浏览量:147
您的贴身翻译助手,实现高速高精度翻译。
Felo实时翻译是一款应用最新AI技术,提供实时语音翻译服务的应用程序。它通过GPT技术实现高速和高精度的翻译,支持实时转录语音并识别语种,将语音转录为文字并翻译成多种语言,满足国际交流的需求。产品具有朗读支持、语音转录、本地保存和多语言支持等功能,为用户提供了便捷高效的翻译体验。
一款强大的移动端翻译软件,支持多种语言翻译。
疯狂翻译师是一款提供实时翻译服务的移动端软件,支持文字、图片、文档和视频翻译,覆盖200+语种,帮助用户跨越语言障碍,提升翻译效率,适用于国际交流、学习、工作等多种场景。
一款免费的 AI 双语翻译工具,支持多种格式的实时翻译。
Transor 是一款专业的 AI 翻译工具,致力于打破语言障碍,帮助用户实时翻译网页、文档、视频字幕等。凭借其先进的 AI 技术,Transor 提供高精度的翻译服务,适合各种用户群体。注册用户可免费使用,并可在多个平台上使用该工具,包括网页版、插件和移动应用,极大地提升了用户的翻译体验和效率。
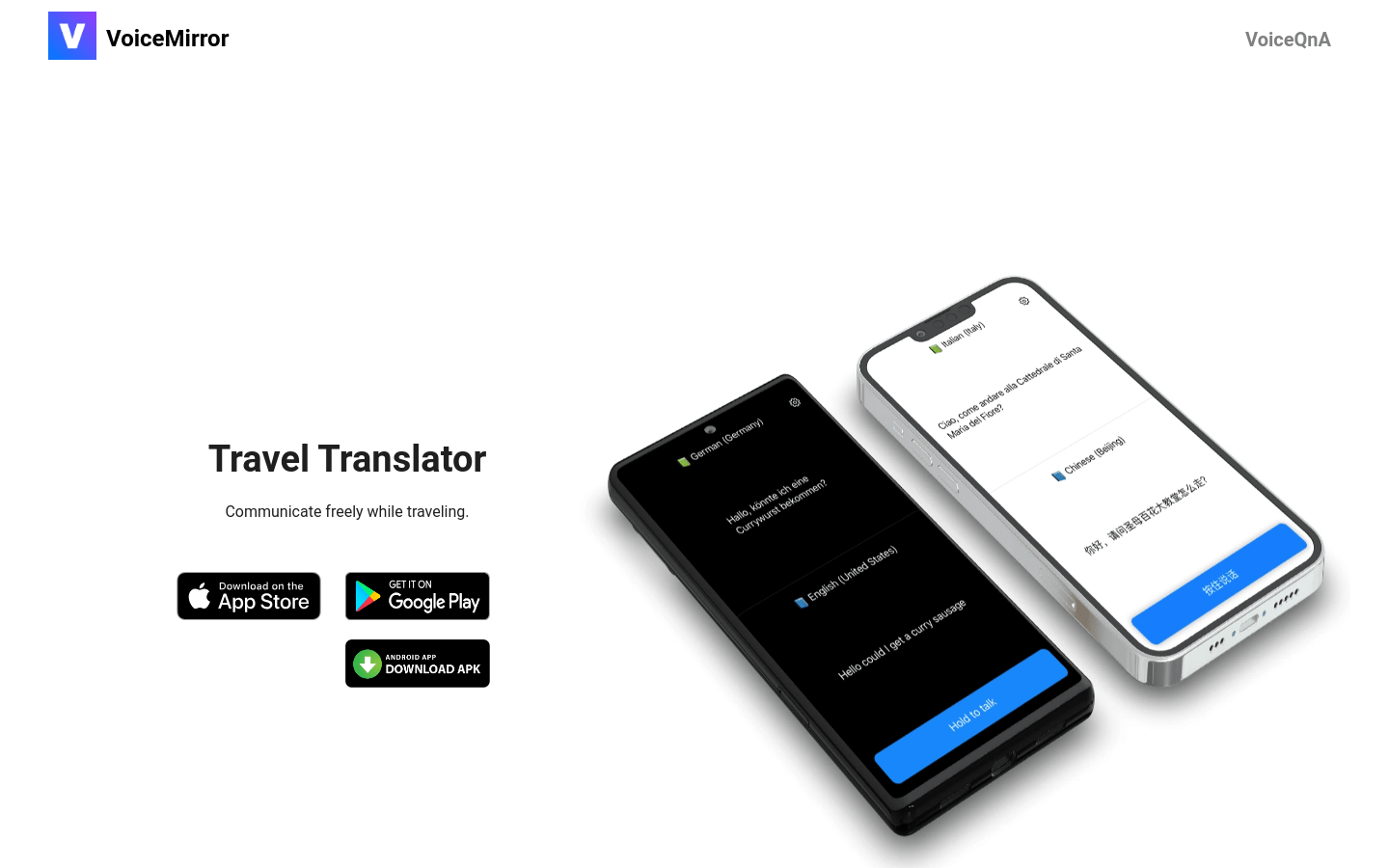
实时语音翻译APP
speakSync是一个基于人工智能的实时语音翻译APP。它能够实现多种语言之间的即时翻译,支持语音转文本和文本转语音,采用了OpenAI的Whisper和GPT模型,实现了流畅准确的翻译效果。该APP专为旅行者、商务人士和语言学习者设计,简化了翻译流程,创建无障碍的跨语言交流环境。
实时语音翻译,打破语言障碍
Interpre-X 是一款实时语音翻译工具,支持10多种语言,帮助用户在任何地方打破语言障碍。通过最先进的人工智能技术,提供语音到语音、语音到文字、文字到语音和文字到文字的翻译服务。无需额外设备,只需良好的网络连接即可使用。Interpre-X 提供高质量的翻译,以自然、人类质量的声音和准确的口音进行播放。适用于社交、旅行、观看电视、学习语言以及与不同语言的朋友交流等场景。现已推出beta版,欢迎试用。
双语对照网页翻译插件
沉浸式翻译是一款浏览器插件,可以智能识别网页主内容区进行双语翻译。支持多种格式的文档翻译、PDF 翻译、EPUB 电子书翻译、字幕翻译等功能。支持多种翻译接口选择,提供最丝滑的翻译体验。
快速准确 稳定可靠的人工智能翻译平台
讯飞智能翻译是一款快速准确、稳定可靠的人工智能翻译平台。支持文档翻译、文本翻译、语音翻译和图片翻译等多种功能。通过23种文档格式的支持,保留原版格式样式和排版,支持文档内图片翻译。覆盖140种语种互译,支持源语言语种自动检测,实现快速翻译。结合讯飞先进的语音识别和翻译技术,满足跨语言的沟通交流。输入图片,即可快速识别图片中的文本内容,进行翻译。提供SaaS、私有化部署和API接口等多种解决方案,满足不同企业的需求。
实时语音翻译,连接全球人们,畅享无障碍沟通。
SpeakShift是一款实时语音翻译产品,通过连接全球人们,打破语言障碍。用户可以在SpeakShift上进行实时语音翻译,实现无缝沟通。SpeakShift的主要功能包括语音识别、翻译、语音合成等。其优势在于高精度的翻译效果和快速的响应速度。SpeakShift提供不同的定价方案供用户选择,并且适用于各种场景,包括旅行、商务、教育等。使用SpeakShift,用户可以轻松地与世界各地的人交流,打破语言壁垒。
实时语音翻译,打破语言沟通障碍。
tuwa.ai 是一款 AI 驱动的实时语音翻译服务,能够实现 100 多种语言之间的无缝沟通。用户可以通过拨打热线电话,与不同语言的通话对象进行对话,而不需要对方下载任何应用。该服务具备超低延迟,保证自然对话体验。提供每月 5 分钟的免费试用,不需要信用卡,适合全球用户。
在线翻译工具
火山翻译是字节跳动旗下的机器翻译品牌,提供在线翻译工具和翻译API。它支持多种语言的翻译,包括通用领域和办公协作等。火山翻译具有智能改写、实用工具多合一、图片翻译、语音同传等功能。用户可以通过网站、小程序和浏览器插件等形态使用火山翻译。
AI翻译,精准匹配译员,母语润色。
有道翻译是网易推出的一款翻译工具,提供文本翻译、文档翻译、AI写作、AI PPT、arXiv论文翻译、网页翻译等多种翻译服务。它通过AI技术,实现快速、准确的翻译,同时支持母语级润色,确保翻译质量。产品背景依托于网易强大的技术实力和丰富的语言资源,旨在为用户提供高效、专业的翻译服务。
多语种文本翻译工具
必应翻译是一款多语种文本翻译工具,可以帮助用户快速准确地翻译各种语言的文本。它具有简单易用、翻译准确、支持多种语言等优势。该产品提供免费和付费版本,付费版本提供更多高级功能。定位于个人用户和商业用户。
实时语音翻译,支持100多种语言的会议、通话和聊天
Byrdhouse提供基于AI的实时语音翻译和字幕翻译,支持100多种语言,可用于你的会议、通话和聊天。Byrdhouse让我们不再为实时翻译操心,让你可以专注于与全球团队和国际合作伙伴的沟通协作。通过Byrdhouse,参会者无需笔记就可以投入到对话中。还可以获得不同语言的会议记录和文字记录。Byrdhouse帮助建立一个包容的文化,让每一个人的声音都能被倾听,无论你说什么语言。
实时语音翻译,跨语言沟通的桥梁。
StreamSpeech是一款基于多任务学习的实时语音到语音翻译模型。它通过统一框架同时学习翻译和同步策略,有效识别流式语音输入中的翻译时机,实现高质量的实时通信体验。该模型在CVSS基准测试中取得了领先的性能,并能提供低延迟的中间结果,如ASR或翻译结果。
AI短视频翻译首发,多国语言精修工具
象寄翻译是一款AI短视频翻译工具,支持中英日韩欧美东南亚等多国语言,提供便捷的图片/短视频精修工具,支持API调用,帮助用户轻松打造精品出海内容素材。产品定价灵活,支持包月模式和张数套餐,定位于提供高效精准的翻译服务。
免费中文在线Google翻译和GPT翻译工具
AI谷歌翻译是一个提供在线翻译服务的网站,支持中文、英文、日语等多种语言的互译。它采用了先进的翻译模型,如Gemini 1.5和GPT 4.0,能够根据用户选择的领域进行专业翻译,确保翻译的准确性和专业性。该产品背景信息显示,它提供免费的翻译服务,对于200字以内的翻译不收费,适合需要快速、准确翻译的用户。
一站式多语言翻译解决方案,支持文本、图片、PDF、语音和视频翻译
智能翻译助手是一个基于AI技术的多语言翻译平台,旨在为用户提供高效、准确的翻译服务。其核心优势在于强大的多语言支持能力,能够满足不同用户在多种场景下的翻译需求。无论是学术研究、商务交流还是日常学习,该平台都能提供精准的翻译结果。此外,其纯网页版的设计无需用户下载安装,随时随地可使用,极大地提高了使用便利性。平台注重用户隐私保护,不保存用户数据,确保信息安全。从技术角度来看,其背后依托先进的AI算法,能够实现对文本、图片、语音等多种格式内容的智能识别与翻译,体现了人工智能在语言翻译领域的强大应用价值。
一键生成带字幕和配音的视频翻译工具
VideoTrans是一款免费开源的视频翻译配音工具。它可以一键识别视频字幕、翻译成其他语言、进行多种语音合成,最终输出带字幕和配音的目标语言视频。该软件使用简单,支持多种翻译和配音引擎,能大幅提高视频翻译的效率。
一款支持多浏览器的高质量翻译插件,提供PDF翻译、学术翻译等多种功能。
北极象沉浸式翻译是一款依托业界专业引擎的翻译插件,支持多种浏览器,提供PDF翻译、学术翻译、沉浸式翻译、整页划词翻译和在线词典等功能。其主要优点是翻译准确度高、速度快,支持多语种,能够满足用户在不同场景下的翻译需求。产品由深圳市象塔科技有限公司开发,目前可在Chrome、Edge、火狐、360安全浏览器等多款浏览器的应用商店下载安装,具体价格未在页面中明确说明,但从页面信息来看,可能存在免费版本。
实时语音翻译器,支持60+语言,用于会议、活动、直播,可免费试用。
Palabra.ai是一款基于AI技术的实时语音翻译工具。其重要性在于打破语言障碍,让不同语言的人能够顺畅交流。主要优点包括支持60多种语言、实时翻译、适用于多种场景(如会议、活动、直播等)。产品背景未提及。价格方面可免费试用。定位是满足跨语言交流需求的高效翻译工具。
实时翻译,轻松沟通
智能翻译助手是一款基于人工智能技术的实时翻译工具。它能够快速准确地将多国语言进行互译,轻松帮助用户进行语言沟通。该产品具有智能识别功能,支持语音翻译、文字翻译、拍照翻译等多种翻译方式。优势包括高准确率、实时翻译、便捷易用。定价灵活,提供免费试用和多种付费套餐选择。定位于个人用户、旅行者、跨文化交流者等。
实时翻译,便捷无忧
智能翻译助手是一款实时翻译插件,能够快速准确地翻译多种语言。它具有以下功能和优势:1. 实时翻译,无需等待,即时满足用户需求;2. 支持多种语言,覆盖全球主要语种;3. 界面简洁易用,操作方便;4. 翻译结果准确可靠,提供多种翻译选项;5. 定价合理,免费试用和付费版本可选;6. 适用于各种场景,如网页浏览、办公文档等;7. 支持多种平台,包括浏览器和操作系统插件。定位于提供便捷、高效的翻译服务。
高效准确的在线翻译服务
腾讯翻译君是腾讯公司推出的在线翻译服务,它利用先进的人工智能技术,为用户提供文本、图片和文档的翻译服务。该产品支持多种语言之间的互译,具有高准确性和快速响应的特点,极大地提高了跨语言沟通的效率。腾讯翻译君适合需要进行语言翻译的个人和企业用户,无论是日常沟通还是专业文档翻译,都能提供强大的支持。
声波 - 语音识别和翻译
SpeechPulse是一款语音识别和翻译软件。它使用OpenAI的Whisper语音到文本模型,实现实时的语音识别,支持多种语言。用户可以使用麦克风输入文字,也可以通过转录音视频文件进行语音识别和翻译。SpeechPulse可以在各种场景下使用,例如办公文档编辑、网页浏览、文件转录、视频字幕生成等。它具有极高的准确性和低延迟,并且完全离线使用。SpeechPulse提供免费版和付费版,付费版支持更多功能和更好的准确性。

© 2026 AIbase 备案号:闽ICP备08105208号-14