浏览量:250
最新流量情况
月访问量
1.20m
平均访问时长
00:00:47
每次访问页数
1.57
跳出率
73.53%
流量来源
直接访问
45.07%
自然搜索
28.81%
邮件
0.15%
外链引荐
20.05%
社交媒体
2.97%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
中国
5.52%
英国
3.78%
印度
3.89%
日本
6.95%
美国
26.63%
高级英语口语练习平台
SpeakFit.club是一个高级英语口语练习平台,帮助用户克服中级瓶颈,提高语言说服力。通过每天的话题讨论和语音纠错,让用户更好地思考外语并进行口语实践。平台提供新鲜的话题、精确的语音识别、两种纠错模式、随机短语练习以及个性化的进度追踪,帮助用户在职业目标中取得进步。
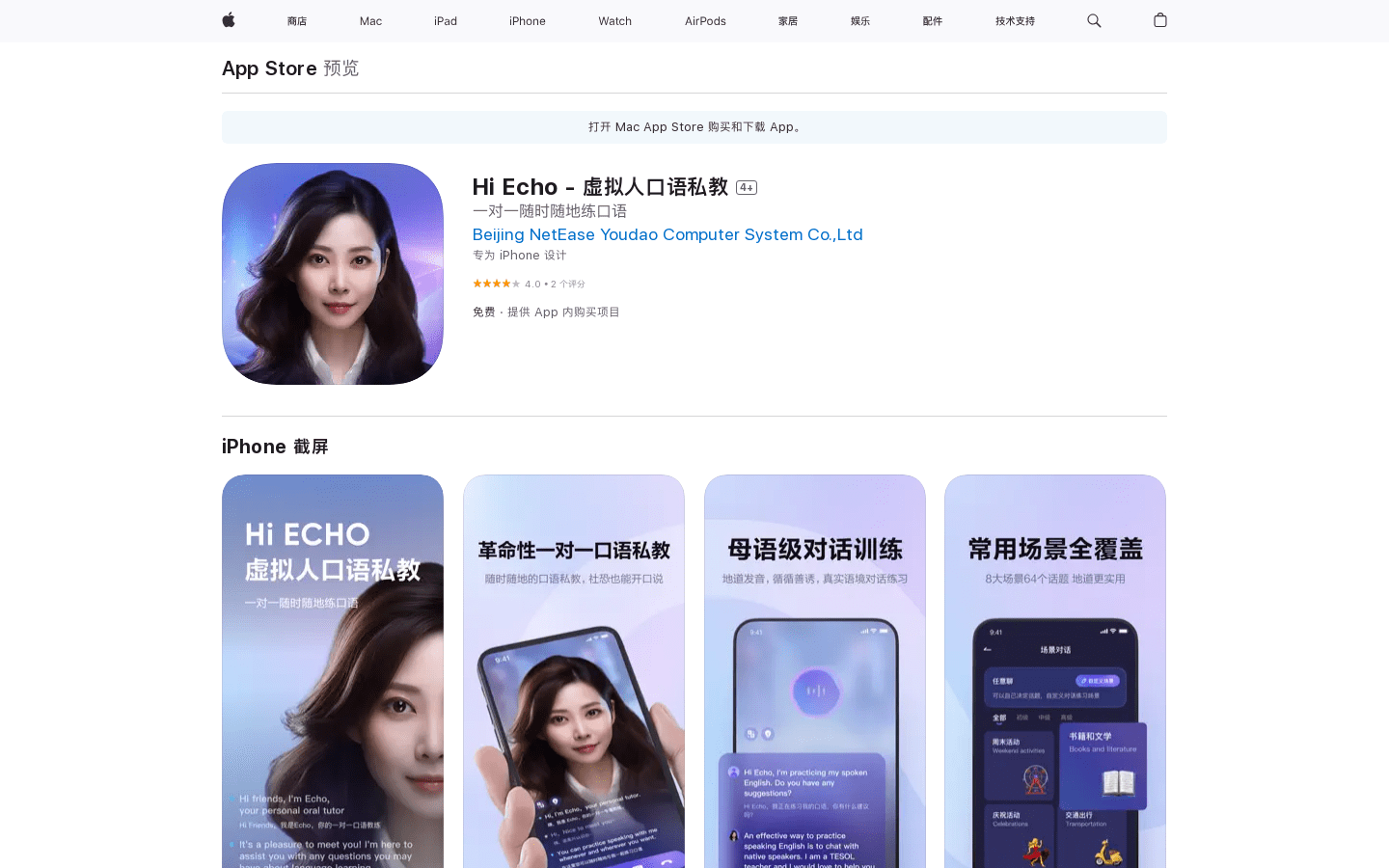
虚拟人口语私教 随时随地练习口语
Hi Echo 是一款口语学习App,为用户提供随时随地的一对一口语练习。覆盖多个对话场景和话题,系统会根据用户的语音进行评测和提升建议,可以快速提高口语能力。无须在意社交焦虑,用户可以随时随地进行口语练习。
AI口语练习应用
AITalk是基于ChatGPT的口语练习应用。最大的特点是可以定制真实的口语对话场景,摆脱固定的口语对话内容,告别紧张和尴尬,坚持自信地说话30天。定价:免费试用。定位:AI口语练习应用。
突破中级英语的AI驱动英语练习应用
AvidX是一款使用人工智能技术的英语练习应用,旨在帮助学习者突破中级英语水平。通过每天进行有意识的练习,使用我们的AI驱动应用,建立新的语言学习习惯,您将在中级英语的瓶颈上取得突破。AvidX采用了独特的学习方式,提供了各种练习模式,包括阅读、听力、口语练习等,帮助您提高词汇量、阅读理解、听力、口语等方面的能力。加入我们的Beta计划,获取独家预发布权限,并在正式发布后获得Pro版3个月的免费使用权。
语音转文字,支持实时语音识别、录音文件识别等
腾讯云语音识别(ASR)为开发者提供语音转文字服务的最佳体验。语音识别服务具备识别准确率高、接入便捷、性能稳定等特点。腾讯云语音识别服务开放实时语音识别、一句话识别和录音文件识别三种服务形式,满足不同类型开发者需求。技术先进,性价比高,多语种支持,适用于客服、会议、法庭等多场景。
一款帮助学习外语口语的实用工具APP
这款APP通过与AI和母语使用者进行实时语音交流,帮助用户练习并快速提高英语口语能力。它能打破语言障碍,让用户一对一地与AI和真人语伴进行实时对话,以提高发音和流利度。用户可以下载APP,开始口语训练之旅。
克服在英语口语中的羞涩,与AI辅导师一起学习英语
Zaplingo是一款使用AI辅导师进行英语学习的产品。通过与Zaplingo进行实时对话和练习,克服在英语口语中的羞涩。说一声你好,迎接一种新的互动便捷的英语学习方式。
提升英语口语能力的语音录制和反馈应用
AISpeak是一款专注于提升英语口语能力的语音录制和反馈应用。用户可以通过录制60秒的回答来练习口语,并在提交后获得有价值的反馈,以提升自己的技巧。此外,AISpeak还提供有趣的词汇游戏和样例问答等功能,帮助用户扩展词汇量和提升回答的组织能力。AISpeak适用于即将参加英语语言考试或正在学习英语的个人。请下载我们的应用以提高英语口语自信。
AI外教1对1情景口语学习APP
可栗口语是一款利用尖端AI技术,提供1对1情景口语练习的英语学习APP。它适用于所有水平的学习者,通过AI虚拟外教进行实时语法和发音纠正,提供多种风格和场景的对话练习,帮助用户全面提升听说读写能力。可栗口语专为移动端设计,同时支持安卓、iPhone和Mac,覆盖了日常生活、留学、职场等多种实用场景,并且提供雅思模考和KET/PET备考功能。产品的主要优点包括个性化学习内容定制、24小时在线的AI外教、以及雅思真题和智能评分系统。
英语学习个性化教练APP
English Coach是一个英语学习个性化教练APP。它可以支持、纠正和鼓励用户在每一个学习阶段,提供专家建议,帮助用户快速获得自信,并为自己的英语感到自豪。该APP内含Oxford University Press设计的100多个工作场景的英语口语和发音练习,涵盖面试、会议、演示等。关键功能包括:实时英语口语练习和接收反馈、个性化学习建议、适合用户学习进度的专业内容、模拟不同工作场景的英语对话练习等。它适用于想提高英语口语和降低口音的用户,尤其是职场人士。
Fluently 是一款 AI 驱动的英语学习工具,帮助用户提升英语口语、语法和词汇能力。
Fluently 是一款基于人工智能技术的英语学习应用,旨在通过个性化学习计划和实时反馈帮助用户提升英语水平。它利用先进的语音识别和自然语言处理技术,为用户提供针对性的口语练习和语法纠错服务。该产品的主要优点包括个性化学习路径、实时反馈以及24/7的可用性。它面向希望提升英语口语能力的非英语母语者,尤其是那些需要在工作或日常生活中使用英语的人群。Fluently 提供免费试用,正式使用需要付费。
个性化外语口语练习工具
Teacher AI是一个个性化外语口语练习工具,可以进行24/7的个性化口语练习,价格仅为人类教师的一小部分。它可以纠正您的错误并解释语法,还可以了解您的学习方式。您可以和AI老师用英语交流,它也会回答您的问题。我们可以跟踪您的进度,让您的成绩得到提高。Teacher AI是由世界上最有经验的语言学习者和教师创建的,不建议给完全初学者使用。加入我们,获得即时访问所有语言和AI老师的机会。
提升英语口语自信,获得流利英语对话能力
FLOW Speak是一款AI辅助反馈的学习工具,帮助用户提高英语口语自信度和流利对话能力。通过轻松有趣的对话练习,掌握日常表达和商务表达,随时随地提升口语水平。用户可以根据自己的节奏自主练习,通过AI智能反馈及时改进。FLOW Speak提供结构化的学习路径,帮助用户逐步提高口语能力,达到各个阶段的学习目标,并获得相应的成就徽章和证书。FLOW Speak的定价相对于在线课程来说,节省了90%的费用。
AI语言教师 | 练习口语与听力
Gliglish是一款基于人工智能的语言教师,帮助用户提高口语流利度和自信心。它提供智能AI辅助教学,节省学习时间和金钱成本。用户可以随时随地练习,无需安排课程。Gliglish支持多种语言,提供个性化建议和反馈,使学习更加高效。
与AI导师对话,成为流利英语口语者
Lorro是一款通过与AI导师对话来提高英语口语能力的产品。用户可以通过与AI导师进行对话练习,提高英语口语表达能力。该产品定位于帮助用户在较低成本的情况下提升英语口语能力。定价灵活,适合不同需求的用户。
个性化英语听力练习
Listening是一个个性化英语听力练习平台,通过将你喜欢的视频转化为听力练习,帮助你提高英语听力技能。我们提供定制化学习,灵活的练习时间,多样的问题类型以及进度跟踪等功能。加入我们的社区,与其他英语学习者分享学习经验。
英语易说 - 学习英语语法、词汇、发音和对话
English Speak Easy是一个完美的应用程序,适用于任何想提高英语口语能力的人。它提供了广泛的功能,可以学习新词汇、练习发音,增强英语口语的自信心。它包括词典、聊天、写作、随机通话、视频通话、群组会议、独立练习、阅读等功能。无论你是初学者还是高级学习者,English Speak Easy都能帮助你提高英语口语能力。
全球首个有温度的AI口语私教,助力提升口语能力
咕噜口语speakguru是一款专注于提升用户口语能力的AI教育APP。它利用AI技术模拟真实对话场景,为用户提供一对一的口语练习环境。重要性在于打破了传统口语学习受时间、地点和师资限制的困境,让用户随时随地都能练习口语。主要优点是具有“温度”,能像真实私教一样与用户互动交流,理解用户意图并给出针对性反馈。该产品定位为全球用户提供便捷、高效的口语学习工具,目前暂未提及价格相关信息。
AI驱动的口语助手,提供个性化反馈提高口语技能
Spellar AI是一个AI驱动的口语助手,通过提供个性化反馈来增强口语技能和提高自信心。该产品可以实时检测语速、标记填充词,并根据语速显示不同颜色以示警告。它还可以根据专业、友好等风格给出个性化语音建议。主要功能有语音识别、填充词检测、语速检测、会议记录、语音风格转变等。适用于提高英语口语能力,准备演讲、面试、会议等场景使用。
英语口音识别工具
BoldVoice Accent Oracle是一个在线工具,能够在短时间内识别出用户说英语时的口音,并猜测用户的母语。这项技术的重要性在于它能够帮助语言学习者了解自己的发音特点,从而进行针对性的改进。产品背景信息显示,BoldVoice致力于通过技术提升人们的沟通能力,该工具可能被用于教育和语言学习领域。关于价格,网站并未提供具体信息,但考虑到其教育性质,可能提供免费试用或基础服务免费,高级功能付费的模式。
和AI伙伴进行语音对话练习语言
TalkMe是一个语言学习App。用户可以与具有不同口音和性格的AI伙伴进行自由对话,练习听说能力。App提供实时语法纠错、词汇学习、语言翻译等功能,科学的语言学习模型帮助用户快速掌握语言。
基于Google Gemini AI的英语发音纠正工具
Gemini 英语口语助手是一个基于Google Gemini AI的英语口语练习助手,能够实时识别用户的英语发音,并提供即时反馈和纠正建议。它具备实时语音识别、AI驱动的发音评估、语法纠正、情景对话练习等功能,旨在帮助用户提高英语口语能力。该产品由个人开发者Box开发,以其免费、实用的特性,特别适合英语学习者和教师使用。
英语学习插件
PACT是一款易于使用的Chrome插件,通过喜爱的视频来提升你的英语技能。它将视频的字幕转化为练习题,你的答案会被AI评估和分析。你可以跟踪错误答案,并通过个人仪表板了解自己的学习进展。PACT提供基础和高级两个版本,高级版提供更多智能功能,定价为每月2.99美元或每年27美元。无论你是英语初学者还是高级学习者,PACT都能满足你的需求。
与先进AI学习60种外语,跨越语言边界,提升口语能力。
TalkAI练口语是一款先进的口语学习工具,通过AI技术为用户提供一对一的口语陪聊服务,支持超过60种语言。其重要性在于帮助用户突破语言障碍,提升口语水平,无论是初学者还是希望提升口语能力的学习者都能从中受益。该产品由深圳市惊叹科技有限公司开发,于2021年12月03日成立,注册地位于深圳市宝安区。其服务对象广泛,包括学校、企业和个人用户,致力于通过技术创新推动语言学习的普及和发展。目前暂无明确公开的价格信息,但根据其功能和服务范围,推测其可能采用付费模式或提供部分免费试用服务。
基于AI的英语学习应用
LinguAI是一个基于AI的英语学习App。它提供词汇卡片、AI老师、AI伙伴聊天等功能,可以帮助用户提高英语听说读写能力。它使用个性化学习和积分反馈来激励用户,使英语学习过程更轻松有趣。
Duolingo English Test在线练习平台
DET练习是一个专为Duolingo English Test设计的在线练习平台,提供广泛的题库、模拟考试、AI评分和课程学习等功能,帮助用户提高英语水平并准备Duolingo English Test。平台以其智能性能跟踪、实时反馈和个性化学习计划为主要优点,满足了不同水平英语学习者的需求,特别适合那些寻求提高Duolingo English Test成绩的学习者。
提高口语,与AI对话
AI英语口语助教是一款帮助提高口语的应用程序,用户可以与AI角色进行自然流畅的对话,并获得实时反馈。通过提示更好的表达方式,用户可以扩展词汇量,优化沟通风格。应用提供多种可调节的功能,如调速、重听、翻译等。用户可以自由练习英语对话,无需担心被评判。购买不同套餐可以获得不同的使用时长。

© 2026 AIbase 备案号:闽ICP备08105208号-14