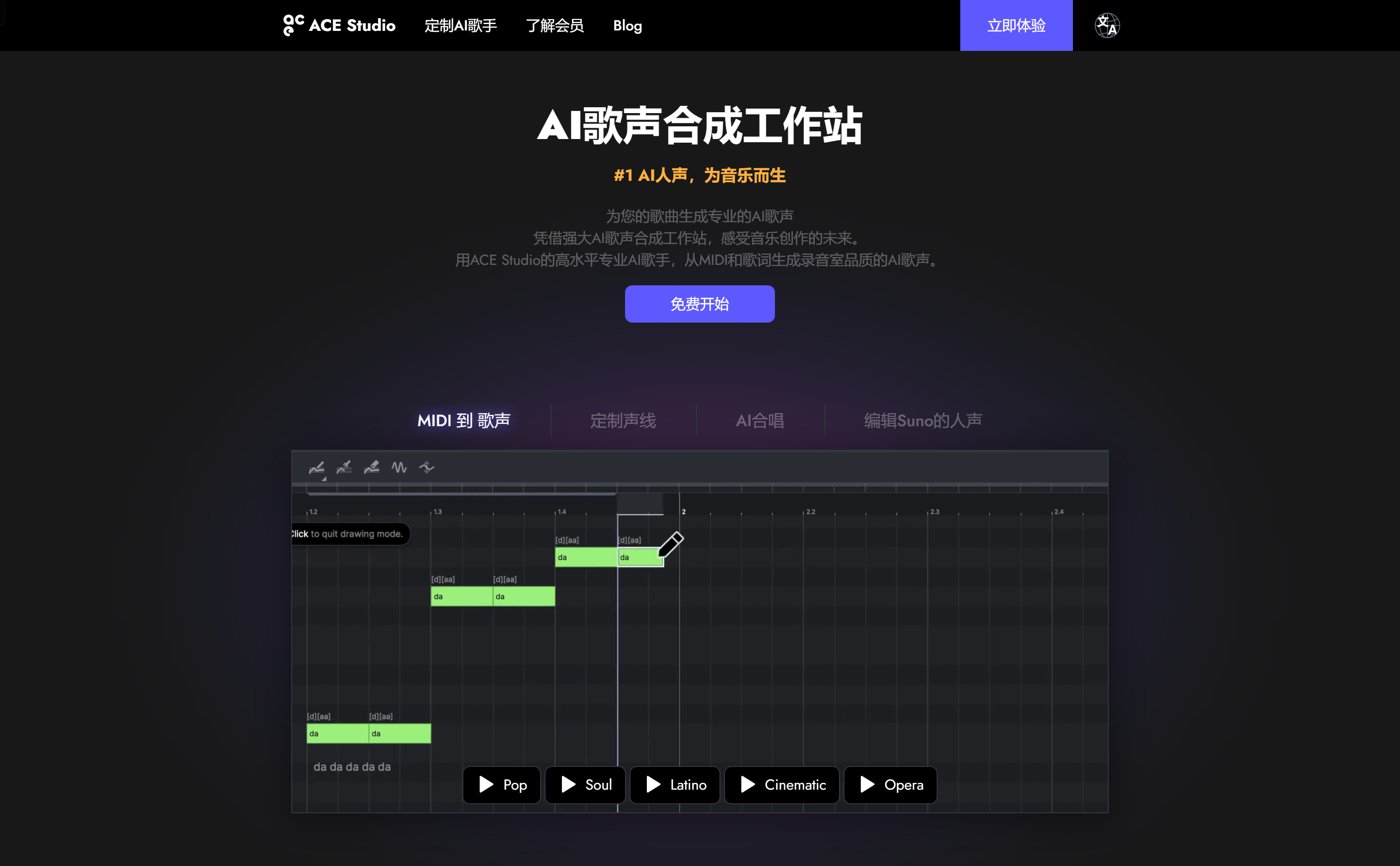
ACE Studio是一个专业的AI歌声合成工作站,它通过强大的人工智能技术,使用户能够从MIDI和歌词生成录音室品质的AI歌声。产品支持多种语言的歌声合成,包括英语、西班牙语、中文和日语,覆盖多种音乐风格,如流行、灵魂、拉丁等。ACE Studio的主要优点在于其高度的可编辑性,用户不仅可以更换歌曲中的声音,还可以编辑旋律、歌词,甚至是音乐风格,创造出独特的演唱效果。此外,ACE Studio还提供了AI驱动的音轨分离器以及人声转MIDI功能,使任何歌曲的人声变得可编辑。产品背景信息显示,ACE Studio旨在为音乐制作人和作曲家提供升级音乐制作流程的工具,它不仅是一个AI歌声合成器,还是一个音乐创作和编辑的平台。关于价格,ACE Studio提供免费试用,用户可以免费开始体验,但具体的定价细节未在页面中明确说明。
需求人群:
"目标受众为音乐制作人、作曲家、独立音乐人以及音乐爱好者。ACE Studio适合他们,因为它提供了一个无需真人歌手即可创作和编辑高质量歌声的平台,大大节省了音乐制作的时间成本和经济成本,同时为音乐创作提供了更多的可能性和创意空间。"
使用场景示例:
音乐制作人使用ACE Studio将MIDI文件转换成具有专业品质的歌声,用于新专辑的制作。
独立音乐人通过定制AI声线,创作出具有个人特色的歌声,用于个人音乐作品的发布。
音乐爱好者利用ACE Studio的AI素材社区,发现并使用他人分享的歌声片段,制作自己的音乐混音作品。
产品特色:
- MIDI到歌声:将MIDI文件和歌词转换成AI合成的歌声。
- 定制声线:用户可以根据需要定制独特的AI声线。
- AI合唱:实现AI合唱效果,丰富音乐层次感。
- 编辑Suno的人声:对AI生成的歌声进行编辑,以达到理想的效果。
- 多语言支持:支持英语、西班牙语、中文和日语等多种语言的歌声合成。
- 多风格演唱:提供流行、灵魂、拉丁等多种演唱风格。
- AI素材社区:用户可以分享和发现AI歌手、歌声片段和歌曲模板。
- AI音乐工具:提供分离人声、歌声转MIDI等音乐编辑工具。
- 声线编辑:通过混合不同的“声音种子”创造新的AI声线。
- 进阶版AI歌声编辑:编辑发音、音高、颤音等,控制演唱表现。
使用教程:
1. 访问ACE Studio官网并注册账号。
2. 登录后,选择‘立即体验’开始使用。
3. 上传MIDI文件和歌词,选择相应的AI歌手和风格。
4. 利用ACE Studio的AI歌声合成技术,生成歌声。
5. 通过编辑工具调整歌声的音高、情感等细节。
6. 使用AI素材社区分享或发现新的AI歌手和歌声片段。
7. 如果需要,可以利用AI音乐工具进行更深入的音乐编辑。
8. 完成编辑后,导出最终的音乐作品。
浏览量:172
最新流量情况
月访问量
508.16k
平均访问时长
00:01:17
每次访问页数
2.57
跳出率
44.30%
流量来源
直接访问
39.08%
自然搜索
43.26%
邮件
0.07%
外链引荐
5.91%
社交媒体
10.85%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
西班牙
4.83%
法国
4.59%
英国
6.70%
日本
10.47%
美国
22.27%
AI歌声合成工作站,为音乐创作而生。
ACE Studio是一个专业的AI歌声合成工作站,它通过强大的人工智能技术,使用户能够从MIDI和歌词生成录音室品质的AI歌声。产品支持多种语言的歌声合成,包括英语、西班牙语、中文和日语,覆盖多种音乐风格,如流行、灵魂、拉丁等。ACE Studio的主要优点在于其高度的可编辑性,用户不仅可以更换歌曲中的声音,还可以编辑旋律、歌词,甚至是音乐风格,创造出独特的演唱效果。此外,ACE Studio还提供了AI驱动的音轨分离器以及人声转MIDI功能,使任何歌曲的人声变得可编辑。产品背景信息显示,ACE Studio旨在为音乐制作人和作曲家提供升级音乐制作流程的工具,它不仅是一个AI歌声合成器,还是一个音乐创作和编辑的平台。关于价格,ACE Studio提供免费试用,用户可以免费开始体验,但具体的定价细节未在页面中明确说明。
VOCALOID6 是最新的歌声合成软件。
VOCALOID6 是由雅马哈公司开发的歌声合成软件,通过先进的 AI 技术,能实现更加自然的歌声表达。该软件适用于各类音乐创作,支持多种语言,用户可以利用它轻松制作和编辑音乐作品。VOCALOID6 支持 VST/AU/ARA2 格式,价格适中,是音乐创作者的重要工具。
一键创作你的AI音乐
海绵音乐是一个在线音乐创作平台,利用人工智能技术帮助用户快速创作个性化的音乐作品。它通过提供各种风格和情感的音乐模板,简化了音乐创作的复杂性,让没有专业音乐背景的用户也能轻松创作出属于自己的音乐。产品的主要优点包括易用性、多样性和创新性,背景信息显示它支持多种音乐风格,如R&B、国风、EMO等,适合不同用户的需求。目前产品提供免费试用,具体价格和定位信息未在页面中明确。
改变音乐创作未来
Lyria音乐生成器是一款最先进的 AI 音乐生成模型,可帮助音乐家和创作者创作出令人难以置信的音乐作品。它通过生成高质量的音乐,包括乐器和人声,执行转换和延续任务,并提供更精细的风格和表演控制。除此之外,还有两个 AI 实验项目:Dream Track 和 Music AI 工具,旨在为创造力开辟新的领域。
打造你的音乐创作利器
OmMuse是一款专为音乐创作而设计的在线平台,提供丰富的音乐创作工具和资源,帮助用户轻松制作音乐作品。通过OmMuse,用户可以编辑和混合音频,添加各种音效和乐器,创建个性化的音乐作品。OmMuse还提供音乐素材库、合作交流平台和教程资源,让音乐创作者可以更加方便地学习、合作和分享。定价灵活,适合个人用户和团队使用。
AI音乐创作平台
Cassette AI是首个利用人工智能将文本转化为精细音乐创作的平台。我们使用基于潜在扩散模型(LDMs)的尖端人工智能技术,使音乐制作、定制和聆听对每个人都可用。现在,创作音乐就像写一个提示一样简单。
AI音乐创作,智能音乐生成平台
YourMusic是一个基于SUNO AI 3.5模型的人工智能技术音乐生成平台,它利用深度学习算法分析音乐数据和风格,融合音符、和弦和节奏,为音乐创作者、爱好者以及寻求独特音乐体验的用户提供个性化的音乐作品。
让您的音乐创作更快更轻松
Delphos是一款极致的音乐生成软件,可以帮助您轻松生成专业音乐轨道。它具有生成旋律和鼓声的能力,并可以生成高达100个音轨。您可以使用Delphos的试用设计器,或者选择付费使用完整生成器。Delphos还提供Soundworld Builder计划,允许您构建自己的声音世界,进行无限次的训练和生成,以及进行分发和盈利。
AI音乐创作工作室,秒速生成专业、免版税的各类型音乐轨道。
Sonura是一款AI音乐生成器,能够根据文本描述快速生成高质量的节拍、循环和完整曲目。它的重要性在于极大地降低了音乐创作的门槛,使初学者和专业人士都能快速实现音乐创作的想法。主要优点包括生成速度快(平均不到10秒)、质量高(工作室级输出)、灵活性强(支持几乎所有音乐流派),并且用户拥有完全的商业版权。该产品免费提供创作信用额度,无需信用卡即可试用,之后可选择付费计划。其定位是面向各类音乐创作者,无论是新手还是专业制作人,都能通过简单的文本描述实现音乐创作。
专为音乐家设计的会话录音应用程序,可将录音整理到文件夹中,自动拆分为部分,并使用表情符号或注释标记关键时刻。
Dubnote是一款专为音乐家设计的会话录音应用程序,帮助他们捕捉和整理音乐创意。用户可以将录音整理到文件夹中,自动拆分为部分,并使用表情符号或注释标记关键时刻。这款应用的主要优点在于帮助音乐家更好地管理和保存创意灵感。
AI辅助的音乐创作伙伴
Fryderyk是一个集成了AI助手的音乐制作网页应用程序,它提供了一个浏览器内的音乐创作环境,支持即插即用,连接麦克风或任何MIDI乐器。用户可以访问广泛的虚拟乐器库,应用混响、失真、延迟等效果和混合工具,进行音频编辑、录制和编辑音频。Fryderyk还提供云存储功能,项目自动保存并同步至所有设备。它的内置生成性AI能够扩展用户的想法或在用户遇到创作瓶颈时提供新的想法。
AI音乐创作,一键生成个性化音乐。
AI Music FM 的 AI Music Generator是一个利用人工智能技术的音乐创作工具,它能够根据用户输入的文本、图像或歌词,生成不同风格和情感的音乐作品。该产品通过深度学习技术,从大量音乐作品中学习并融合创新,生成独特且无版权风险的音乐。它不仅为专业音乐制作人提供灵感,也降低了音乐创作的门槛,让更多音乐爱好者能够轻松参与到音乐创作中来。
全档位AI吉他,让音乐创作更自由。
ENSTANT 智云即弹是一款结合人工智能技术的吉他学习与创作应用,它通过模拟真实吉他的演奏体验,为用户提供了一种全新的音乐创作和学习方式。该产品利用先进的AI算法,能够即时生成和弦和旋律,帮助用户快速掌握吉他演奏技巧,激发音乐创作灵感。智云即弹以其创新性、易用性和强大的功能,为吉他爱好者和音乐创作者提供了一个便捷的音乐创作平台。
AI 为音乐创作者打造的工具
Co-Producer 是我们正在构建的一套 AI 功能,旨在帮助音乐创作者节省更多创作时间,减少搜索时间,首先推出的是 Pack Generator。Pack Generator 是一个强大的样本包生成器,通过文本描述即可创建独特的免版税样本包。用户可以选择不同的情绪、乐器、流派或参考艺术家,即可获得即时灵感。通过生成的样本包,用户可以快速将想法变为现实,并在任何数字音频工作站中进行创作。
让每个人都能享受音乐创作的快乐
Splash是一款AI音乐平台,通过自主研发的AI技术,可以演唱、说唱、演奏乐器、作曲和制作原创音乐。我们的目标是使音乐创作变得比以往任何时候都更加易于接触。Splash Pro的音乐创作属于您,您可以随心所欲地使用、分享和发表作品。
音乐创作与分享平台
MashApp Music是一个音乐应用,用户可以在此平台上轻松创作和分享音乐混音。它允许用户选择不同的歌曲部分进行混搭,创造出全新的音乐作品。该应用利用人工智能技术,推荐可能搭配良好的歌曲,使音乐创作变得更加简单有趣。MashApp Music旨在让非音乐专业人士也能享受到音乐创作的乐趣,并通过分享作品与朋友互动,增强音乐社交体验。
个性化音乐创作平台
Suno是一个音乐创作平台,通过其最新功能Personas,用户可以捕捉并保存任何曲目的独特氛围,赋予其生命。Personas允许用户保存歌曲的本质——其人声、风格和氛围,并在新的创作中重新想象它。这就像是给曲目一个独特的身份,随时准备激发你的创造力。Personas让用户以音乐的本质为基础,创造新的音乐声音,这些声音承载着他们最喜欢的曲目的灵魂。通过公开Personas,不仅是关于你的音乐——它是一个邀请他人加入和协作的邀请。
AI音乐创作与探索应用
Suno是一款AI音乐和歌曲生成器,面向所有音乐爱好者,无论是否具备乐器演奏能力,都能通过想象力创作音乐。它提供基础计划每天50个免费积分,以及多种订阅选项,以支持更深入的音乐创作。
利用尖端AI技术,快速生成任何流派的原创音乐。
AI音乐生成器是一个基于人工智能的在线平台,能够快速生成原创音乐。它利用复杂的机器学习模型和神经网络技术,分析数百万首歌曲的模式和结构,生成高质量的旋律、和声和人声。该产品的主要优点是能够快速实现音乐创作,支持多种流派和风格的定制,并提供灵活的生成选项。它适合音乐创作者、内容制作者和企业用户,能够帮助他们节省创作时间,激发灵感,并生成符合特定需求的音乐。产品提供免费试用和多种付费计划,满足不同用户的需求。
AI音乐创作助手
Lemonaid Music是一款AI音乐创作助手,通过智能算法和机器学习技术,帮助音乐人快速创作出优秀的音乐作品。它提供丰富的音乐素材库和自动生成曲谱、编曲、和声等功能,让用户能够轻松创作出专业水准的音乐作品。Lemonaid Music还提供定制化的音乐风格推荐和智能音乐排行榜,帮助用户发现热门音乐和创作灵感。定价灵活合理,适用于音乐人、制作人、创作爱好者等各类用户。
音乐创作平台,将文字转化为个性化音乐作品。
音疯是一个创新的音乐创作平台,它利用先进的AI技术,将用户的歌词和旋律动机转化为完整的音乐作品。用户可以通过简单的界面输入歌词,选择音乐风格,平台将自动生成具有个性化的音乐。音疯不仅为音乐爱好者提供了一个展示创意的舞台,也为专业音乐制作人提供了便捷的创作工具。该平台以其用户友好的界面和强大的创作功能,满足了不同层次用户的音乐创作需求。
生成个性化、原创、免版税音乐的AI音乐创作软件
AIbstract是一款基于人工智能技术的音乐创作软件,可以为个人和专业人士提供虚拟作曲家和演奏家的服务。无需音乐技能,用户可以生成和实时播放个性化、原创、免版税的音乐。AIbstract集成了许多互补功能,以满足各种音乐需求和用例。用户可以通过AIbstract表达音乐需求,软件可以完成从音乐想法到音乐作品实时播放的所有步骤。AIbstract在云计算中运行,可以在任何设备上使用,甚至在性能不强的设备上也可以使用。AIbstract的音乐完全属于用户,用户可以自由使用这些音乐,包括分享、公开分发、注册版权管理服务和销售。
AI音乐创作与分享平台
Euphonme是一款AI音乐创作与分享平台,用户可以描述他们想要的音乐,Euphonme将根据描述创作出符合要求的音乐。该产品定位于提供便捷的音乐创作与分享服务,为用户提供全新的音乐体验。Euphonme的定价灵活多样,包括免费的beta版服务。该产品主打智能音乐创作,用户无需具备专业音乐知识,即可轻松创作出个性化音乐。
AI音乐创作助手,无需演唱
SongBot.ai是首个文本转声音的应用程序!无需演唱!SongBot.ai利用人工智能的力量生成精彩的歌词和震撼的人声!创建歌词,选择其中一个AI歌手、音乐曲目和自定义视频,然后创建一部史诗般的原创音乐视频!
AI创作音乐与语音
Suno AI是一款通过人工智能创作音乐和语音的产品。它利用先进的算法和数据模型,能够生成高质量的音乐和语音作品。Suno AI具有以下功能和优势:1. 创作多种风格的音乐,包括流行、古典、电子等;2. 生成自然流畅的语音,可用于语音合成、配音等场景;3. 提供丰富的音乐和语音效果,可根据用户需求进行定制;4. 界面简洁友好,操作简单易上手;5. 支持多种输出格式,方便用户在不同平台上使用。Suno AI的定价根据用户的使用情况而定,详情请访问官方网站。

© 2026 AIbase 备案号:闽ICP备08105208号-14