对,开放合作、共治共享等原则。它结合人工智能技术特性,分析风险来源和表现形式,针对模型算法安全、数据安全和系统安全等内生安全风险,以及网络域、现实域、认知域、伦理域等应用安全风险,提出了相应的技术应对和综合防治措施。
为独立作者提供全球有声读物分发和盈利的平台
Findaway Voices by Spotify 是一个面向独立作者的有声读物分发平台。它通过与 Spotify 等全球知名平台合作,帮助作者将作品推向全球听众。该平台不仅提供广泛的分发渠道,还为作者提供高比例的版税收入,帮助他们更好地实现商业价值。此外,它还提供听众洞察功能,帮助作者了解作品的受欢迎程度和趋势。其定位是为独立创作者提供一站式的有声读物解决方案,帮助他们在全球范围内获得更多的曝光和收益。
用人工智能生成音频和视频
Sora AI Video Generator是一个使用人工智能技术生成视频的在线平台。用户只需要输入文本描述,它就可以自动生成高质量的视频动画。该平台提供强大的创意工具,使用户无需专业技术就可以创作出精美的视频内容。关键功能包括:支持多种视觉风格选择,视频分辨率高达4K,支持添加背景音乐和文字,一键生成高质量视频等。适用于视频创作者、广告公司、游戏开发者等创意行业,以及个人用户的视频内容生产。
京东自主研发的人工智能开放平台
京东人工智能开放平台NeuHub,汇聚京东自主研发的人工智能核心技术,包含语音、图像、视频、NLP等技术,通过平台向外开放,助力行业智能升级。平台还提供数据标注、模型开发、训练和发布等全流程服务,以及创新应用案例,帮助企业实现智能化转型。
一键将各种文本格式转换为自然发音的有声读物。
QuickPiperAudiobook是一款能够将PDF、epub、txt、mobi、djvu、HTML、docx等多种文本格式转换为有声读物的桌面客户端软件。它使用piper模型支持多种语言,所有转换过程完全离线进行,保护用户隐私。该软件特别适合需要将文本内容快速转换为音频格式的用户,例如视障人士、喜欢听书的用户或需要学习外语的用户。
OLAMI是一个人工智能开放平台
OLAMI是一个提供云端API、管理界面、多元机器感知解决方案的人工智能软件开发平台。OLAMI平台具有语音识别、自然语言理解、对话管理、语音合成等语音AI技术,以及图像识别、语义理解等视觉AI技术,可以轻松地为产品加入人工智能,提升用户体验。
使用人工智能将文本转换为音频
AI语音生成器是一个简单易用的产品,它使用人工智能技术将文本转换为音频。它提供了多达25种不同的声音,完美演绎英语。您只需在Telegram上输入文本,我们即可回复相应的音频,无需等待。立即试用,快速将文本转换为语音。
人工智能视频生成APP,支持上传单张图片生成说话视频
D-ID APP利用人工智能技术,可以通过上传单张图片生成说话的视频。支持上传自己的语音,对上传图片中的人物进行 Lip Sync。视频效果逼真,提供了三种版本:Lite 免费版本,Pro 每月$29,Advanced 每月$195.99。APP 在图像处理和视频生成方面做得很出色。
一站式有声内容创作平台,助力高效创作有声书。
万象有声是一个专为有声创作者打造的智能内容创作平台。它通过集成创新技术和行业经验,提供全流程的创作工具,降低创作成本,提高效率,适合有声书创作者及各类内容创作者。该平台提供的功能使得创作者能够轻松地完成从剧本编辑到成品发布的整个过程,是市场上领先的创作工具。
提供AI和机器学习课程
Udacity人工智能学院提供包括深度学习、计算机视觉、自然语言处理和AI产品管理在内的AI培训和机器学习课程。这些课程旨在帮助学生掌握人工智能领域的最新技术,为未来的职业生涯打下坚实的基础。
探索人工智能的无限可能
无限人工智能致力于构建生成式视频模型,专注于人类。我们相信人是故事的中心,而故事是人类处理、学习和进化的方式。我们预测未来 10 年内,一支由 3 名作家组成的团队,无需演员、导演或其他工作人员,将赢得奥斯卡奖。我们正在开发他们将使用的工具。欢迎加入我们的探索之旅。
智能播客生成平台,一键生成音频内容
PodCastLM是一个创新的智能播客生成平台,它利用先进的人工智能技术,让用户能够快速生成个性化的音频内容。用户只需上传PDF文件,选择问题、语气、时长和语言等参数,即可生成一段高质量的音频播客。该产品背景信息强调了在快节奏的生活中,人们对于快速获取信息和娱乐内容的需求,PodCastLM通过简化音频内容的制作过程,让用户能够轻松创建和分享自己的播客。目前,PodCastLM提供免费试用,用户可以体验其强大的功能和便捷的操作。
音频处理和生成的深度学习库
AudioCraft 是一个用于音频处理和生成的 PyTorch 库。它包含了两个最先进的人工智能生成模型:AudioGen 和 MusicGen,可以生成高质量的音频。AudioCraft 还提供了 EnCodec 音频压缩 / 分词器和 Multi Band Diffusion 解码器等功能。该库适用于音频生成的深度学习研究。
绘图,问答,图片处理一站式 AI 服务
小门道 AI 是一个提供 AI 服务的网站,包括 Midjourney 和 Stable Diffusion 绘图,chatgpt 对话,抠图,去除水印,魔法抹除,图片变清,无损放大等功能。我们提供智能问答功能,可联网搜索,任务式 (基于 AutoGPT),学术助理,上传文件,数学解题等。同时,我们还提供抠图、放大变清、转矢量图、人脸融合等图片处理功能。产品定价根据具体功能和使用情况而定,定位于提供高质量的 AI 服务。
快速、准确、免费的音频转文字服务
AIbase音频提取文字工具利用人工智能技术,通过机器学习模型快速生成高质量的音频文本描述,优化文本排版,提升可读性,同时完全免费使用,无需安装、下载或付款,为创意人员提供便捷的基础服务。
全球最大的音频库,提供有声书、播客等丰富音频资源。
Azalea Labs是一个音频资源平台,作为全球最大的音频库,它拥有海量的有声书、播客等资源。其重要性在于为用户提供了便捷获取各类音频内容的途径,满足了不同用户的音频需求。主要优点包括资源丰富、可免费试用一段时间。产品定位是打造一个集多种音频内容于一体的平台,让用户能够轻松享受音频带来的乐趣。目前未提及价格相关信息,推测可免费试用。
高效并行音频生成技术
SoundStorm是由Google Research开发的一种音频生成技术,它通过并行生成音频令牌来大幅减少音频合成的时间。这项技术能够生成高质量、与语音和声学条件一致性高的音频,并且可以与文本到语义模型结合,控制说话内容、说话者声音和说话轮次,实现长文本的语音合成和自然对话的生成。SoundStorm的重要性在于它解决了传统自回归音频生成模型在处理长序列时推理速度慢的问题,提高了音频生成的效率和质量。
视频到音频生成模型
vta-ldm是一个专注于视频到音频生成的深度学习模型,能够根据视频内容生成语义和时间上与视频输入对齐的音频内容。它代表了视频生成领域的一个新突破,特别是在文本到视频生成技术取得显著进展之后。该模型由腾讯AI实验室的Manjie Xu等人开发,具有生成与视频内容高度一致的音频的能力,对于视频制作、音频后期处理等领域具有重要的应用价值。
将任何文本转换为有声读物质量的声音。
AudiowaveAI是一款利用人工智能技术将文本转换成高质量音频的应用程序。它与传统的文本到语音技术不同,提供了更加自然、富有情感的语音输出,让听众在学习和享受内容时获得更好的听觉体验。产品背景信息包括它是由全球创新公司和自由职业者信赖的产品,其主要优点在于其引人入胜的声音、自然的声音效果以及令人愉悦的听觉享受。产品定位为教育工具,旨在帮助用户在移动中学习,享受夏日阳光。
用人工智能生成图标
IconizeAI 是一个创意工具包,通过人工智能生成图标,简化设计流程,节省时间和精力。无论您是设计师、开发者还是企业所有者,IconizeAI 都可以帮助您即刻将创意想法变成现实。",
高效的文本到音频生成模型
TangoFlux是一个高效的文本到音频(TTA)生成模型,拥有515M参数,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频。该模型通过提出CLAP-Ranked Preference Optimization (CRPO)框架,解决了TTA模型对齐的挑战,通过迭代生成和优化偏好数据来增强TTA对齐。TangoFlux在客观和主观基准测试中均实现了最先进的性能,并且所有代码和模型均开源,以支持TTA生成的进一步研究。

© 2026 AIbase 备案号:闽ICP备08105208号-14