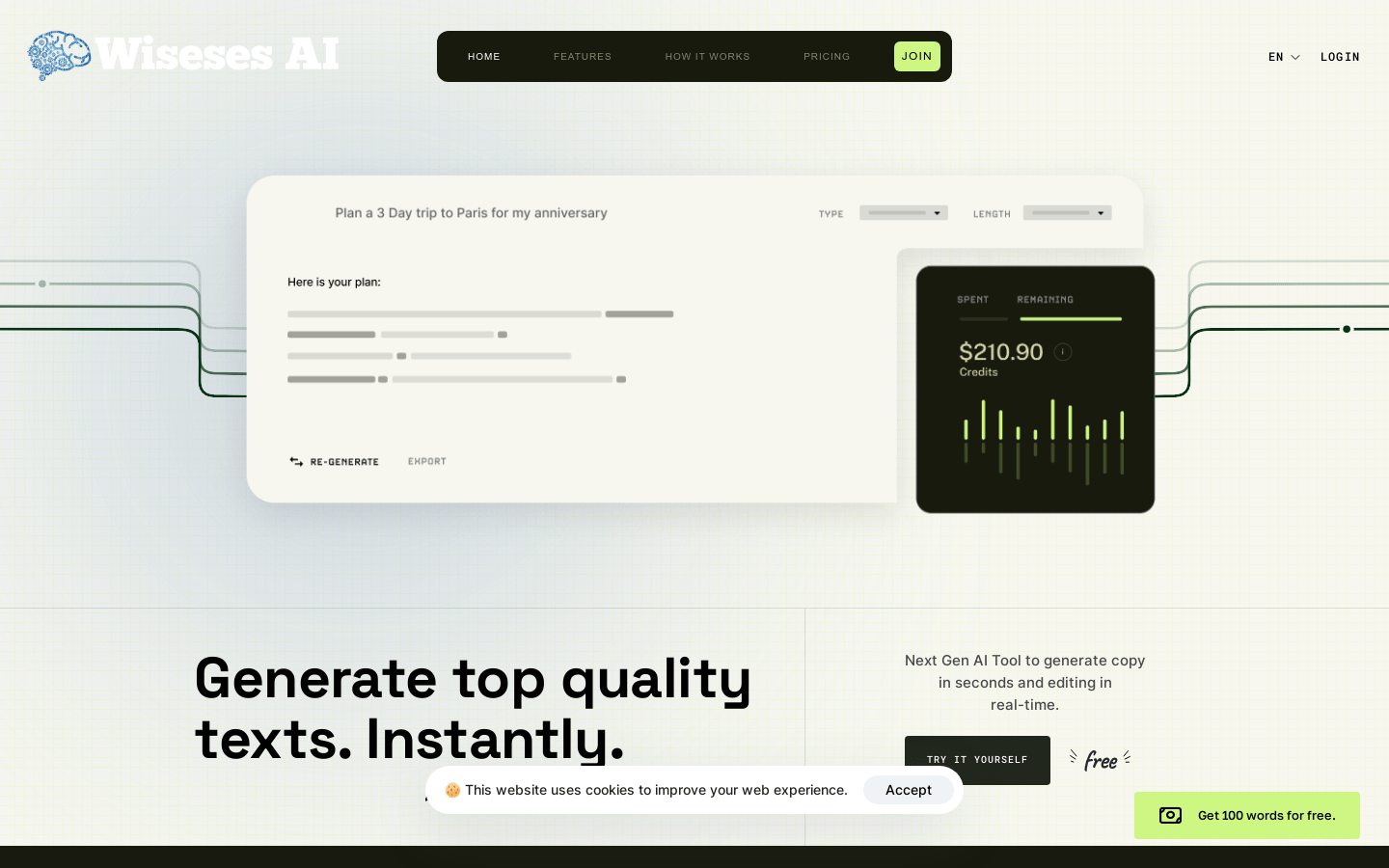
Wiseses AI是一款智能内容创作平台,提供智能写作、智能编辑等功能。它能够帮助用户高效地生成优质的文章、博客、广告文案等内容,大大提升写作效率。Wiseses AI拥有强大的语言模型和自然语言处理技术,能够根据用户的需求自动生成与之匹配的内容。用户可以根据自己的需要定制内容的风格、主题和长度,并进行实时编辑和修改。Wiseses AI还提供多种语言和领域的内容创作模板,方便用户快速生成专业的文案。平台定价灵活,用户可以根据自己的使用情况选择不同的套餐。Wiseses AI适用于个人写作、企业广告文案、新闻报道、博客撰写等各种场景。
需求人群:
适用于个人写作、企业广告文案、新闻报道、博客撰写等各种场景。
使用场景示例:
生成专业的广告文案
快速撰写博客文章
优化新闻报道的文案
产品特色:
智能写作
智能编辑
内容定制
实时编辑和修改
多语言支持
内容创作模板
灵活定价
浏览量:76
快速生成短视频文案,提升内容创作效率。
AIbase短视频文案提取生成器是一款利用先进的AI算法快速生成短视频内容文案的工具。它通过精准的文本提取技术,帮助用户在短时间内获取视频的文案内容,优化文案排版,并保证文案的可读性和准确性。该工具完全免费使用,无需任何安装、下载或付款,是内容创作者的得力助手。
内容和营销文案创作效率10倍提升
AI写作引擎是一款专注于内容和营销文案创作的智能工具,比GPT更智能,能够提升创作效率十倍。该引擎涵盖多个领域,包括新闻稿、文章、故事小说、论文大纲、总结报告等。通过AI写作引擎,用户可以轻松生成各种类型的文案,满足不同写作需求。
高效人工智能写作,快速生成工作报告、新媒体文案、特定主题文章
迅捷AI写作是一款AI智能写作工具,支持AI全文写作,根据指定关键词主题,快速生成文章内容,可覆盖文案、报告、干货写作等多种实际场景。软件还提供AI聊天对话、AI画作等功能,可以高效答疑解惑,也能辅助创作,用AI为用户的工作和生活赋能。迅捷AI写作内置了丰富的翻译、文件转换和压缩等功能,可用于满足用户日常办公需求。界面简单易用,操作和交互经过简化设计,用户可根据指引快速上手。迅捷AI写作提供「我的文件」功能,可清晰展现文件操作、处理记录,高效管理文件。免费试用,免费体验软件内功能。在线客服24小时解答,无病毒、无广告、无风险,简洁的UI界面与操作流程。
AI驱动,帮助写作和内容创作
小鱼AI写作是一个AI驱动的写作辅助平台,提供3958个精品AI写作模板,满足不同场景的使用需求。该平台特别适合0基础用户,可以在1分钟内轻松完成写作任务,激发写作灵感,帮助用户更好地表达思想。功能包括AI文章创作、AI续写、文章润色等。
SEO 友好的 AI 写作生成器
智能写作助手利用人工智能来辅助进行 SEO 写作。我们的 AI 文章生成器可以生成博客大纲 / 博客标题 / 博客引言 / 博客创意,扩展文章大纲,修改语言,改写或总结文本,生成摘要,增强句子结构等功能。我们的 AI 写作生成器简单易用,可定制化,生成高质量内容,价格实惠。
智能内容创作平台
Wiseses AI是一款智能内容创作平台,提供智能写作、智能编辑等功能。它能够帮助用户高效地生成优质的文章、博客、广告文案等内容,大大提升写作效率。Wiseses AI拥有强大的语言模型和自然语言处理技术,能够根据用户的需求自动生成与之匹配的内容。用户可以根据自己的需要定制内容的风格、主题和长度,并进行实时编辑和修改。Wiseses AI还提供多种语言和领域的内容创作模板,方便用户快速生成专业的文案。平台定价灵活,用户可以根据自己的使用情况选择不同的套餐。Wiseses AI适用于个人写作、企业广告文案、新闻报道、博客撰写等各种场景。
一站式智能创作平台
创作王是一个全能型智能创作平台,可以智能回答、智能创作、智能编写、智能翻译、智能写代码等,帮助您解决各种创作难题。我们提供小红书创作、今日头条创作、知乎问答创作、微博创作、公众号创作等多种场景下不同风格的文章创作,以及视频口播稿、SWOT 分析法、英文写作、节日祝福、夸夸神器、塔罗牌预测、解梦神器等多种创作工具。
智能写作AI,提升内容创作效率
SmartWriteAI是一款基于AI技术的内容创作工具,提供写作辅助、图片生成、语音转文字和聊天机器人等功能。通过智能、易用的界面和模板选项,帮助企业快速生产高质量内容。定价灵活,适用于各类写作项目。
AI创作助手,智能写作的未来
AI Majickey是一款智能写作助手,可以为博客、文章、网站、社交媒体等创作内容。它采用最新的AI技术,支持超过25种语言,提供编辑AI文本的便捷功能。用户可以将生成的文本结果导出为PDF和Word文件。同时,AI Majickey还可以通过输入文本生成AI图片。它的定价及其他详细信息请访问官方网站。
一键生成创作文案
极简智能王是一款智能创作工具,可以帮助用户快速生成各类文案,包括新媒体运营、职场效率提升、创意功能写作等。它提供了丰富的模板和功能,用户可以根据自己的需要选择合适的模板,进行创作。极简智能王具有简单易用、高效快捷的特点,可以极大地提升用户的创作效率。
一款功能全面的 AI 智能写作工具。
蛙蛙写作是一款集创意灵感获取、小说改编、视频生成等多种功能于一体的智能写作助手。它帮助用户高效创作,适用于学术、职场及个人项目。产品背景强大,定位于提升写作效率,适合各类创作者。
CueMe,你的智能写作助手,让创作变得轻松有趣。
CueMe是一个智能写作平台,它利用先进的人工智能技术,为用户提供高效、个性化的写作服务。CueMe能够根据用户的需求,创作出各种体裁的文章,包括但不限于论文、报告、博客、故事等。它不仅能够模仿用户的写作风格,还能提供校对和润色服务,帮助用户提升写作质量。CueMe的目标是成为用户在学习和工作中的得力助手,无论是学术写作、商业文案还是日常随笔,CueMe都能提供专业的支持。
AI 助手,提供智能写作和内容生成服务
Mind Meld Canvas AI 是一款 AI 助手,旨在提供智能写作和内容生成服务。它可以根据用户的需求快速生成准确的内容,并提供事实核查和协作功能。使用 Mind Meld Canvas AI,用户可以节省时间,专注于自己的创作和学术研究。它提供多种模板和功能,包括生成文章、AI 图像、AI 代码、语音转文字等。Mind Meld Canvas AI 适用于个人创作者、学术研究者和商业用户。根据用户的需求和使用频率,提供不同的订阅套餐。
Arvin - 智能写作助手,AI内容生成器
Arvin是一款智能写作助手和AI内容生成器,可以帮助您提升写作水平。它提供多种功能,包括生成吸引人的营销邮件、引人入胜的博客文章、有效的产品列表和专业的求职材料等。Arvin还提供了丰富的写作场景,可以根据您的需求快速生成优质的文案。无论您是营销人员、博主、商家还是求职者,Arvin都能帮助您在写作中取得更好的效果。定价灵活合理,适合个人和企业用户。
AI写作助手,智能创作文案
AutoMagic AI是一个强大且快速的写作工具,通过AI驱动的写作和图像生成,轻松转录音频为文本,帮助用户创建令人惊叹的内容。它适用于作家、博主、市场营销人员、企业家和商业专业人士,提高工作效率,节省时间,同时不降低质量。
由人工智能强力驱动,为职场人打造千人千面创意写作工作流
多墨智能写作是一款由人工智能强力驱动的创意写作工具,帮助职场人提高工作交付效率。它独家支持根据不同岗位通过算法一键生成工作文档,适合各种职业需求,包括产品经理、抖音运营专员、战略咨询专家、老师、医生、公职人员、旅游导游、公关等。多墨智能写作提供一键成文、辅助撰写、命令自定义和私有化部署等功能,可定制解决方案并保护内部数据隐私。
提升你的文案内容创作
copyPenAi是一款利用先进的人工智能技术,轻松突破创作障碍的工具。它能够生成与你品牌声音完全一致的引人入胜的内容创意,确保在每个平台上都呈现出真实的存在感。你可以根据需要精确定制与你的受众共鸣的内容,调整语调、风格和信息,无论是博客还是社交媒体等,都能轻松胜任。copyPenAi提供了一套全面的工具,适用于各种平台,从而为你的内容策略释放强大的力量。
智能写作助手
DeepType是一款智能写作助手,通过AI技术为你提供相关信息,并帮助你改善写作流程。它能够从你输入的文字中获取关键信息,丰富你的内容,提供新的创意,同时还能在你的文本编辑器中进行在线搜索。使用DeepType,你可以更快地写作,获得灵感,提升写作效果。
人工智能写作、创意助手
Solan AI是一个人工智能写作和创意助手产品。它可以为用户自动生成各种创意文案,包括标题、简介、文章、广告语等,大大提升写作效率。它具有自定义语言模型、支持多种创作场景、实时交互式写作等功能。Solan AI通过人工智能算法学习用户风格,输出个性化高质量内容。它可以让任何人快速进行高效的创意写作。
智能写作助手
WriteBot AI是一款智能写作助手工具,可以帮助用户生成博客内容、电子邮件模板、社交媒体内容、视频脚本、网站内容等。它基于人工智能技术,能够自动生成高质量的文案,并提供丰富的模板和功能点供用户使用。WriteBot AI能大大提高写作效率,节省时间和精力,适用于个人博主、企业营销人员、内容创作者等。定价灵活,提供多种订阅套餐和按需购买选项。
智能写作助手
Originality AI是一款智能写作助手,帮助用户提升写作效率和质量。它通过自然语言处理和机器学习技术,提供实时的字数和字符统计,帮助用户控制文章长度;还能自动检测文本中的重复内容和抄袭问题,保证内容的原创性;同时,它还提供了丰富的写作模板和提示,帮助用户更好地组织思路和提升文章质量。Originality AI定价灵活,用户可以选择免费试用或购买高级会员享受更多功能和服务。
人工智能写作助手,高质量内容创作
Cluc.io是一款人工智能写作助手,能够帮助用户快速创建高质量的内容。它提供了简单易用的平台,让您轻松地定制人工智能内容。Cluc.io能够生成定制化的AI内容,助您提升写作效率。它可以应用于各种场景,帮助用户在短时间内创作出优质的文章、SEO描述等。Cluc.io的定价合理,性价比高。它是一款专注于提高内容创作效率的工具。
AI智能生成写作大纲,快速为您生成论文大纲
轻创AI写作系统是一款AI智能生成写作大纲的在线平台。它可以根据用户输入的论文关键词,快速生成包括标题、章节等在内的完整论文大纲。该系统具有操作简单、智能生成、节省时间等优势,适用于期刊论文、科普文章、毕业论文、商业报告等多种写作场景,可以高效辅助用户进行学术和商业写作。
人工智能写作助手,生成高质量内容
Aquila是一款先进的AI写作助手,能够为您生成高质量的内容。它基于预训练的深度学习模型,进行人类般的预测。Aquila支持生成转化驱动的销售文案、博客文章、通讯邮件和短信等多种内容形式。无论是语言还是情感,Aquila都能生成与人类写作几乎无异的内容。
Ai写作助手,支持论文、文案、策划等文字创作
面向专业写作领域的多场景AI写作工具,能免费生成AI文案,操作简单,无任何使用门槛。写作场景包括论文大纲、公文写作、商业计划书、自媒体创作、营销内容和生活娱乐内容等。除了一键生成文案,它还支持智能续写、改写文稿,只需上传文档或输入内容。你还可使用免费AI对话、专家对话等功能进行答疑解惑、趣味聊天。
解锁AI潜力,智能写作,快十倍!尝试Jaeves吧!
Jaeves AI是一款强大的智能写作工具,能够帮助用户以更高效的方式生成最佳优化内容。它具有优秀的生成能力,通过智能算法和语言模型,能够在记录时间内生成最佳优化内容。Jaeves AI还提供丰富的功能和优势,价格合理,适用于各种写作场景。
使用Scalenut AI写作助手,提高写作效率,生成优质内容
Scalenut: AI写作助手是一款强大的AI助手,可在浏览器中生成优秀的、无抄袭的内容。无论是写邮件、社交媒体帖子、回复评论,还是撰写广告文案等,AI Copywriter都能为您提供优质的文案,节省时间并提高效率。

© 2026 AIbase 备案号:闽ICP备08105208号-14