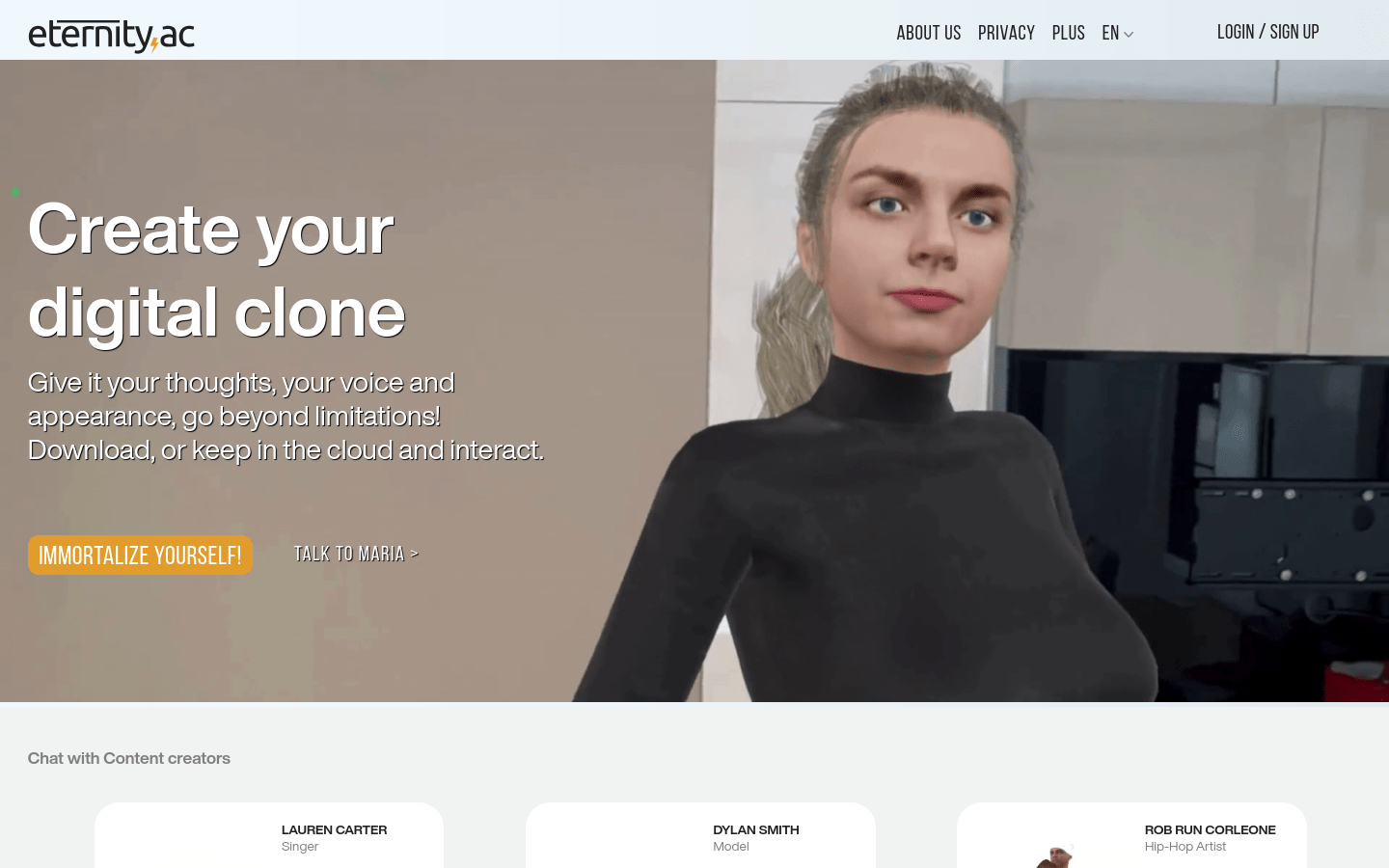
eternity.ac是一个提供数字克隆服务的平台,允许用户创建具有自己思想、声音和外观的数字克隆体。这项技术突破了传统的交流和表达方式,使用户能够以全新的形式与世界互动。产品背景信息显示,eternity.ac致力于推动数字存在技术的革命,为用户提供一种全新的自我表达和社交方式。
需求人群:
"目标受众包括追求个性化表达和社交创新的个人用户,以及希望利用数字克隆技术提升品牌形象和客户服务的企业用户。数字克隆技术适合他们,因为它提供了一种新颖的互动方式,可以跨越时间和空间的限制,实现更广泛的社交和商业目的。"
使用场景示例:
Lauren Carter的数字克隆可以与粉丝进行一对一的交流,分享音乐创作心得。
Dylan Smith的数字克隆可以作为模特品牌的一部分,与粉丝互动并提供时尚建议。
Rob Run Corleone的数字克隆可以参与音乐活动的宣传,与粉丝分享创作灵感。
产品特色:
与数字克隆进行对话,分享您的想法和感受。
数字克隆可以代表您与他人进行交流,甚至在您不在时支持您的家庭。
数字克隆可以作为公众克隆,与他人分享并拍照留念。
数字克隆可以用于商业,提升销售、服务和市场营销效果。
数字克隆可以作为内容创作者,与粉丝进行一对一的交流,扩大个人品牌影响力。
数字克隆可以作为私人或公共的AI数字克隆,提供个性化服务。
使用教程:
访问eternity.ac网站并注册账户。
选择创建数字克隆的选项,并根据提示提供个人信息。
上传您的声音样本和外观照片,以便数字克隆能够模拟您的声音和外观。
设置数字克隆的个性特征和对话风格。
完成设置后,您可以开始与数字克隆进行互动,或将其分享给其他人。
根据需要,您可以调整数字克隆的设置,以优化其表现和功能。
浏览量:75
最新流量情况
月访问量
677
平均访问时长
00:00:00
每次访问页数
1.05
跳出率
33.36%
流量来源
直接访问
0
自然搜索
0
邮件
0
外链引荐
0
社交媒体
0
展示广告
0
截止目前所有流量趋势图
创建您的数字克隆,超越限制,实现自我不朽。
eternity.ac是一个提供数字克隆服务的平台,允许用户创建具有自己思想、声音和外观的数字克隆体。这项技术突破了传统的交流和表达方式,使用户能够以全新的形式与世界互动。产品背景信息显示,eternity.ac致力于推动数字存在技术的革命,为用户提供一种全新的自我表达和社交方式。
体验个性化情绪支持的人工智能
Emotional Support AI 通过具有共情能力的人工智能技术提供个性化、可访问的情绪支持。它可以与您对话并提供情绪上的支持和建议。无论您感到压力、焦虑还是孤独,Emotional Support AI 都会倾听您的需求并提供恰当的支持。您可以在官方网站上注册并选择不同的服务计划来获取更多个性化的支持。
为品牌提供个性化的人工智能内容
我们帮助营销人员加快生产周期,实现品牌定制的、商业安全的内容在规模上的10倍增长。我们的产品具有以下功能和优势:- 提供个性化的人工智能内容 - 提高生产效率,节省时间和资源 - 商业安全,保护品牌声誉 - 可以定制的定价计划,适应不同的业务需求 - 适用于各种营销场景和渠道
由人工智能驱动的个性化杂志服务,让定制信息融入生活。
Myzine 是一款通过人工智能技术生成个性化杂志的应用,旨在提升用户的信息消费体验。用户可以根据自己的兴趣、阅读习惯及偏好自定义内容,创造出独特的阅读体验。Myzine 支持多种兴趣领域的选择,定期更新内容,帮助用户轻松获取所需的信息,并享受个性化的阅读乐趣。应用提供免费和付费订阅套餐,适合各类用户。 适用于想要提升阅读效率、获取定制内容的用户。
在线AI塔罗牌阅读,提供个性化占卜服务。
TarotRead AI是一个结合塔罗牌占卜与人工智能技术的在线平台,旨在为用户提供快速、个性化的塔罗牌阅读体验。该平台由塔罗牌爱好者和AI技术爱好者共同创建,致力于让每个人都能获得神圣的指引,无论他们身处人生的哪个阶段。TarotRead AI以其准确的占卜结果和个性化建议受到用户的好评,尽管AI不能完全复制人类塔罗牌阅读者的主观解读,但它提供了一种新颖且便捷的塔罗牌阅读方式。目前,该服务是免费的,但未来可能会根据使用情况收费。
智能对话助手,提供个性化服务和解决方案。
ChatGPT是一个基于人工智能技术的聊天平台,它能够通过自然语言处理和机器学习技术,理解用户的需求并提供相应的帮助。它不仅可以帮助用户规划旅行、测试知识、撰写邮件,还能设计编程游戏,教授编程基础。ChatGPT的主要优点在于其高度的交互性和个性化服务能力,能够根据用户的具体需求提供定制化的解决方案。
使用人工智能为孩子创建个性化的童话故事。
Dailos.ai是一款能够为孩子创建魔幻有趣的个性化故事的神奇笔记本。用户只需输入故事主角、希望传达的价值观以及想要包含的角色,即可创作充满魔力和乐趣的故事。Dailos.ai鼓励阅读,激发孩子的想象力。
Play.ai 是一个基于人工智能的语音交互平台,提供个性化的对话体验。
Play.ai 是一个先进的语音交互平台,它利用人工智能技术为用户提供流畅、自然的对话体验。该平台不仅能够理解用户的指令,还能根据上下文进行智能回应,为用户提供个性化的服务。Play.ai 的主要优点在于其高度的交互性和智能化,它能够适应不同用户的需求,提供定制化的对话服务。此外,Play.ai 还具有易于使用、快速响应等特点,使其成为企业和个人提升沟通效率的有力工具。
结合人工智能与塔罗牌智慧,提供个性化指导和每日运势预测
Soul Tarot 是一款创新的塔罗牌应用程序,将人工智能技术与塔罗牌的古老智慧相结合。它通过人工智能语音咨询、每日塔罗牌抽奖和幸运数字预测等功能,为用户提供便捷、深度、个性化的指导。该应用适合对塔罗牌感兴趣、希望通过神秘方式获得生活灵感的用户。它强调个性化和便捷性,用户可以随时随地获取塔罗牌的解读和建议,无需复杂的塔罗牌知识。
个性化高效的简历建立服务
ResumeReady是一项个性化高效的简历建立服务,使用微软Word和ChatGPT,帮助求职者创建符合职位要求的求职简历,从而在求职过程中脱颖而出。服务包括灵活的兼职简历建立、专业简历建立以及简历捆绑优惠。用户可通过Zoom会议与Atmiya进行45分钟或2小时的简历建立会话,获得个性化建议,并可获得可下载的Word模板及多次修改机会。服务备受学生欢迎,已制作40份以上简历。用户可在网站上查看满意客户的反馈。如果有任何疑问,请通过电子邮件联系。
人工智能入门教程网站,提供全面的机器学习与深度学习知识。
该网站由作者从 2015 年开始学习机器学习和深度学习,整理并编写的一系列实战教程。涵盖监督学习、无监督学习、深度学习等多个领域,既有理论推导,又有代码实现,旨在帮助初学者全面掌握人工智能的基础知识和实践技能。网站拥有独立域名,内容持续更新,欢迎大家关注和学习。
智能网站设计,一键生成个性化网页。
AI Web Designer是一个利用人工智能技术帮助用户快速生成个性化网站设计的在线平台。它通过用户输入的网站领域信息,自动生成设计草案,用户可以自由编辑和导出设计,甚至可以将其白标为自有产品。平台支持导出到Figma和获取原始HTML代码,为设计师和开发者提供了极大的便利。
推动人工智能安全治理,促进技术健康发展
《人工智能安全治理框架》1.0版是由全国网络安全标准化技术委员会发布的技术指南,旨在鼓励人工智能创新发展的同时,有效防范和化解人工智能安全风险。该框架提出了包容审慎、确保安全,风险导向、敏捷治理,技管结合、协同应对,开放合作、共治共享等原则。它结合人工智能技术特性,分析风险来源和表现形式,针对模型算法安全、数据安全和系统安全等内生安全风险,以及网络域、现实域、认知域、伦理域等应用安全风险,提出了相应的技术应对和综合防治措施。
利用AI技术创作个性化儿童绘本
阿贝智能是一家位于科技与教育交汇点的创新型企业,致力于通过尖端的人工智能技术,开启儿童教育的新纪元。我们相信每个孩子都拥有无限的潜能,而我们的使命是通过科技的力量,解锁这些潜能,帮助孩子们在愉悦的环境中成长和学习。
数字人定制与克隆服务
奇妙元提供真人形象克隆、声音克隆、3D 数字人定制和 IP 活化等超前沿的克隆与定制服务。通过高质量数据输入和迭代克隆模型,实现高清还原真人形象。用户可使用真人形象克隆终身,通过输入文字使数字人说话,表情神态可比真人。此外,奇妙元还提供数字人视频制作、直播会员和定制服务等功能。数字人视频制作可一键将文本转为视频,无需繁琐拍摄;直播会员可选择真人数字人或 3D 数字人进行直播,为用户挣钱;定制服务可根据用户需求定制数字人形象。奇妙元的产品广泛应用于 20 多个行业,500 多个客户已经受益于数字人定制与克隆服务。
定制深度个性化智能体
通义星尘是一个提供定制深度个性化智能体能力的产品,可以快速创造拥有独特人设和风格的智能体,并在不同场景中进行丰富的互动。它具备拟人化、场景化、多模态和共情的对话能力,以及复杂任务执行能力,可应用于IP复刻、恋爱&交友、萌宠&养成、游戏NPC、教育&服务等多个场景。通义星尘可以深度定义人设,包括基本信息、说话风格、专业知识或特殊技能等。它还能创造丰富的事件,如时空背景、故事情节、人物关系、任务和目标等。用户可以通过语言聊天、肢体动作、图片表情包等多种形式与通义星尘进行互动,并与其建立记忆、关系和情感的链接。
个性化AI代理,智能化你的知识库。
Genforge with ThinkChain.AI是一款个性化AI代理产品,它可以智能化你的知识库,并提供个性化的服务。它的功能包括自动化回答问题、智能搜索、个性化推荐等。优势是节省时间和提高效率,定价方面请咨询官方网站。它适用于各种场景,包括客户支持、知识管理、智能助手等。标签包括人工智能、个性化、智能化。
个性化图像生成工具
Midjourney是一个独立的研究实验室,专注于探索新的思想媒介和扩展人类想象力。它是一个自筹资金的小团队,专注于设计、人类基础设施和人工智能。Midjourney Personalization通过用户对图像对的评分来学习用户的偏好,并根据这些偏好生成个性化的图像。
怪兽智能科技推出的AI数字人产品,提供全息交互数字人、3D超写实交互数字人,AIGC生产、SaaS管理和直播服务平台
怪兽AI数字人是怪兽智能科技推出的产品,旨在通过AI技术提供数字人克隆、短视频生成、直播解决方案等服务。产品包括真人形象克隆、声音克隆、孪生姿态合成等核心技术,支持短视频内容生产创作及直播宣传,适用于品牌商家及本地生活商家。
生成个性化发型AI
TuNuevoLook是一个使用人工智能生成个性化发型的在线服务。用户可以上传一张自拍照片,30分钟内就会收到由人工智能生成的个性化发型照片。我们提供男性和女性的发型选择,并保证用户满意度。用户只需支付相应费用,即可获得个性化的发型建议。
AI生成个性化视频
FoxAcid AI是一款基于人工智能技术的个性化视频生成工具。通过上传一段个人录像和一个包含目标客户数据的电子表格,FoxAcid AI可以智能地根据电子表格中的数据为每个目标客户生成一段个性化视频。视频内容会根据电子表格中的姓名、地理位置、业务详情等信息进行定制,让每个目标客户都感觉到自己受到直接的关注。使用FoxAcid AI可以大大提升您的市场推广效果,提高客户转化率。
京东自主研发的人工智能开放平台
京东人工智能开放平台NeuHub,汇聚京东自主研发的人工智能核心技术,包含语音、图像、视频、NLP等技术,通过平台向外开放,助力行业智能升级。平台还提供数据标注、模型开发、训练和发布等全流程服务,以及创新应用案例,帮助企业实现智能化转型。
绘图,问答,图片处理一站式 AI 服务
小门道 AI 是一个提供 AI 服务的网站,包括 Midjourney 和 Stable Diffusion 绘图,chatgpt 对话,抠图,去除水印,魔法抹除,图片变清,无损放大等功能。我们提供智能问答功能,可联网搜索,任务式 (基于 AutoGPT),学术助理,上传文件,数学解题等。同时,我们还提供抠图、放大变清、转矢量图、人脸融合等图片处理功能。产品定价根据具体功能和使用情况而定,定位于提供高质量的 AI 服务。
人工智能制作,趋势个性化内容
Ghost Craft是一款AI辅助的内容创作工具,通过智能技术和个性化算法,帮助用户轻松定制和分享优质内容。其功能包括自动内容定制、AI辅助重写工具、智能内容策划和跨平台分享。Ghost Craft的定价灵活,定位于帮助用户提升数字声音,简化复杂流程,提高内容创作效率。
个性化旅行建议助手
VACAY CHATBOT是世界上第一个用户为中心的人工智能旅行助手。从奢华度假到文化融合,Vacay可以根据您的旅行风格、预算和独特偏好,为您规划完美的旅程。它还可以生成全面的指南,发现当地的推荐,以及为您的目的地提供独特的个性化见解。此外,Vacay还提供直达酒店、餐厅、体验等旅行选择的链接,确保透明度和最佳优惠。您可以轻松保存和导出聊天内容,将您的发现与其他旅行者分享。
人工智能遇见真实对话
FlirtAI App是一款将人工智能应用于在线约会的前沿应用程序。它旨在帮助用户有效自信地进行沟通,确保他们在约会平台上的体验愉快和成功。FlirtAI致力于通过一次次的对话改变在线约会场景。
数字绘画行为的人工智能模型
Paints-UNDO是一个旨在提供人类绘画行为基础模型的项目,希望未来的AI模型能更好地满足人类艺术家的真实需求。项目名称'Paints-Undo'的灵感来源于模型输出看起来像是在数字绘画软件中多次按下'撤销'按钮(通常是Ctrl+Z)。

© 2026 AIbase 备案号:闽ICP备08105208号-14