PixVerse V2是一个革命性的更新,它赋予每个用户轻松创建令人惊叹的视频内容的能力。使用V2,您可以轻松制作视觉冲击力强的电影,甚至可以加入现实世界中不存在的元素。主要优点包括模型升级、画质提升、剪辑间的一致性等。
需求人群:
"PixVerse V2适合需要快速制作高质量视频内容的创意专业人士,例如视频编辑、动画制作者和市场营销专家。它通过提供先进的视频生成技术,帮助用户节省时间并提高工作效率。"
使用场景示例:
视频编辑使用PixVerse V2快速制作电影预告片。
动画制作者利用该工具创作独特的动画短片。
市场营销团队使用PixVerse V2为产品制作引人入胜的广告视频。
产品特色:
直接生成长达8秒的视频,为创意和叙事提供更多空间。
显著提升视频分辨率、细节和动态效果。
在1到5个视频剪辑中保持一致的风格、主题和场景,增强最终视频的连贯性和内容一致性。
支持文本到视频和图像到视频的转换。
支持最多同时生成5个场景的视频。
提供视频编辑功能,包括角色、环境和动作的选项。
自动将所有剪辑拼接在一起,不支持单个剪辑下载。
使用教程:
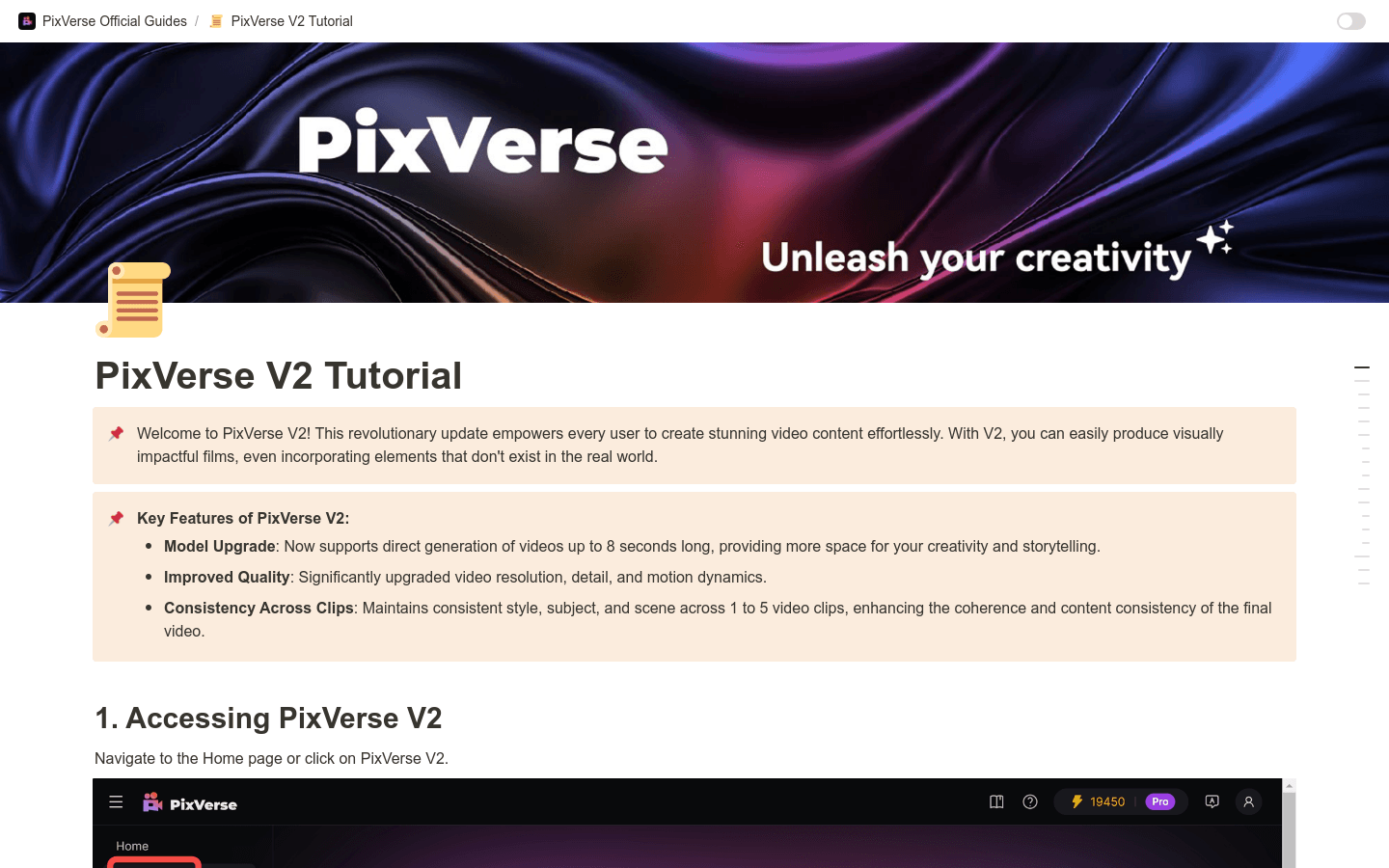
访问PixVerse V2的首页或直接点击PixVerse V2进入。
输入提示或上传图像以生成视频。
选择视频长度,PixVerse V2支持5秒和8秒的视频生成。
添加新场景,编辑场景以匹配所需的风格和内容。
生成视频,每个生成需要消耗一定的积分,并且自动将所有剪辑拼接。
编辑生成的视频,通过选择不同的效果来调整视频内容。
重新生成视频,所有未修改的场景也将在重新生成时发生变化。
浏览量:127
最新流量情况
月访问量
71.82k
平均访问时长
00:00:30
每次访问页数
1.54
跳出率
62.01%
流量来源
直接访问
25.22%
自然搜索
32.45%
邮件
0.10%
外链引荐
38.98%
社交媒体
2.43%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
西班牙
5.71%
韩国
4.88%
墨西哥
6.52%
俄罗斯
12.89%
美国
13.85%
Freepik AI 视频生成器,基于人工智能技术快速生成高质量视频内容。
Freepik AI 视频生成器是一款基于人工智能技术的在线工具,能够根据用户输入的初始图像或描述快速生成视频。该技术利用先进的 AI 算法,实现视频内容的自动化生成,极大地提高了视频创作的效率。产品定位为创意设计人员和视频制作者提供快速、高效的视频生成解决方案,帮助用户节省时间和精力。目前该工具处于 Beta 测试阶段,用户可以免费试用其功能。
利用AI技术快速生成视频内容
AI视频生成神器是一款利用人工智能技术,将图片或文字转换成视频内容的在线工具。它通过深度学习算法,能够理解图片和文字的含义,自动生成具有吸引力的视频内容。这种技术的应用,极大地降低了视频制作的成本和门槛,使得普通用户也能轻松制作出专业级别的视频。产品背景信息显示,随着社交媒体和视频平台的兴起,用户对视频内容的需求日益增长,而传统的视频制作方式成本高、耗时长,难以满足快速变化的市场需求。AI视频生成神器的出现,正好填补了这一市场空白,为用户提供了一种快速、低成本的视频制作解决方案。目前,该产品提供免费试用,具体价格需要在网站上查询。
创新的AI视频生成器,快速实现创意视频。
Luma AI的Dream Machine是一款AI视频生成器,它利用先进的AI技术,将用户的想法转化为高质量、逼真的视频。它支持从文字描述或图片开始生成视频,具有高度的可扩展性、快速生成能力和实时访问功能。产品界面用户友好,适合专业人士和创意爱好者使用。Luma AI的Dream Machine不断更新,以保持技术领先,为用户提供持续改进的视频生成体验。
基于 AI 技术生成视频内容的智能服务。
清影 AI 视频生成服务是一个创新的人工智能平台,旨在通过智能算法生成高质量的视频内容。该服务适合各种行业用户,能够快速便捷地生成富有创意的视觉内容。无论是商业广告、教育课程还是娱乐视频,清影 AI 都能提供优质的解决方案。该产品依托于先进的 GLM 大模型,确保生成内容的准确性与丰富性,同时满足用户个性化需求。提供免费试用,鼓励用户探索 AI 视频创作的无限可能。
利用AI技术,将文字和图像转化为创意视频。
通义万相AI创意作画是一款利用人工智能技术,将用户的文字描述或图像转化为视频内容的产品。它通过先进的AI算法,能够理解用户的创意意图,自动生成具有艺术感的视频。该产品不仅能够提升内容创作的效率,还能激发用户的创造力,适用于广告、教育、娱乐等多个领域。
轻松创建视觉冲击的视频内容。
PixVerse V2是一个革命性的更新,它赋予每个用户轻松创建令人惊叹的视频内容的能力。使用V2,您可以轻松制作视觉冲击力强的电影,甚至可以加入现实世界中不存在的元素。主要优点包括模型升级、画质提升、剪辑间的一致性等。
使用简单的提示和图像生成视频片段。
Adobe Firefly 是一款基于人工智能技术的视频生成工具。它能够根据用户提供的简单提示或图像快速生成高质量的视频片段。该技术利用先进的 AI 算法,通过对大量视频数据的学习和分析,实现自动化的视频创作。其主要优点包括操作简单、生成速度快、视频质量高。Adobe Firefly 面向创意工作者、视频制作者以及需要快速生成视频内容的用户,提供高效、便捷的视频创作解决方案。目前该产品处于 Beta 测试阶段,用户可以免费使用,未来可能会根据市场需求和产品发展进行定价和定位。
通过文本生成高质量AI视频
Sora视频生成器是一个可以通过文本生成高质量AI视频的在线网站。用户只需要输入想要生成视频的文本描述,它就可以使用OpenAI的Sora AI模型,转换成逼真的视频。网站还提供了丰富的视频样例,详细的使用指南和定价方案等。
使用 AI 将照片或视频转换为创意视频生成内容。
CloneAI 是一款运用人工智能技术将用户提供的照片或视频素材,快速生成创意、视觉冲击力较强的视频内容的应用程序。背景上,它抓住了短视频/社交媒体时代用户对“快速生成、个性化、易分享”内容的需求。技术上通常包括人像识别、动作/表情合成、风格迁移或动画化等。主要优点包括:操作门槛低(普通用户也能上手)、生成速度快、素材可社交化分享、支持多种视觉风格。定位为社交内容创作者、短视频制作者、普通用户“让记忆动起来”工具。价格采用免费试用 + 内购订阅模式(参见 App Store 内“Pro Subscription”信息):contentReference[oaicite:0]{index=0}
将您的创意转化为电影级视频,轻松生成精彩内容。
VO3 AI 视频生成器是一款先进的 AI 视频生成工具,允许用户通过文本和图像生成高质量的视频。它结合了最新的 AI 技术,使得视频创作变得前所未有的快速和简单。其定价模式合理,适合不同层次的创作者,初始套餐仅需 $2.99,可以生成 3 个无水印的视频,吸引大量新用户和内容创作者。
AI赋能的短视频生产平台,批量生成多样化视频内容。
Giga视频超级工厂是一款基于AI技术,融合多项智能能力的视频生产平台。它通过智能化技术和工业化生产线,实现短视频的批量生产,让创意快速变为现实。产品具备视频生视频、图文生视频、报纸生视频以及视频智能翻译等功能,适用于新闻报道、企业宣传、活动推广等多种场景,助力用户高效制作并传播视频内容。
AI驱动的视频生成工具,一键生成高质量营销视频
小视频宝(ClipTurbo)是一个AI驱动的视频生成工具,旨在帮助用户轻松创建高质量的营销视频。该工具利用AI技术处理文案、翻译、图标匹配和TTS语音合成,最终使用manim渲染视频,避免了纯生成式AI被平台限流的问题。小视频宝支持多种模板,用户可以根据需要选择分辨率、帧率、宽高比或屏幕方向,模板将自动适配。此外,它还支持多种语音服务,包括内置的EdgeTTS语音。目前,小视频宝仍处于早期开发阶段,仅提供给三花AI的注册用户。
在线免费 AI 视频生成器,支持视频、图像和文本转视频。
Lanta AI 是一款在线 AI 视频生成工具,允许用户通过简单的操作将文本、图像和视频转换为高质量的 AI 生成视频。其主要优势在于操作简便,生成速度快,支持多种风格转换,适合内容创作者、动画制作者及企业营销人员使用。该产品定位于提供高效的视频制作解决方案,且提供免费试用服务以吸引用户。
AI视频创作工具,将老照片转化为动态视频。
京亦智能AI视频生成神器是一款利用人工智能技术,将静态的老照片转化为动态视频的产品。它结合了深度学习和图像处理技术,使得用户能够轻松地将珍贵的老照片复活,创造出具有纪念意义的视频内容。该产品的主要优点包括操作简便、效果逼真、个性化定制等。它不仅能够满足个人用户对于家庭影像资料的整理和创新需求,也能为商业用户提供一种新颖的营销和宣传方式。目前,该产品提供免费试用,具体价格和定位信息需进一步了解。
生成多镜头叙事视频的工具,具有高连贯性和视觉效果。
StoryMem 是一款针对多镜头长视频叙事的生成模型,通过记忆条件的视频扩散模型,能够根据故事剧本生成连贯且具有电影视觉质量的分钟长视频。它适用于创作者和开发者,在视频制作中提供了一种新的高效且创意的方式,帮助用户在短时间内生成故事视频。此工具的定位在于提升视频内容创作的生产力,适合各种风格的叙事需求。
Google最先进的视频生成模型,提供高质量1080p视频生成。
Veo是Google最新推出的视频生成模型,能够生成高质量的1080p分辨率视频,支持多种电影和视觉风格。它通过先进的自然语言和视觉语义理解,能够精确捕捉用户创意愿景,生成与提示语调一致且细节丰富的视频内容。Veo模型提供前所未有的创意控制水平,理解电影术语如“延时摄影”或“航拍景观”,创造出连贯一致的画面,使人物、动物和物体在镜头中逼真地移动。
多阶段高美感视频生成
MagicVideo-V2是一个集成了文本到图像模型、视频运动生成器、参考图像嵌入模块和帧插值模块的端到端视频生成管道。其架构设计使得MagicVideo-V2能够生成外观美观、高分辨率的视频,具有出色的保真度和平滑性。通过大规模用户评估,它展现出比Runway、Pika 1.0、Morph、Moon Valley和Stable Video Diffusion等领先的文本到视频系统更优越的性能。
视频生成的精细控制工具
Ctrl-Adapter是一个专门为视频生成设计的Controlnet,提供图像和视频的精细控制功能,优化视频时间对齐,适配多种基础模型,具备视频编辑能力,显著提升视频生成效率和质量。
HappyHorse 1.0可将文本或图像转化为高清AI视频,有免费额度,免信用卡试用。
HappyHorse 1.0是一个基于先进人工智能技术的视频生成平台,其重要性在于为创作者提供了便捷、高效的视频创作途径。该平台的主要优点包括:支持文本和图像转视频,输出高清视频,具备商业使用许可,提供免费额度,无需信用卡即可试用。产品定位为满足创作者和团队对于高质量视频制作的需求,适用于社交媒体内容创作、营销广告等领域。价格方面,有不同质量和时长的套餐可供选择,例如标准质量5秒180积分,10秒360积分;Pro质量5秒240积分,10秒480积分。
Seedance 2.0是AI视频生成助手,能秒速将创意转化为惊艳视频。
Seedance 2.0是一款先进的AI视频生成工具,可通过文本或图像快速生成高质量视频。其重要性在于极大提高了视频创作效率,降低了专业视频制作门槛。主要优点包括镜头叙事连贯、相机运动流畅、音画同步性强,能生成高品质视频且操作简单。产品背景方面,受到全球超过50万创作者信赖。价格上,有不同的订阅计划,包括Lite版、Pro版和Premium版,分别适合不同需求的用户,定位为面向创作者、营销人员和专业团队的视频创作平台。
视频生成AI模型,能够根据文本描述生成高质量视频
VideoCrafter2是一个视频生成AI模型,能够根据文本描述生成高质量、流畅的视频。它通过克服数据局限,实现了高质量视频生成的目标。该模型可以生成照片级质量的视频,支持精细的运动控制和概念组合。用户只需要提供文本描述,VideoCrafter2就可以自动生成剧本级别的视频作品,可用于视频创作、动画制作等领域。
免费去除 Sora AI 视频中的水印,快速清晰处理。
该工具允许用户快速上传带水印的 Sora 视频,并通过 AI 技术自动检测和移除水印,极大地提高了视频处理的效率。其重要性在于帮助用户轻松获取无水印的清晰视频,适用于内容创作者和视频编辑者。该工具免费使用,提供每日视频处理的限制,满足日常需求。
免费在线AI视频生成器,为拒绝平庸的团队提供创意视频制作方案。
HappyHorse 1.0 AI是happyhorse-ai.io的旗舰创意平台,它将统一智能、动态制作和后期润色相结合。该平台适合那些追求高品质视频输出、拒绝普通表现的团队。其优势在于提供导演级别的视频生成控制,具有先进的运动合成技术,可根据文本或图像生成1080p的电影级视频。价格方面,文中虽未明确提及具体收费标准,但提到生成视频有估计成本(如示例中的88学分),推测有付费模式,同时也提供免费试用(可Start Free Now)。平台定位是满足创作者、团队和工作室在现代视频工作流程中对电影级控制、快速迭代和一致视觉质量的需求。
AI视频生成工具
Sora AI Video Generator是一款用于生成AI视频的工具。它可以根据提供的文本内容,自动合成出高质量的视频。该工具具有智能视频编辑、自动配乐、特效添加等功能,可以满足用户在影视制作、广告制作、社交媒体营销等领域的需求。定价方面,请访问官方网站了解详情。

© 2026 AIbase 备案号:闽ICP备08105208号-14